Android 轻量级存储方案的前世今生,kotlin处理null异常
sp.edit().putString(“c”, “dmn”).apply();
每次调用 edit 方法都会创建一个 Editor 对象,造成额外的内存占用。很多设计者会对 SharedPreferences 进行封装,隐藏掉 edit()和commit/apply()调用流程,但往往同时也忽略了Editor.commit/apply()的设计理念和使用场景。如果是复杂的场景,用户可以在多次 putXxx 方法之后再统一进行 commit/apply(),也就是一次更新多个键值对,只进行一次 IO 操作。
commit/apply 引起的 ANR 问题
commit 是同步地提交到硬件磁盘,有返回值表明修改是否成功,如果在主线程中提交会阻塞线程,影响后续的操作,可能导致 ANR;而 apply 是将修改数据提交到内存,而后异步真正提交到硬件磁盘,没有返回值。我们着重研究一下 apply 为什么会导致 ANR 问题,先来看看 apply 的源码:
@Override
public void apply() {
final long startTime = System.currentTimeMillis();
final MemoryCommitResult mcr = commitToMemory();
final Runnable awaitCommit = new Runnable() {
@Override
public void run() {
try {
mcr.writtenToDiskLatch.await(); //等待
} catch (InterruptedException ignored) {
}
···
}
};
QueuedWork.addFinisher(awaitCommit); //加入队列
Runnable postWriteRunnable = new Runnable() {
@Override
public void run() {
awaitCommit.run();
QueuedWork.removeFinisher(awaitCommit);
}
};
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable);
notifyListeners(mcr);
}
首先把带有 await 的 runnable 添加到 QueuedWork 队列,然后把这个写入任务 postWriteRunnable 通过 enqueueDiskWrite 交给 HandlerThread(Handler + Thread) 进行执行,待处理的任务排队进行执行。然后我们进入 ActivityThread 的 handleStopActivity 方法中,可以看到如下代码
// Make sure any pending writes are now committed.
if (!r.isPreHoneycomb()) {
QueuedWork.waitToFinish();
}
我们再来看看 waitToFinish 中的一段源码
Is called from the Activity base class’s onPause(), after BroadcastReceiver’s onReceive,
- after Service command handling, etc. (so async work is never lost)
*/ //这个注释很重要
public static void waitToFinish() {
···
try {
while (true) {
Runnable finisher;
synchronized (sLock) {
finisher = sFinishers.poll();
}
if (finisher == null) {
break;
}
finisher.run(); //关键,相当于调用 mcr.writtenToDiskLatch.await()
}
} finally {
sCanDelay = true;
}
}
还记得之前的 QueuedWork.addFinisher(awaitCommit)吗,里面的 awaitCommit 在等待写入线程,如果用户使用了太多的 apply,也就是说写入队列中会有很多写入任务。而只有一个线程在写入,一旦涉及到大量的读写很容易造成ANR(android 8.0 之前,android 8.0 之前的实现 QueuedWork.waitToFinish 是有缺陷的。在多个生命周期方法中,在主线程等待任务队列去执行完毕,而由于cpu调度的关系任务队列所在的线程并不一定是处于执行状态的,而且当apply提交的任务比较多时,等待全部任务执行完成,会消耗不少时间,这就有可能出现 ANR),因为本文的源码时基于 android 29 的,所以该版本或者说是 android 8.0之后并不存在 ANR 问题,因为 8.0之后做了很大的优化,会主动触发processPendingWork取出写任务列表中依次执行,而不是只在在等待。还有一个更重要的优化:
我们知道在调用 apply 方法时,会将改动同步提交到内存中 map 中,然后将写入磁盘的任务加入的队列中,在工作线程中从队列中取出写入任务,依次执行写入。注意,不管是内存的写入还是磁盘的写入,对于一个 xml 格式的 sp 文件来说,都是全量写入的。 这里就存在优化的空间,比如对于同一个 sp 文件,连续调用 n 次apply,就会有 n 次写入磁盘任务执行,实际上只需要最后执行最后那次就可以了,最后那次提交对应内存的 map 是持有最新的数据,所以就可以省掉前面 n-1 次的执行,这个就是android 8.0中做的优化,是使用版本来进行控制的。
解决方案
解决方案可以参考今日头条的解决方案,通过反射 ActivityThread 中的 H(Handler) 变量,给 Handler 设置一个 callback,Handler 的 dispatchMessage 中先处理 callback。队列清理需要反射调用 QueuedWork。Google 之所以在Activity/Service 的 onStop 之前调用该方法是为了尽量保证 sp 的数据持久化,该文章中也对比了清理队列和未清理情况下的失败率(相差不大)。
还有一个解决方案,因为 SharedPreferences 是个接口,所以可以自己实现 apply (异步调用系统 commit,这样并不会导致类似系统 apply 那样的阻塞),同时重写 Activity 和 Application 的 getSharedPreference 方法,直接返回自己的实现。但是这个方案带来的副作用比清理等待锁更加明显:系统apply是先同步更新缓存再异步写文件,调用方在同一线程内读写缓存是同步的,无需关心上下文数据读写同步问题;commit 异步化之后直接在子线程中更新缓存再写文件,调用方需要关注上下文线程切换,异步有可能引发读写数据不一致问题。所以还是推荐使用第一种方案。
安全机制
安全机制我们可以分为线程安全,进程安全,文件备份机制。
SharedPreferences 通过锁来保证线程安全,这里就不赘述了。而如何保证进程安全呢,我们再来看看 SharedPreferences 类的注释,可以看到不支持进程安全。
-
Note: This class does not support use across multiple processes.
SharedPreferences 提供了 MODE_MULTI_PROCESS 这个 Flag 来支持跨进程,保证了在 API 11 以前的系统上,如果 sp 已经被读取进内存,再次获取这个 sp 的时候,如果有这个 flag,会重新读一遍文件,仅此而已!
@Override
public SharedPreferences getSharedPreferences(File file, int mode) {
SharedPreferencesImpl sp;
···
if ((mode & Context.MODE_MULTI_PROCESS) != 0 ||
getApplicationInfo().targetSdkVersion < android.os.Build.VERSION_CODES.HONEYCOMB) {
// If somebody else (some other process) changed the prefs
// file behind our back, we reload it. This has been the
// historical (if undocumented) behavior.
sp.startReloadIfChangedUnexpectedly();
}
return sp;
}
所以说 SharedPreferences 的跨进程通信压根就不可靠!对于如何保证进程安全,可以使用 ContentProvider 进行统一访问,或者使用文件锁的方式。
最后我们再来看看文件备份机制,我们在运行程序的时候,可能会遇到手机死机或者断电等突发状况,这个时候如何保证文件的正常和安全就至关重要了。Android 系统本身的文件系统虽然有保护机制,但还会有数据丢失或者文件损坏的情况,所以对文件的备份就至关重要了。从 SharedPreferencesImpl 的 commit() -> enqueueDiskWrite() -> writeToFile(),
@GuardedBy(“mWritingToDiskLock”)
private void writeToFile(MemoryCommitResult mcr, boolean isFromSyncCommit) {
···
//尝试写入文件
if (!backupFileExists) {
if (!mFile.renameTo(mBackupFile)) { //直接把原有的文件命名成备份文件
Log.e(TAG, "Couldn’t rename file " + mFile
- " to backup file " + mBackupFile);
mcr.setDiskWriteResult(false, false);
return;
}
} else {
mFile.delete();
}
// Writing was successful, delete the backup file if there is one.
// 写入成功,删除备份文件
mBackupFile.delete();
···
}
备份的时候是直接将原有的文件重命名为备份文件,写入成功后再删除备份文件。再来看看前面的 loadFromDisk 方法
private void loadFromDisk() {
synchronized (mLock) {
if (mLoaded) {
return;
}
if (mBackupFile.exists()) {
mFile.delete();
mBackupFile.renameTo(mFile);
}
···
}
如果因为异常情况(比如进程被 kill)导致写入失败,下次启动的时候若发现存在备份文件,则将备份文件重新命名为源文件,原本未完成写入的文件就直接丢弃。
小结
到此我们先做个小结,我们提到了 SharedPreferences 的内存占用问题以及可能阻塞主线程,正确的应用场景和合适的代码调用方式,还提到了可能导致的 ANR 问题,最后我们分析了它的安全机制,线程安全,进程安全(无),文件备份机制。
在正确使用 SharedPreferences 的情况下,可以大概总结一下 SharedPreferences 的问题,可能导致内存占用高,ANR,无法保证进程安全。
MMKV
MMKV 腾讯开发的基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强,支持多进程。从 2015 年中至今在微信上使用,其性能和稳定性经过了时间的验证。后续也已移植到 Android / macOS / Win32 / POSIX 平台,一并开源。
MMKV 原本是要解决微信上特殊文字引起系统的 crash,解决过程中有一些计数器需要保存(因为闪退随时可能发生),这时就需要一个性能非常高的通用 key-value组件,SharedPreferences、NSUserDefaults、SQLite 等常见组件这些都不满足,考虑到这个防 crash 方案最主要的诉求还是实时写入,而 mmap 内存映射文件刚好满足这种需求。
使用方式
首先导入依赖
dependencies {
implementation ‘com.tencent:mmkv-static:1.2.7’
// replace “1.2.7” with any available version
}
MMKV 的使用非常简单,所有变更立马生效,无需调用 sync、apply。 在 App 启动时初始化 MMKV,设定 MMKV 的根目录(files/mmkv/),例如在 Application 里:
public void onCreate() {
super.onCreate();
String rootDir = MMKV.initialize(this);
System.out.println("mmkv root: " + rootDir);
//……
}
如果不同的业务需要区别存储,也可以单独创建自己的实例
MMKV kv = MMKV.mmkvWithID(“MyID”);
kv.encode(“bool”, true);
如果业务需要多进程访问,那么在初始化的时候加上标志位 MMKV.MULTI_PROCESS_MODE:
MMKV kv = MMKV.mmkvWithID(“InterProcessKV”, MMKV.MULTI_PROCESS_MODE);
kv.encode(“bool”, true);
MMKV 提供一个全局的实例,可以直接使用:
import com.tencent.mmkv.MMKV;
//……
MMKV kv = MMKV.defaultMMKV();
kv.encode(“bool”, true);
boolean bValue = kv.decodeBool(“bool”);
kv.encode(“int”, Integer.MIN_VALUE);
int iValue = kv.decodeInt(“int”);
kv.encode(“string”, “Hello from mmkv”);
String str = kv.decodeString(“string”);
支持的数据类型
-
支持以下 Java 语言基础类型:
-
boolean、int、long、float、double、byte[] -
支持以下 Java 类和容器:
-
String、Set -
任何实现了
Parcelable的类型
SharedPreferences 迁移
-
MMKV 提供了
importFromSharedPreferences()函数,可以比较方便地迁移数据过来。 -
MMKV 还额外实现了一遍
SharedPreferences、SharedPreferences.Editor这两个 interface,在迁移的时候只需两三行代码即可,其他 CRUD 操作代码都不用改。
private void testImportSharedPreferences() {
//SharedPreferences preferences = getSharedPreferences(“myData”, MODE_PRIVATE);
MMKV preferences = MMKV.mmkvWithID(“myData”);
// 迁移旧数据
{
SharedPreferences old_man = getSharedPreferences(“myData”, MODE_PRIVATE);
preferences.importFromSharedPreferences(old_man);
old_man.edit().clear().commit();
}
// 跟以前用法一样
SharedPreferences.Editor editor = preferences.edit(); //注意 preferences.edit();
editor.putBoolean(“bool”, true);
editor.putInt(“int”, Integer.MIN_VALUE);
editor.putLong(“long”, Long.MAX_VALUE);
editor.putFloat(“float”, -3.14f);
editor.putString(“string”, “hello, imported”);
HashSet set = new HashSet();
set.add(“W”); set.add(“e”); set.add(“C”); set.add(“h”); set.add(“a”); set.add(“t”);
editor.putStringSet(“string-set”, set);
// 无需调用 commit()
//editor.commit();
}
可以看到使用preferences.edit();可以让迁移后的用法和之前一样,MMKV 已经为我们考虑的很周到了,迁移的成本非常低,不迁移过来还等什么呢?
mmap 原理
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对应关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
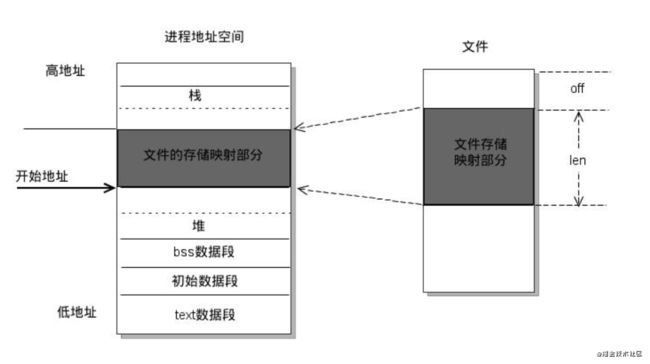
关于虚拟(地址)空间和虚拟内存:请放弃虚拟内存这个概念,那个是广告性的概念,在开发中没有意义。开发中只有虚拟空间的概念,进程看到的所有地址组成的空间,就是虚拟空间。虚拟空间是某个进程对分配给它的所有物理地址(已经分配的和将会分配的)的重新映射。 mmap的作用,在应用这一层,是让你把文件的某一段,当作内存一样来访问。
通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
为什么选择 Protobuf
数据序列化方面我们选用 Protobuf 协议,pb 在性能和空间占用上都有不错的表现。Protocol buffers 通常称为 Protobuf,是 Google 开发的一种协议,允许对结构化数据进行序列化和反序列化,不仅仅是一种消息格式,它还是一组用于定义和交换这些消息的规则和工具。 谷歌开发它的目的是提供一种比 XML更好的方式来进行系统间通信。该协议甚至超越了JSON,具有更好的性能,更好的可维护性和更小的尺寸。
但是它也有一些缺点,二进制格式可读性差,维护成本高等。关于序列化选型,可以参考这篇文章。
增量更新机制
标准 protobuf 不提供增量更新的能力,每次写入都必须全量写入。考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力:将增量 kv 对象序列化后,直接 append 到内存末尾;这样同一个 key 会有新旧若干份数据,最新的数据在最后;那么只需在程序启动第一次打开 mmkv 时,不断用后读入的 value 替换之前的值,就可以保证数据是最新有效的。
使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。例如同一个 key 不断更新的话,是可能耗尽几百 M 甚至上 G 空间,而事实上整个 kv 文件就这一个 key,不到 1k 空间就存得下。这明显是不可取的。我们需要在性能和空间上做个折中:以内存 pagesize 为单位申请空间,在空间用尽之前都是 append 模式;当 append 到文件末尾时,进行文件重整、key 重排,尝试序列化保存重排结果;重排后空间还是不够用的话,将文件扩大一倍,直到空间足够。
多进程设计与实现
我们先来看MMKV的设计初衷是要解决什么问题,最主要的诉求还是实时写入,而且要求速度够快,性能高。当要求跨进程通信的时候,我们先看看我们有什么,C/S 架构中有 ContentProvider,但是问题很明显,启动慢访问也慢,这个可以说是 Android 下基于Binder 的 C/S 架构组件的痛点,socket、PIPE、message queue,因为要至少 2 次的内存拷贝,就更加慢了。
MMKV 追求的是极致的访问速度,我们要尽可能的避免进程间通信,C/S架构是不可取的。再考虑到 MMKV 底层使用 mmap 实现,采用去中心化的架构是很自然的选择。我们只需要将文件 mmap 到每个访问进程的内存空间,加上合适的进程锁,再处理好数据的同步,就能够实现多进程并发访问。
性能对比
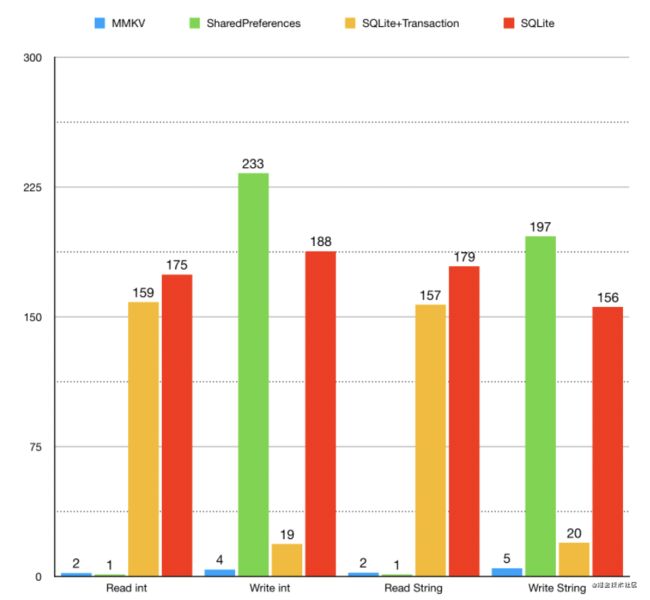
- 单进程性能,可以看到 MMKV 在写入性能上远远超过 SharedPreferences 和 SQlite,在读取性能上也有相近或超越的表现。
- 多进程性能,MMKV 无论是在写入性能还是在读取性能,都远远超越 MultiProcessSharedPreferences & SQLite & SQLite, MMKV 在 Android 多进程 key-value 存储组件上是不二之选。
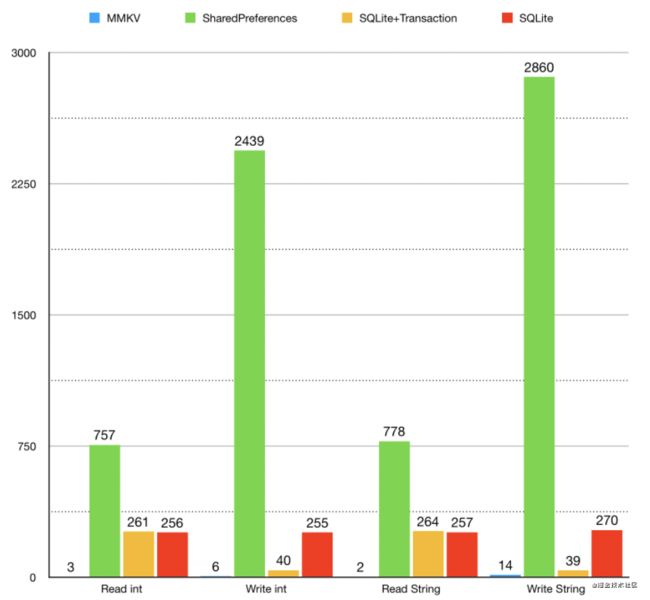
(测试机器是 华为 Mate 20 Pro 128G,Android 10,每组操作重复 1k 次,时间单位是 ms。)
小结
MMKV 可以解决 SharedPreferences 不能直接跨进程通信的问题,但 SharedPreferences 也可以通过 ContentProvider 或者文件锁等方式解决该问题,个人感觉 MMKV 的主要优势有两点,SharedPreferences 可能导致 Activity/Service 等生命周期去做 waitToFinish() 导致ANR 问题,而 MMKV 不存在这个问题,另一个优势是实时写入,性能高,速度快(设计初衷)。
虽然 SharedPreferences 的跨进程、ANR 问题也可以用技术方案进行解决,但是 MMKV 天然不存在这两个问题,而且该组件也支持从 SharedPreferences 迁移到 MMKV,迁移也及其简单,成本很小。所以 MMKV 的确是一个更好的轻量级存储方案。
DataStore
DataStore 是 Android Jetpack 的一部分。Jetpack DataStore 是一种数据存储解决方案,允许您使用协议缓冲区存储键值对或类型化对象。DataStore 使用 Kotlin 协程和流程(Flow)以异步、一致的事务方式存储数据。官方建议如果当前在使用 SharedPreferences 存储数据,请考虑迁移到 DataStore。
DataStore 提供两种不同的实现:Preferences DataStore 和 Proto DataStore。
-
Preferences DataStore 以键值对的形式存储在本地和 SharedPreferences 类似,此实现不需要预定义的架构,也不确保类型安全。
-
Proto DataStore 将数据作为自定义数据类型的实例进行存储。此实现要求您使用协议缓冲区来定义架构,但可以确保类型安全。
Preferences DataStore 使用方式
先导入依赖
dependencies {
// Preferences DataStore (SharedPreferences like APIs)
implementation “androidx.datastore:datastore-preferences:1.0.0-alpha06”
// Typed DataStore (Typed API surface, such as Proto)
implementation “androidx.datastore:datastore-core:1.0.0-alpha06”
}
Preferences DataStore 的使用方式如下
//1.构建 DataStore
val dataStore: DataStore = context.createDataStore(name = PREFERENCE_NAME)
//2.Preferences DataStore 以键值对的形式存在本地,需要定义一个 key(比如:KEY_JACKIE)
//Preferences DataStore 中的 key 是 Preferences.Key 类型
val KEY_JACKIE = stringPreferencesKey(“username”)
GlobalScope.launch {
//3.存储数据
dataStore.edit {
it[KEY_JACKIE] = “jackie”
}
//4.获取数据
val getName = dataStore.data.map {
it[KEY_JACKIE]
}.collect{ //flow 调用collect 开始消费数据
Log.i(TAG, “onCreate: $it”) //打印出 jackie
}
}
需要注意的是读取、写入数据都要在协程中进行,因为 DataStore 是基于 Flow 实现的。也可以看到没有 commit/apply() 方法,同时可以监听到操作成功或者失败结果。
Preferences DataStore 只支持 Int , Long , Boolean , Float , String 键值对数据,适合存储简单、小型的数据,并且不支持局部更新,如果修改了其中一个值,整个文件内容将会被重新序列化。
SharedPreferences 迁移到 Preferences DataStore
接下来我们来看看 SharedPreferences 迁移到 DataStore,在构建 DataStore 的时候传入 SharedPreferencesMigration,当 DataStore 构建完了之后,需要执行一次读取或者写入操作,即可完成迁移,迁移成功后,会自动删除 SharedPreferences 文件
val dataStoreFromPref = this.createDataStore(name = PREFERENCE_NAME_PREF
,migrations = listOf(SharedPreferencesMigration(this,OLD_PREF_NANE)))
我们原本的 SharedPreferences 数据如下
lsm
原本文件目录如下:

迁移后的文件目录如下:

可以看到迁移后原本的 SharedPreferences 被删除了,同时也可以看到 DataStore 的文件更小一些,在迁移的过程中发现一个有趣的情况,如果我直接迁移后并不进行任意值的读取,在对应的目录上找不到迁移后的文件,只有当我进行任意值的读取后,才会在对应的目录上找到文件,不知道是不是 bug,还是说设计如此。完整代码如下:
val dataStoreFromPref = this.createDataStore(name = PREFERENCE_NAME_PREF
, migrations = listOf(SharedPreferencesMigration(this, OLD_PREF_NANE)))
建议
当我们出去找工作,或者准备找工作的时候,我们一定要想,我面试的目标是什么,我自己的技术栈有哪些,近期能掌握的有哪些,我的哪些短板 ,列出来,有计划的去完成,别看前两天掘金一些大佬在驳来驳去 ,他们的观点是他们的,不要因为他们的观点,膨胀了自己,影响自己的学习节奏。基础很大程度决定你自己技术层次的厚度,你再熟练框架也好,也会比你便宜的,性价比高的替代,很现实的问题但也要有危机意识,当我们年级大了,有哪些亮点,与比我们经历更旺盛的年轻小工程师,竞争。
-
无论你现在水平怎么样一定要 持续学习 没有鸡汤,别人看起来的毫不费力,其实费了很大力,这四个字就是我的建议!!!!!!!!!
-
准备想说怎么样写简历,想象算了,我觉得,技术就是你最好的简历
-
我希望每一个努力生活的it工程师,都会得到自己想要的,因为我们很辛苦,我们应得的。
-
有什么问题想交流,欢迎给我私信,欢迎评论
【附】相关架构及资料


资料领取
点击这里免费获取
内含往期Android高级架构资料、源码、笔记、视频。高级UI、性能优化、架构师课程、NDK、混合式开发(ReactNative+Weex)微信小程序、Flutter全方面的Android进阶实践技术
握的有哪些,我的哪些短板 ,列出来,有计划的去完成,别看前两天掘金一些大佬在驳来驳去 ,他们的观点是他们的,不要因为他们的观点,膨胀了自己,影响自己的学习节奏。基础很大程度决定你自己技术层次的厚度,你再熟练框架也好,也会比你便宜的,性价比高的替代,很现实的问题但也要有危机意识,当我们年级大了,有哪些亮点,与比我们经历更旺盛的年轻小工程师,竞争。
-
无论你现在水平怎么样一定要 持续学习 没有鸡汤,别人看起来的毫不费力,其实费了很大力,这四个字就是我的建议!!!!!!!!!
-
准备想说怎么样写简历,想象算了,我觉得,技术就是你最好的简历
-
我希望每一个努力生活的it工程师,都会得到自己想要的,因为我们很辛苦,我们应得的。
-
有什么问题想交流,欢迎给我私信,欢迎评论
【附】相关架构及资料
[外链图片转存中…(img-lS993r9P-1643947204541)]
[外链图片转存中…(img-Zmzpa3wu-1643947204542)]
资料领取
点击这里免费获取
内含往期Android高级架构资料、源码、笔记、视频。高级UI、性能优化、架构师课程、NDK、混合式开发(ReactNative+Weex)微信小程序、Flutter全方面的Android进阶实践技术