Java常用集合总结
Java常用集合介绍
- 1.集合的理解和好处
- 2.单列集合Collection
-
- 2.1 List接口
-
- 2.1.1ArrayList类
- 2.1.2 Vector类
- 2.1.3LinkedList类
- 2.2 Set接口
-
- 2.2.1 HashSet类
- 2.2.2 LinkedHashSet类
- 2.3 COW并发容器
-
- 2.3.1 CopyOnWriteArrayList源码
- 2.3.2 CopyOnWriteArraySet源码
- 3.双列集合Map
-
- 3.1 HashMap类
-
- 3.1.1Hashmap基本结构讲解:
- 3.1.2 存储数据过程
- 3.1.5 取数据过程get(key)
- 3.1.6 扩容问题
- 3.1.4 手动实现HashMap
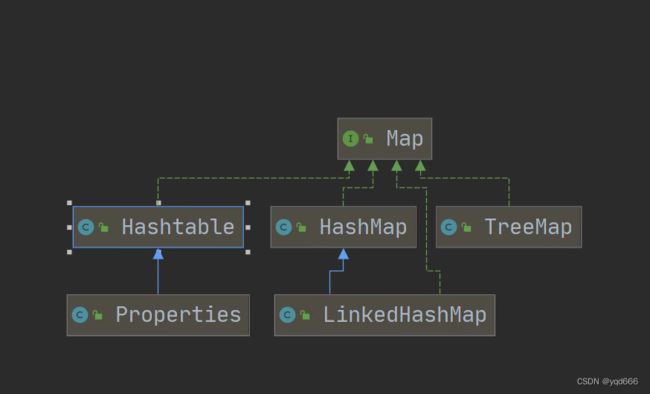
- 3.2 HashTable类
- 3.3 ConcurrentHashMap
- 3.4 TreeMap类
1.集合的理解和好处
1)我们先分析一下使用数组的弊端:
①长度开始时必须指定,并且一旦指定,不能更改
②保存的元素必须为同一类型
③增加/删除元素比较麻烦
2)集合的好处
①可以动态保存任意多个对象,使用比较方便
②提供了很多方便的操作对象的方法:add、remove、set、get等
3)集合的框架体系如下:
①单列集合

②双列集合
2.单列集合Collection
1)Collection接口常用方法
①add():添加单个元素
②remove():删除指定元素
③contains():查找元素是否存在
④size():获取元素个数
⑤isEmpty():判断是否为空
⑥clear():清空
⑦addAll():添加多个元素
⑧removeAll():删除多个元素
⑨containsAll():查找多个元素是否都存在
2)Collection接口遍历元素的方法[使用Iterator(迭代器)]
①Iterator对象称为迭代器,主要用于遍历Collection集合中的元素
②所有实现了Iterator接口的集合类都有一个iterator()方法,用以返回一个实现了Iterator接口的对象,即可以返回一个迭代器
③查看源码发现,iterator()方法存在于Collection的上一级Iterable中
public interface Iterable<T> {
Iterator<T> iterator();
}
④迭代器的执行原理
Iterator iterator = coll.iterator();//得到一个集合的迭代器
//hasNext();判断是否还有下一个元素
while(iterator.hasNext()){
iterator.next()//next作用:坐标下移,返回下一个元素
}
⑤迭代器的简化版[增强for循环]
for(元素类型 元素名 : 集合名/数组名){
访问元素
}
2.1 List接口
1.List接口的特点
1)List集合类中元素有序(即添加顺序和取出顺序一致)、且可重复
2)List集合中的每一个元素都有其对应的顺序索引
2.List接口常用方法
List list = new ArrayList();
list.add("亚瑟");
list.add("程咬金");
// 1) void add(int index, E element): 在index位置插入元素
list.add(1, "后羿");
System.out.println("list=" + list);//list=[亚瑟, 后羿, 程咬金]
// 2) boolean addAll(int index, Collection c):从index位置将c中所有元素添加进来
List list1 = new ArrayList<>();
list1.add("张三");
list1.add("李四");
list.addAll(1, list1);
System.out.println("list=" + list);//list=[亚瑟, 张三, 李四, 后羿, 程咬金]
// 3) E get(int index):获取指定index位置的元素
// 4) int indexOf(Object o):返回o在集合中首次出现的位置
System.out.println(list.indexOf("后羿"));//3
// 5) int lastIndexOf(Object o):返回o在集合中未次出现的位置
list.add("后羿");
System.out.println(list.lastIndexOf("后羿"));
// 6) E remove(int index);移除指定index位置的元素,并返回此元素
// 7) E set(int index, E element);替换指定index位置的元素
list.set(0, "鲁班");
System.out.println("list=" + list);
// 8) List subList(int fromIndex, int toIndex);返回从fromIndex到toIndex位置的子集合
System.out.println(list.subList(1,3));
2.1.1ArrayList类
ArrayList list = new ArrayList();
for (int i = 0; i < 10; i++) {
list.add(i);
}
for (int i = 11;i<=15;i++){
list.add(i);
}
list.add(100);
list.add(200);
list.add(null);
}
上面代码的执行源码流程如下:

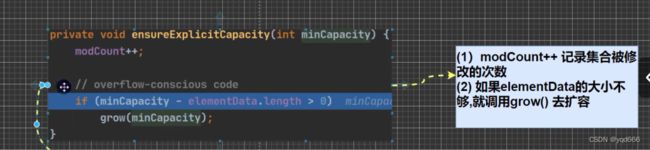
ArrayList源码分析:
(1)ArrayList中维护了一个Object类型的数组elementData
transient Object[] elementData;//transient表示瞬间,短暂的,表示该属性不会被序列化
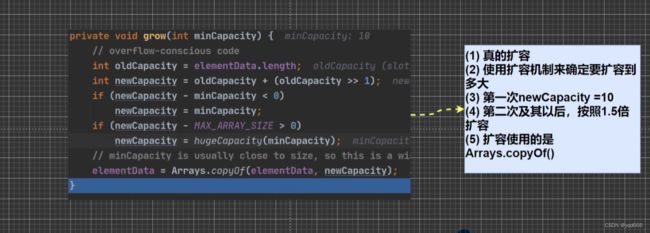
(2)当创建ArrayList对象时,如果使用的是无参构造器。则初始elementData容量为0,第一次添加,则扩容elementData为10,如需要再次扩容,则扩容elementData为1.5倍
(3)如果使用的是指定大小的构造器,则初始elementData容量为指定大小,如果需要扩容,则直接扩容elementData为1.5倍。
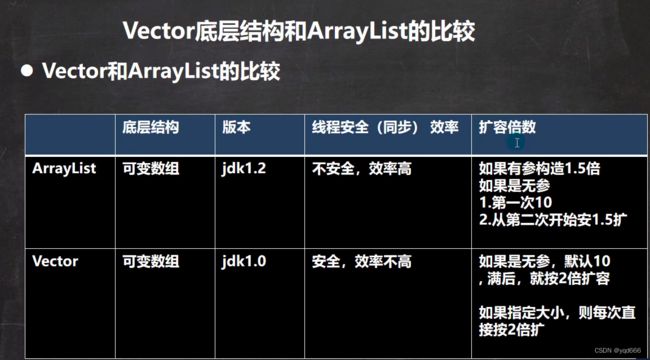
2.1.2 Vector类
1.Vector类的特点:
(1)Vector类底层是一个数组, protected Object[] elementData;
(2)Vector是线程同步的,即线程安全的,该类方法带有synchronized
2.Vector和ArrayList的比较
2.1.3LinkedList类
1.LinkedList类的特点
1)LinkedList底层实现了双向链表和双端队列特点
2)可以添加任意元素(元素可以重复),包括null
3)线程不安全,没有实现同步
2.LinkedList底层操作机制
1)LinkedList底层维护了一个双向链表
2)LinkedList中维护了两个属性first和last分别指向首节点和尾节点
3)每个节点(Node对象),里面又维护了prev、next、item,其中通过prev指向前一个,通过next指向后一个节点。最终实现双向链表。
4)LinkedList添加和删除元素不是通过数组完成的,相对来说效率较高。
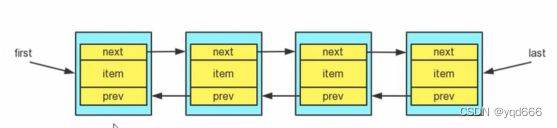
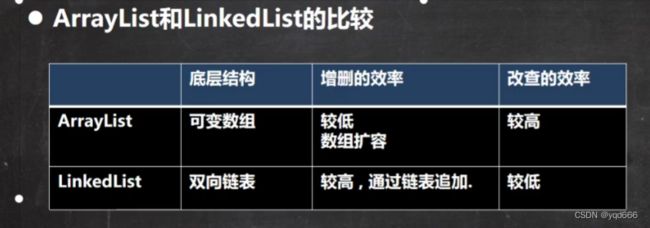
3.ArrayList和LinkedList的比较
2.2 Set接口
1.Set接口的基本介绍
1)无序(添加和取出的顺序不一致),取出的顺序虽然不是添加的顺序,但是它的顺序是固定的。
2)不允许有重复元素;可以存放null,最多包含一个null
3)没有索引,故不能使用索引的方法来获取元素
2.2.1 HashSet类
1.HashSet的简介
1)HashSet实现了Set接口
2)查看源码可知,HashSet实际上是HashMap
public HashSet() {
map = new HashMap<>();
}
2.HashSet的底层源码分析
1)使用HashSet添加一个元素时,会先得到hash值,然后转成—>索引值
2)找到存储数据表table,看这个索引位置是否已经存放的有元素。
3)没有则直接加入,如果有,则调用equals方法进行比较
4)在Java8中,如果一条链表的元素个数达到TREEIFY_THRESHOLD (默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY (默认是64),就会进行树化(红黑树),这样又大大提高了查找的效率。
2.2.2 LinkedHashSet类
1.LinkedHashSet的简介
1)在LinkedHashSet中维护了一个hash表和双向链表(LinkedHashSet有head和tail)
2)每一个节点有before和after属性,这样可以形成双向链表
3)在添加一个元素时,先求hash值,再求索引,确定该元素在table的位置,然后将添加的元素加入到双向链表
4)遍历LinkedHashSet,插入顺序和遍历顺序一致
2.3 COW并发容器
(1)COW并发容器,全称Copy On Write容器,写时复制容器(即读写分离容器)
(2)原理:
向容器中添加元素时,先将容器进行Copy复制出一个新容器,然后将元素添加到新容器中,再将原容器的引用指向新容器。
并发读的时候不需要锁定容器,因为原容器没有变化,所以可以读取到原容器中的值,使用的是一种读写分离的思想。
(3)这种设计的好处是什么?
注意上面的操作arr数组本身是无锁的,没有锁,在添加数据的时候,做了额外的复制;此时如果有线程来读数据,那么读取的是
老arr的数据,此时arr的地址还没有改呢,在添加元素的过程中,无论有多少个线程来读线程,读的都是原来的arr,不是新的arr,
所以性能很高,读写分离。提高了并发性能,如果再读就会再复制
(4)注意
CopyOnWrite容器只能保证数据的最终一致性,不能保证数据实时一致性。所以如果你希望写入的数据,马上就能读到,就不要
再使用CopyOnWrite容器了
(5)适合特定场合
这个应用场景显而易见,适合读多写少的情况。如果一万个线程都添加操作,都在集合中添加数据,数组就会不断复制,长度不断+1,
那么JVM肯定会一直往上飙升。你用的时候就需要先评估一下使用场景。由于每次更新都会复制新容器,所以如果数据量较大并且更新
操作频繁则对内存消耗很高,建议在高并发读的场景下使用
(6)COW容器有两种,一种是CopyOnWriteArrayList,一种是CopyOnWriteArraySet;一个是替代ArrayList,一个是替代Set
2.3.1 CopyOnWriteArrayList源码
public class CopyOnWriteArrayList<E>{
//底层是基于数组实现的
private transient volatile Object[] array;
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
final void setArray(Object[] a) {
array = a; // array = new Object[0]
}
//add方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//返回底层array数组,给了elements
Object[] elements = getArray();
//获取elements的长度 --》 获取老数组的长度
int len = elements.length;
//完成数组的复制,将老数组中的元素复制到新数组中,并且新数组的长度+1
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 将e元素放入新数组的最后位置
newElements[len] = e;
//array数组的指向从老数组变为新数组
setArray(newElements);
return true;
} finally {
lock.unlock();
} }
private boolean addIfAbsent(E e, Object[] snapshot) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//取出array数组给current
Object[] current = getArray();
int len = current.length;
if (snapshot != current) {
// Optimize for lost race to another addXXX operation
int common = Math.min(snapshot.length, len);
//遍历老数组
for (int i = 0; i < common; i++)
//将遍历的元素和老数组的每一个元素进行比较,如果有重复的元素,就返回false,不添加了
if (current[i] != snapshot[i] && eq(e, current[i]))
return false;
if (indexOf(e, current, common, len) >= 0)
return false;
}
Object[] newElements = Arrays.copyOf(current, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
} } }
2.3.2 CopyOnWriteArraySet源码
public class CopyOnWriteArraySet<E> extends AbstractSet<E>
//CopyOnWriteArraySet底层是基于CopyOnWriteArrayList的
private final CopyOnWriteArrayList<E> al;
//add方法底层调用的还是CopyOnWriteArrayList的addIfAbsent方法
public boolean add(E e) {
return al.addIfAbsent(e);
}
由上面的源码可以看出,每次调用CopyOnWriteArraySet的add方法的时候,其底层是基于CopyOnWriteArrayList的addIfAbsent方法的,
每次在addIfAbsent方法中都要对数组进行遍历,所以CopyOnWriteArraySet的性能低于CopyOnWriteArrayList
3.双列集合Map
Map就是用来存储“键(key)-值(value)对”的;Map类中存储的“键值对”通过键来标识,所以“键对象”不能重复。
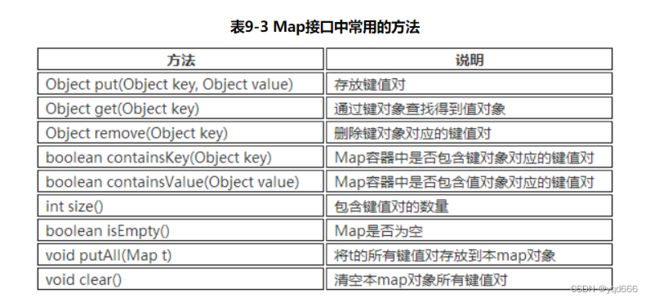
3.1 HashMap类
HashMap底层使用了哈希表。哈希表的基本结构就是“数组+链表”
①数组:占用空间连续。寻址容易,查询速度块。但是,增加和删除效率非常低
②链表:占用空间不连续。寻址困难,查询速度慢。但是,增加和删除效率非常高。
(1)JDK1.7之前,HashMap 就是一个table数组 + 链表实现的存储结构
(2)JDK1.8中,当链表的存储数据个数大于等于8的时候,不再采用链表存储,而采用了红黑树存储结构
3.1.1Hashmap基本结构讲解:
(1)哈希表的基本结构就是“数组+链表”。我们打开HashMap源码,发现有如下两个核心内容

(2)其中的Entry[] table 就是HashMap的核心数组结构,我们也称之为“位桶数组”。我们再继续看Entry是什么,源码如下:

一个Entry对象存储了:
① key:键对象 value:值对象
② next:下一个节点
③ hash: 键对象的hash值
显然每一个Entry对象就是一个单向链表结构,我们使用图形表示一个Entry对象的典型示意:
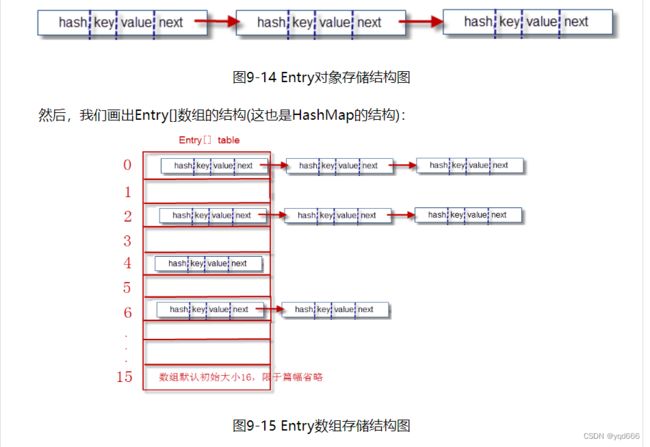
3.1.2 存储数据过程
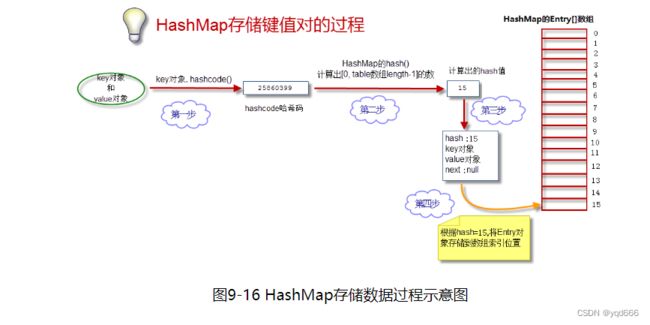
(1)获得key对象的hashcode
首先调用key对象的hashcode()方法,获得hashcode
(2) 根据hashcode计算出hash值
hashcode是一个整数,我们需要将它转化成[0, 数组长度-1]的范围。我们要求转化后的hash值尽量均匀地分布在[0,数组长度-1]这个区间,减少“hash冲突”
(3) 生成Entry对象
如上所述,一个Entry对象包含4部分:key对象、value对象、hash值、指向下一个Entry对象的引用。我们现在算出了hash值。下一个Entry对象的引用为null。
(4) 将Entry对象放到table数组中
如果本Entry对象对应的数组索引位置还没有放Entry对象,则直接将Entry对象存储进数组;如果对应索引位置已经有Entry对象,则将已有Entry对象的next指向本Entry对象,形成链表
3.1.5 取数据过程get(key)
我们需要通过key对象获得“键值对”对象,进而返回value对象。明白了存储数据过程,取数据就比较简单了,参见以下步骤:
(1) 获得key的hashcode,通过hash()散列算法得到hash值,进而定位到数组的位置。
(2) 在链表上挨个比较key对象。调用equals()方法,将key对象和链表上所有节点的key对象进行比较,直到碰到返回true的节点对象为止。
(3) 返回equals()为true的节点对象的value对象。
明白了存取数据的过程,我们再来看一下hashcode()和equals方法的关系:
Java中规定,两个内容相同(equals()为true)的对象必须具有相等的hashCode。因为如果equals()为true而两个对象的hashcode不同;那在整个存储过程中就发生了悖论。
3.1.6 扩容问题
(1)HashMap的位桶数组,初始大小为16。实际使用时,显然大小是可变的。如果位桶数组中的元素达到(0.75*数组 length), 就重新调整数组大小变为原来2倍大小。
(2)扩容很耗时。扩容的本质是定义新的更大的数组,并将旧数组内容挨个拷贝到新数组中。
3.1.4 手动实现HashMap
public class DemoHashMap<K,V> {
Node[] table;//位桶数组
int size;//存放的键值对的个数
@Override
public String toString() {
StringBuilder sb = new StringBuilder("{");
// 遍历bucket数组
for (int i = 0; i < table.length; i++) {
Node temp = table[i];
// 遍历链表秒
while (temp != null) {
sb.append(temp.key + ":" + temp.value + ",");
temp = temp.next;
} }
sb.setCharAt(sb.length() - 1, '}');
return sb.toString();
}
public static void main(String[] args) {
DemoHashMap<Integer, Object> m = new DemoHashMap<>();
m.put(10, "aa");
m.put(20, "bb");
m.put(30, "cc");
m.put(20, "sss");
m.put(53, "gg");
m.put(69, "mm");
m.put(85, "kk");
System.out.println(m);
System.out.println( m.get(53));
}
public DemoHashMap() {
table = new Node[16]; //长度一般定义成2的整数次幂
}
public V get(K key) {
int hash = myHash(key.hashCode(), table.length);
V value = null;
if (table[hash] != null) {
Node temp = table[hash];
while (temp != null) {
if (temp.key.equals(key)) {//如果相等,则说明找到了键值对,返回对应的value
value = (V) temp.value;
break;
} else {
temp = temp.next;
} } }
return value;
}
public void put(K key, V value) {
// 定义了新的结点对象
Node newNode = new Node();
newNode.hash = myHash(key.hashCode(), table.length);
newNode.key = key;
newNode.value = value;
newNode.next = null;
Node temp = table[newNode.hash];
Node iterLast = null;//正在遍历的最后一个元素
boolean keyRepeat = false;
if (temp == null) {
// 此处数组元素为空,则直接将新节点放进去
table[newNode.hash] = newNode;
size++;
} else {
// 此处数组元素不为空,则遍历对应链表。。
while (temp != null) {
// 判断key如果重复,则覆盖
if (temp.key.equals(key)) {
keyRepeat = true;
temp.value = value;//只是覆盖value即可。其他的值(hash,key.next)保持不变
break;
} else {
// key不重复,则遍历下一个
iterLast = temp;
temp = temp.next;
} }
if (!keyRepeat) {//如果没有发生key重复的情况,则添加到链表最后
iterLast.next = newNode;
size++;
} } }
public int myHash(int v, int length) {
return v & (length - 1);
} }
class Node<K,V> {
int hash;
K key;
V value;
Node next;
}
3.2 HashTable类
HashTable类和HashMap用法几乎一样,底层实现几乎一样,只不过HashTable的方法添加了synchronized关键字确保线程同步检查,效率较低。
HashMap与HashTable的区别
(1)HashMap: 线程不安全,效率高。允许key或value为null。
(2) HashTable: 线程安全,效率低。不允许key或value为null。
3.3 ConcurrentHashMap
(1)与HashMap的区别是什么?
ConcurrentHashMap是HashMap的升级版,HashMap是线程不安全的,而ConcurrentHashMap是线程安全。而其他功能和实现原理和HashMap类似。
(2)与Hashtable的区别是什么?
①Hashtable也是线程安全的,但每次要锁住整个结构,并发性低。相比之下,ConcurrentHashMap获取size时才锁整个对象。
②Hashtable对get/put/remove都使用了同步操作。ConcurrentHashMap只对put/remove同步。
③Hashtable是快速失败的,遍历时改变结构会报错ConcurrentModificationException。ConcurrentHashMap是安全失败,允许并发检索和更新。
3.4 TreeMap类
TreeMap是红黑二叉树的典型实现。我们打开TreeMap的源码,发现里面有一行核心代码:
private transient Entry<K,V> root = null;
root用来存储整个树的根节点。我们继续跟踪Entry(是TreeMap的内部类)的代码:

可以看到里面存储了本身数据、左节点、右节点、父节点、以及节点颜色。 TreeMap的put()/remove()方法大量使用了红黑树的理论。