Supervised and Unsupervised NeuralApproaches to T ext Readability翻译
我们提出了一套新的神经监督和非监督方法来确定文档的可读性。在无监督设置中,我们利用神经语言模型,而在监督设置中,测试了三种不同的神经分类架构。我们表明,提出的神经无监督方法是稳健的,可跨语言转移,并允许适应特定的可读性任务和数据集。通过对两种语言的可读性基准数据和新标注数据集上的几种神经结构的系统比较,本研究也提供了可读性分类的不同神经方法的综合分析。我们揭示了它们的优缺点,将它们的性能与当前最先进的可读性分类方法(在大多数情况下仍依赖于广泛的特征工程)进行了比较,并提出了改进的可能性。
1.介绍
可读性涉及到给定文本和读者理解文本的认知负荷之间的关系。这种复杂的关系受到许多因素的影响,比如词汇和句法复杂程度、语篇衔接和背景知识(Crossley 等人,2017年)。为了简化测量阅读能力的问题,传统的可读性公式只关注词汇和句法特征,如词长、句子长度和词难度等统计特征(Davison 和 Kantor 1982)。这些方法已经被批评,因为他们的还原论和薄弱的统计基础(克罗斯利等人2017年)。另一个问题是他们的客观性和文化迁移性,因为不同年龄阶段的儿童掌握了不同的概念。例如,一个单词电视是相当长的,包含许多音节,但众所周知,大多数家庭生活在电视机。
随着新的自然语言处理技术的发展,一些研究试图消除传统的易读性公式的缺陷。这些尝试包括利用高级文本特性进行可读性建模,例如文本的语义和论述属性。其中,衔接和连贯是最受关注的,基于这些文本特征已经提出了几种可读性预测因子(见第2节)。然而,似乎没有一种预测文本的可读性,以及上述更简单的可读性公式(Todirascu et al. 2016)。
随着机器学习的进步,重点再次转移,大多数较新的方法认为可读性是一种分类、回归或排名任务。机器学习方法建立预测模型,根据一些属性和覆盖尽可能多的文本维度的人工构建的特征来预测人类分配的可读性分数(Schwarm和Ostendorf 2005;彼得森和奥斯坦多夫2009;Vajjala和Meurers 2012)。它们通常比传统的可读性公式和基于文本内聚的方法产生更好的结果,但需要额外的外部资源,如稀缺的标记可读性数据集。另一个问题是这些方法在不同的语料库和语言之间的可转移性,因为所产生的特征集不能很好地概括到不同类型的文本(Xia, Kochmar,和Briscoe 2016;Filighera, Steuer和Rensing 2019)。
最近,深度神经网络(Goodfellow, Bengio和Courville, 2016)在许多与语言相关的任务中表现出了令人印象深刻的表现。事实上,在数据量充足的情况下,他们已经在所有语义任务中达到了最先进的性能(Collobert等人2011;张,赵,乐村2015)。尽管最近一些神经学方法被提出用于可读性预测(Nadeem和Ostendorf 2018;Filighera, Steuer和Rensing 2019),这些类型的研究仍然相对稀缺,需要进一步研究,以建立哪种类型的神经结构最适合不同的可读性任务和数据集。此外,语言模型特征旨在衡量文本的词汇和语义属性,这可以在许多可读性研究中发现(Schwarm和Ostendorf 2005;彼得森和奥斯坦多夫2009;Xia, Kochmar和Briscoe 2016),使用传统的n元语言模型生成,尽管随着神经语言模型的引入,语言建模已经得到了极大的改进(Mikolov等人2011年)。
本研究的目的是双重的。首先,我们提出了一种新的方法来衡量可读性,考虑了神经语言模型统计。这种方法是无监督的,不需要标记的训练集,只需要来自给定域的文本集合。我们证明,由于神经网络的可训练性,以及它可以跨不同语言转移,所提出的方法能够将可读性上下文化。在此范围内,我们提出了一种新的可读性度量方法,即句子可读性评分排序,与真实可读性评分具有良好的相关性。
其次,我们通过实验发现了如何使用具有自动化特征生成的不同神经结构进行可读性分类,并将其性能与最先进的分类方法进行了比较。在四个黄金标准可读性语料库上对神经网络结构的三个不同分支——回归神经网络(RNN)、分层注意网络(HAN)和迁移学习技术——进行了测试,取得了良好的效果。
文章结构如下。第2节介绍了关于可读性预测的相关工作。第3节提供了在我们的实验中使用的数据集的全面分析,在第4节,我们提出的方法和结果的可读性预测的非监督方法。第5节介绍了监督方法的方法和实验结果。我们在第6节中给出了结论和进一步工作的方向。
2. Related Work
自动测量可读性的方法试图找到和评估与人类对可读性的感知相关的因素。过去已经提出了几个衡量可读性不同方面的指标,并在第2.1节中介绍。这些测量方法被用作新方法的特征,这些新方法在带有人类注释的可读性水平的文本上训练机器学习模型,以便它们能够预测新的未标记文本的可读性水平。依赖于大量手工设计特性的方法在第2.2节中进行了描述。最后,第2.3节介绍了使用神经分类器处理可读性预测的方法。除了将可读性作为一个分类问题来处理之外,过去还提出了其他几种用于可读性预测的监督统计方法。它们包括回归(Sheehan et al. 2010) ,支持向量机分类(SVM)排序(Ma,FoslerLussier,and Lofthus 2012) ,以及基于图的方法(Jiang,Xun,and Qi 2015)等等。我们在相关的工作中不包括这些方法,因为它们与所提议的方法没有直接关系。
2.1可读性特性
经典的可读性指标大致可以分为五个不同的群体:传统的、语篇衔接的、词汇语义的、句法的和语言模型的特征。我们在下面描述它们。
2.1.1 传统特性
传统上,文本的可读性是通过统计可读性公式来衡量的,该公式试图构建一个简单的人类可理解的公式,与人类感知的可读性程度有良好的相关性。其中最简单的是平均句子长度(ASL),尽管他们考虑了各种其他统计因素,如单词长度和单词难度。这些公式大多数最初是为英语开发的,但也适用于其他语言,并进行了一些修改(ˇSkvorc et al. 2019)。
The Gunning FOG Index (Gunning 1952) (GFI)估计了一个人在第一次阅读时理解文本所需的正规教育年限。计算公式如下:
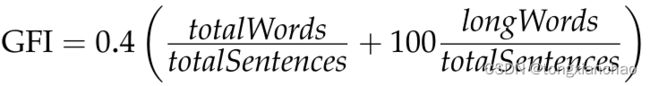
longWords是指超过7个字符的单词。索引值越高,可读性越低。
Flesch reading ease (Kincaid et al. 1975) (FRE) 为更易读的文本赋予更高的值,计算方法如下:

Flesch-Kincaid年级水平(Kincaid et al. 1975) (FKGL)返回的值对应于理解计算公式的文本通常需要的教育年数。公式定义如下:

另一个返回与理解文本所需的教育年数对应的可读性公式是Automated Readability Index (Smith and Senter 1967) (ARI):
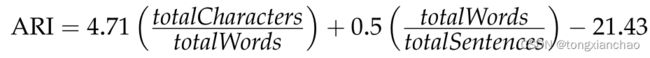
Dale-Chall可读性公式(Dale and Chall 1948) (DCRF)要求一份3000个单词的清单,美国四年级的学生都能真正理解。没有出现在这个列表中的单词被认为是难的。如果没有单词列表,可以使用GFI方法,将所有超过7个字符的单词视为困难。计算时使用以下表达式:
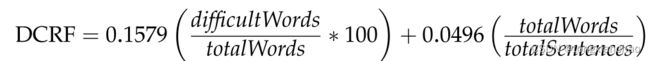
SMOG等级(Simple Measure of Gobbledygook)(McLaughlin 1969)是一个可读性公式,最初用于检查健康信息。与FKGL和ARI类似,它大致相当于理解文本所需的教育年限。计算公式如下:
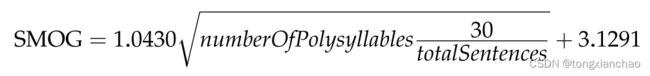
其中numberOfPolysyllables是指有三个或三个以上音节的单词的数量。
我们知道有一项研究探索了这些公式在不同语类之间的可转换性(Sheehan,Flor,and Napolitano 2013) ,还有一项研究探索了跨语言的可转换性(Madrazo Azpiazu and Pera 2020)。Sheehan,Flor 和 Napolitano (2013)的研究得出结论,主要是由于不同语类的词汇特点,传统的可读性测量方法不适合跨语类预测,因为它们低估了文学语篇的复杂程度,高估了教育语篇的复杂程度。另一方面,Madrazo Azpiazu 和 Pera (2020)的研究得出结论,当使用这些公式时,同一文本的翻译的可读性水平预测很少是一致的。
上述所有的可读性测量都是针对英语文本的具体使用而设计的。有一些罕见的尝试,使这些公式适用于其他语言(坎德尔和摩尔斯1958年)或创造新的公式,可用于其他语言以外的语言(安德森1981年)。
为了展示我们的方法的多语言潜力,我们在这项研究中处理了两种语言,英语和斯洛文尼亚语,一种斯拉夫语言,具有丰富的形态学和比英语少数量级的资源,对于斯洛文尼亚语,可读性研究很少。ˇSkvorc等人(2019)研究了上述统计可读性公式对斯洛文尼亚文本的作用,试图将文本从三个不同的来源分类:儿童杂志、成人报纸和杂志,以及斯洛文尼亚国民议会会议记录。这项研究的结果表明,考虑单词和/或句子长度的公式比依赖单词列表的公式效果更好。他们还注意到,简单的可读性指标,如形容词百分比和平均句子长度,在斯洛文尼亚语中效果很好。据我们所知,Zwitter Vitez(2014)是唯一一项对斯洛文尼亚文本使用可读性公式的研究。在该研究中,作者识别任务采用可读性公式作为特征。
2.1.2语篇衔接特征。
在文献中,我们至少可以发现两个不同的语篇衔接概念(Todirascu et al. 2016)。第一个是连贯的概念,定义为“话语的语义属性,基于对每个句子相对于其他句子的解释” (Van Dijk 1977)。先前研究这个概念的研究试图确定一篇文章是否可以被理解为一个连贯的信息,而不仅仅是一组不相关的句子。这可以通过测量文本的某些可观察到的特征来实现,例如实词的重复,或通过分析明确表达连接词的单词(因为,结果,作为结果,等等)(Sheehan et al. 2014)。衔接是一个比较受研究的概念,因为它更容易操作,它被定义为“一种由明确的正式语法联系(话语连接词)和表明话语或更大的文本部分如何相互联系的词汇联系所代表的文本属性”。
根据Todirascu等人(2016)的研究,我们可以将衔接特征分为五类:共指和回指链特征、实体密度和实体衔接特征、词汇衔接指标以及基于词性标签的衔接特征。共指和回指链性质最早由Bormuth(1969)提出,他测量了回指的各种特征。这些特征包括统计,如参考链的平均长度或各种类型的提及(名词短语、专有名词等)在链中的比例。实体密度特性包括统计数据,例如每个文档中所有/唯一实体的总数、每个句子中所有/唯一实体的平均数量,等等。这些特征首先由Feng、Elhadad和Huenerfauth(2009)和Feng等人(2010)提出,他们遵循了Halliday和Hasan(1976)和Williams(2006)的理论路线。实体衔接特征评估相邻句子中同一实体所发挥的句法功能之间可能过渡的相对频率(Pitler和Nenkova, 2008)。词汇衔接测量包括一些特征,比如相邻句子中内容词重复的频率(Sheehan 等人,2014年) ,一个由 Landauer (2011年)提出的基于潜在语义学的测量词汇和段落相似性的特征,或者一个由 Flor,Klebanov 和 Sheehan (2013年)提出的叫做词汇紧密度的测量,定义为文本中所有对的内容词的正规化点间互信息的平均值。最后一类是基于词性标签的衔接特征,用于度量代词和冠词词类的比例,这是衔接的两个关键要素(Todirascu et al. 2016)。
Todirascu等人(2016)分析了可读性文献中发现的65个语篇特征,得出的结论是,与传统的可读性公式或简单的统计数据(如句子长度)相比,它们通常对文本可读性分类器的预测能力贡献不大。
2.1.3词汇语义特征。
Collins-Thompson(2014)认为词汇知识是阅读理解的一个重要方面,词汇-语义特征衡量词汇在文本中的难度。一个常见的特性是类型标记比率(TTR),它度量文本中唯一单词的数量与总单词数量之间的比率。文本长度对TTR有影响;因此,一些产生更公正表示的修正,如Root TTR和Corrected TTR,也被用于可读性预测。
在可读性的分类方法中,其他经常使用的特征是n-gram词汇特征,例如单词和字符n-gram (Vajjala和Meurers 2012;Xia, Kochmar和Briscoe 2016)。基于pos的词汇特征衡量词汇变化(即词汇项的TTR,如名词、形容词、动词、副词和介词)和密度(如内容词和虚词的百分比),基于单词列表的特征使用外部心理语言学和第二语言习得(SLA)资源,它包含了特定年龄或英语学习班级获得的单词和短语的信息。
2.1.4句法功能
句法特征衡量文本的语法复杂性,可以分为几种类型。解析树特性包括解析树的平均高度或每个句子的名词短语或动词短语的平均数量。语法关系特征包括一个句子中成分之间的语法关系的度量,例如解析器生成的语法关系集中的最长/平均距离。句法单位特征的复杂性衡量一个句法单位在句子、从句(任何带有主语和限定动词的结构)和t单位级别(一个主句加上任何从句)的长度。最后, 协调和从属特征衡量句子中协调和从属的数量,包括每个t单位的子句数量或每个子句的协调短语数量等特征
2.1.5语言模型特性。
语言建模的标准任务可以正式地定义为,对于单词wt+1,给定历史序列w1:t = [w1,…wt],从固定大小的词汇V中预测单词的概率分布。为了衡量它的表现,传统上使用了一个称为困惑度的指标。语言模型m的评估是根据它预测单词的单独测试序列w1:N = [w1,…, wN]的效果。对于这种情况,定义语言模型m()的perplexity (PPL)为:

其中 m (wi)是语言模型 m 赋予词 wi 的概率,n 是序列的长度。困惑得分越低,语言模型对文档中单词的预测能力越强,也就是说,语言模型对文档中单词的预测能力越强,并且与文本的训练集越一致。
过去所有使用语言建模的可读性检测方法都利用了较旧的n元语言模型,而不是较新的神经语言模型。Schwarm和Ostendorf(2005)为训练数据集中的每个可读性类c训练一个n-gram语言模型。对于每个文本文档d,他们按照以下公式计算似然比:
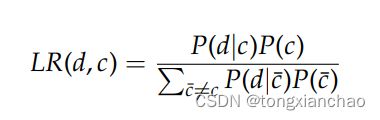
其中 p (d | c)表示语言模型对 c 类标记文本的训练返回的概率,p (d |- c)表示语言模型对 -c 类标记文本的训练返回的概率。假定类的先验概率是统一的。在分类模型中,采用似然比作为特征,同时考虑了所有模型的困惑。
在Petersen和Ostendorf(2009)中,三种统计语言模型(unigram、bigram和trigram)在四种外部数据资源上训练:Britannica(成人)、大英百科全书基本、CNN(成人)和CNN缩略版。得到的12个n元语言模型用于计算每个目标文档的困惑度。假设在成人水平文本上训练的语言模型计算出的困惑度得分较低,而在初级/节略水平上训练的语言模型计算出的困惑度得分较高,说明阅读水平较高。成人水平语言模型的困惑度得分较高,初级/节略水平语言模型的困惑度得分较低,说明阅读水平较低。
Xia, Kochmar和Briscoe(2016)在英国国家语料库上训练1- 5克基于单词的语言模型,在WeeBit语料库的5个类上训练25个基于pos的1- 5克的语言模型。语言模型的对数似然和困惑度作为分类器的特征。
2.2基于特征工程的分类方法
上述方法使用所描述的特性,以一种无监督的方式度量可读性。或者,我们可以以监督的方式预测可读性的级别。这些方法通常需要大量的特性工程,并利用前面描述的许多特性。
Schwarm和Ostendorf(2005)提出了可读性的第一个分类方法。它依靠SVM分类器在WeeklyReader语料库上训练,包含根据目标受众的年龄将文章分成4类。模型中使用了传统的、语法和语言模型特性。该方法在Petersen和Ostendorf(2009)中得到了扩展和改进。
在Vajjala和Luˇci´c(2018)提出的方法中,总共使用了155个传统的、话语衔接、词汇-语义和句法特征,并在最近发布的OneStopEnglish语料库上进行了测试。基于线性核的序次最小优化(SMO)分类器对初级、中级和高级三个阅读水平类别的分类准确率达到78.13%。
Vajjala和Meurers(2012)提出了一种成功的可读性分类方法。他们的多层感知器分类器在WeeBit语料库上训练(Vajjala和Meurers 2012)(参见第3节了解更多关于WeeBit和其他提到的语料库的信息)。根据目标人群的年龄,这些短信被分为五类。对于分类,作者使用了46个手工制作的传统、词汇语义和句法特征。为了进行评估,他们在每个类的500个文档组成的训练集上训练分类器,并在625个文档(每个类包含125个文档)的平衡测试集上测试它。他们报告在测试集上的准确率为93.3%。
另一组实验WeeBit语料库是由夏,Kochmar,和电话(2016),谁的语料库进行了额外的清洁,因为它包含一些文本与破碎的句子和额外的元信息的源文本,如版权声明和链接,强烈与目标标签。他们使用类似Vajjala和Meurers(2012)的词汇、句法和传统特征,但增加了语言建模(详见2.1.5节)和基于话语内聚的特征。通过5倍交叉验证,该SVM分类器的准确率达到80.3%。这是对分类模型的可转让性进行测试的研究之一。作者使用了一个附加的CEFR(欧洲共同语言参考框架)语料库。这个小数据集的cefr分级文本是为英语学习者量身定制的(欧洲委员会2001),还包含5个可读性课程。在WeeBit语料库上训练并在CEFR语料库上测试的SVM分类器的分类准确率达到了23.3%,几乎没有超过大多数分类器的基线。这一低的结果是由于两个语料库在可读性类上的差异,因为WeeBit语料库的目标人群是不同年龄段的儿童,而CEFR语料库的目标人群主要是不同英语理解水平的成年外国人。然而,这一结果强烈表明,可读性分类模型在不同类型的文本之间的可转移性是值得怀疑的。
另外两项研究是由Sheehan, Flor, and Napolitano(2013)和Napolitano, Sheehan, and Mundkowsky(2015)进行的,研究涉及可读性预测的多类型前景。两项研究都在文本评估工具(Sheehan et al. 2010)的背景下描述了这个问题,这是一个用于文本复杂性分析的在线系统。该系统支持多体裁的可读性预测,采用两阶段预测工作流程,首先确定文本的体裁(信息性、文学性或混合性),然后使用相应体裁的可读性预测模型预测文本的可读性水平。与上述研究类似,这项工作也表明,使用分类模型进行跨类型预测是不可行的。
当涉及到多语和跨语分类时,Madrazo Azpiazu和Pera(2020)探索了跨语可读性评估的可能性,并表明他们的方法称为CRAS(跨语可读性评估策略),其中包括构建一个分类器,使用一套传统的词汇-语义,句法,基于话语内聚的特征在多语言环境下也很有效。它们还表明,通过将不同语言的文档包含到特定语言的序列集中,可以改进一些低资源语言的分类。
2.3神经分类方法
近年来,人们提出了几种基于神经网络的可读性预测方法。Nadeem和Ostendorf(2018)在WeeBit语料库回归任务上测试了两种不同的架构,即基于注意机制的顺序门控循环单元(GRU) (Cho et al. 2014)和具有两种不同注意类型的分层RNN (Yang et al. 2016):Bahdanau、Cho和Bengio(2014)提出的更经典的注意机制,以及Vaswani等人(2017)提出的多头注意机制。研究结果表明,分级rnn的性能普遍优于顺序rnn。Nadeem和Ostendorf(2018)还表明,神经网络可以很好地替代更传统的基于特征的模型,用于预测短于100字的文本的可读性,但在较长的文本上不能表现出竞争力。
Azpiazu和Pera(2019)提出了另一种带有注意机制的分层RNN。他们的系统名为V ec2Read,是一种多注意RNN,能够利用分层文本结构,借助单词和句子级别的注意机制和自定义的聚合机制。他们在多语言环境中使用该网络(语料库包含巴斯克语、加泰罗尼亚语、荷兰语、英语、法语、意大利语和西班牙语文本)。他们的结论是,尽管用于训练的实例数量对系统的整体性能有很强的影响,但没有出现特定于语言的模式,表明预测某些语言的可读性比其他语言更难。
一个更近期神经可读性分类的方法清洗WeeBit语料库(夏、Kochmar和电话2016)提出了Filighera, Steuer,和仁瑟(2019),测试了一组不同的嵌入模型,word2vec (Mikolov et al . 2013),外露的常见的爬行手套(曼宁Socher彭宁顿,2014),ELMo (Peters等人2018年)和BERT (Devlin等人2019年)。将嵌入信息输入到循环神经网络或卷积神经网络中。他们工作中提出的基于bert的方法与本工作中提出的基于bert的监督分类方法有些相似。但是,一个主要的区别是,在他们的实验中没有对BERT模型进行微调(即在预训练好的BERT语言模型上进行嵌入的提取)。他们最好的基于elmo的双向LSTM模型在开发集上实现了79.2%的精度,略低于Xia、Kochmar和Briscoe(2016)在5倍交叉验证场景中实现的80.3%的精度。然而,他们确实通过对所有模型的综合,提高了技术水平,实现了81.3%的准确性,宏观f1平均得分为80.6%。
Mohammadi和Khasteh(2019)提出了一种有点不同的神经方法来进行可读性分类,他们使用深度强化学习来解决这个问题,或者更具体地说,使用深度卷积循环双对抗性Q网络(Wang et al. 2016),使用5个相邻单词的有限窗口。为了消除复杂的自然语言特征,我们使用手套嵌入和统计语言模型来表示输入文本。该模型用于多语言设置(英语和波斯语数据集),并在所有数据集上取得了与目前水平相当的性能,其中也在Weebit语料库上(准确率为91%)
最后,Deutsch Jasbi 和 Shieber (2020)最近的一项研究使用 HAN 和 BERT 模型的预测作为支持向量机模型的附加特征,同时使用了一组句法和词汇语义特征。虽然他们设法提高了他们的支持向量机分类器的性能与额外的神经特征,他们的结论是,额外的句法和词汇语义特征一般不提高预测的神经模型。
3.数据集
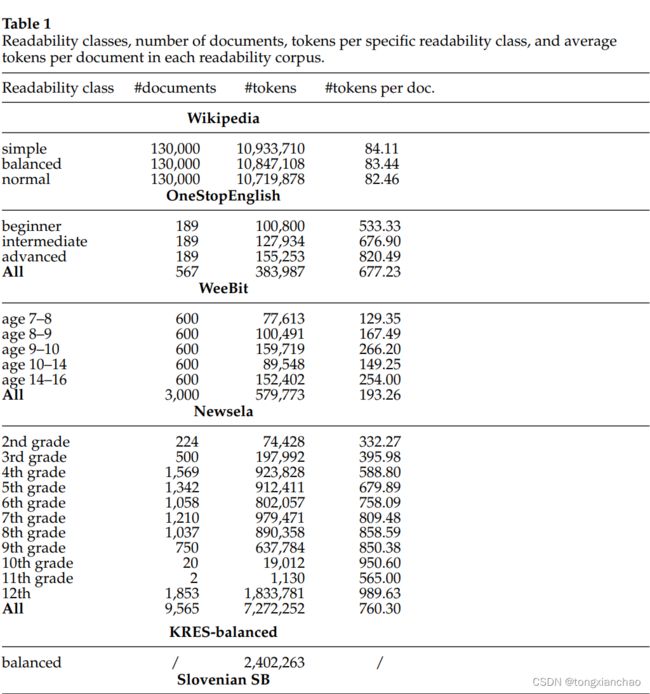
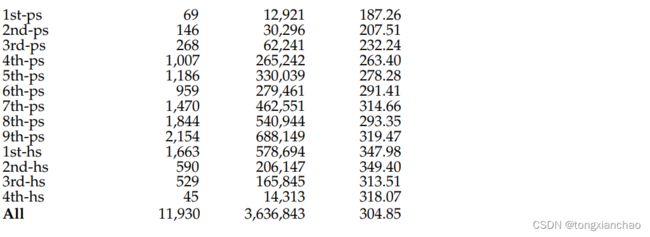
在本节中,我们首先介绍实验中使用的数据集(第3.1节),然后进行初步分析(第3.2节),以评估拟议实验的可行性。数据集统计数据如表1所示。
3.1数据集展示
所有实验均在四个标注可读性分数的语料库上进行:
WeeBit语料库:WeeklyReader3和BBC-Bitesize4的文章根据他们的目标年龄段被分为五类。班级分为7-8岁、8-9岁、9-10岁、10-14岁和14-16岁年龄组。三个面向年轻读者的课程由《每周读者》(WeeklyReader)的文章组成,这是一份教育报纸,涵盖了从科学到时事的广泛非虚构话题。有两个针对老年受众的课程由BBC-Bitesize网站上的材料组成,其中包含的教育材料分类为与英国学校主题大致匹配的主题。在Vajjala和Meurers(2012)的原始语料库中,类平衡,语料库共包含3125个文档,每个类625个。在我们的实验中,我们遵循了Xia, Kochmar和Briscoe(2016)的建议来修复破碎的句子,并删除额外的元信息,如版权声明和链接,与目标标签强相关。我们按照Xia, Kochmar,和Briscoe(2016)中描述的程序从HTML文件中重新提取语料库,并在提取和清洗过程中由于缺少内容而丢弃了一些文档。我们实验中使用的最终语料库总共包含3000个文档,每个班600个。
OneStopEnglish语料库(Vajjala和Luˇci´c 2018)包含三个不同阅读水平(初级、中级和高级)的一致文本,是专门为英语为第二语言(ESL)学习者编写的。该语料库是2013-2016年期间从语言学习资源onestopenglish.com的每周新闻课程部分编译的。该部分包含了来自《卫报》的文章,由英语教师重写,针对三个层次的成人ESL学习者(初级、中级和高级)。总的来说,与文档对齐的并行语料库由189个文本组成,每个文本以三个版本(总共567个)编写。该语料库是免费的
Newsela语料库(Xu, Callison-Burch, and Napoles 2015):我们使用2016年1月29日的语料库版本,共有10786个文档,其中我们只使用了9565个英语文档。语料库包含1911篇英语原版新闻文章,每篇原创文章最多有4个简化版本,也就是说,每篇原创新闻文章都被Newsela的编辑手工重写了多达4次,Newsela是一家生产大学预科课堂阅读材料的公司,,以不同年级的儿童为目标,并帮助教师准备与每个年级所需的英语语言技能相匹配的课程。该数据集是一个文档对齐的平行语料库,由原始版本和简化版本组成,总共对应11个不同的不平衡年级水平(从2年级到12年级)。
斯洛文尼亚教科书语料库(斯洛文尼亚SB):为了测试所提方法对其他语言的可移植性,我们编制了斯洛文尼亚教科书语料库。该语料库收录了小学9个年级和中学4个年级的125本教科书中的3639665个单词。它的创建有几个目的,比如研究学校书籍的不同质量方面,提取术语和语言分析。该语料库包含16种不同学科的学校书籍,从文学、音乐、历史到数学、生物和化学,主题非常不同,但比例不相等,其中读者是学校书籍的最大类型。
虽然有些文本是从Gigafida的斯洛文尼亚书面参考语料库中提取的(Logar et al. 2012),但大多数文本是从PDF文件中提取的。提取后,我们首先对提取的文本进行一些轻微的手工清理(删除索引、版权声明、引用等)。接下来,为了去除额外的干扰(提示、方程等),我们应用了一个过滤脚本,该脚本依赖于手工编写的句子提取规则(例如,如果文本以大写字母开头,以句子结尾的标点符号结束,那么文本就是一个句子),从而只获得包含句子的段落。最终提取的文本没有结构信息(具体章节在哪里结束或开始,哪些句子构成一个段落,哪里有问题,等等),因为标记文档结构将需要大量的手工工作;因此我们在本研究中没有尝试。
在监督分类实验中,我们将教科书分成25个句子长的块,以建立一个具有足够数量文档的训练集和测试集。选择25个句子的长度是由于BERT分类器的大小限制,它可以被输入包含多达512字节对标记的文档(Kudo和Richardson 2018),翻译过来平均不到25句话。
语言模型是在大量文本语料库上训练的。为此,我们使用了以下语料库。
英语维基百科语料库和简单维基百科文章语料库:我们创建了三个语料库,用于我们的无监督英语实验:
- Wiki-normal包含从维基百科转储中随机选择的13万篇文章,其中包括489,976个句子和10,719,878个标记。
- Wiki-simple包含从Simple Wikipedia转储中随机选择的13万篇文章,其中包括654,593个句子和10,933,710个令牌。
- Wiki-balanced包含从维基百科转储(日期为2018年1月26日)中随机选择的65000篇文章和从简单维基百科转储中随机选择的65000篇文章。语料库共有571,964个句子和10,847,108个令牌。
KRES-balanced: KRES语料库(Logar et al. 2012)是一个1亿字平衡的斯洛文尼亚语参考语料库:35%的内容是书籍,40%的期刊,20%的网络文本。从这个语料库中,我们从两份儿童杂志(Ciciban和Cicido)、四份青少年杂志(Cool、Frka、PIL plus和Smrklja)和三份针对成人受众的杂志(ˇZivljenje in tehnika、Radar、City magazine)中提取了所有可用的文档。用这些文本,我们建立了一个大约240万单词的语料库。语料库在某种意义上是平衡的,大约三分之一的句子来自针对儿童的文件,三分之一是针对青少年的,最后三分之一是针对成年人的。
3.2数据集分析
总的来说,我们的数据集有几个不同之处:
•语言:如前所述,我们有三个英语(Newsela, OneStopEnglish和WeeBit),和一个斯洛文尼亚语(斯洛文尼亚SB)测试数据集。
•平行语料库vs.非对齐语料库:Newsela和OneStopEnglish数据集是平行语料库,这意味着来自不同可读性类的文章在语义上彼此相似。另一方面,WeeBit和斯洛文尼亚SB数据集在每个可读性类中包含完全不同的文章。尽管这可能不会影响不考虑语义信息的传统可读性度量,但它可能会对分类器的性能和拟议的基于语言模型的可读性度量产生实质性的影响。
•文档长度:Newsela和OneStopEnglish数据集与WeeBit和Slovenian SB数据集的另一个区别是数据集文档的长度。Newsela和OneStopEnglish数据集包含较长的文档,平均约为760和677个单词,WeeBit和斯洛文尼亚SB语料库中的文档平均分别约为193和305个单词
•类型:OneStopEnglish和Newsela数据集包含新闻文章,WeeBit由教育文章组成,斯洛文尼亚SB数据集由学校书籍组成。对于英语语言模型的训练,我们使用Wikipedia和Simple Wikipedia,其中包含百科全书的文章,对于斯洛文尼亚语言模型的训练,我们使用kres平衡语料库,其中包含杂志文章。
•目标受众:OneStopEnglish是唯一一个专门针对成人ESL学习者的测试数据集,而不是儿童,其他测试数据集也是如此。对于用于语言模型训练的数据集,KRES-balanced语料库由针对成人和儿童的文章组成。Wikipedia和Simple Wikipedia的问题在于没有针对特定的目标受众,因为文章都是由志愿者撰写的。事实上,使用简单的维基百科作为简化算法的训练数据集被批评在过去,因为它缺乏具体的简化原则,这是只基于简单的创建维基百科的声明书”的儿童和成年人学习英语”(徐,卡利森-伯奇和那不勒斯2015年)。缺乏质量的指南也有助于减少简化根据徐,凯里森,和Napoles(2015),他发现语料库可以吵,一半的句子也不是实际的简化,而是通过模仿原维基百科。
数据集的多样性限制了该研究提供跨类型、语言或数据集的普遍结论的雄心。另一方面,它提供了一个机会来确定每个数据集的细节如何影响每个建议的可读性预测器,并确定所应用方法的总体稳健性。
尽管不同的数据集在许多方面有所不同,但是所有的数据集也有一些共同的特征,这些特征允许在所有数据集上使用相同的预测方法。它们大多与构建可读性数据集时使用的常见技术有关,无论特定数据集的语言、类型或目标受众是什么。并行简化语料库(如Newsela、OneStopEnglish和Simple Wikipedia)的创建通常涉及三种技术:分裂(将长句子拆成短句子)、删除(删除句子中不重要的部分)和释义(通过重新排序、替换、偶尔扩张)(冯轲2008)。尽管其中可能涉及一些微妙之处(因为对于一种类型的用户来说,构成简化的内容可能不适用于另一种类型的用户),但如何应用这些技术是相当普遍的。此外,虽然在非平行语料库(WeeBit,斯洛文尼亚SB)中没有使用简化,但贡献作者仍被指示为特定目标群体编写文本,并相应地调整写作风格。在大多数情况下,这导致了相同的结果(例如,更短、更简单的句子和更简单的词汇,用于面向年轻或口语不流利的听众)。
数据集之间的共性的主张可以通过这样一个事实得到支持,即即使是传统的可读性指标也与人类指定的可读性相当相关,无论每个数据集的具体类型、语言或目的是什么。表2通过展示第2.1.1节中传统可读性公式的可读性得分证明了这一点。我们可以看到,所有数据集和所有指标的难度都在增加——可读性分数越大(或者在FRE的情况下,分数越小),这些数据集中包含为年龄较大的儿童或更高水平的ESL学习者编写的文本。这表明,即使只采用传统的浅层可读性指标,对选定的数据集进行多数据集、多类型甚至多语言的可读性预测也是可行的。
然而,结果确实表明,跨类型甚至跨数据集的可读性预测可能存在问题,因为根据浅层预测公式(以及基础真理可读性标签),数据集覆盖的可读性范围并不相同。例如,WeeBit 14-16岁年龄组的文档得分与Newsela 6年级的文档非常相似,这意味着在WeeBit语料库上训练的分类器可能很难对Newsela等级较高的文档进行分类,因为根据所有的浅层可读性指标,这些文档的可读性都低于WeeBit语料库中最复杂的文档。出于这个原因,我们选择不进行任何有监督的跨数据集或跨类型实验。尽管如此,跨类型预测的问题在提出的无监督实验的背景下是重要的,因为用于训练语言模型的数据集和模型使用的数据集之间的类型差异可能会影响提出的基于语言模型的测量的性能。第4.2节对此主题进行了更详细的讨论。

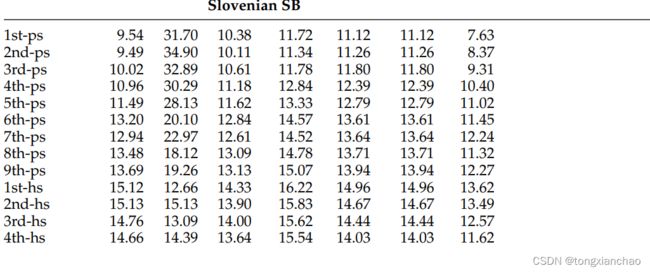
表2的分析也证实了Madrazo Azpiazu和Pera(2020)的发现,他们表明用浅显的可读性指标进行跨语言可读性预测是有问题的。例如,如果我们比较Newsela语料库和斯洛文尼亚语SB语料库,它们都涵盖了大致相同的年龄组,我们可以看到,对于一些可读性指标(FRE、FKGL、DCRF和ASL),它们的值是完全不同的尺度。
4. 无监督神经的方法
在本节中,我们将探讨如何使用神经语言模型以无监督的方式确定文本的可读性。在4.1节中,我们介绍了实验中使用的神经结构;在第4.2节中,我们描述了拟议方法的方法论;在第4.3节中,我们介绍了所进行的实验。
4.1神经语言模型架构
Mikolov 等人(2011年)已经证明,神经语言模型在大型和相对较小(少于100万个标记)的数据集上的高边际优于 n-gram 语言模型。在困惑方面取得的差异(见公式(1))归因于神经网络可以获得更丰富的历史上下文信息,而不像 n-gram 语言模型那样局限于一个小的上下文窗口(通常最多5个前置词)。在2.1.5节中,我们提到了一些使用 n 元语言模型进行可读性预测的方法。然而,我们不知道有任何方法可以使用深层神经网络语言模型来确定文本的可读性。
在本研究中,我们利用三种神经架构进行语言建模。首先是rnn,它适用于对序列数据建模。在每一个时间步长t,输入向量xt和隐状态向量ht−1被送入网络,产生下一个隐向量状态ht,递归方程如下:
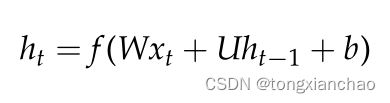
其中f为非线性激活函数,W和U为输入层和隐层的权值矩阵,b为偏置向量。使用普通rnn学习远程输入依赖是有问题的,因为梯度消失(Bengio, Simard和Frasconi 1994);因此,在实践中,改进的循环网络,如长短期记忆网络(LSTMs)被使用。在我们的实验中,我们使用了Kim等人(2016)提出的基于lstm的语言模型。通过利用额外的字符级卷积神经网络(CNN),该架构适用于形态学丰富的语言建模,例如斯洛文尼亚语言。卷积层学习单词的字符结构,并连接到基于lstm的层,该层在单词级产生预测。
Bai, Kolter和Koltun(2018)引入了一种新的基于卷积的序列建模架构,称为时间卷积网络(TCN),我们的实验中也使用了该架构。TCN使用因果卷积操作,确保从未来时间步到过去没有信息泄漏。TCN接受一个序列作为输入,并将其映射到相同大小的输出序列,这使得该体系结构适合于语言建模。通过使用非常深入的网络体系结构和扩展的卷积层次结构,tcn能够利用长上下文。对于1维序列x的s元,可以定义一个单独的扩张卷积运算F,公式如下:
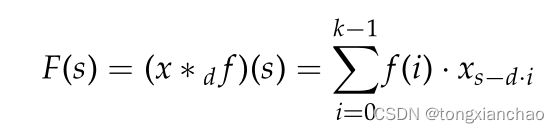
其中f: 0,…K−1为大小为K的滤波器,d为膨胀因子,s−d·I表示过去的方向。这样,在预测过程中考虑的背景可以通过使用更大的过滤器尺寸和增加膨胀系数来增加。最常见的做法是随着网络深度的指数增加膨胀系数。
最近,Devlin等人(2019)提出了一种新的语言建模方法。他们的BERT同时使用了左右上下文,这意味着序列中的单词wt不仅仅是由其左序列w1:t−1 = [w1,… wt−1]]决定的。也从其右字序列wt+1:n = [wt+1,…wt + n]。这种方法引入了一个新的学习目标,一个屏蔽语言模型,其中从输入的单词序列中随机选择的单词的预定义百分比被屏蔽,目标是从未屏蔽的上下文中预测这些被屏蔽的单词。BERT使用变压器神经网络架构(Vaswani et al. 2017),它依赖于自我注意机制。这种方法的显著特点是使用了几个并行的注意层,即所谓的注意头,这减少了计算成本,并允许系统同时注意几个依赖项。
所有类型的神经网络语言模型,TCN、LSTM和BERT,输出整个词汇表上计算的softmax概率分布,并给出每个单词的历史序列(以及BERT和未来序列)的概率。这些网络的训练通常最小化训练语料词序列w1:n = [w1,…]的负对数似然(NLL)。通过时间反向传播:
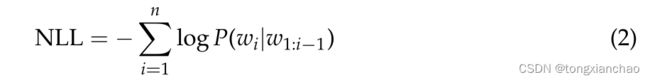
在BERT情况下,最小化NLL的公式也使用了右字序列:
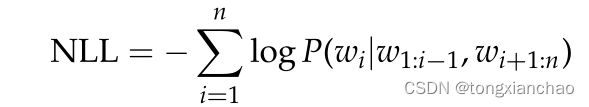
其中,wi是蒙面词。
下式用于测量神经语言模型的困难,定义了困难 (PPL,见式(1))和NLL(见式(2))之间的关系:
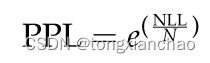
4.2无监督方法
我们希望在无监督方法中调查的两个主要问题如下:
•独立的神经语言模型可以用于无监督的可读性预测吗?
•我们能否开发一个强大的新的可读性公式,不仅依靠浅显的词汇复杂度指标,而且依靠神经语言模型统计数据,从而超越传统的可读性公式?
4.2.1非监督可读性评估的语言模型。
相关研究的结果表明,应该为每个可读性类训练一个单独的语言模型,以便提取特征以成功预测可读性(Petersen和Ostendorf 2009;Xia, Kochmar和Briscoe 2016)。另一方面,我们测试了使用神经语言模型作为独立的无监督可读性预测器的可能性。
支持这种用法的两点是基于这样一个事实: 与传统的 n 元模型相比,神经语言模型倾向于捕获更多的信息。首先,由于以前可读性检测工作中使用的 n-gram 语言模型在大多数情况下仅限于一个最多5个单词的小的上下文窗口,它们的学习潜力仅限于词汇语义信息(例如,关于词汇和文本中 n-gram 结构难度的信息)和关于文本句法的信息。我们认为,由于神经模型更大的上下文信息(例如,BERT 利用了多达512个字节对标记的序列) ,它跨越了句子,神经语言模型也学习了高层次的文本属性,例如长距离依赖关系(Jawahar,sacot,和 Seddah 2019) ,以便在训练期间最小化 NLL。其次,在过去的可读性研究中,n 元模型只是在后来使用的语料库(或者更具体地说,语料库的某些部分)上进行了训练。相比之下,通过在大型通用语料库上训练神经模型,模型还可以学习语义信息,当模型用于较小的测试语料库时,语义信息可以被传递。这种知识转移的成功在某种程度上取决于训练语料库和测试语料库的体裁兼容性。
支持神经语言模型更大灵活性的第三点依赖于这样一个事实:没有哪个语料库是由可读性完全相同的单元(即句子、段落和文章)组成的整体文本块。这意味着在大型语料库上训练的语言模型将暴露在不同复杂程度的文本块中。我们假设,由于这一事实,模型将在某种程度上能够区分这些级别,并为更标准、可预测(即可读)的文本返回较低的困惑。反之,晦涩难懂的语言结构和词汇量会对语言模型的性能产生负面影响,表现为较高的困惑度分数。如果这个假设是正确的,那么理想情况下,训练语料库的平均可读性应该位于测试语料库可读性谱的中间位置。
为了测试这些语句,我们在第3节中描述的Wiki-normal、Wiki-simple和Wiki-balanced语料库上训练语言模型。为了确保训练集的大小不影响实验结果,所有三个Wiki语料库包含的文本量大致相同。我们期望的结果如下:
•假设1:在可读性适合测试语料库可读性谱的中间位置的语料库上训练语言模型,将产生语言模型的性能和可读性之间的最佳相关性。根据第3.2节对我们的语料库进行的初步分析和表2的分析结果,可以在三种情况下实现这种理想的情景:(1)如果使用语言模型训练Wiki-simple Newsela全集,(2)如果一个语言模型训练使用Wiki-balanced语料库OneStopEnglish语料库,和(3)如果模型训练KRES-balanced语料库在斯洛文尼亚某人使用语料库,尽管这些语料的类型不匹配。
•假设2:仅在成人文本(Wiki-normal)上训练的语言模型在儿童文本(WeeBit和Newsela)上表现出更高的困惑,因为他们的训练集不包含这类文本;这将对语言模型的性能和可读性之间的相关性产生负面影响
•假设3:仅在儿童文本(Wiki-simple语料库)上训练语言模型,当应用于成人文本(OneStopEnglish)时,语言模型的困惑度分数会更高。这将对语言模型的性能和可读性之间的相关性产生积极的影响。然而,该语言模型不能可靠地区分不同水平的成人ESL学习者的文本,这将对相关性产生负面影响。
为了进一步测试非监督语言模型作为可读性预测器的可行性,以及测试使用单一语言模型的局限性,我们还探讨了在大型通用语料库上训练语言模型的可能性。英语 BERT 语言模型是基于大型语料库(Google Books Corpus [ Goldberg and Orwant 2013]和维基百科)的3300万个单词,其中大部分是成人英语使用者的文本。根据假设2,这将对模型的性能和可读性之间的相关性产生负面影响。
由于BERT模型规模大,训练语料库庞大,训练过程中获得的语义信息比我们在较小语料库上训练模型获得的语义信息要大得多。这意味着BERT模型更有可能是在与测试语料库内容相似的语义文本上进行训练的,并且这一信息能够成功传递。然而,问题仍然存在,BERT的训练语料库到底包含什么类型的语义内容?一种假设是,它的训练语料库包含更多针对成人受众的内容,而针对儿童的语料库中的内容较少。这将对模型性能与WeeBit语料库可读性之间的相关性产生负面影响。相反,由于WeeBit语料库中可读性最高的两个类包含了来自不同科学领域用于高中教育的文章,可以包含相当具体和技术性的内容,在一般训练语料库中不太可能常见,这可能会影响模型性能和可读性之间的正相关关系。另一方面,Newsela和OneStopEnglish是平行语料库,这意味着所有类的语义内容非常相似;因此,语义迁移的成功或失败很可能不会影响这两个语料库。
4.2.2句子可读性评分排序。
基于以下两点考虑,我们提出了一种新的句子可读性分级评分(rsrs),用语言模型来衡量句子的可读性。
•浅层词汇复杂度指标,如句子的长度,与文本的可读性密切相关。将它们与语言模型的统计数据结合使用,可以改善无监督可读性预测。
•用于衡量语言模型性能的困惑度分数是预测序列中单词困惑度的未加权总和。实际上,少量不可读的单词可能会大大降低整个文本的可读性。为这些词分配更大的权重可能会改善语言模型得分与可读性的相关性。
建议的可读性评分按以下步骤计算。首先,使用NLTK库中的默认句子标记器将给定的文本分割成句子(Bird和Loper 2004)。为了获得特定上下文中每个单词的可读性估计,我们对句子中的每个单词按照以下公式计算单词负对数似然(WNLL):
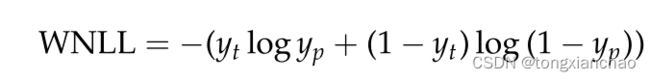
yp 表示语言模型根据历史顺序所预测的概率(来自 softmax 分布) ,yt 表示句子中某个特定位置的经验分布,即 yp 表示顺序中实际出现的词汇中单词的值1,yt 表示词汇中所有其他单词的值0。接下来,我们根据所有单词的 WNLL 得分按升序排列句子中的所有单词,然后用下面的表达式计算排序后的句子可读性得分(RSRS) :

其中S表示句子长度,i表示单词在句子中根据其WNLL值的排名。√排名这个词用于按比例加权词根据其可读性,因为最初的实验表明,使用√排名代表之间的最佳平衡允许所有单词,句子的整体可读性是一样的,只允许至少可读的单词影响句子的整体可读性。对于词汇外的单词,平方根排名权重增加一倍,因为在我们看来,这些罕见的单词是不标准文本的良好指标。最后,为了得到整个文本的可读性得分,我们计算文本中所有RSRS得分的平均值。图1显示了如何为特定句子计算RSRS的示例。

RSRS 分数背后的主要思想是避免传统可读性公式的简化。我们的目标是通过基于神经语言模型的统计学,包括高层次的结构和语义信息。第一个假设是复杂的语法和词汇结构损害了语言模型的表现。由于我们为每个单词计算的 WNLL 得分取决于单词出现的上下文,因此出现在更复杂的语法和词汇上下文中的单词具有更高的 WNLL。第二个假设是,可读性计算中包含了语言模型语义信息: 语义与语言模型训练集中的文档不同的测试文档将对语言模型的性能产生负面影响,导致语义未知的单词的 WNLL 得分较高。语言模型的可训练性允许针对特定任务、主题和语言定制和个性化 RSRS。这意味着 RSRS 将缓解传统可读性公式的文化不可传递性问题。
另一方面,RSRS还通过索引加权方案利用了浅层词汇复杂性指标,这确保可读性较低的单词在整体可读性得分中贡献更多。这有点类似于传统的可读性公式(如GFI和DCRF)中长而难的单词的计数。句子较长的文本的RSRS值也会增加,因为随着句子长度的增加,单词秩权重的平方根会变大。这与传统公式(如GFI、FRE、FKGL、ARI和DCRF)的行为类似,在这些公式中,通过将总单词数和总句子数之间的比例合并到方程中来实现这种效果。
4.3无监督实验
对于提出的基于神经语言模型的无监督可读性评估方法,我们首先给出了实验设计,然后给出了结果。
4.3.1实验设计。
三种不同的语言体系结构模型(4.1节)中描述用于实验:时间卷积网络(TCN)提出的呗,科特勒,和Koltun(2018),复发性语言模型(那么使用RLM)使用字符级CNN和LSTM金提出的et al .(2016),和一种引起语言模型,伯特(Devlin et al . 2019年)。在英语语言实验中,我们使用三个Wiki语料库对TCN和RLM进行训练。
为了探索使用在一般语料库上训练的语言模型进行无监督可读性预测的可能性,我们使用bert -base-uncase英语语言模型,一个在BooksCorpus (0.8G单词)(Zhu et al. 2015)和英语Wikipedia (2.5G单词)上训练的预训练的无大小写语言模型。在斯洛文尼亚语实验中,仅包含教科书的语料库太小,无法有效训练语言模型;因此TCN和RLM仅在章节3中描述的kres平衡语料上训练。为了探索使用通用语言模型进行无监督可读性预测的可能性,使用了一个预先训练的CroSloEngual BERT模型,该模型训练自斯洛文尼亚语(1.26G单词)、克罗地亚语(1.95G单词)和英语(2.69G单词)(Ulˇcar和Robnik-ˇSikonja 2020)三种语言的语料库。用于训练模型的语料库是新闻文章和一般Web抓取的混合体。
语言模型的性能通常用困惑度来衡量(见公式(1))。为了回答独立语言模型是否可以用于无监督的可读性预测的研究问题,我们调查了语言模型的测量困惑度如何与第3节中描述的黄金标准WeeBit、OneStopEnglish、Newsela和斯洛文尼亚SB语料库中的可读性标签相关。与这些地面真实度标签的相关性也被用来评估RSRS测量的性能。为了进行性能比较,我们为黄金标准语料库中的每个文档计算传统的可读性公式值(见第2节),并测量这些值与手动分配的标签之间的相关性。作为基准,我们使用每个文档的平均句子长度(ASL)。
相关性是用皮尔逊相关系数(ρ)来测量的。给定一对分布X和Y,协方差cov和标准差σ, ρ的公式为:

更大的正相关意味着除FRE可读性指标外的所有指标的性能都更好。由于这个公式给可读性更好的文本分配了更高的分数,更大的负相关表明FRE测量的更好的表现。
4.3.2实验结果
实验结果如表3所示。表4列出了英语和斯洛文尼亚数据集上的测量值排名。
所有测量的相关系数在不同语料库之间差异很大。最高的ρ值是在Newsela语料库上获得的,其中最好的性能测量(令人惊讶的是,这是我们的基线-平均句子长度)达到了0.906的ρ值。其他两个英语语料库的最高ρ值要低得多。在WeeBit语料库上,采用GFI和FKGL度量,ρ值为0.544;在OneStopEnglish语料库上,采用TCN RSRS-simple度量,ρ值为0.615。在斯洛文尼亚SB上,ρ值更高,最好的测量方法是TCN RSRS得分平衡,ρ值为0.789。
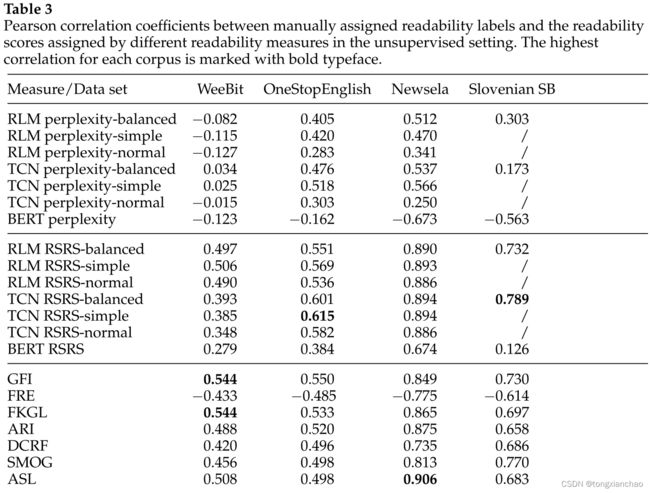
困惑为基础的措施显示了一个低得多的相关性与真值可读性得分。总的来说,它们在两种语言中的表现最差(见表4) ,但是我们可以观察到它们在不同语料库中的表现有很大差异。尽管这三种语言模型的困惑与 WeeBit 语料库的可读性之间不存在相关性或低度负相关性,但是在OneStopEnglish 和 Newsela 语料库上,RLM 和 TCN 所获得的困惑与 WeeBit 语料库的可读性之间存在一定的相关性(在 Newsela 语料库上,TCN 所获得的最高 ρ 为0.566)。在斯洛文尼亚文 SB 语料库中,RLM 和 TCN 的困惑度量和可读性类之间的相关性很低,RLM 的困惑平衡 ρ 为0.303,TCN 的困惑平衡 ρ 为0.173。
然而,WeeBit 语料库上的弱负相关却难以解释,因为同样的分析表明,WeeBit 语料库中包含的复杂文本在所有被测语料库中是最少的,如果这一结果与语义知识的成功转移有关,则支持了 WeeBit 语料库中包含最复杂文本的两类文章具有较复杂的技术内容这一假设。但是,语义迁移的作用也应该减弱对斯洛文尼亚语 SB 的负相关,这是一个非平行语料库,也包含了相当多的针对高中学生的技术教育内容。虽然我们需要进一步的实验和数据来找出结果差异的确切原因,但是我们仍然可以得出结论,使用一个单一的语言模型来为年轻的读者或者英语学习者在无监督的情况下对文本进行可读性预测,至少根据我们的结果,是不可行的。
考虑到我们的期望,语言模型的性能训练的语料库的平均可读性,适合在某个地方的测试语料库的可读性谱中产生最好的相关性与手动标记的可读性得分,这是有趣的看看之间的性能差异 TCN 和 RLM 困惑措施训练的正常,wiki 简单,和 Wiki-balanced 语料库。正如预期的那样,WeeBit 语料库的相关性得分更差,因为该语料库中的所有类包含的文本比任何训练语料库中的文本都要简单。在 OneStopEnglish 语料库中,wiki 简单的困惑度量表现最好,这是出乎意料的,因为我们期望平衡度量表现更好。在新塞拉语料库上,RLM 的困惑均衡性优于 RLM 的困惑均衡性,单纯性优于 RLM 的0.042(出乎意料) ,TCN 的困惑均衡性优于 TCN 的困惑均衡性优于 TCN 的0.029。同时,基于 wiki 简单和 wiki 平衡的困惑度量方法对 OneStopEnglish 和 Newsela 语料库进行了比较,结果表明两种维基常规的困惑度量方法都有较大的优势。对于 RSRS 也可以进行类似的观测,这也利用了语言模型统计。在所有语料库中,wiki 简单 RSRS 度量和 wiki 平衡 RSRS 度量的性能是可比的,这些度量一直优于 wiki 常规 RSRS 度量。
这些结果并不完全符合第4.2.1节中的假设1,即Wiki-balanced度量与OneStopEnglish语料库上的可读性最相关,Wiki-simple度量与Newsela语料库上的可读性最相关。然而,在可读性处于测试语料库可读性谱中间的语料库上训练语言模型似乎是一种有效的策略,因为Wiki-balanced和Wiki-simple度量之间的性能差异不大。另一方面,Wiki-simple的良好的性能措施支持我们的假设3部分4.2.1,准备培训语言模型在文本可读性更接近底部的可读性光谱测试语料库的儿童将导致更高的困惑得分的语言模型应用于成人文本时,这将对可读性的相关性产生积极的影响。
Newsela语料库和OneStopEnglish语料库上的可读性与wiki_simple和wiki_balanced困惑度指标均呈显著正相关,这有力地支持了可读性较低的文本的语言结构和词汇越复杂,其困惑度越高的假设。有趣的是,强相关性也表明语言模型训练和测试集之间的类型差异似乎没有对成绩产生强烈的影响。虽然语言建模的神经体系结构的选择似乎不是那么关键,但语言模型训练集的可读性是最重要的。如果训练集平均包含比测试集中大多数文本更复杂的文本,就像仅在Wiki-normal语料库(以及bert)上训练的语言模型的情况一样,可读性和困惑度之间的相关性消失,甚至得到恢复,由于在更复杂的语言结构上训练的语言模型学会了如何处理这些困难。
困惑测量的低性能表明,神经语言模型统计不是可读性的良好指标,因此不应该单独使用可读性预测。然而,TCN RSRS 和 RLM RSRS 的结果表明,当与其他浅层词汇复杂度指标结合时,语言模型包含了相当有用的信息,特别是当需要对各种不同的数据集进行可读性分析时。
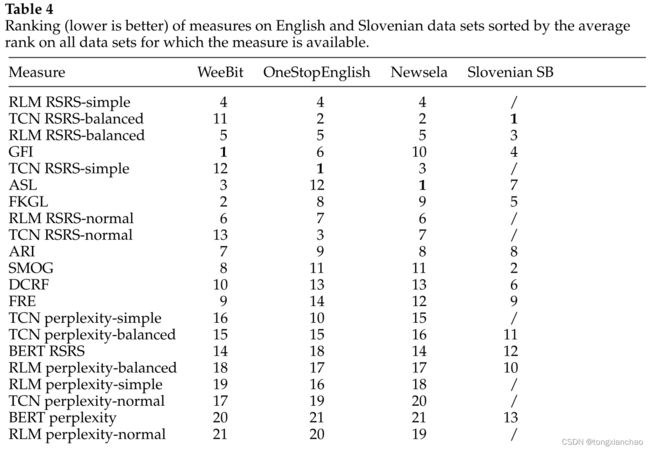
如表4所示,对于不同类型和语言的数据集,浅层可读性预测器会给出不一致的结果。例如,最简单的可读性衡量标准,平均句子长度,在Newsela上排名第一,在OneStopEnglish上排名第十二。它在斯洛文尼亚语料库的表现也不佳,排名第七。另一方面,SMOG在斯洛文尼亚的SB语料库中排名很好(排名2),但在英语语料库中排名第11和第8。在传统的测量中,GFI在性能和一致性方面表现出最好的平衡,在WeeBit排名第一,在OneStopEnglish排名第六,在Newsela排名第十,在斯洛文尼亚SB排名第四。
另一方面,根据表4中的排名,rsrs -简单和rsrs -平衡的度量在不同类型和语言的数据集上提供了更健壮的性能。例如,RLM RSRS-simple量表在所有英语语料库中排名第四。TCN rsrs平衡测量,也被用于斯洛文尼亚SB,在斯洛文尼亚SB排名第一,在OneStopEnglish和Newsela排名第二。然而,它在WeeBit上的表现并不好,因为语言模型训练集和测试集之间的可读性差异太大。RLM RSRS-balanced在所有英语语料库上的一致性较高,排名第五,在斯洛文尼亚语语料库上排名第三。这些结果表明,语言模型统计可以提高各种不同数据集上预测的一致性。该度量的鲁棒性是通过在特定的列车集上训练语言模型来实现的,通过这种训练可以优化针对特定任务和语言的RSRS度量。
5. 监督神经的方法
正如在第1节中提到的,文本分类的最新趋势表明,内部使用自动特征构建的深度学习方法占主导地位。现有的可读性预测神经方法(见第2.3节)倾向于更好地跨数据集和类型一般化(Filighera, Steuer和Rensing 2019),因此依靠广泛的特征工程解决经典机器学习方法的问题(Xia, Kochmar和Briscoe 2016)。
在本节中,我们将分析不同类型的神经分类器如何预测文本的可读性。在5.1节中,我们描述了方法,在5.2节中,我们提出了实验场景和实验结果。
5.1监督方法
我们测试了三种不同的文本分类神经网络方法:
•双向长短时记忆网络(BiLSTM)。我们使用Conneau等人(2017)提出的RNN方法进行分类。BiLSTM层是向前和向后LSTM层的串联,它们从两个相反的方向读取文档。对LSTM输出特征矩阵进行最大和平均池化,得到矩阵的最大值和平均值。得到的向量被串联起来,并输入到负责预测的最终线性层。
•层次注意网络(HAN)。我们使用Yang等人(2016)的架构,在两级注意机制中考虑了文本的层次结构(Bahdanau, Cho和Bengio 2014;Xu et al. 2015)应用于由BiLSTMs编码的单词和句子表示。
•学习转移。我们使用预训练的BERT变压器架构,有12层大小为768和12个自我注意头。在预训练语言模型的基础上增加线性分类头,并对每个数据集进行三个时代的精细调整。对于英语数据集,我们使用BERT-base-uncase英语语言模型,而对于斯洛文尼亚语SB语料库,我们使用在斯洛文尼亚语、克罗地亚语和英语上训练的CroSloEngual BERT模型(Ulˇcar和Robnik-ˇSikonja 2020)
我们将所有语料库随机洗牌,然后将Newsela语料库和Slovenian SB语料库分成队列(80%语料库)、验证(10%语料库)和测试(10%语料库)集。由于OneStopEnglish和WeeBit语料库的文档数量较少(见第3节的描述),为了得到更可靠的结果,我们对这些语料库进行了五次分层交叉验证。每折叠一次,将语料库分为训练集(80%的语料库)、验证集(10%的语料库)和测试集(10%的语料库)。我们使用Scikit StratifiedKFold,都用于训练测试分割和5倍交叉验证分割,以保存每个类别的样本百分比。
BiLSTM和HAN分类器在训练集上训练,每个纪元后在验证集上测试(最多100个纪元)。在验证集上表现最好的模型被选择为最终模型,并在测试集上产生预测。在列车上对BERT模型进行了三个时期的微调,并在测试集上对得到的模型进行了测试。利用验证集进行网格搜索,找出模型的最佳超参数。对于BiLSTM,在选择最佳组合之前,对以下超参数值的所有组合进行了测试,如下表以粗体表示:
• Batch size: 8, 16, 32
• Learning rates: 0.00005, 0.0001, 0.0002, 0.0004, 0.0008
• Word embedding size: 100, 200, 400
• LSTM layer size: 128, 256
• Number of LSTM layers: 1, 2, 3, 4
• Dropout after every LSTM layer: 0.2, 0.3, 0.4
对于HAN,我们测试了以下超参数值的所有组合(最佳组合用粗体表示):
• Batch size: 8, 16, 32
• Learning rates: 0.00005, 0.0001, 0.0002, 0.0004, 0.0008
• Word embedding size: 100, 200, 400
• Sentence embedding size: 100, 200, 400
对于BERT微调,我们使用默认的学习率0.00002。输入序列长度限制为512字节对,这是支持的最大输入序列长度。
我们对所有语料库使用相同的配置,并且没有对语料库的分类器参数进行特定的调整。我们衡量了所有分类器的性能,包括准确性(以便将它们的性能与相关工作中的分类器的性能进行比较)、加权平均精度、加权平均查全率和加权平均f1得分。因为可读性类是序数变量(在我们的例子中,从0到n =类的数量−1),不是所有分类器的错误都是相等的;因此,我们还利用二次加权Kappa (QWK)测度,它允许根据特定错误的成本,对错误预测进行不同的加权。QWK的计算涉及三个矩阵,包括观察分数、基础真实分数和权重矩阵分数,在我们的例子中,权重矩阵分数对应类ci和cj之间的距离d,并被定义为d = |ci−cj|。因此,QWK的计算公式为:
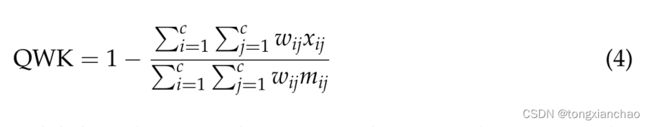
其中c是可读性类的数量,wij、xij和mij分别是权重矩阵、观察矩阵和基本真值矩阵中的元素
5.2监督实验结果
表5展示了使用不同深度神经网络架构的监督可读性评估的结果,以及相关工作(Xia, Kochmar和Briscoe 2016;Filighera, Steuer和Rensing 2019;Deutsch, Jasbi和Shieber, 2020)。我们只提供每个基线研究报告的最佳结果;唯一的例外是Deutsch, Jasbi和Shieber(2020),我们给出了两个结果,SVM- bf (SVM with BERT特征)和SVM- hf (SVM with HAN特征),分别在WeeBit和Newsela语料库上证明是最好的