windows下搭建redis集群
一、什么是集群
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
单个redis存在不稳定性,当redis服务宕机了,就没有可以用的服务了,因为单个redis的读写能力是有限的,所以有了redis集群,基于redis主从复制实现的,主要就是为了强化redis的读写能力。
1 、 redis主从复制
主从复制模型中,有多个redis节点。
其中,有且仅有一个为主节点Master。从节点Slave可以有多个。
只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步。
|
|
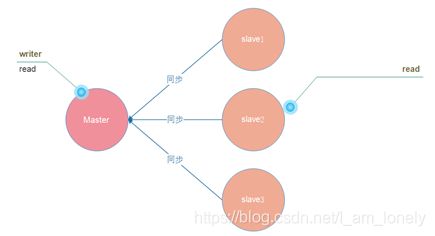
主从模型可以提高读的能力,在一定程度上缓解了写的能力。因为能写仍然只有Master节点一个,可以将读的操作全部移交到从节点上,变相提高了写能力。
2、哨兵模式
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。
(2)主服务器出现故障时自动将从服务器转换为主服务器。
3、Redis-Cluster集群
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
Redis-Cluster采用无中心结构,它的特点如下:
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
数据分布理论
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
常见的分区规则有哈希分区和顺序分区。Redis Cluster采用哈希分区规则
- 节点取余分区
- 一致性哈希分区
- 虚拟槽分区(redis-cluster采用的方式)
顺序分区
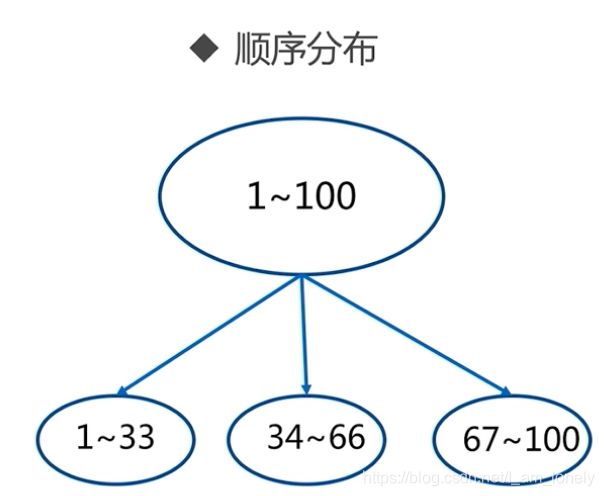
哈希分区

例如按照节点取余的方式,分三个节点
1~100的数据对3取余,可以分为三类
- 余数为0
- 余数为1
- 余数为2
那么同样的分4个节点就是hash(key)%4
节点取余的优点是简单,客户端分片直接是哈希+取余
虚拟槽分区
Redis Cluster采用虚拟槽分区
虚拟槽分区使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,整数定义为槽(slot)。
Redis Cluster槽的范围是0 ~ 16383。
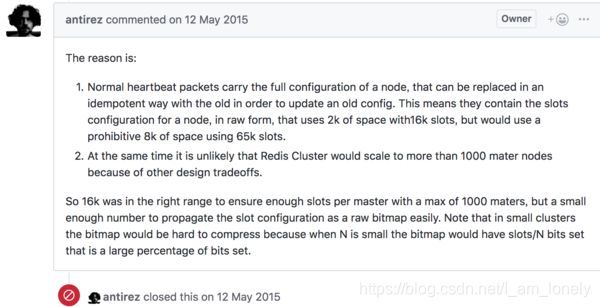
作者原话,关注下。
1、普通心跳数据包携带节点的完整配置,该配置可以用旧配置以幂等方式替换,以便更新旧配置。这意味着它们包含原始形式的节点的槽配置,16k的槽配置需要使用2k内存空间,但是使用65k槽将使用8k的内存空间。
2、同时,由于其他设计折衷,Redis集群不可能扩展到超过1000个节点。
因此,16k是比较合适的,可以确保每个主设备有足够的槽,最大为1000个。redis的node配置信息通过位图存储传输的,传输前有一个压缩过程,压缩比跟槽个数和节点数有很大关系(because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.)【槽数量/节点数】当这个N越大,压缩比就越小。
槽是集群内数据管理和迁移的基本单位。采用大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,
每个节点负责一定数量的槽。
集群进入fail状态的必要条件
A、某个主节点和所有从节点全部挂掉,我们集群就进入faill状态。
B、如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
C、如果集群任意master挂掉,且当前master没有slave.集群进入fail状态
一、什么是集群
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
单个redis存在不稳定性,当redis服务宕机了,就没有可以用的服务了,因为单个redis的读写能力是有限的,所以有了redis集群,基于redis主从复制实现的,主要就是为了强化redis的读写能力。
1 、 redis主从复制
主从复制模型中,有多个redis节点。
其中,有且仅有一个为主节点Master。从节点Slave可以有多个。
只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步。
|
|

主从模型可以提高读的能力,在一定程度上缓解了写的能力。因为能写仍然只有Master节点一个,可以将读的操作全部移交到从节点上,变相提高了写能力。
2、哨兵模式
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。
(2)主服务器出现故障时自动将从服务器转换为主服务器。
3、Redis-Cluster集群
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
Redis-Cluster采用无中心结构,它的特点如下:
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
数据分布理论
分布式数据库首要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整个数据的一个子集。
常见的分区规则有哈希分区和顺序分区。Redis Cluster采用哈希分区规则
- 节点取余分区
- 一致性哈希分区
- 虚拟槽分区(redis-cluster采用的方式)
顺序分区

哈希分区