六、数据结构设计-栈与队列
学习来源:
代码随香炉:https://www.programmercarl.com/
labuladong算法:https://labuladong.github.io/algo/
数据结构设计+栈与队列
单调栈
前三道题的单调栈解法: 单调栈结构解决三道算法题
每日温度(下一个比今天大的温度的,还有几天 )
下一个比今天大的温度的,还有几天 单调栈:从栈顶到栈底 单调递增
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
// 版本一
class Solution {
public:
vector<int> dailyTemperatures(vector<int>& T) {
// 递增栈
stack<int> st; // 栈里面保存的是索引
vector<int> result(T.size(), 0);
st.push(0);
for (int i = 1; i < T.size(); i++) {
if (T[i] < T[st.top()]) { // 情况一
st.push(i);
} else if (T[i] == T[st.top()]) { // 情况二
st.push(i);
} else {
while (!st.empty() && T[i] > T[st.top()]) { // 情况三
result[st.top()] = i - st.top();
st.pop();
}
st.push(i);
}
}
return result;
}
};

下一个更大元素 I

// 版本一
class Solution {
public:
vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
stack<int> st;
vector<int> result(nums1.size(), -1);
if (nums1.size() == 0) return result;
unordered_map<int, int> umap; // key:下标元素,value:下标
for (int i = 0; i < nums1.size(); i++) {
umap[nums1[i]] = i;
}
st.push(0);
for (int i = 1; i < nums2.size(); i++) {
if (nums2[i] < nums2[st.top()]) { // 情况一
st.push(i);
} else if (nums2[i] == nums2[st.top()]) { // 情况二
st.push(i);
} else { // 情况三
while (!st.empty() && nums2[i] > nums2[st.top()]) {
if (umap.count(nums2[st.top()]) > 0) { // 看map里是否存在这个元素
int index = umap[nums2[st.top()]]; // 根据map找到nums2[st.top()] 在 nums1中的下标
result[index] = nums2[i];
}
st.pop();
}
st.push(i);
}
}
return result;
}
};
下一个更大元素 II

// 版本一
class Solution {
public:
vector<int> nextGreaterElements(vector<int>& nums) {
// 拼接一个新的nums
vector<int> nums1(nums.begin(), nums.end());
nums.insert(nums.end(), nums1.begin(), nums1.end());
// 用新的nums大小来初始化result
vector<int> result(nums.size(), -1);
if (nums.size() == 0) return result;
// 开始单调栈
stack<int> st;
for (int i = 0; i < nums.size(); i++) {
while (!st.empty() && nums[i] > nums[st.top()]) {
result[st.top()] = nums[i];
st.pop();
}
st.push(i);
}
// 最后再把结果集即result数组resize到原数组大小
result.resize(nums.size() / 2);
return result;
}
};
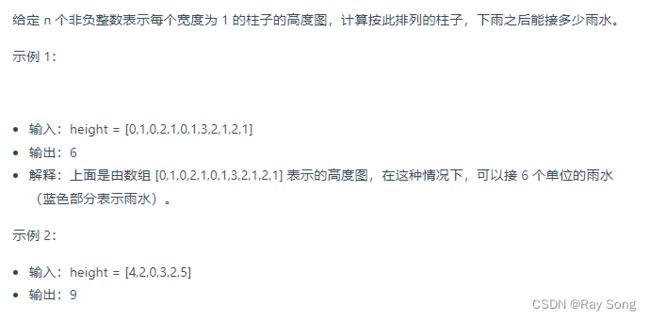
三种解法:
双指针法
class Solution {
public:
int trap(vector<int>& height) {
int sum = 0;
for (int i = 0; i < height.size(); i++) {
// 第一个柱子和最后一个柱子不接雨水
if (i == 0 || i == height.size() - 1) continue;
int rHeight = height[i]; // 记录右边柱子的最高高度
int lHeight = height[i]; // 记录左边柱子的最高高度
for (int r = i + 1; r < height.size(); r++) {
if (height[r] > rHeight) rHeight = height[r];
}
for (int l = i - 1; l >= 0; l--) {
if (height[l] > lHeight) lHeight = height[l];
}
int h = min(lHeight, rHeight) - height[i];
if (h > 0) sum += h;
}
return sum;
}
};
动态规划
class Solution {
public:
int trap(vector<int>& height) {
if (height.size() <= 2) return 0;
vector<int> maxLeft(height.size(), 0);
vector<int> maxRight(height.size(), 0);
int size = maxRight.size();
// 记录每个柱子左边柱子最大高度
maxLeft[0] = height[0];
for (int i = 1; i < size; i++) {
maxLeft[i] = max(height[i], maxLeft[i - 1]);
}
// 记录每个柱子右边柱子最大高度
maxRight[size - 1] = height[size - 1];
for (int i = size - 2; i >= 0; i--) {
maxRight[i] = max(height[i], maxRight[i + 1]);
}
// 求和
int sum = 0;
for (int i = 0; i < size; i++) {
int count = min(maxLeft[i], maxRight[i]) - height[i];
if (count > 0) sum += count;
}
return sum;
}
};
单调栈
class Solution {
public:
int trap(vector<int>& height) {
if (height.size() <= 2) return 0; // 可以不加
stack<int> st; // 存着下标,计算的时候用下标对应的柱子高度
st.push(0);
int sum = 0;
for (int i = 1; i < height.size(); i++) {
if (height[i] < height[st.top()]) { // 情况一
st.push(i);
} if (height[i] == height[st.top()]) { // 情况二
st.pop(); // 其实这一句可以不加,效果是一样的,但处理相同的情况的思路却变了。
st.push(i);
} else { // 情况三
while (!st.empty() && height[i] > height[st.top()]) { // 注意这里是while
int mid = st.top();
st.pop();
if (!st.empty()) {
int h = min(height[st.top()], height[i]) - height[mid];
int w = i - st.top() - 1; // 注意减一,只求中间宽度
sum += h * w;
}
}
st.push(i);
}
}
return sum;
}
};
柱状图中的最大矩形

双指针
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
int sum = 0;
for (int i = 0; i < heights.size(); i++) {
int left = i;
int right = i;
for (; left >= 0; left--) {
if (heights[left] < heights[i]) break;
}
for (; right < heights.size(); right++) {
if (heights[right] < heights[i]) break;
}
int w = right - left - 1;
int h = heights[i];
sum = max(sum, w * h);
}
return sum;
}
};
动态规划
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
vector<int> minLeftIndex(heights.size());
vector<int> minRightIndex(heights.size());
int size = heights.size();
// 记录每个柱子 左边第一个小于该柱子的下标
minLeftIndex[0] = -1; // 注意这里初始化,防止下面while死循环
for (int i = 1; i < size; i++) {
int t = i - 1;
// 这里不是用if,而是不断向左寻找的过程
while (t >= 0 && heights[t] >= heights[i]) t = minLeftIndex[t];
minLeftIndex[i] = t;
}
// 记录每个柱子 右边第一个小于该柱子的下标
minRightIndex[size - 1] = size; // 注意这里初始化,防止下面while死循环
for (int i = size - 2; i >= 0; i--) {
int t = i + 1;
// 这里不是用if,而是不断向右寻找的过程
while (t < size && heights[t] >= heights[i]) t = minRightIndex[t];
minRightIndex[i] = t;
}
// 求和
int result = 0;
for (int i = 0; i < size; i++) {
int sum = heights[i] * (minRightIndex[i] - minLeftIndex[i] - 1);
result = max(sum, result);
}
return result;
}
};
单调栈
// 版本一
class Solution {
public:
int largestRectangleArea(vector& heights) {
stack st;
heights.insert(heights.begin(), 0); // 数组头部加入元素0
heights.push_back(0); // 数组尾部加入元素0
st.push(0);
int result = 0;
// 第一个元素已经入栈,从下标1开始
for (int i = 1; i < heights.size(); i++) {
// 注意heights[i] 是和heights[st.top()] 比较 ,st.top()是下标
if (heights[i] > heights[st.top()]) {
st.push(i);
} else if (heights[i] == heights[st.top()]) {
st.pop(); // 这个可以加,可以不加,效果一样,思路不同
st.push(i);
} else {
while (heights[i] < heights[st.top()]) { // 注意是while
int mid = st.top();
st.pop();
int left = st.top();
int right = i;
int w = right - left - 1;
int h = heights[mid];
result = max(result, w * h);
}
st.push(i);
}
}
return result;
}
};
LRU设计
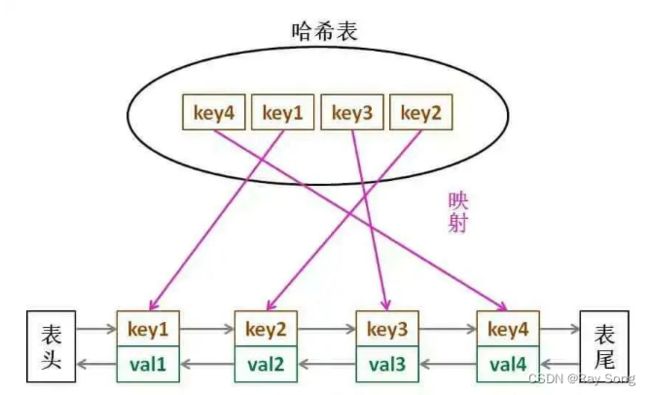
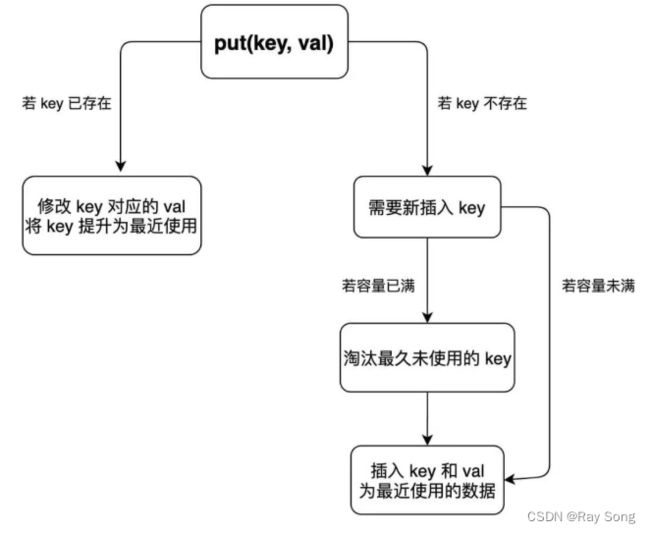
private: unordered_map
public:
1. 构造函数 - 初始化 head tail capacity size
2. put(int key, int value) - 如果 key 不存在,创建一个新的节点 ; 添加进哈希表 ; 添加至双向链表的头部;
如果超出容量,删除双向链表的尾部节点; 删除哈希表中对应的项; 释放内存; size–
3. get(int key) - 如果 key 存在,先通过哈希表定位,再移到头部
4. addToHead(node) - 添加到头部
5. removeNode(node) - 移除节点
6. removeTail() - 移除尾部节点
//需要 后面细看~
struct DLinkedNode {
int key, value;
DLinkedNode* prev;
DLinkedNode* next;
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private:
unordered_map<int, DLinkedNode*> cache;
DLinkedNode* head;
DLinkedNode* tail;
int size;
int capacity;
public:
LRUCache(int _capacity): capacity(_capacity), size(0) {
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (!cache.count(key)) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
DLinkedNode* node = cache[key];
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (!cache.count(key)) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode* node = new DLinkedNode(key, value);
// 添加进哈希表
cache[key] = node;
// 添加至双向链表的头部
addToHead(node);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode* removed = removeTail();
// 删除哈希表中对应的项
cache.erase(removed->key);
// 防止内存泄漏
delete removed;
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
DLinkedNode* node = cache[key];
node->value = value;
moveToHead(node);
}
}
void addToHead(DLinkedNode* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
void removeNode(DLinkedNode* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
// 由前两个函数构成
void moveToHead(DLinkedNode* node) {
removeNode(node);
addToHead(node);
}
DLinkedNode* removeTail() {
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
LFU设计
L;FU
- 哈希表 和 平衡二叉树
struct Node {
int cnt, time, key, value;
Node(int _cnt, int _time, int _key, int _value):cnt(_cnt), time(_time), key(_key), value(_value){}
bool operator < (const Node& rhs) const {
return cnt == rhs.cnt ? time < rhs.time : cnt < rhs.cnt;
}
};
class LFUCache {
// 缓存容量,时间戳
int capacity, time;
unordered_map<int, Node> key_table;
set<Node> S;
public:
LFUCache(int _capacity) {
capacity = _capacity;
time = 0;
key_table.clear();
S.clear();
}
int get(int key) {
if (capacity == 0) return -1;
auto it = key_table.find(key);
// 如果哈希表中没有键 key,返回 -1
if (it == key_table.end()) return -1;
// 从哈希表中得到旧的缓存
Node cache = it -> second;
// 从平衡二叉树中删除旧的缓存
S.erase(cache);
// 将旧缓存更新
cache.cnt += 1;
cache.time = ++time;
// 将新缓存重新放入哈希表和平衡二叉树中
S.insert(cache);
it -> second = cache;
return cache.value;
}
void put(int key, int value) {
if (capacity == 0) return;
auto it = key_table.find(key);
if (it == key_table.end()) {
// 如果到达缓存容量上限
if (key_table.size() == capacity) {
// 从哈希表和平衡二叉树中删除最近最少使用的缓存
key_table.erase(S.begin() -> key);
S.erase(S.begin());
}
// 创建新的缓存
Node cache = Node(1, ++time, key, value);
// 将新缓存放入哈希表和平衡二叉树中
key_table.insert(make_pair(key, cache));
S.insert(cache);
}
else {
// 这里和 get() 函数类似
Node cache = it -> second;
S.erase(cache);
cache.cnt += 1;
cache.time = ++time;
cache.value = value;
S.insert(cache);
it -> second = cache;
}
}
};
- 方法二:双哈希表
// 缓存的节点信息
struct Node {
int key, val, freq;
Node(int _key,int _val,int _freq): key(_key), val(_val), freq(_freq){}
};
class LFUCache {
int minfreq, capacity;
unordered_map<int, list<Node>::iterator> key_table;
unordered_map<int, list<Node>> freq_table;
public:
LFUCache(int _capacity) {
minfreq = 0;
capacity = _capacity;
key_table.clear();
freq_table.clear();
}
int get(int key) {
if (capacity == 0) return -1;
auto it = key_table.find(key);
if (it == key_table.end()) return -1;
list<Node>::iterator node = it -> second;
int val = node -> val, freq = node -> freq;
freq_table[freq].erase(node);
// 如果当前链表为空,我们需要在哈希表中删除,且更新minFreq
if (freq_table[freq].size() == 0) {
freq_table.erase(freq);
if (minfreq == freq) minfreq += 1;
}
// 插入到 freq + 1 中
freq_table[freq + 1].push_front(Node(key, val, freq + 1));
key_table[key] = freq_table[freq + 1].begin();
return val;
}
void put(int key, int value) {
if (capacity == 0) return;
auto it = key_table.find(key);
if (it == key_table.end()) {
// 缓存已满,需要进行删除操作
if (key_table.size() == capacity) {
// 通过 minFreq 拿到 freq_table[minFreq] 链表的末尾节点
auto it2 = freq_table[minfreq].back();
key_table.erase(it2.key);
freq_table[minfreq].pop_back();
if (freq_table[minfreq].size() == 0) {
freq_table.erase(minfreq);
}
}
freq_table[1].push_front(Node(key, value, 1));
key_table[key] = freq_table[1].begin();
minfreq = 1;
} else {
// 与 get 操作基本一致,除了需要更新缓存的值
list<Node>::iterator node = it -> second;
int freq = node -> freq;
freq_table[freq].erase(node);
if (freq_table[freq].size() == 0) {
freq_table.erase(freq);
if (minfreq == freq) minfreq += 1;
}
freq_table[freq + 1].push_front(Node(key, value, freq + 1));
key_table[key] = freq_table[freq + 1].begin();
}
}
};
前缀树的应用
前缀树

数据流中的中位数(hard)
数据流中位数
二叉堆实现优先级队列 !!
二叉堆优先级队列实现
设计朋友圈时间线 设计推特
355. 设计推特
两个栈实现队列(模拟)
定义两个栈 一个入 一个出 push pop peek isEmpty函数实现
class MyQueue {
public:
stack<int> stIn;
stack<int> stOut;
/** Initialize your data structure here. */
MyQueue() {
}
/** Push element x to the back of queue. */
void push(int x) {
stIn.push(x);
}
/** Removes the element from in front of queue and returns that element. */
int pop() {
// 只有当stOut为空的时候,再从stIn里导入数据(导入stIn全部数据)
if (stOut.empty()) {
// 从stIn导入数据直到stIn为空
while(!stIn.empty()) {
stOut.push(stIn.top());
stIn.pop();
}
}
int result = stOut.top();
stOut.pop();
return result;
}
/** Get the front element. */
int peek() {
int res = this->pop(); // 直接使用已有的pop函数
stOut.push(res); // 因为pop函数弹出了元素res,所以再添加回去
return res;
}
/** Returns whether the queue is empty. */
bool empty() {
return stIn.empty() && stOut.empty();
}
};
队列实现栈 (模拟)
可以使用两个队列实现 一个队列备份 一个队列操作
也可以使用一个队列实现 将前面部分搬移到最后一个元素后面 然后在pop即可
class MyStack {
public:
queue<int> que1;
queue<int> que2; // 辅助队列,用来备份
/** Initialize your data structure here. */
MyStack() {
}
/** Push element x onto stack. */
void push(int x) {
que1.push(x);
}
/** Removes the element on top of the stack and returns that element. */
int pop() {
int size = que1.size();
size--;
while (size--) { // 将que1 导入que2,但要留下最后一个元素
que2.push(que1.front());
que1.pop();
}
int result = que1.front(); // 留下的最后一个元素就是要返回的值
que1.pop();
que1 = que2; // 再将que2赋值给que1
while (!que2.empty()) { // 清空que2
que2.pop();
}
return result;
}
/** Get the top element. */
int top() {
return que1.back();
}
/** Returns whether the stack is empty. */
bool empty() {
return que1.empty();
}
};
有效的括号 栈
给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
使用栈结构进行匹配 左括号push 遇到可以匹配的右括号pop 判断栈最后是否为空即可
需要主要考虑清楚三种情况
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
class Solution {
public:
bool isValid(string s) {
stack<int> st;
for (int i = 0; i < s.size(); i++) {
if (s[i] == '(') st.push(')');
else if (s[i] == '{') st.push('}');
else if (s[i] == '[') st.push(']');
// 第三种情况:遍历字符串匹配的过程中,栈已经为空了,没有匹配的字符了,说明右括号没有找到对应的左括号 return false
// 第二种情况:遍历字符串匹配的过程中,发现栈里没有我们要匹配的字符。所以return false
else if (st.empty() || st.top() != s[i]) return false;
else st.pop(); // st.top() 与 s[i]相等,栈弹出元素
}
// 第一种情况:此时我们已经遍历完了字符串,但是栈不为空,说明有相应的左括号没有右括号来匹配,所以return false,否则就return true
return st.empty();
}
};
删除字符串中的所有相邻重复项 栈结构
可以把字符串顺序放到一个栈中,然后如果相同的话 栈就弹出,这样最后栈里剩下的元素都是相邻不相同的元素了。
解法:a)可以直接将字符串当作栈结构使用 b)也可以使用栈结构排除,最后再revesrse一下。
-
题目
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
示例:
输入:“abbaca”
输出:“ca”
解释:例如,在 “abbaca” 中,我们可以删除 “bb” 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 “aaca”,其中又只有 “aa” 可以执行重复项删除操作,所以最后的字符串为 “ca”。 -
思路:
本题要删除相邻相同元素,其实也是匹配问题,相同左元素相当于左括号,相同右元素就是相当于右括号,匹配上了就删除。
那么再来看一下本题:可以把字符串顺序放到一个栈中,然后如果相同的话 栈就弹出,这样最后栈里剩下的元素都是相邻不相同的元素了。
用stack的版本
class Solution {
public:
string removeDuplicates(string S) {
stack<char> st;
for (char s : S) {
if (st.empty() || s != st.top()) {
st.push(s);
} else {
st.pop(); // s 与 st.top()相等的情况
}
}
string result = "";
while (!st.empty()) { // 将栈中元素放到result字符串汇总
result += st.top();
st.pop();
}
reverse (result.begin(), result.end()); // 此时字符串需要反转一下
return result;
}
};
直接用string的版本
class Solution {
public:
string removeDuplicates(string S) {
string result;
for(char s : S) {
if(result.empty() || result.back() != s) {
result.push_back(s);
}
else {
result.pop_back();
}
}
return result;
}
逆波兰表达式求值 栈结构
后缀表达式 不用考虑优先级 相对于中缀表达式 更适合 计算机的思考模式
示例 1:
输入: [“2”, “1”, “+”, “3”, " * "]
输出: 9
解释: 该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
那么来看一下本题,其实逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。
但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后续遍历的方式把二叉树序列化了,就可以了。
在进一步看,本题中每一个子表达式要得出一个结果,然后拿这个结果再进行运算,那么这岂不就是一个相邻字符串消除的过程,和1047.删除字符串中的所有相邻重复项 (opens new window)中的对对碰游戏是不是就非常像了.
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
for (int i = 0; i < tokens.size(); i++) {
if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {
int num1 = st.top();
st.pop();
int num2 = st.top();
st.pop();
if (tokens[i] == "+") st.push(num2 + num1);
if (tokens[i] == "-") st.push(num2 - num1);
if (tokens[i] == "*") st.push(num2 * num1);
if (tokens[i] == "/") st.push(num2 / num1);
} else {
st.push(stoi(tokens[i]));
}
}
int result = st.top();
st.pop(); // 把栈里最后一个元素弹出(其实不弹出也没事)
return result;
}
};
滑动窗口最大值 单调队列

优先级队列无法删除其他数值,所以要用单调队列 利用deque定义一个单调队列
元素大小递减排序 ,遇到小元素不管,大元素于队列尾部元素比较,如何大于已经有的,则将已经有的去除,把新的大的添加进去。
class Solution {
private:
class MyQueue { //单调队列(从大到小)
public:
deque<int> que; // 使用deque来实现单调队列
// 每次弹出的时候,比较当前要弹出的数值是否等于队列出口元素的数值,如果相等则弹出。
// 同时pop之前判断队列当前是否为空。
void pop(int value) {
if (!que.empty() && value == que.front()) {
que.pop_front();
}
}
// 如果push的数值大于入口元素的数值,那么就将队列后端的数值弹出,直到push的数值小于等于队列入口元素的数值为止。
// 这样就保持了队列里的数值是单调从大到小的了。
void push(int value) {
while (!que.empty() && value > que.back()) {
que.pop_back();
}
que.push_back(value);
}
// 查询当前队列里的最大值 直接返回队列前端也就是front就可以了。
int front() {
return que.front();
}
};
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
MyQueue que;
vector<int> result;
for (int i = 0; i < k; i++) { // 先将前k的元素放进队列
que.push(nums[i]);
}
result.push_back(que.front()); // result 记录前k的元素的最大值
for (int i = k; i < nums.size(); i++) {
que.pop(nums[i - k]); // 滑动窗口移除最前面元素
que.push(nums[i]); // 滑动窗口前加入最后面的元素
result.push_back(que.front()); // 记录对应的最大值
}
return result;
}
};
前 K 个高频元素 优先级队列
方法一: unordered_map 存储元素频次,然后sort一下
#include
#include 方法二
定义一个哈希map,遍历统计频率;
然后定义一个小顶堆,保持个数为k,添加元素的同时把小的数据pop掉,最后剩下的就是前k个高频数据了。
注意:priority_queue
Mycomparision的定义中 与 排序算法相反,lhs.second > rhs.second; 建立小根堆。
// 时间复杂度:O(nlogk)
// 空间复杂度:O(n)
class Solution {
public:
// 小顶堆
class mycomparison {
public:
bool operator()(const pair<int, int>& lhs, const pair<int, int>& rhs) {
return lhs.second > rhs.second;
}
};
vector<int> topKFrequent(vector<int>& nums, int k) {
// 要统计元素出现频率
unordered_map<int, int> map; // map