Lucene系列二:反向索引及索引原理
了解关系型数据库的童靴都了解它底层结构采用b+tree的实现,而Lucene则是基于反向索引实现,并将它发挥到了极致。如果不了解Lucene是什么,可以参阅《系列一之全文检索》
目录
1. 什么是反向索引
2. 如何设计反向索引
2.1 如何快速查询与苍老师有关的新闻?
2.2 有标题列索引和内容列索引会有什么问题
2.3 反向索引的记录数【英文/中文】会不会很大
2.4 开源中文分词器有哪些
2.5. 你、我、他、my、she、it、标点符号怎么办
2.6. 当出现了新词了该怎么办
2.7. 如何进行搜索
2.8. 反向索引是存储在内存中还是磁盘
2.9. 反向索引更新问题
小结
3. 索引内部原理
3.1 FST
3.2 FST-性能测试
3.3 索引结构
3.4 倒排表结构
3.5 正向文件
3.6 列式存储DocValues
1. 什么是反向索引
反向索引英文名叫做 Inverted index,顾名思义,是通常意义下索引的倒置,它相当于一篇文章包含了哪些词,它从词出发,记载了这个词在哪些文档中出现过,由两部分组成——词典和倒排表。这就是:反向索引(Inverted index)。举个例子:
| 1 | I love you |
| 2 | I love you too |
| 4 | I dislike you |
如果要用单词作为索引,而句子的位置作为被索引的元素,那么索引就发生了倒置:
I : {1,2,3}
love : {1,2}
you : {1,2,3}
dislike : {3}
如果要检索I dislike you这句话,那么就可以这么计算 : {1,2,3} ^ {3} ^ {1,2,3} (^是交集)
2. 如何设计反向索引
2.1 如何快速查询与苍老师有关的新闻?
分析:输入的是苍老师,想要得到标题或内容中包含“苍老师”的新闻列表。
标题列索引:

内容列索引:
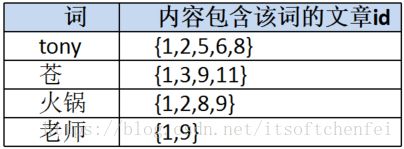
那如果是这样的文章呢?
| id | 标题 | 新闻内容 |
| 1 | Tony 与苍老师一起吃火锅 | 2018年4月1日,Tony 在四川成都出席某活动时,碰巧主办方也邀请了苍老师来提高人气,在主办方的邀请下和苍老师一起吃了个火锅,很爽! |
如果是英文文章(It’s one thing to find the 10 best documents to match your query)好不好分?英文好分(有空格)。
中文则不好分,一定分的话,就必须写一套专门的程序来做这个事情:分词器(有个词的字典,对语句前后字进行组合,与字典匹配,歧义分析)。
2.2 有标题列索引和内容列索引会有什么问题
两个索引需要合并,好处是:可以减少访问数据库的次数

2.3 反向索引的记录数【英文/中文】会不会很大
| 英语 | 单词的大致数量是10万个 |
| 汉字 | 汉字的总数已经超过了8万,而常用的只有3500字,《现代汉语规范词典》比《现代汉语词典》收录的字和词数量更多。 前者是13000多字,72000多词,后者是11000多字,69000多词 |
结论:量不会很大,30万以内;通过这个索引找文章会很快
2.4 开源中文分词器有哪些
准确率、分词效率、中英文混合分词支持,常用中文分词器有:IKAnalyzer、mmseg4j
2.5. 你、我、他、my、she、it、标点符号怎么办
这些词称为:停用词。分词器支持指定/添加停用词,不需要为其创建索引
2.6. 当出现了新词了该怎么办
撩妹 老司机、软妹子、直男、腿玩年、苍老师...
分词器应支持为其词典添加新词
2.7. 如何进行搜索
搜索与 “tony OR 苍老师” 相关的新闻,怎么做?
Step 1: 对搜索输入进行分词,得到:tony 、苍老师
Step 2:在反向索引中找出包含tony、苍老师的文章列表
Step3:合并两个列表,排序输出
2.8. 反向索引是存储在内存中还是磁盘
大的放磁盘,小的放内存,同时需要做持久化。应该说都有使用,下面会详细讲解
2.9. 反向索引更新问题
问1:新增时,需要怎么更新?
问2:删除时,需要怎么更新?
问3:修改时,需要怎么更新?
带着疑问继续向下看
小结
我们创建反向索引,大概如下所示:

3. 索引内部原理
之前讲过绝大多数全文检索都基于倒排索引来实现,主要用到词典和倒排表。特别是词典结构尤为重要,有很多种词典类数据结构,各有各的优缺点
| 数据结构 |
优缺点 |
| 排序列表 |
实现简单,但性能差 |
| Hash表 |
性能高,内存消耗大 |
| 跳跃表 |
占用内存小且可调,但模糊查询支持不好 |
| B树 |
磁盘索引,更新方便,但检索速度慢,数据库应用比较多 |
| 字典树 |
查询效率只跟字符串长度有关,但只适合英文词典 |
| 双数组字典树 |
可做中文词典,内存占用小,分词工具应用比较多 |
| Finit state Transducers(FST) |
中文有穷状态转换器, 优点:内存占用率低,压缩率一般在3倍~20倍之间、模糊查询支持好、查询快 |
lucene里面就引入了term dictonary的概念,也就是term的字典。在term很多,内存放不下的时候,效率还是需要进一步提升。
Lucene3.0之前使用的也是跳跃表结构,后(Lucene4.0,为了方便实现rangequery或者前缀,后缀等复杂的查询语句)换成了FST,但跳跃表在Lucene其他地方还有应用如倒排表合并和文档号索引。
3.1 FST
它功能类似于字典的功能,但其查找是O(1)的,仅仅等于所查找的key长度。FST可以用HashMap代替。但是相比HashMap,FST有以下优点:
- 紧凑的结构,通过对词典中单词前缀和后缀的重复利用,压缩了存储空间。
- O(len(str))的查询时间复杂度。
如果不考虑FST的输出,FST本质上是一个最小的,有向无环DFA。算法摘自
对aaaa,bbaa,ccbaa,ddcbaa这4个单词构建FST(注意:单词插入前必须先进行排序,否则就无法生成最小FST)

如果感兴趣的话,可以从源码org.apache.lucene.util.fst.Builder的add()方法作为切入口一步步去分析
3.2 FST-性能测试
对HashMap、TreeMap、FST进行100万数据性能测试
String inputs={"abc","abd","acf","acg"}; //keys
long outputs={1,3,5,7}; //values
FST fst=new FST<>();
for(int i=0;i iterator=new BytesRefFSTEnum<>(fst);
while(iterator.next!=null){...} | 数据结构 | HashMap | TreeMap | FST |
|---|---|---|---|
| 构建时间(ms) | 185 | 500 | 1512 |
| 查询所有key(ms) | 106 | 218 | 890 |
从上面结果可以看出,FST性能基本跟HaspMap差距不大,但FST有个不可比拟的优势就是占用内存小,只有HashMap10分之一左右,这对大数据规模检索是至关重要的,毕竟速度再快放不进内存也是没用的。因此一个合格的词典结构要求有:
- 查询速度。
- 内存占用。
- 内存+磁盘结合。
3.3 索引结构
存储文件
在介绍索引结构之前,先看一下lucene的存储文件,

说明一下:属于一个段的所有文件具有相同的名称和不同的扩展名。当使用复合索引文件,这些文件(除了段信息文件、锁文件和已删除的文档文件)将压缩成单个.cfs文件。当任何索引文件被保存到目录时,它被赋予一个从未被使用过的文件名字。
| 名称 | 文件扩展名 | 简短描述 |
|---|---|---|
| Segments File | segments_N | 保存了一个提交点(a commit point)的信息 |
| Lock File | write.lock | 防止多个IndexWriter同时写到一份索引文件中 |
| Segment Info | .si | 保存了索引段的元数据信息 |
| Compound File | .cfs,.cfe | 一个可选的虚拟文件,把所有索引信息都存储到复合索引文件中 |
| Fields | .fnm | 保存fields的相关信息 |
| Field Index | .fdx | 保存指向field data的指针 |
| Field Data | .fdt | 文档存储的字段的值 |
| Term Dictionary | .tim | term词典,存储term信息 |
| Term Index | .tip | 到Term Dictionary的索引 |
| Frequencies | .doc | 由包含每个term以及频率的docs列表组成 |
| Positions | .pos | 存储出现在索引中的term的位置信息 |
| Payloads | .pay | 存储额外的per-position元数据信息,例如字符偏移和用户payloads |
| Norms | .nvd,.nvm | .nvm文件保存索引字段加权因子的元数据,.nvd文件保存索引字段加权数据 |
| Per-Document Values | .dvd,.dvm | .dvm文件保存索引文档评分因子的元数据,.dvd文件保存索引文档评分数据 |
| Term Vector Index | .tvx | 将偏移存储到文档数据文件中 |
| Term Vector Documents | .tvd | 包含有term vectors的每个文档信息 |
| Term Vector Fields | .tvf | 字段级别有关term vectors的信息 |
| Live Documents | .liv | 哪些是有效文件的信息 |
| Point values | .dii,.dim | 保留索引点,如果有的话 |
索引文件结构
Lucene经多年演进优化,现在的一个索引文件结构如图所示,基本可以分为三个部分:词典、倒排表、正向文件、列式存储DocValues。索引结构中,不仅仅保存了反向信息,还保存了正向信息。
正向信息
(1)按层次保存了从索引,一直到词的包含关系:索引(Index)-->段(segment)->文档(Document)->域(Field)->词(Term)
(2)也即此索引包含了那些段,每个段包含了那些文档,每个文档包含了那些域,每个域包含了那些词。segments_N保存了此索引包含多少个段,每个段包含多少篇文档。XXX.fnm保存此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
XXX.fdx,XXX.fdt保存了此段包含的所有文档,每篇文档包含了多少域,每个域保存了那些信息。
反向信息
(1)保存了词典到倒排表的映射:词(Term) --> 文档(Document)
(2)含反向信息的文件有:
#XXX.tis,XXX.tii保存了词典(Term Dictionary),也即此段包含的所有的词按字典顺序的排序
#XXX.frq保存了倒排表,也即包含每个词的文档ID列表。
#XXX.prx保存了倒排表中每个词在包含此词的文档中的位置。

它的特点就是:
- 词查找复杂度为O(len(str))
- 共享前缀、节省空间
- 内存存放前缀索引、磁盘存放后缀词块
我们往索引库里插入四个单词abd、abe、acf、acg,看看它的索引文件内容。

- tip部分,每列一个FST索引,所以会有多个FST,每个FST存放前缀和后缀块指针,这里前缀就为a、ab、ac
- tim里面存放后缀块和词的其他信息如倒排表指针、TFDF等
- doc文件里就为每个单词的倒排表
它的检索过程分为三个步骤:
- 内存加载tip文件,通过FST匹配前缀找到后缀词块位置。
- 根据词块位置,读取磁盘中tim文件中后缀块并找到后缀和相应的倒排表位置信息。
- 根据倒排表位置去doc文件中加载倒排表。
这里就会有两个问题,第一就是前缀如何计算,第二就是后缀如何写磁盘并通过FST定位,下面将描述下Lucene构建FST过程:已知FST要求输入有序,所以Lucene会将解析出来的文档单词预先排序,然后构建FST,我们假设输入为abd,abd,acf,acg,

- 插入abd时,没有输出。
- 插入abe时,计算出前缀ab,但此时不知道后续还不会有其他以ab为前缀的词,所以此时无输出。
- 插入acf时,因为是有序的,知道不会再有ab前缀的词了,这时就可以写tip和tim了,tim中写入后缀词块d、e和它们的倒排表位置ip_d,ip_e,tip中写入a,b和以ab为前缀的后缀词块位置(真实情况下会写入更多信息如词频等)。
- 插入acg时,计算出和acf共享前缀ac,这时输入已经结束,所有数据写入磁盘。tim中写入后缀词块f、g和相对应的倒排表位置,tip中写入c和以ac为前缀的后缀词块位置。
以上是一个简化过程,Lucene的FST实现的主要优化策略有:
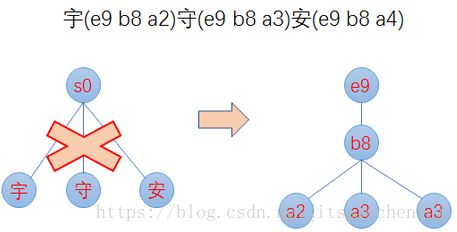
- 最小后缀数。Lucene对写入tip的前缀有个最小后缀数要求,默认25,这时为了进一步减少内存使用。如果按照25的后缀数,那么就不存在ab、ac前缀,将只有一个跟节点,abd、abe、acf、acg将都作为后缀存在tim文件中。我们的10g的一个索引库,索引内存消耗只占20M左右。
- 前缀计算基于byte,而不是char,这样可以减少后缀数,防止后缀数太多,影响性能。如对宇(e9 b8 a2)、守(e9 b8 a3)、安(e9 b8 a4)这三个汉字,FST构建出来,不是只有根节点,三个汉字为后缀,而是从unicode码出发,以e9、b8为前缀,a2、a3、a4为后缀,如下图:
3.4 倒排表结构
倒排表就是文档号集合,但怎么存,怎么取也有很多讲究,Lucene现使用的倒排表结构叫Frame of reference,它主要有两个特点:

- 数据压缩,可以看上图怎么将6个数字从原先的24bytes压缩到7bytes
- 跳跃表加速合并,因为布尔查询时,and 和or 操作都需要合并倒排表,这时就需要快速定位相同文档号,所以利用跳跃表来进行相同文档号查找。可以参考官方
3.5 正向文件
正向文件指的就是原始文档,Lucene对原始文档也提供了存储功能,它存储特点就是分块+压缩,fdt文件就是存放原始文档的文件,它占了索引库90%的磁盘空间,fdx文件为索引文件,通过文档号(自增数字)快速得到文档位置,它们的文件结构如下:
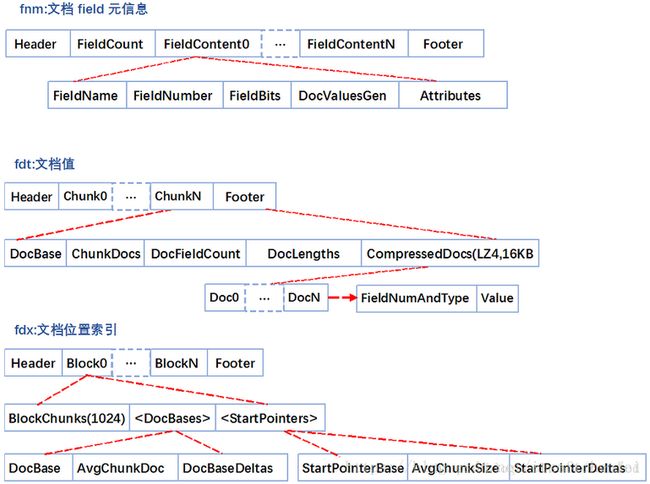
- fnm中为元信息存放了各列类型、列名、存储方式等信息。
- fdt为文档值,里面一个chunk就是一个块,Lucene索引文档时,先缓存文档,缓存大于16KB时,就会把文档压缩存储。一个chunk包含了该chunk起始文档、多少个文档、压缩后的文档内容。
- fdx为文档号索引,倒排表存放的时文档号,通过fdx才能快速定位到文档位置即chunk位置,它的索引结构比较简单,就是跳跃表结构,首先它会把1024个chunk归为一个block,每个block记载了起始文档值,block就相当于一级跳表。
查找文档,就分为三步:
第一步二分查找block,定位属于哪个block。
第二步就是根据从block里根据每个chunk的起始文档号,找到属于哪个chunk和chunk位置。
第三步就是去加载fdt的chunk,找到文档。这里还有一个细节就是存放chunk起始文档值和chunk位置不是简单的数组,而是采用了平均值压缩法。所以第N个chunk的起始文档值由 DocBase + AvgChunkDocs * n + DocBaseDeltas[n]恢复而来,而第N个chunk再fdt中的位置由 StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]恢复而来。
总结lucene对原始文件的存放是行是存储,并且为了提高空间利用率,是多文档一起压缩,因此取文档时需要读入和解压额外文档,因此取文档过程非常依赖随机IO,以及lucene虽然提供了取特定列,但从存储结构可以看出,并不会减少取文档时间。
3.6 列式存储DocValues
我们知道倒排索引能够解决从词到文档的快速映射,但当我们需要对检索结果进行分类、排序、数学计算等聚合操作时需要文档号到值的快速映射,而原先不管是倒排索引还是行式存储的文档都无法满足要求。原先4.0版本之前,Lucene实现这种需求是通过FieldCache,它的原理是通过按列逆转倒排表将(field value ->doc)映射变成(doc -> field value)映射,但这种实现方法有着两大显著问题:
- 构建时间长。
- 内存占用大,易OutOfMemory,且影响垃圾回收
因此4.0版本后Lucene推出了DocValues来解决这一问题,它和FieldCache一样,都为列式存储,但它有如下优点:
- 预先构建,写入文件。
- 基于映射文件来做,脱离JVM堆内存,系统调度缺页。
DocValues这种实现方法只比内存FieldCache慢大概10~25%,但稳定性却得到了极大提升。
Lucene目前有五种类型的DocValues:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型Lucene都有特定的压缩方法。如对NUMERIC类型即数字类型,数字类型压缩方法很多,如:增量、表压缩、最大公约数,根据数据特征选取不同压缩方法。SORTED类型即字符串类型,压缩方法就是表压缩:预先对字符串字典排序分配数字ID,存储时只需存储字符串映射表,和数字数组即可,而这数字数组又可以采用NUMERIC压缩方法再压缩,图示如下:

这样就将原先的字符串数组变成数字数组,一是减少了空间,文件映射更有效率,二是原先变成访问方式变成固长访问。对DocValues的应用,ElasticSearch功能实现地更系统、更完整,即ElasticSearch的Aggregations——聚合功能,它的聚合功能分为三类:
1. Metric -> 统计
典型功能:sum、min、max、avg、cardinality、percent等
2. Bucket ->分组
典型功能:日期直方图,分组,地理位置分区
3. Pipline -> 基于聚合再聚合
典型功能:基于各分组的平均值求最大值。
基于这些聚合功能,ElasticSearch不再局限与检索,而能够回答如下SQL的问题
select gender,count(*),avg(age) from employee where dept='sales' group by gender //销售部门男女人数、平均年龄是多少
我们看下ElasticSearch如何基于倒排索引和DocValues实现上述SQL的

- 从倒排索引中找出销售部门的倒排表。
- 根据倒排表去性别的DocValues里取出每个人对应的性别,并分组到Female和Male里。
- 根据分组情况和年龄DocValues,计算各分组人数和平均年龄
- 因为ElasticSearch是分区的,所以对每个分区的返回结果进行合并就是最终的结果。
上面就是ElasticSearch进行聚合的整体流程,也可以看出ElasticSearch做聚合的一个瓶颈就是最后一步的聚合只能单机聚合,也因此一些统计会有误差,比如count(*) group by producet limit 5,最终总数不是精确的。因为单点内存聚合,所以每个分区不可能返回所有分组统计信息,只能返回部分,汇总时就会导致最终结果不正确,具体如下:
| Shard 1 |
Shard 2 |
Shard 3 |
| Product A (25) |
Product A (30) |
Product A (45) |
| Product B (18) |
Product B (25) |
Product C (44) |
| Product C (6) |
Product F (17) |
Product Z (36) |
| Product D (3) |
Product Z (16) |
Product G (30) |
| Product E (2) |
Product G (15) |
Product E (29) |
| Product F (2) |
Product H (14) |
Product H (28) |
| Product G (2) |
Product I (10) |
Product Q (2) |
| Product H (2) |
Product Q (6) |
Product D (1) |
| Product I (1) |
Product J (8) |
|
| Product J (1) |
Product C (4) |
|
count(*) group by producet limit 5,每个节点返回的数据如下:
| Shard 1 |
Shard 2 |
Shard 3 |
| Product A (25) |
Product A (30) |
Product A (45) |
| Product B (18) |
Product B (25) |
Product C (44) |
| Product C (6) |
Product F (17) |
Product Z (36) |
| Product D (3) |
Product Z (16) |
Product G (30) |
| Product E (2) |
Product G (15) |
Product E (29) |
合并后:
| Merged |
| Product A (100) |
| Product Z (52) |
| Product C (50) |
| Product G (45) |
| Product B (43) |
商品A的总数是对的,因为每个节点都返回了,但商品C在节点2因为排不到前5所以没有返回,因此总数是错的。