FastInst: A Simple Query-Based Model for Real-Time Instance Segmentation 代码解析
FastInst: A Simple Query-Based Model for Real-Time Instance Segmentation
在自己的数据集上训练
1 首先将数据集改为coco 的实例分割格式
在detectron2/data/datasets/builtin.py目录下,将我的数据集名称加入到字典中
_PREDEFINED_SPLITS_COCO["coco"] = {
"coco_2014_train": ("coco/train2014", "coco/annotations/instances_train2014.json"),
"coco_2014_val": ("coco/val2014", "coco/annotations/instances_val2014.json"),
"coco_2014_minival": ("coco/val2014", "coco/annotations/instances_minival2014.json"),
"coco_2014_valminusminival": (
"coco/val2014",
"coco/annotations/instances_valminusminival2014.json",
),
"coco_2017_train": ("coco/train2017", "coco/annotations/instances_train2017.json"),
"coco_2017_val": ("coco/val2017", "coco/annotations/instances_val2017.json"),
"coco_2017_test": ("coco/test2017", "coco/annotations/image_info_test2017.json"),
"coco_2017_test-dev": ("coco/test2017", "coco/annotations/image_info_test-dev2017.json"),
"coco_2017_val_100": ("coco/val2017", "coco/annotations/instances_val2017_100.json"),
"ged_coco_instance_train":("new_ged/train/images", "/fastersharefiles/liuzezheng/new_ged/train/annotations/train.json"),
}
原始代码每次开终端都要重新定义环境变量,将DETECTRON2_DATASETS定位到数据集的根目录
export DETECTRON2_DATASETS=/fastersharefiles/xxxx/
我比较讨厌每次都设置,直接修改builtin.py文件下的_root文件夹定位到我的根目录
if __name__.endswith(".builtin"):
# Assume pre-defined datasets live in `./datasets`.
_root = os.path.expanduser(os.getenv("DETECTRON2_DATASETS", "datasets"))
_root = "/fastersharefiles/liuzezheng"
register_all_coco(_root)
register_all_lvis(_root)
register_all_cityscapes(_root)
register_all_cityscapes_panoptic(_root)
register_all_pascal_voc(_root)
register_all_ade20k(_root)
2 在同目录的builtin_meta.py 文件当中为自己的数据集重写一个关于注册类信息的函数
def _get_ged_instances_meta():
thing_ids = [1]
thing_colors = [(128, 64, 128)]
# Mapping from the incontiguous COCO category id to an id in [0, 79]
thing_dataset_id_to_contiguous_id = {k: i for i, k in enumerate(thing_ids)}
thing_classes = [k["name"] for k in ged_CATEGORIES if k["isthing"] == 1]
ret = {
"thing_dataset_id_to_contiguous_id": thing_dataset_id_to_contiguous_id,
"thing_classes": thing_classes,
"thing_colors": thing_colors,
}
return ret
在上层的builtin.py进行修改,传入key值

3 指定训练用的config文件中的训练的dataset
DATASETS:
TRAIN: ("ged_coco_instance_train",)
TEST: ("coco_2017_val",)
训练时遇到的问题
1 训练时一直报警报
set_operations.py:133: RuntimeWarning: invalid value encountered in intersection
return lib.intersection(a, b, **kwargs)
在github上看见有效的解决方法——将Shapely的包换成老版本的1.8
https://github.com/shapely/shapely/issues/1345
2 训练一会报错
ValueError: matrix contains invalid numeric entries
在github上查了一下 issue里讨论的结果是因为学习率比较高 调低学习率即可解决 但是我试了1e-4 1e-5 1e-6都还是报错
这个问题改了三天最终解决了,解决方法很简单,在config文件中关闭AMP训练就可以了。
过程很折磨,一部分人触发这个问题是因为cost matrix中含有无穷值导致报错,这应该是由于优化的学习率导致的。但是经过排查,发现触发这个问题是在我的成本矩阵中包含Nan,这可能是因为混合精度导致的,具体原因不清楚。
Instance activation-guided queries的结构与训练过程
Instance query 是本篇论文的关键改进,消融掉该模块会导致四到五个点的性能差异,且与其他query方式对比,也能产生一个点的性能提升。具体来讲,IAQ是由一个分类头所产生,该分类头会对输入的特征的每一个像素进行分类,以判断前景还是背景
# [batch size, classes,proposal_h ,proposal_w]
outputs["proposal_cls_logits"]
作者对分类头的工作分为两部分,第一部分为如何在一张特征图上选择出100个点作为query,第二是该分类头的训练方式
query 产生
query产生代码在transformer_decoder/utils.py文件中的QueryProposal()类来实现,该类包含分类头用于产生proposal_cls_logits,这里作者做了一个在每个类平面上取局部最大值的处理。这种处理解决的问题是,如果不取局部最大值,在下面topk的操作中取前100个最大值点,那么对于预测的很好的类来说,模型会对该类的平面中产生很多置信度较高的预测,取topk的话就取得全是这些点。通过取局部最大值,不仅可以取到局部最优质的点还可以抑制掉那些重复的预测。
proposal_cls_logits = self.conv_proposal_cls_logits(x) # b, c, h, w
#softmax激活后的匪类结果
proposal_cls_probs = proposal_cls_logits.softmax(dim=1) # b, c, h, w
#产生局部最大值的map
proposal_local_maximum_map = self.seek_local_maximum(proposal_cls_probs) # b, c, h, w
#分类概率按照两者加和计算
proposal_cls_probs = proposal_cls_probs + proposal_local_maximum_map # b, c, h, w
产生query的索引
#proposal_cls_probs[:, :-1, :, :] 去掉背景类 b classes-1 h w
#proposal_cls_probs[:, :-1, :, :].flatten(2) 拉平后两个维度 b classes-1 hw
#torch.topk(proposal_cls_probs[:, :-1, :, :].flatten(2).max(1), self.topk, dim=1 返回在第二个维度(也就是分类维度)最大值的前100个索引
topk_indices = torch.topk(proposal_cls_probs[:, :-1, :, :].flatten(2).max(1)[0], self.topk, dim=1)[1] # b, q
topk_indices = topk_indices.unsqueeze(1) # b, 1, q
分类头的训练方式
分类头使用匈牙利匹配的方式进行训练,首先需要定义出该匹配的成本矩阵,成本矩阵除了监督分类的分类陈本,还有作者添加的位置陈本,添加位置陈本背后的直觉是,只有落在对象内部的像素才有理由推断该对象的类和mask嵌入。此外,位置开销减少了二分匹配空间,加快了训练收敛速度。
#add location cost when the proposal is not inside the instance region.
#位置成本是在下采样的gt mask上获得,对应位置-1 降低了预测位置正确的像素的cost
cost_location = -scaled_tgt_mask.flatten(1).transpose(0, 1) # [proposal_hw, num_obj]
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be omitted.
#分类成本是减去预测正确类别的置信度
cost_class = -proposal_cls_prob[:, tgt_ids] # [proposal_hw, num_obj]
这里产生的成本矩阵大小是[proposal_hw, num_obj],对num_obj个gt,分类头产生的特征图上的每一个像素都有cost,成本矩阵交给linear_sum_assignment_with_inf()函数,后面的空集的成本会被自动填充。
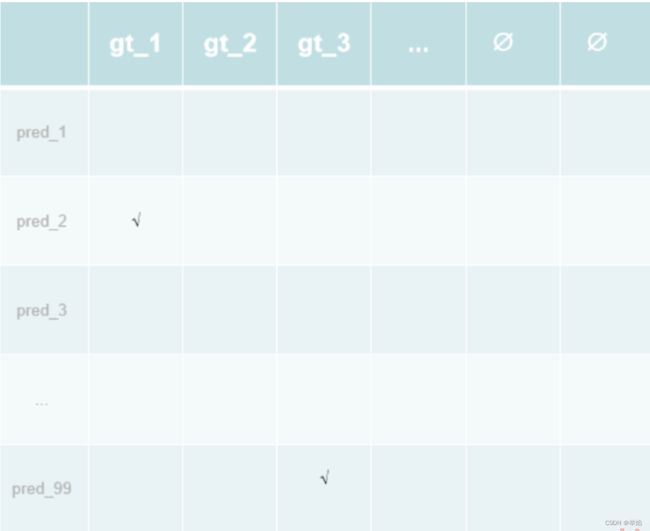
最后返回indices 不同行代表不同的样本,我这里batch size为2 所以有两行,第一列代表特征图,第二列为gt,对于第一行来说就是索引是2的这个点最对应样本1中的第一个物体。这里匹配的结果是一一对应的,对于一个物体来说只有一个点会和gt计算loss

loss 是使用交叉熵计算的分类loss
def loss_proposals(self, output_proposals, targets, indices):
assert "proposal_cls_logits" in output_proposals
proposal_size = output_proposals["proposal_cls_logits"].shape[-2:]
proposal_cls_logits = output_proposals["proposal_cls_logits"].flatten(2).float() # b, c, hw
target_classes = self.num_classes * torch.ones([proposal_cls_logits.shape[0],
proposal_size[0] * proposal_size[1]],
device=proposal_cls_logits.device)
target_classes = target_classes.to(torch.int64)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
idx = self._get_src_permutation_idx(indices)
target_classes[idx] = target_classes_o
loss_proposal = F.cross_entropy(proposal_cls_logits, target_classes, ignore_index=-1)
losses = {"loss_proposal": loss_proposal}
return losses