python pytorch- TextCNN TextRNN FastText Transfermer (中英文)文本情感分类实战(附数据集,代码皆可运行)
python pytorch- TextCNN TextRNN FastText Transfermer 文本情感分类实战(附数据集,代码皆可运行)
注:本次实验,主要注重代码实现这些模型,博主的数据集质量较差,模型评估效果并不是十分理想,后续同学们可以自行使用自己的数据集去运行这些模型,训练自己的优质模型。数据集我会上传到我得资源当中,大家可以自行下载。
最近博主做了基于深度学习的文本情感分类的实验,在这个实验中,我们用到了四个比较热门的深度学习文本分类模型TextCNN TextRNN FastText Transfermer 。使用的是pytorch框架实现的。
在这篇博文中,博主不会介绍这些模型的数学原理,主要还是讲可运行的代码放在这篇博文里。
这篇博客分为如下几个部分
1.数据集介绍
2.数据集预处理思路简要介绍和实现代码
3.TextCNN 文本分类实战
4.TextRNN 文本分类实战
5.FastText 文本分类实战
6.Transfermer 文本分类实战
1.数据集介绍
如下是我们的数据集:

数据集由六个txt文件组成,如下图:
分别是三个训练集文件和三个测试集文件,三个训练集文件分别对应消极、积极、中性的三种文本数据。同理三个测试机文件也分别对应消极、积极、中性的三种文本数据。
其中每一个数据集都是一个一个的句子组成,每个句子占一行。
如下:

只有stopwrods.txt比较特别:
其实由一个个的停用词组成,每一行为一个停用词。
建议大家可以下载我得数据集,也可以在私聊我,我可以将数据集发给你们。
2.数据集预处理思路简要介绍和实现代码
(1)将句子通过jieba库进行分词操作。
(2)另外在数据处理过程中我们使用了停用词库。
(3)由于文本分词之后长度不一,但是使用的四个模型都要求长度统一的文本,所以我们对分词之后的单词列表进行调整,为了尽量不是数据丢失,我们将一个句子单词数量设定为20,对于单词小于20的句子进行补足,补‘#’单词,对于单词数量大于20的句子,我们进行裁剪,一般裁剪前20个单词。
(4)考到模型的特性,一般情况下,如果单词小于20,我们是在末尾进行‘#’补足,但是对于TextRNN,考虑到其对信息的记忆,在开头进行‘#’补足,这样,可以更多关注后续的信息。
(5)对于停用词集,我们根据数据集,也自己添加了一部分停用词。
这里我们附上我们的数据预处理代码:
import os
import jieba
import re
string = "This is a string with 12345 numbers"
path=r"D:\work\10-5\use_data"
def get_stop_words():
file_object = open(r'D:\work\10-5\use_data\stopwords.txt',encoding='utf-8')
stop_words = []
for line in file_object.readlines():
line = line[:-1]
line = line.strip()
stop_words.append(line)
return stop_words
stop_words=get_stop_words()
stop_words.append('%')
stop_words.append('\n')
#print(stop_words)
def get_data():
setences=[]
label=[]
setences_test=[]
label_test=[]
for file in os.listdir(path):
print(file)
if file.startswith('s')==False and 'train' in file:
fp=open(path+'//'+file,encoding='utf8')
for line in fp.readlines():
if file.startswith('zp'):
label.append(0)
if file.startswith('zs'):
label.append(1)
if file.startswith('zn'):
label.append(2)
line = re.sub(r'\d+', '', line)
words=jieba.lcut(line, cut_all=False)
words_s=[ i for i in words if i not in stop_words]
if len(words_s)<=20:
for i in range(20-len(words_s)):
words_s=['#']+words_s
else:
words_s=words_s[0:20]
# print(words_s)
words_s=" ".join(words_s)
# print(words_s)
setences.append(words_s)
fp.close()
if file.startswith('s')==False and 'test' in file:
fp=open(path+'//'+file,encoding='utf8')
for line in fp.readlines():
if file.startswith('zp'):
label_test.append(0)
if file.startswith('zs'):
label_test.append(1)
if file.startswith('zn'):
label_test.append(2)
line = re.sub(r'\d+', '', line)
words=jieba.lcut(line, cut_all=False)
words_s=[ i for i in words if i not in stop_words]
# print(words_s)
if len(words_s)<20:
for i in range(20-len(words_s)):
words_s=['#']+words_s
else:
words_s=words_s[0:20]
words_s=" ".join(words_s)
print(words_s)
setences_test.append(words_s)
fp.close()
return setences,label,setences_test,label_test
3.TextCNN 文本分类实战
在这个算法中,对每个单词赋予一个随机的词向量,让后堆叠成图像那样的二维矩阵,之后使用卷积神经网络的方式,对其进行卷积操作。模型如下图:
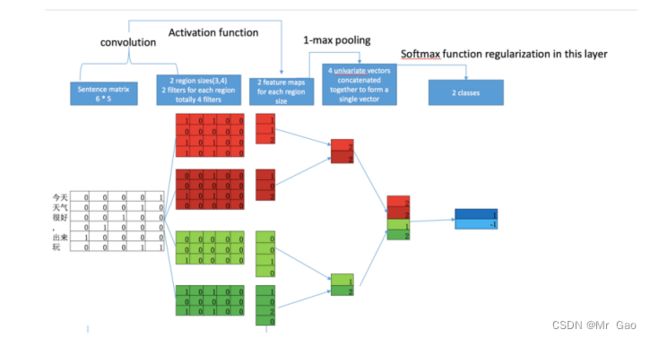
模型我们就不介绍了,这里我们直接附上实现代码,并且该代码还涉及模型评估的代码:
#coding=gbk
from cgi import test
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from data_process import get_data
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3 words sentences (=sequence_length is 3)
import matplotlib.pyplot as plt
sentences,labels,setences_test,label_test=get_data()
print(sentences,labels)
#sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
#labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.
embedding_size = 100
num_classes = len(set(labels))
batch_size = 10
classnum=3
sequence_length = 20
word_list = " ".join(sentences).split()
word_list2 = " ".join(setences_test).split()
vocab = list(set(word_list+word_list2))
word2idx = {w:i for i,w in enumerate(vocab)}
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
l=[word2idx[n] for n in sen.split()]
if len(l)<sequence_length:
length=len(l)
for i in range(sequence_length-length):
l.append(0)
inputs.append(l)
else:
inputs.append(l[0:sequence_length])
targets = []
for out in labels:
targets.append(out)
return inputs, targets
input_batch, target_batch = make_data(sentences, labels)
print(input_batch, target_batch)
print("fdsfafas")
input_batch= torch.LongTensor(input_batch)
target_batch= torch.LongTensor(target_batch)
print("*"*100)
print(input_batch.size(),target_batch.size())
dataset = Data.TensorDataset(input_batch,target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
epoch=100
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
output_channel = 3
self.conv = nn.Sequential(nn.Conv2d(1, output_channel, kernel_size=(4,embedding_size)), # inpu_channel, output_channel, 卷积核高和宽 n-gram 和 embedding_size
nn.ReLU(),
nn.MaxPool2d((2,1)))
self.fc = nn.Linear(24,num_classes)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
embedding_X = self.W(X) # [batch_size, sequence_length, embedding_size]
embedding_X = embedding_X.unsqueeze(1) # add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
conved = self.conv(embedding_X) # [batch_size, output_channel,1,1]
flatten = conved.view(batch_size, -1)# [batch_size, output_channel*1*1]
output = self.fc(flatten)
return output
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
loss_list=[]
# Training
for epoch in range(epoch):
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
loss_list.append(loss)
if (epoch + 1) % 5 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
#test
input_batch, target_batch = make_data(setences_test, label_test)
print(input_batch, target_batch)
print("fdsfafas")
input_batch= torch.LongTensor(input_batch)
target_batch= torch.LongTensor(target_batch)
print("*"*100)
print(input_batch.size(),target_batch.size())
dataset = Data.TensorDataset(input_batch,target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
test_loss = 0
correct = 0
total = 0
target_num = torch.zeros((1,classnum))
predict_num = torch.zeros((1,classnum))
acc_num = torch.zeros((1,classnum))
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
print(pred.argmax(1))
print(batch_y)
test_loss += loss
_, predicted = torch.max(pred.data, 1)
total += batch_y.size(0)
correct += predicted.eq(batch_y.data).cpu().sum()
pre_mask = torch.zeros(pred.size()).scatter_(1, predicted.cpu().view(-1, 1), 1.)
predict_num += pre_mask.sum(0)
tar_mask = torch.zeros(pred.size()).scatter_(1, batch_y.data.cpu().view(-1, 1), 1.)
target_num += tar_mask.sum(0)
acc_mask = pre_mask*tar_mask
acc_num += acc_mask.sum(0)
recall = acc_num/target_num
precision = acc_num/predict_num
F1 = 2*recall*precision/(recall+precision)
accuracy = acc_num.sum(1)/target_num.sum(1)
recall = (recall.numpy()[0]*100).round(3)
precision = (precision.numpy()[0]*100).round(3)
F1 = (F1.numpy()[0]*100).round(3)
accuracy = (accuracy.numpy()[0]*100).round(3)
# 打印格式方便复制
print('recall'," ".join('%s' % id for id in recall))
print('precision'," ".join('%s' % id for id in precision))
print('F1'," ".join('%s' % id for id in F1))
print('accuracy',accuracy)
plt.plot(loss_list,label='TextCNN')
plt.legend()
plt.title('loss-epoch')
plt.show()
模型跑出的结果如下:
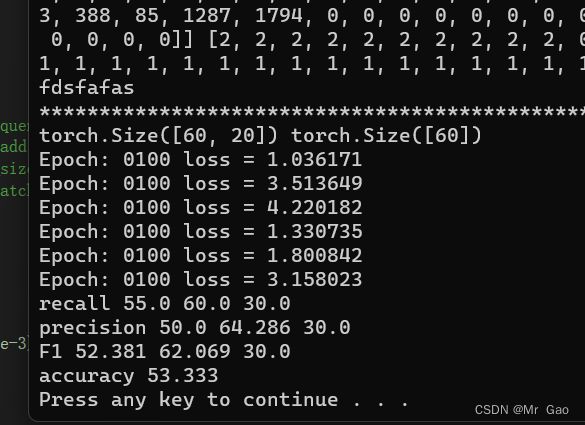
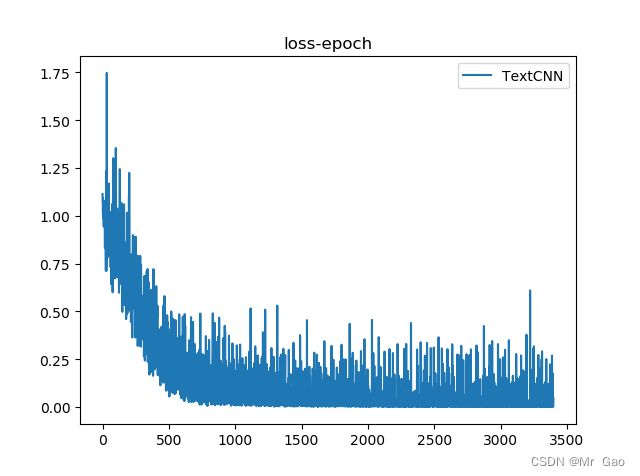
3.TextRNN 文本分类实战
在这个算法中,进行Word Embedding后,输入到双向LSTM中,然后对最后一位的输出输入到全连接层中,在对其进行softmax分类即可,模型如下图:
网络结构图如下:
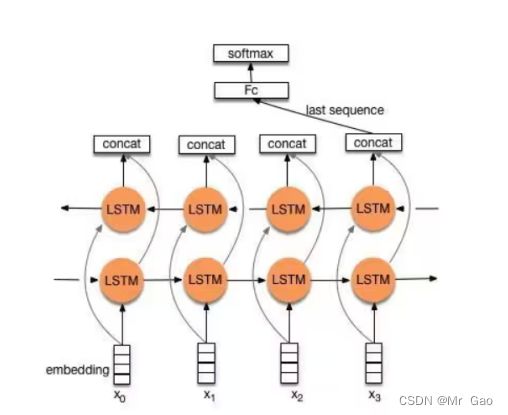
代码如下
#coding=gbk
from cgi import test
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from data_process import get_data
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3 words sentences (=sequence_length is 3)
import matplotlib.pyplot as plt
def make_data(sentences):
input_data = []
input_label = []
for sen in sentences:
words = sen.split()
input_data_tmp = [word2id[i] for i in words[:-1]]
input_label_tmp = word2id[words[-1]]
input_data.append(np.eye(vocab_size)[input_data_tmp])
input_label.append(input_label_tmp)
return input_data, input_label
class TextRNN(nn.Module):
def __init__(self):
super(TextRNN, self).__init__()
# 每个词向量的维度是词表长度,隐藏层输出特征大小是n_hidden
self.rnn = nn.RNN(input_size=vocab_size, hidden_size=n_hidden)
self.fc = nn.Linear(n_hidden, vocab_size)
def forward(self, h0, X):
# X: [batch_size, n_step, vocab_size]
the_input = X.transpose(0, 1) # RNN需要的数据得一二维度转置一下
# RNN的输入是X和
# RNN层会返回所有x1,x2对应的输出为out,我们只取最后一个输出
# hidden是最后一个词计算得到的隐藏状态(符号RNN的图)
# print("fds",the_input.size(),h0.size())
out, hidden = self.rnn(the_input, h0)
out = out[-1]
res = self.fc(out)
return res
if __name__ == '__main__':
# 准备一些简单的数据
sentences,labels,setences_test,label_test=get_data()
print(sentences,labels)
#sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
#labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.
for i in range(len(sentences)):
sentences[i]=sentences[i]+' '+str(labels[i])
for i in range(len(setences_test)):
setences_test[i]=setences_test[i]+' '+str(label_test[i])
embedding_size = 100
sequence_length = 20
num_classes = len(set(labels))
batch_size = 10
word_list = " ".join(sentences).split()
word_list2 = " ".join(setences_test).split()
word_list=['0','1','2']+word_list
vocab = list(set(word_list+word_list2))
epoch=100
n_step = 20 # n_step是输入的话的x部分的长度,因为我们的话只有三个单词所以就是2
n_hidden = 100 # 隐藏输出特征的大小
word2id = {w: i for i, w in enumerate(vocab)}
id2word = {i: w for i, w in enumerate(vocab)}
vocab_size = len(vocab)
# 构造dataset, dataloader
input_data, input_label = make_data(sentences)
# print( input_data, input_label)
#for i in input_data[0:10]:
# print(i)
# print(i[0])
# print(len(i))
input_data = torch.Tensor(input_data)
input_label= torch.LongTensor(input_label)
dataset = Data.TensorDataset(input_data, input_label)
# 此时得到的输入数据是index形式的,不是向量形式
dataloader = Data.DataLoader(dataset, batch_size, True)
model = TextRNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
loss_list=[]
# 训练部分
for i in range(epoch):
for x, y in dataloader:
h0 = torch.zeros(1, x.shape[0], n_hidden)
pred = model(h0, x)
loss = criterion(pred, y)
loss_list.append(loss)
if (i + 1) % 5 == 0:
print("epoch: ", '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# input = [sen.split()[:2] for sen in sentences]
# # Predict
# hidden = torch.zeros(1, len(input), n_hidden)
# predict = model(hidden, input_data).data.max(1, keepdim=True)[1]
# print([sen.split()[:2] for sen in sentences], '->', [id2word[n.item()] for n in predict.squeeze()])
#test
input_data, input_label = make_data(setences_test)
# print( input_data, input_label)
#for i in input_data[0:10]:
# print(i)
# print(i[0])
# print(len(i))
input_data = torch.Tensor(input_data)
input_label= torch.LongTensor(input_label)
dataset = Data.TensorDataset(input_data, input_label)
# 此时得到的输入数据是index形式的,不是向量形式
dataloader = Data.DataLoader(dataset, batch_size, True)
print("fdsfafas")
classnum=3
test_loss = 0
correct = 0
total = 0
target_num =[0,0,0]
predict_num = [0,0,0]
acc_num =[0,0,0]
for x, y in dataloader:
h0 = torch.zeros(1, x.shape[0], n_hidden)
pred = model(h0, x)
loss = criterion(pred, y)
if (epoch + 1) % 5 == 0:
print("epoch: ", '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
for i in y:
target_num[int(id2word[int(i)])]+=1
test_loss += loss
p=0
for i in pred:
print(i.argmax())
index=int(i.argmax())
if id2word[index] in ['0','1','2']:
predict_num[int(id2word[index])]+=1
print(id2word[index],id2word[p])
if index==int(y[p]):
p=p+1
acc_num[int(id2word[index])]+=1
print(y)
recall = [acc_num[i]/target_num[i] for i in range(3)]
precision = [acc_num[i]/predict_num[i] for i in range(3)]
F1 = [2*recall[i]*precision[i]/(recall[i]+precision[i]) for i in range(3)]
accuracy = sum(acc_num)/sum(target_num)
# 打印格式方便复制
print('recall'," ".join('%s' % id for id in recall))
print('precision'," ".join('%s' % id for id in precision))
print('F1'," ".join('%s' % id for id in F1))
print('accuracy',accuracy)
plt.plot(loss_list,label='TextRNN')
plt.legend()
plt.title('loss-epoch')
plt.show()
评估结果:
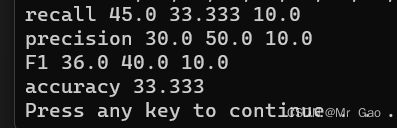
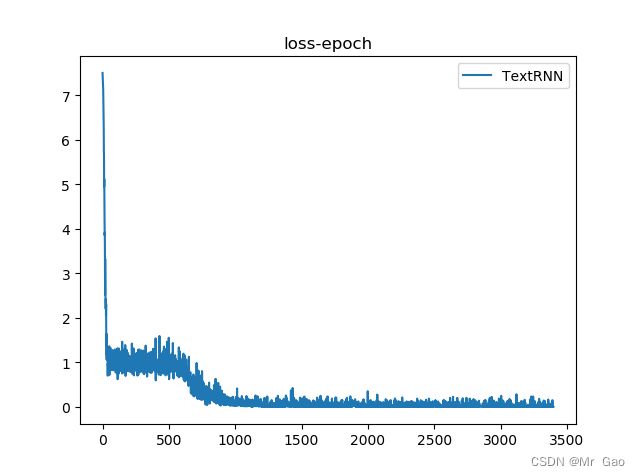
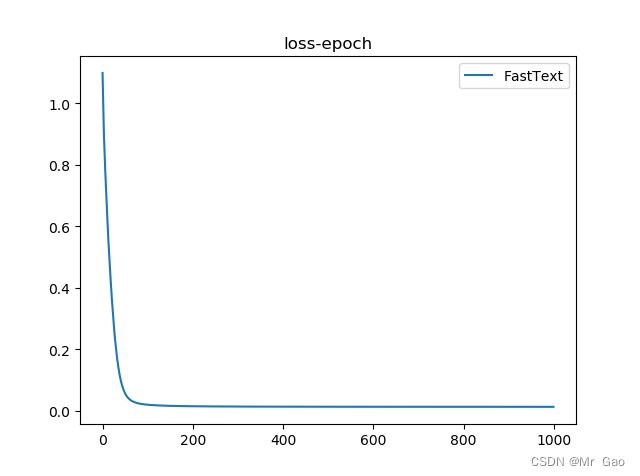
5.FastText 文本分类实战
FastText使用x1,x2…xn表示一个ngram向量,其使用多个向量来表示一个词,然后再使用全部的ngram去预测指定的类别。
网络结构如下:
实现代码如下:
#coding=gbk
import torch
import torch.nn as nn
import torch.optim as optim
import pandas as pd
import numpy as np
from data_process import get_data
import matplotlib.pyplot as plt
loss_list=[]
class FastText(nn.Module):
def __init__(self, vocab, w2v_dim, classes, hidden_size):
super(FastText, self).__init__()
#创建embedding
self.embed = nn.Embedding(len(vocab), w2v_dim) #embedding初始化,需要两个参数,词典大小、词向量维度大小
self.embed.weight.requires_grad = True #需要计算梯度,即embedding层需要被训练
self.fc = nn.Sequential( #序列函数
nn.Linear(w2v_dim, hidden_size), #这里的意思是先经过一个线性转换层
nn.BatchNorm1d(hidden_size), #再进入一个BatchNorm1d
nn.ReLU(inplace=True), #再经过Relu激活函数
nn.Linear(hidden_size, classes)#最后再经过一个线性变换
)
def forward(self, x):
x = self.embed(x.type(dtype=torch.LongTensor)) #先将词id转换为对应的词向量
out = self.fc(torch.mean(x, dim=1)) #这使用torch.mean()将向量进行平均
return out
def train_model(net, epoch, lr, data, label): #训练模型
print("begin training")
net.train() # 将模型设置为训练模式,很重要!
optimizer = optim.Adam(net.parameters(), lr=lr) #设置优化函数
Loss = nn.CrossEntropyLoss() #设置损失函数
for i in range(epoch): # 循环
optimizer.zero_grad() # 清除所有优化的梯度
output = net(data) # 传入数据,前向传播,得到预测结果
loss = Loss(output, label) #计算预测值和真实值之间的差异,得到loss
loss_list.append(loss)
loss.backward() #loss反向传播
optimizer.step() #优化器优化参数
# 打印状态信息
print("train epoch=" + str(i) + ",loss=" + str(loss.item()))
print('Finished Training')
predict_list=[]
def model_test(net, test_data, test_label):
net.eval() # 将模型设置为验证模式
correct = 0
total = 0
with torch.no_grad():
outputs = net(test_data)
# torch.max()[0]表示最大值的值,troch.max()[1]表示回最大值的每个索引
_, predicted = torch.max(outputs.data, 1) # 每个output是一行n列的数据,取一行中最大的值
total += test_label.size(0)
print(test_label)
print(predicted)
predict_list.append(predicted)
# correct += (predicted == test_label).sum().item()
correct += (predicted == test_label).sum().item()
print('Accuracy: %d %%' % (100 * correct / total))
if __name__ == "__main__":
#这里没有写具体数据的处理方法,毕竟大家所做的任务不一样
sentences,labels,setences_test,label_test=get_data()
print(sentences,labels)
#sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
#labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.
#for i in range(len(sentences)):
# sentences[i]=sentences[i]+' '+str(labels[i])
#for i in range(len(setences_test)):
# setences_test[i]=setences_test[i]+' '+str(label_test[i])
word_list = " ".join(sentences).split()
word_list2 = " ".join(setences_test).split()
word_list=['0','1','2']+word_list
vocab = list(set(word_list+word_list2))
vocab_size=len(vocab)
batch_size = 64
epoch = 1000 # 迭代次数
w2v_dim = 300 # 词向量维度
lr = 0.001
hidden_size = 128
classes = len(set(labels))
word2id = {w: i for i, w in enumerate(vocab)}
id2word = {i: w for i, w in enumerate(vocab)}
sequence_length=20
def make_data(sentences, labels):
inputs = []
for sen in sentences:
l=[word2id[n] for n in sen.split()]
if len(l)<sequence_length:
length=len(l)
for i in range(sequence_length-length):
l.append(0)
inputs.append(l)
else:
inputs.append(l[0:sequence_length])
targets = []
print("labels",labels)
for out in labels:
targets.append(out)
return inputs, targets
input_data, input_label = make_data(sentences,labels)
# print( input_data, input_label)
#for i in input_data[0:10]:
# print(i)
# print(i[0])
# print(len(i))
input_data = torch.Tensor(input_data)
input_label= torch.LongTensor(input_label)
# 定义模型
net = FastText(vocab=vocab, w2v_dim=w2v_dim, classes=classes, hidden_size=hidden_size)
# 训练
print("开始训练模型")
train_model(net, epoch, lr, input_data, input_label)
# 保存模型
print("开始测试模型")
input_data, input_label= make_data(setences_test,label_test)
# print( input_data, input_label)
#for i in input_data[0:10]:
# print(i)
# print(i[0])
# print(len(i))
input_data = torch.Tensor(input_data)
input_label= torch.LongTensor(input_label)
model_test(net, input_data, input_label)
test_loss = 0
correct = 0
total = 0
target_num =[0,0,0]
predict_num = [0,0,0]
p=0
acc_num =[0,0,0]
for i in label_test:
target_num[i]+=1
for i in predict_list[0]:
print(i.argmax())
index=int(i)
if index in [0,1,2]:
predict_num[index]+=1
print(id2word[index],id2word[p])
if index==label_test[p]:
acc_num[index]+=1
p=p+1
recall = [acc_num[i]/target_num[i] for i in range(3)]
precision = [acc_num[i]/predict_num[i] for i in range(3)]
F1 = [2*recall[i]*precision[i]/(recall[i]+precision[i]) for i in range(3)]
accuracy = sum(acc_num)/sum(target_num)
plt.plot(loss_list,label='FastText')
plt.legend()
plt.title('loss-epoch')
plt.show()
# 打印格式方便复制
print('recall'," ".join('%s' % id for id in recall))
print('precision'," ".join('%s' % id for id in precision))
print('F1'," ".join('%s' % id for id in F1))
print('accuracy',accuracy)
评估结果:

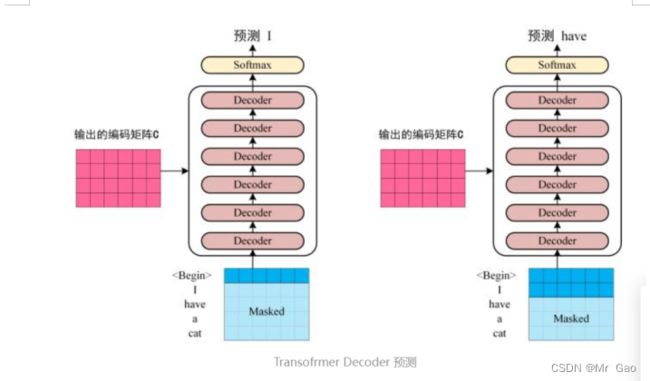
6.Transfermer 文本分类实战
对于Transfermer算法,我们将其decoder的输入用特殊字符#代替,这样其原本的翻译模型也可以修改为分类模型了。
其网络结构图如下:
Transfermer的代码比较多:
#coding=gbk
from cgi import test
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
from data_process import get_data
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3 words sentences (=sequence_length is 3)
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentencesz,labels,setences_test,label_test=get_data()
sentences_t=[]
for i in range(len(sentencesz)):
a=[]
sentencesz[i]=' '.join(sentencesz[i].split())
a.append(sentencesz[i])
a.append('#')
a.append(str(labels[i]))
sentences_t.append(a)
print(sentences_t)
sentences=sentences_t
word_list = " ".join(sentencesz).split()
word_list2 = " ".join(setences_test).split()
word_list=word_list
vocab = list(set(word_list+word_list2))
# Padding Should be Zero
#src_vocab = {'P' : 0, 'ich' : 1, 'mochte' : 2, 'ein' : 3, 'bier' : 4, 'cola' : 5}
src_vocab = {w: i for i, w in enumerate(vocab)}
src_vocab_size = len(src_vocab)
tgt_vocab = {'0' : 0, '1' : 1, '2' : 2, '#' : 3}
setences_test_z=[]
for i in range(len(setences_test)):
a=[]
setences_test[i]=' '.join(setences_test[i].split())
a.append(setences_test[i])
a.append('#')
a.append(str(label_test[i]))
setences_test_z.append(a)
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 20 # enc_input max sequence length
tgt_len = 1 # dec_input(=dec_output) max sequence length
def make_data(sentences):
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
enc_inputs_test, dec_inputs_test, dec_outputs_test = make_data(setences_test_z)
print("enc_inputs",enc_inputs)
print("dec_inputs",dec_inputs,)
print("dec_outputs",dec_outputs)
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 40, True)
loader_test = Data.DataLoader(MyDataSet(enc_inputs_test, dec_inputs_test, dec_outputs_test), 1, True)
# Transformer Parameters
d_model =500 # Embedding Size
d_ff = 1000 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
#for enc_inputs, dec_inputs, dec_outputs in loader:
# print(enc_inputs, dec_inputs, dec_outputs)
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table)
def get_attn_pad_mask(seq_q, seq_k):
'''
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], False is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
def get_attn_subsequence_mask(seq):
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, attn
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model)(output + residual), attn
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model)(output + residual) # [batch_size, seq_len, d_model]
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
'''
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len]
'''
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(src_vocab_size, d_model),freeze=True)
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
'''
enc_inputs: [batch_size, src_len]
'''
word_emb = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
pos_emb = self.pos_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs = word_emb + pos_emb
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = []
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
'''
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_vocab_size, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
'''
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batsh_size, src_len, d_model]
'''
word_emb = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
pos_emb = self.pos_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = word_emb + pos_emb
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequent_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0) # [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
'''
# tensor to store decoder outputs
# outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
model = Transformer()
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.000008)
loss_list=[]
for epoch in range(35):
co=0
to=0
for enc_inputs, dec_inputs, dec_outputs in loader:
'''
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
# enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
#print(outputs.argmax(1))
#print(dec_outputs)
index=outputs.argmax(1)
print(index)
#print(dec_outputs)
for i in range(len(dec_outputs)):
if index[i]==dec_outputs[i]:
co+=1
to=to+len(index)
loss = criterion(outputs, dec_outputs.view(-1))
loss_list.append(loss)
# print(outputs,dec_outputs)
# print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("epoch is: ",epoch)
print("accurac is: ",co/to)
enc_inputs, dec_inputs, _ = next(iter(loader))
print("test")
correct=0
total=0
for enc_inputs, dec_inputs, dec_outputs in loader_test:
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
#print(outputs.argmax(1))
#print(dec_outputs)
index=outputs.argmax(1)
print(index)
#print(dec_outputs)
for i in range(len(dec_outputs)):
if index[i]==dec_outputs[i]:
correct+=1
total=total+len(index)
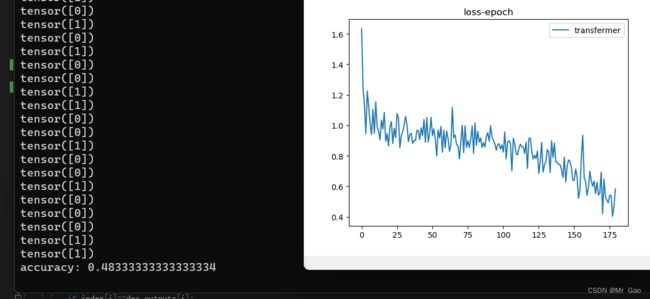
print( "accuracy:",correct/total)
plt.plot(loss_list,label='transfermer')
plt.legend()
plt.title('loss-epoch')
plt.show()
评估结果如下:
好的,这次实验,博主认为可以对于大家在学习这几个模型有着一些帮助。