Spring Cloud日志集中化处理:ELK + Kafka
本文示例代码已上传至github:
https://github.com/ZhaiBo/microservice-scaffold
为什么需要对微服务日志做集中化处理
在微服务架构下,各个基础服务可能使用集群方式部署在不同的机器上,这样日志查看就变得非常困难,一旦服务出现问题,在大量的日志下很难定位问题,所以就需要对微服务日志进行集中式处理,以便于我们查找、定位问题。
ELK是目前主流的日志收集处理方案,具有良好的性能和美观的界面,所以我们采用如下方案来对SpringCloud日志进行集中化处理:

为什么需要kafka
原因有两点:
- 保证LogStash可用性。当业务量增大时,日志跟着增多,直接传入会使LogStash压力过大,可能挂掉,所以需要增加一个缓冲区。
- 日志数据解耦。为其他数据分析平台提供日志,可从Kafka中获取日志进行实时分析处理。
安装Kafka
使用Github上的开源项目来快速搭建Kakfa环境。
克隆代码到本地
使用此命令克隆elk到本地,git clone https://github.com/wurstmeister/kafka-docker.git
可以看到如下文件:
修改配置
修改docker-compose-single-broker.yml文件,KAFKA_ADVERTISED_HOST_NAME为Kafka部署的IP;
vim docker-compose-single-broker.yml

修改docker-compose.yml文件,KAFKA_ADVERTISED_HOST_NAME为Kafka部署的IP;
vim docker-compose.yml

启动
docker-compose up -d
看到控制台打印以下信息,说明启动成功:
![]()
安装elk
同上,github上已经有成熟的elk搭建方案,所以我们直接使用github上的开源方案来搭建elk。
克隆代码到本地
使用此命令克隆elk到本地,git clone https://github.com/deviantony/docker-elk.git
可以看到如下文件:

修改配置
修改docker-elk/logstash/pipeline/目录下的logstash.conf,将tcp方式改为kafka:
input {
# tcp {
# port => 5000
# }
kafka {
id => "ms_id001"
bootstrap_servers => "YOUR-KAFKA-HOST" # 这里要修改为你的Kafka地址
topics => "test"
auto_offset_reset => "latest"
}
}
## Add your filters / logstash plugins configuration here
filter {
grok {
match => {
"message" => "%{TIMESTAMP_ISO8601:logTime} %{GREEDYDATA:logThread} %{LOGLEVEL:logLevel} %{GREEDYDATA:logClass} %{GREEDYDATA:logContent}"
}
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "elastic"
password => "changeme"
}
}
logstash自定义日志格式
见上述配置文件中filter>grok>match下,详细的partterns可参考下面链接:
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
启动
在此目录下使用docker-compose up -d命令来启动elk,看到控制台信息,则说明启动正常。

验证
访问http://localhost:5601,输入用户名:elastic,密码:changeme,看到如下页面,即代表启动成功。

SpringBoot整合ELK + Kafka
引入maven包
<dependency>
<groupId>com.github.danielwegener</groupId>
<artifactId>logback-kafka-appender</artifactId>
<version>0.2.0-RC2</version>
</dependency>
配置logback-spring.xml
在SpringBoot应用resources目录下创建logback-spring文件,写入如下所示内容。
需要注意的有以下两点:
- 配置文件下Kafka配置要根据自己的Kafka配置来修改。
- pattern是和logstash下filter>grok>match的内容相互对应。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration>
<configuration>
<springProperty scope="context" name="kakfaHost" source="logging.kafka.host" defaultValue="localhost"/>
<include resource="org/springframework/boot/logging/logback/base.xml"/>
<appender name="KAFKA" class="com.github.danielwegener.logback.kafka.KafkaAppender">
<encoder>
<pattern>
%d{yyyy-MM-dd HH:mm:ss SSS} [%thread] %-5level %logger{50} - %msg%n
</pattern>
</encoder>
<topic>test</topic>
<appender-ref ref="CONSOLE"/>
<producerConfig>bootstrap.servers=YOUR-KAFKA-HOST</producerConfig>
<keyingStrategy class="com.github.danielwegener.logback.kafka.keying.NoKeyKeyingStrategy"/>
<deliveryStrategy class="com.github.danielwegener.logback.kafka.delivery.AsynchronousDeliveryStrategy"/>
</appender>
<root level="INFO">
<appender-ref ref="KAFKA"/>
<appender-ref ref="CONSOLE"/>
</root>
</configuration>
启动应用验证
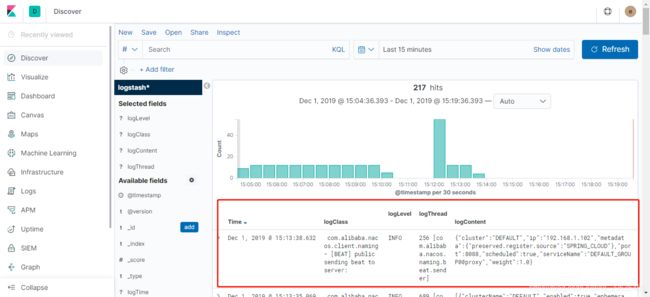
应用启动成功后,可登入Kibana控制台查看应用日志是否成功写入。可以看到应用日志已经按照我们自定义的格式写入到ES中。
至此,使用SpringCloud集成ELK + Kafka集中化日志处理已完成。