开放目标检测Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection 论文阅读笔记
开放目标检测Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- Detection Transformers
- Open-Set Object Detection
- 四、Grounding DINO
-
- 4.1 特征提取和增强器
- 4.2 语言引导的 Query 选择
- 4.3 跨模态解码器
- 4.4 子句层次的文本特征
- 4.5 损失函数
- 五、实验
-
- 5.1 实验设置
-
- 实施细节
- 5.2 ZeroShot Transfer of Grounding DINO
-
- COCO Benchmark
- LVIS Benchmark
- ODinW Benchmark
- 5.3 Referring Object Detection Settings
- 5.4 消融实验
- 5.5 从 DINO 迁移到 Grounding DINO
- 六、结论
-
- 限制
- A、更多的实施细节
- B、数据的使用
- C、更多在 COCO enchmarks 上的结果
-
- C.1 在 1x 设置下的 COCO 检测结果
- D、在 ODinW 数据集上的结果
- E、DINO 和 Grounding DINO 的比较
- F、可视化
- G、添加了 Stable Diffusion 的 Grounding DINO
-
- 采用 GLIGEN 用于定位生成
- H、RefC 和 COCO 数据集上的结果
- I、模型效率
写在前面
这篇论文在桌面搁置好久了,今个来做下笔记。这篇论文的模型和实验结果都很强的。
- 论文地址:Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
- 代码地址:https://github.com/IDEA-Research/GroundingDINO
- 预计投稿于:CVPR 2024
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
本文提出一个开放目标检测器 Grounding DINO,采用基于 Transformer 的 DINO 框架+预训练,能够检测任意输入类别或表达式对应的目标。开放目标检测的关键在于引入语言到一个闭集的检测器中,从而实现开放的概念泛化。于是本文提出将闭集的检测器划分为三个阶段并提出一种轻量化的融合方法,包含一个特征增强器,一个语言引导的 query 选择,一个跨模态的检测器用于跨模态融合。之前的工作主要评估模型在新类别上的性能,而本文也提出在指代表达式理解进行评估。实验表明 Grounding DINO 性能很强。

二、引言
本文旨在提升系统对开放目标检测的能力。这一任务的应用很广,例如图像编辑等。接下来是对开放目标检测所需的能力进行介绍,和摘要部分重合的就略过了。
本文提出 Grounding DINO,相比 CLIP 有一些优势:首先基于 Transformer 的框架与语言模型类似,能够处理图像和语言数据;基于 Transformer 的检测器能够利用大规模数据集;DINO 能够端到端优化,无需使用任何手工设计的模块,例如 NMS。
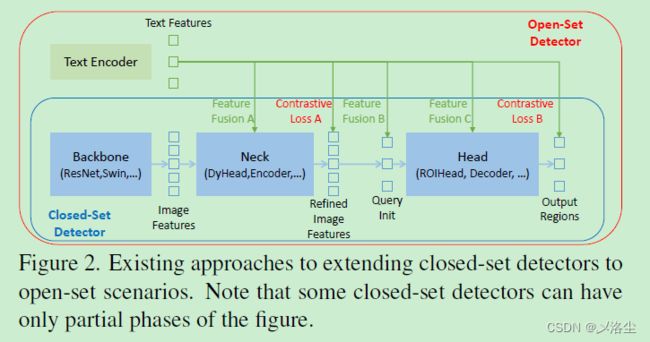
如上图所示,一个闭集的检测器通常包含三个模块:Backbone 用于特征提取,Neck 用于特征增强,Head 用于区域提炼或 box 预测。通过学习语言感知的区域 embedding,闭集的检测器能够检测到新目标。关键是在 neck/head 的输出上,采用输出区域特征和语言特征间的对比损失。
本文认为更多的特征融合能够让模型性能更强。需要注意的是检索任务仅执行多模态特征的对比。对于开放目标检测而言,模型需要根据文本输入来确定图像中的特定目标。在这种情况下,一个早期的融合模块将更有利于性能的提升。接下来是对之前一些目标检测工作和 DINO 的介绍,略过。
在 Neck 阶段,本文设计三种特征融合方法分别在Neck、query 初始化、head 阶段应用。具体来说,通过堆叠 self-attention、text-toimage cross-attention、image-to-text cross-attention 作为 neck 模块得到特征增强器。之后提出一种语言引导的 query 选择模块来初始化 queries 用于 head。
除重要的图像场景外,本文还考虑了指代表达式理解的场景 Referring Expression Comprehension (REC),这是个更加关联的场景,但被以往的工作忽略了。
实验在三种设置下进行:闭集检测、开放检测、指代目标检测。Grounding DINO 的性能很强。本文贡献总结如下:
- 提出 Grounding DINO,拓展闭集检测器 DINO,在多个阶段执行视觉-语言模态融合,其中包含一个特征增强器、跨模态解码器。
- 将开放目标检测拓展到 REC 数据集上,评估任意文本输入下的模型性能。
- 实验表明效果很好。
三、相关工作
Detection Transformers
Grounding DINO 建立在 DINO 之上,接着介绍 DETR、DAB-DETR、DN-DETR、DINO。
Open-Set Object Detection
开放目标检测采用现有的 bounding box 标注,旨在语言泛化的基础上检测任意的类别。之后介绍了 OV-DETR、ViLD、GLIP、DetCLIP。这些方法仅关注在部分阶段融合多模态信息,可能会导致次优的语言泛化能力。例如,GLIP 仅考虑在特征增强阶段融合。此外,REC 任务在评估时通常被忽略,而这对开放目标检测来说是个重要场景。
四、Grounding DINO
输入一组图像-文本对,Grounding DINO 输出多个目标 box 和名词短语对,例如下图中的 “cat” 和 “table”。目标检测任务和 REC 任务都通用下面这个框架。

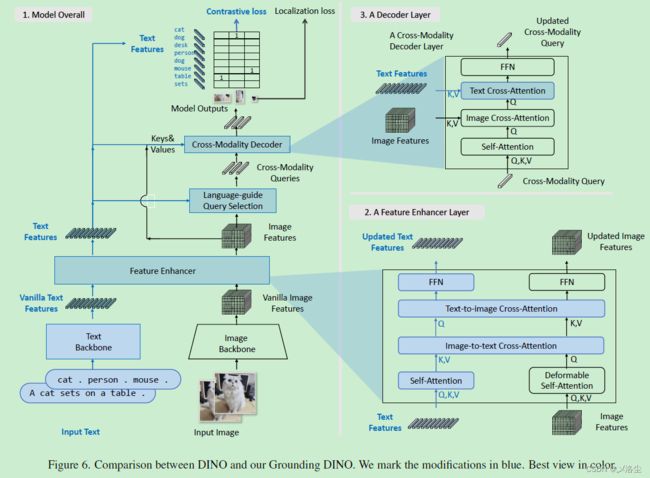
与 CLIP 类似,将所有类别名拼接作为输入的文本,用于目标检测任务。对于 REC 任务,输出最大得分的 box。Grounding DINO 是个双编码器单解码器的结构,包含一个图像 Backbone 用于图像特征提取,一个文本 Backbone 用于文本特征提取,一个特征增强器用于图文特征融合,一个语言引导的 query 选择模块用于 query 初始化,一个跨模态解码器用于 box 的提炼。
对每一图文对,首先利用图像和文本 Backbone 分别提取原始的图像和文本特征,然后送入特征增强模块用于跨模态的特征融合。在获得跨模态图文特征后,用一个语言引导的 query 选择模块从图像特征中选择跨模态的 queries。之后这些 queries 送入跨模态特征解码器去挖掘两个模态中的合适特征并更新自身。最后一层解码层的输出将会用于预测目标 box 及提取相应的短语。
4.1 特征提取和增强器
给定图文对,采用类似 Swin Tranformer 的图像 Backbone 来提取多尺度的图像特征,采用类似 BERT 的文本编码器 Backbone 来提取文本特征,之后送入特征增强器用于跨模态特征融合。如图 3 block 2所示,增强器包含多个特征增强器层,其内部采用 Deformable self-attention 结构。此外,还添加一个 image-to-text cross-attention 和 text-to-image cross-attention 用于特征融合。
4.2 语言引导的 Query 选择
Grounding DINO 旨在从图像中检测输入文本所对应的特定目标,于是设计一个语言引导的 query 选择模块,选择那些与输入文本更相关的特征用于解码器的 queries。其算法流程如下图所示:

其中变量 image features 和 text features 为图像和文本特征。num query 是解码器的 queries 的数量,实验中设为 900。bs 和 ndim 分别为 batch size 和伪代码中的特征维度。num img tokens 和 num text tokens 分别是图像和文本 tokens 的数量。
语言引导的 query 选择模块输出 num query 索引,基于这些选择的索引来提取出特征,从而作为初始化的 queries。与 DINO 相同,使用混合的 query 选择来初始化解码器 queries。每个解码器 query 包含两部分:content 内容部分和 positional 位置部分。将位置部分塑造为动态 anchor boxes,采用编码器的输出来初始化;内容部分设置为可学习的 embedding。
4.3 跨模态解码器
提出跨模态解码器来结合图像和文本特征。如图 3 block 3 所示,每个跨模态 query 送入一个 self-attention 层,一个图像 cross-attention 层来组合图像特征,一个文本 cross-attention 层来组合文本特征。每个 cross-modality 解码器层都包含一个 FFN 层。相较于 DINO 的解码器层,每个解码器层都有一个额外的文本 cross-attention 层。
4.4 子句层次的文本特征

如上图所示,之前的工作探索了两种文本提示,将其命名为句子级别的表示和单词级别的表示。句子级别的表示将整个句子编码到一个特征中。若一些句子在短语定位数据中有多个短语,则提取这些短语并抛弃其它单词。缺点就是去除语言的流利性,同时也失去了句子的细粒度信息。单词级别的表示能够编码多类别名字但引入了不必要的依赖,特别是当输入的文本是多个类别名以无序的方式拼接时。
于是为了避免不必要的词交互,引入注意力 mask 来阻止注意力与不相干的类别关联,称之为 sub-sentence 子句级别的表示。
4.5 损失函数
采用 L1 损失和 GIoU 损失用于 bounding box 的回归,在预测的目标和语言 tokens 间使用对比损失来分类。具体来说,用文本特征点乘每一个 query ,来预测每个文本 token 的 logits,然后为每个 logit 计算 focal 损失。
具体来说,首先在预测和 GT 间执行双边匹配,然后计算 GT 和匹配到的预测的最终损失。与 DETR 类似,在每个解码器层和编码器的输出后添加辅助损失。
五、实验
5.1 实验设置
三个设定:闭集目标检测 COCO 数据集,开放目标检测 zero-shot COCO、LVIS、ODinW 数据集,指代表达式理解 RefCOCO/+/g 数据集。
实施细节
两个模型变体:Grounding-DINO-T,采用 Swin-T 作为 Backbone;Grounding-DINO-L,采用 Swin-L 作为 Backbone。BERT-base 作为文本 Backbone。主要列出 zero-shot 迁移和指代表达式理解的性能。
5.2 ZeroShot Transfer of Grounding DINO
预训练在大规模数据集上,然后在新的数据集上评估,同时也有一些微调的结果用于比较。
COCO Benchmark
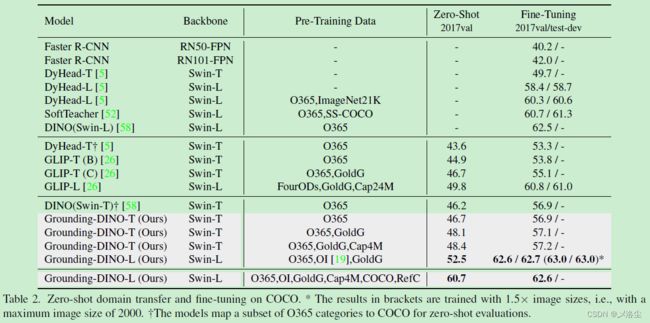
LVIS Benchmark

ODinW Benchmark
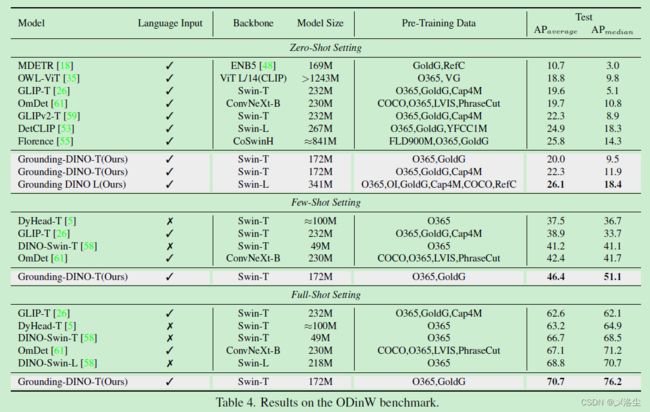
5.3 Referring Object Detection Settings
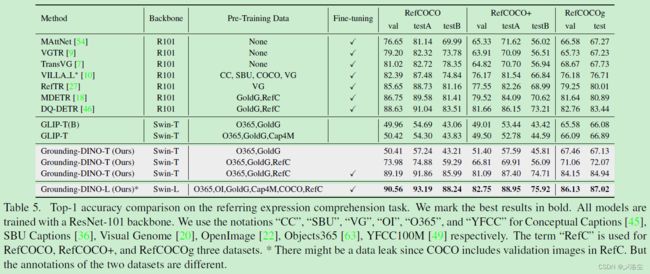
5.4 消融实验
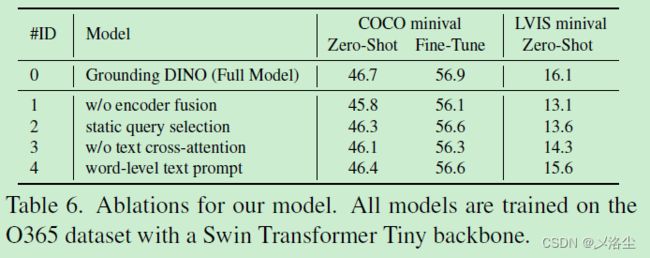
5.5 从 DINO 迁移到 Grounding DINO
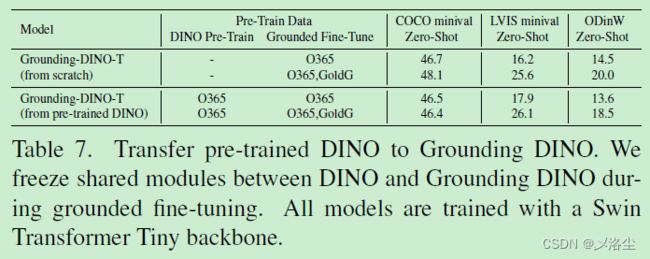

六、结论
本文提出 Grounding DINO 模型,将 DINO 拓展到开放目标检测上,使其能够检测给定文本作为 queries 的目标。回顾开放目标检测的设计,提出一个轻量化的融合方法,提出一个子句级别的表示,实验结果表明模型的设计和融合方法很有效。此外,将开放目标检测拓展到 REC 任务上,在没有微调的情况下,表明现有的开放目标检测器对于 REC 数据,效果不是太好。
限制
Grounding DINO 不能像 GLIPv2 一样执行分割任务,此外训练数据低于大规模 GLIP 模型所使用的,这可能会限制最终的性能。
A、更多的实施细节

最大 token 的数量 256,6 层的特征增强器层,6 层的特征解码器层。Tiny 模型训练用 16 块 V100,Batch_size 32(一般的实验室就别想啦!)。提取三个特征尺度,从 8 到 32;对于 Swin Transformer Large,从 4 到 32,模型训练在 64 块 A100(真 tm 有钱),Batch_size 64。
B、数据的使用
- 检测数据:COCO、O365、OpenImage(OI);
- 定位数据:GoldG、RefC;
- 字幕数据:使用伪标签字幕数据用于模型训练,而一个训练好的模型用于生成这些伪标签。
预训练 Grounding-DINO-T 在 O365v1 上,Grounding-DINO-L 预训练在 O365v2,前者是后者的子集。
C、更多在 COCO enchmarks 上的结果
C.1 在 1x 设置下的 COCO 检测结果
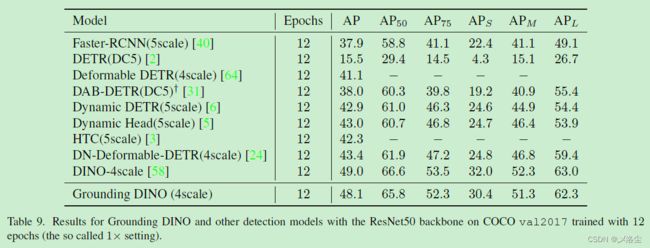
D、在 ODinW 数据集上的结果
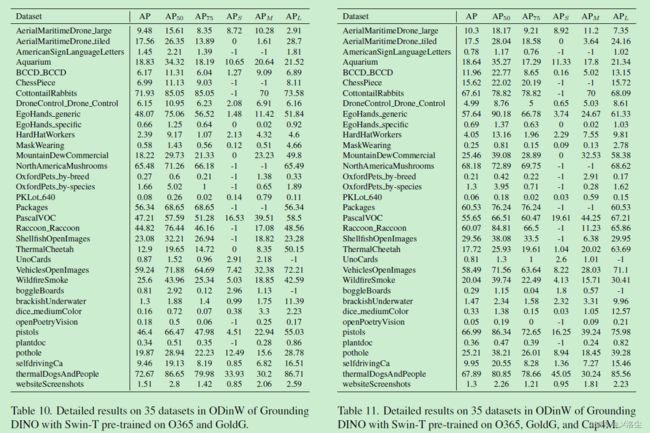

E、DINO 和 Grounding DINO 的比较
F、可视化

G、添加了 Stable Diffusion 的 Grounding DINO
采用 GLIGEN 用于定位生成
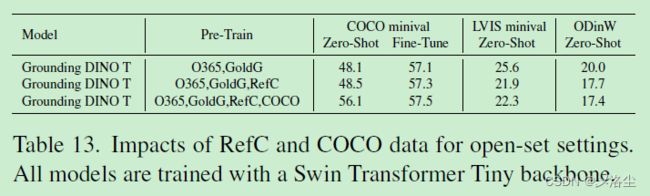
H、RefC 和 COCO 数据集上的结果
I、模型效率

写在后面
这篇文章框架比较简单,但是效果也是显而易见。另外实验非常充足,就是这个附录整的太花里胡哨了,是想强调下工作量嘛?