pandas的Series和DataFrame
文章目录
- pandas的核心类
- Series(数据系列)带标签的数组
-
- 一、创建Series对象
- 二、Series索引和切片
- 三、Series的基本用法
-
- 1.处理空值(缺失值)
- 2.去重
- 3.替换
- DataFrame二维数组
- 一、创建DataFrame
-
- 1.通过数组创建
- 2.用字典创建DataFrame
- 3. 通过读取CSV文件创建DataFrame
- 4.通过读Excel文件创建DataFrame
- 5.读取数据库文件
-
-
- 连接数据库
- 读取mysql中的数据
-
- 6.读取文本文件
- 二、DataFrame的属性
- 1.基本属性
- 2.查看前/后几行数据
- 3.列/行索引(取值)
- 4.添加行/列
- 5.删除行/列
- 6.数据抽样
- 7.数据筛选
- 8.排序
- 三、DataFrame的方法
- pandas的方法
- 一、Pandas统计计算和描述
- 二、索引和复合索引(层次化索引)
-
- 1.简单的索引操作
- 2.Series复合索引
- 3.DataFrame复合索引
- 三、pandas的对齐运算
- 四、pandas的函数应用
- 五、缺失数据的处理
-
- 1.判断数据是否为NaN
- 2.处理方法
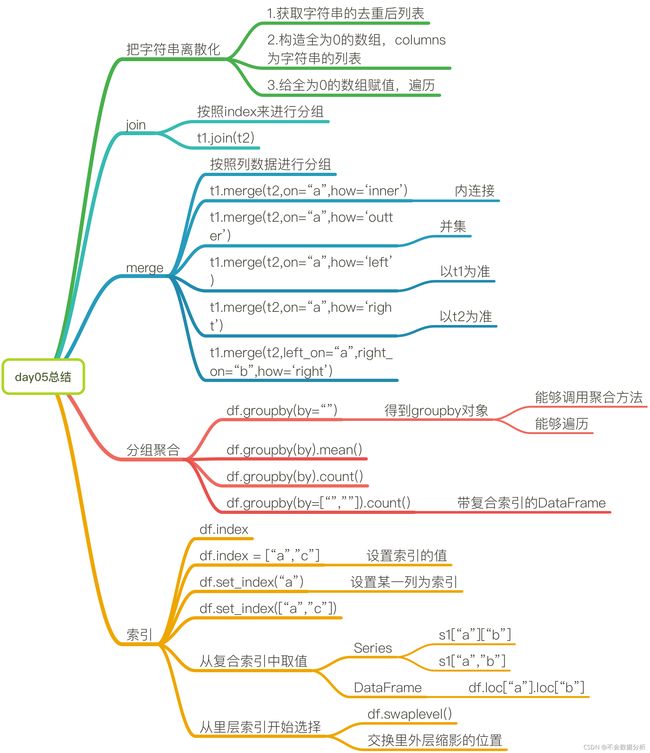
- 六、多表合并与连接
-
- 1.merge 按指定列将多表进行连接
- 2.Join——根据行索引合并数据
- 3. concat沿一条轴将多个表合并
- 七、数据聚合与分组运算
-
- group by分组
- 聚合
- 八、文件操作
-
- 1.分块读取大文件
- 九、时间序列
-
- 创建固定频率的时间序列
- 时间重采样
- 创建时期对象
pandas的核心类
Series(一位数组)、DataFrame(二维数组)、Index(索引)
导入pandas:import pandas as pd
Series(数据系列)带标签的数组
一、创建Series对象
1 . ser=pd.Series( 列表/数组/字典 )
ser1=pd.Series([1,2,3])
ser2=pd.Series(np.arange(1,6))
ser3=pd.Series('name':'John','age':18,'score':'95')
通过字典创建时索引可以比值多,其他方法索引和值的个数必须相同
ser1=pd.Series(np.random.randint(10,100,5))
ser1
#索引 数据
#0 56
#1 78
#2 22
#3 42
#4 14
#dtype: int32 (元素类型)
2.可以直接在创建Series数组时创建索引
①:
ser = pd.Series(
data=[value1,value2,value3,...],
index=[index1,index2,index3,...]
ser
②:
ser=pd.Series(
data={
index1:value1,
index2:value2,
....
}
)
二、Series索引和切片
ser [ 元素下标 ]:直接返回该下标对应的值,一次只能取单个元素
ser [ 索引]:选取单个索引
ser [ [ 元素下标1,元素下标2,... ] ]:返回对应的索引和值
ser [ [ 索引1,索引2,...] ]:返回对应的索引和值,当数组中有重复索引时会返回该索引对应的全部值
ser[开始下标:结束下标]:切片
ser[开始索引:结束索引]:切片,包含末端数据
ser[ser>n]:布尔索引取值,返回索引和值,默认找到为True的值
三、Series的基本用法
1.处理空值(缺失值)
判断是否为空:ser.isnull()
不是空值的:ser.notnull
None:Python的空值
np.nan:numpy的空值
删除空值
①ser.dropna( ):返回删除了空值的新的Series对象
②ser.dropna(inplace=True):直接删除原来的Series对象
填充空值
①用指定值 x 填充空值:ser.fillna ( x ),有inplace时改变原来的Series对象
②用空值前面或后面的值填充空值
用前面的值填:ser.ffill( )
用后面的值填:ser.bfill( )
2.去重
获取不重复元素构成的数组 :ser.unique( )
去重:ser.drop_duplicates( )
统计重复次数:
①非重复元素的个数:ser.nunique( )
②统计重复次数:ser.value_counts( )
3.替换
①替换不满足条件的值:ser.where( 判断条件,替换值)
②替换满足条件的值:ser.mask(判断条件,替换值)
DataFrame二维数组
表格型的数据结构,Series容器
一、创建DataFrame
DataFrame对象既有行索引,又有列索引
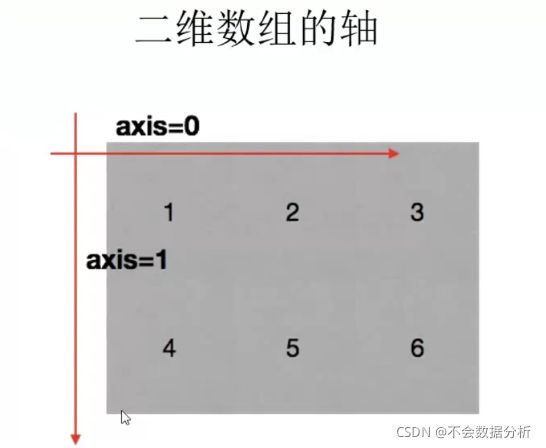
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表明不同列,纵向索引,叫columns,1轴,axis=1
1.通过数组创建
df = pd.DataFrame(
data=[[],[],[],...],
【
index=['a','b','c',...]
columns=['A','B','C',...]
】
)
没给索引命名时默认为0,1,2…
①通过二维数组构造创建:df=pd.DataFrame(np.arange(12),reshape(3,4))
②通过字典构造成的列表创建
#例子
list1=[{'apple':3.6,'banana':3.6},{'apple':3.2,'banana':3.2},{'apple':3.4}]
df=pd.DataFrame(list1)
# apple banana
#0 3.6 3.6
#1 3.2 3.2
#2 3.4 NaN
③通过Series构造的列表创建
list2=[pd.Series(np.random.rand(4)),pd.Series(np.random.rand(3))]
df=pd.DataFrame(list2)
# 0 1 2 3
#0 0.722993 0.856625 0.643983 0.030172
#1 0.695130 0.044956 0.677233 NaN
2.用字典创建DataFrame
用字典创建DataFrame时,字典的键就是列名
①数组、列表、元祖构成的字典构造DataFrame
df=pd.DataFrame(
data={
...
},#字典
index=
)
# 一个例子
df=pd.DataFrame(
data={
'Chinese':[90,92,87,88],
'English':[85,87,88,80],
'Math':[91,93,95,97]
},
index=range(1001,1005)
)
# Chinese English Math
#1001 90 85 91
#1002 92 87 93
#1003 87 88 95
#1004 88 80 97
②Series构成的字典构造DataFrame
df=pd.DataFrame({'a':pd.Series(np.arange(3)),
'b':pd.Series(np.arange(3,5))})
# a b
#0 0 3.0
#1 1 4.0
#2 2 NaN
③字典构成的字典构造DataFrame(字典嵌套)
dic={
'a':{'apple':3.6,'banana':3.6},
'b':{'apple':3.2,'banana':3.3},
'c':{'apple':3.4}
}
df=pd.DataFrame(dic)
# a b c
#apple 3.6 3.2 3.4
#banana 3.6 3.3 NaN
3. 通过读取CSV文件创建DataFrame
读CSV文件,逗号分隔符文件:pd.read_csv('文件路径')
关于行的操作
①设置作为行索引的列:index_col=列名,index_col=[列名1,列名2...]
②设置读取的行数(从前往后读):nrows=n
③跳过指定行(通过索引确定):skiprows=[m,n],跳过m行和n行
列操作 设置需要读取的列:usecols=[列1,列2,....]
④设置列名:names=[列1,列2...]
⑤直接将其中几列转换为日期格式:`parse_dates=[‘列1’【,‘列2’】]
4.通过读Excel文件创建DataFrame
读Excel文件前 装第三方库:!pip install xlrd xlwt openpyxl
:pd.read_excel('.../.../...')
设置工作表表名(针对一个Excel文件中有多张表时):sheet_name='Sheet'
5.读取数据库文件
下载pymysql:!pip install pymysql
导入第三方库:import pymysql
连接数据库
con=pymysql.connect(
host='****',#数据库ip地址
port=3306,#mysql数据库通用端口号
user='****',#数据库账号
password='****',#数据库密码
database='****',#库名
charset='utf8mb4' #数据类型
)
读取mysql中的数据
df=pd.read_sql(
'select a1,a2 from table_name' #sql查询语句从表中查出想要读取的数据,写入df中
con,
index_col=
)
6.读取文本文件
df=pd.read_table('文件名',sep='\s+'):sep用于对行中字段进行拆分的字符序列或正则表达式
二、DataFrame的属性
1.基本属性
df.shape:查看形状
df.values:所有的值,data
df.index:行索引
df.columns:列索引
df.info():查看数据性质
df.T:进行转置(行与列进行转置)
2.查看前/后几行数据
默认查看5行,可在( )中加参数规定查看行数
前几行:df.head( n )
后几行:df.tail( n )
3.列/行索引(取值)
1) 取整行
df [ 开始位置 : 结束位置 ]写数组,表示取行,对行进行操作;
df.loc[ 行索引 , 列索引 ]:标签索引,通过标签 获取行数据,取某行某列的一个值;
df.iloc [ 行索引 ]:位置索引,行索引(默认值),通过位置 获取行数据
2)取整列
df [ 列名 ]:写字符串,表示取列索引,对列进行操作;
3)取n行n列
①某几行的一列:df [ 行开始位置 : 行结束位置 ] [ 列名 ]
② 同时取多行多列df [ 行开始位置 : 行结束位置 ] [ 列开始位置 : 列结束位置 ]
③df.loc[ [行索引1 , 行索引2 , ... ] , [ 列索引1 , 列索引2 , 列索引3 , ....] ]:取不连续的值
④df.loc[m:n,x:y]:取m行到n行,x列到y列的数据
⑤df.loc [ m : n , [ x , y] ]:取m到n行的x列和y列,省略m代表从0行取到n行,省略n代表从m行开始取到最后一行
⑥df.loc[ [ m , n ] , x : y ]:取m行和n行中x列到y列的值,省略x代表从0列取到y列,省略y代表从x列开始取到最后一列
⑦ix标签与位置混合索引:已弃用
冒号在loc里面是闭合的,即会选择到冒号后面的数据
4)赋值更改数据
用索引取值后进行赋值
更改列的值:df[列索引]=新值,df[列名]=新值,df.列=新值,修改为多个不同的值时值用列表表示:[值1,值2,…]
修改行的值:df.loc[ 行名] = 新值
修改某个值:df.loc[行名,列名]=新值
4.添加行/列
1 ) 添加列
①给添加的列赋统一值:df [ 列名 ] ='值'
②给添加的列赋不一样的值:df [ 列名 ]= [ 值1 ,值2 ,... ]
③随机赋值:df [ 列名 ] =[ 随机数组 ]
④在指定位置添加列:df.insert(列下标,'列名',[.值1,值2,..])
2 ) 添加行
df.loc['行名']=[值1,值2,值3...]
df [ 行索引 ]={ 列1 : 值1 , 列2 : 值 , .... }
pd.append(dic,ignore_index=True)
5.删除行/列
1 ) 删除行
index可以省略
①删除行时结果创建一个新表:df.drop( index=行索引 )
②从原表直接删除:df.drop( index=行索引 , inplace=Ture )
③删除多行:df.drop(index=[ 行索引1 , 行索引2 , ....]
2 ) 删除列
del df['列名']
df.drop(列名,axis=1):DataFrame删除列,axis='columns’也是在列上操作
df.drop( columns=列名 , inplace=True ):在原对象上进行删除
6.数据抽样
指定抽样数量: df.sample( n=4 )
按比例抽样: df.sample( frac=0.3 )
7.数据筛选
用布尔索引 筛选数据:df [ ( df.条件1 ) & ( df.条件2) | (df.条件3 ) ],
按Python条件筛选:df.query ( '筛选条件' )
8.排序
df.sort_index():根据索引排序,默认按行索引升序,axis=1按列索引,添加ascending=False参数改为降序排序
df.sort_values( by='列名'):根据值的大小进行排序,缺失值默认排在最后;添加ascending=False参数改为降序排序
三、DataFrame的方法
pandas的方法
一、Pandas统计计算和描述
默认为axis=0按列统计;axis=1时按行统计 ;skipna用来排除缺失值,默认为True
| 函数 | 说明 |
|---|---|
| ser.describe() | 获取描述性统计信息 |
| ser.index | 获取全部索引 |
| ser.values | 获取所有数据 |
| ser.size | 获取元素个数 |
| ser.isin([n]) | 判断值n是否存在,返回布尔类型 |
| ser.head() | 取出前几行数据,默认为前五行 |
| ser.tail() | 取出后几行数据,默认为后五行 |
| ser.sort_values( ) | 按值排序 |
| ser.sort_index( ) | 按索引排序 |
| ser.nlargest( n )、ser.nsmallest( n ) | 找出topN |
| ser.name | 命名,对象名,ser.index.name:对象索引名 |
| ser.is_monotonic | 判断是否单调,默认为递增 |
| ser.is_monotonic_increasing | 判断是否递增 |
| ser.is_monotonic_decreasing | 判断是否递减 |
| ser.map() | 映射 |
| df.sum() | 求和 |
| df.idxmax() | 返回最大值的索引 |
| sample(序列a,n) | 从序列a中随机抽取n个元素,并将n个元素生以list形式返回 |
#ser
#1季度 43
#2季度 51
#3季度 63
#4季度 51
#3季度 53
#2季度 47
ser.map(lambda item:item*100)
#1季度 4300
#2季度 5100
#3季度 6300
#4季度 5100
#3季度 5300
#2季度 4700
常规数据
最大值:ser.max( )
最小值:ser.min( )
均值:ser.mean( )
中值:ser.median( )
二、索引和复合索引(层次化索引)
1.简单的索引操作
获取index:df.index
指定index :df.index = ['x','y']
重新设置index(更改index的顺序) : df.reindex(list("abcedf")),用来创建一个符合新索引的新对象;对Series,调用该 Series 的 reindex 将会根据新索引进行重排。如果某个索引值当前不存在,就引入缺失值。对于 DataFrame, reindex 可以修改行索引、列、或者两个都修改,如果仅传入一个序列,则会重新索引行,使用 columns 关键字即可重新索引列
指定某一列作为index :df.set_index("Country",drop=False),drop表示是否将设为索引的列从数据中去除
重新设置索引:df.reset_index(drop=Ture),将索引设为0-n,drop为True时删除原索引
返回index的唯一值:df.set_index("Country").index.unique()
将层次化索引变为简单索引:df.set_reindex()
2.Series复合索引
有复合索引(层级索引)的Series对象
ser=pd.Series(np.arange(10),index=(['a','b','c','d'],[1,2,3,4]):创建一个有复合索引的Series对象
ser[外层索引]:外层索引
ser[[外层索引1,外层索引2]],ser.loc[[外层索引1,外层索引2]]:取多个
ser[外层索引1:外层索引2]:切片
ser[:][内层索引],ser[:,内层索引]:内层索引
ser[外层索引,内层索引],ser["外层索引"]["内层索引"]
ser.swaplevel():交换全部内外索引
ser.swaplevel()["原内层索引"]["原外层索引"]:交换层次化索引的顺序
3.DataFrame复合索引
df.loc["外层索引"].loc["内层索引"]
三、pandas的对齐运算
pandas执行算术运算时,会先按照索引进行对齐,对齐后再进行相应的运算,没有对齐的位置会用NAN进行补齐。Series是按行索引进行对齐,DataFrame按行索引、列索引进行对齐;
可以在调用add方法时用fill_value使用对象中存在的数据进行补充:df1.add(df2,fill_value=x)
四、pandas的函数应用
1.通过apply将函数应用到列或行 df.apply(函数):默认axis=0列
2.通过applymap将函数运用到每个数据 df.applymap(函数)
五、缺失数据的处理
1.判断数据是否为NaN
np.isnull ( df ),np.notnull( df )
2.处理方法
1 ) 删除NaN所在的行或列
df.dropna(axis=0,how='any',inplace=False)
how=‘any’:any—默认值,当前行或列有一个就删除整行或整列;all—当前行/列全为NaN时才删除该行/列
axis:默认为0;0或index—删除缺失数据所在的行;1或values—删除包含缺失值的列
2 ) 填充数据
df.fillna( 填充值),填充某一列时先取出该列再填充:df[ 列名 ] . fillna(填充值)
df.fillna( t.mean()):用平均数填充
df.fillna( t.median()):
df.fillna(0)
六、多表合并与连接
1.merge 按指定列将多表进行连接
df1.merge (df2 , on=用于连接的列名)
pd.merge(表1(左表) , 表2(右表) , ... , on=通过哪一列进行连接 , 【how= 连接方式(默认为内连接), left_on=None , right_on=None , left_index=False , right_index=False , sort=False ,suffixes=('_x','y')】)
①lef_on/right_on:以左侧或右侧的DateFrame作为连接键
②sort:是否排序,接收布尔值,默认为False
③suffixes:用于追加到重叠列名的末尾,默认为(_x,_y)
④ left_index/right_index:左/右侧的行索引用作连接键
2.Join——根据行索引合并数据
df1 . join (df2 , 【on , how=' ' ,lsuffix=' ' , rsuffix=' ' , sort=False】)
①默认情况下把行索引相同的 数据合并到一起,合并的表不能有重叠列
②on:用于连接的列名
③how可以从{left,right,outer,inner}中选一个,默认使用left方式。
④lsuffix、rsuffix:接收字符串,用于在左/右侧重叠的列名后添加后缀名
⑤sort:用于接收布尔值,根据连接键对合并的数据进行排序,默认为False
3. concat沿一条轴将多个表合并
pd.concat( [ 表1 , 表2 , ...] , axis=0 , join=' outer' , ignore_index=False , keys= ' ' )
①axis:表示连接的轴向,0或1,默认为0(加在原数组下面,按列名对齐);axis=1时加在原数组右边按行名对齐
②join:连接方式,默认使用外连接outer
③ignore_index:接收布尔值,默认为False。为True时表示清楚现有索引并重置索引值
④keys:接收序列,表示添加最外层索引
保存数据到Excel文件中: total_df . to_excel( '文件名.xlsx' )
七、数据聚合与分组运算
group by分组
df.group by (by=None , axis=0 , level=None , as_index=True , sort=True )
1.通过列名进行分组
df.groupby ( by=列名 ):得到一个DataFrameGroupBy对象,可通过遍历该对象查看每个分组具体内容(每组结果为一个元祖)
获取分组后的某一部分数据: df.groupby(by=[ 分组条件1 , 条件2 , ...])[ 需要的部分] . count( )
对某几列数据进行分组(返回DataFrame类型): df[ [需要的部分]] . groupby(by=[df [条件1] , df [条件2] ] ) .count(),df.groupby(by=[条件1 , 条件2])[[需要的部分]].count()
group1=df.groupby(by='colu')
for i in group1:
print(i)
unstack()函数可以将多条件分组后的数据进行压缩,使同组的结果在同一行进行显示
2.通过Series对象进行分组
可以创建Series对象作为分组依据,df.groupby(by=ser),(按索引进行分组)当Series对象索引的长度与Pandas索引长度不同时,只会将具有相同索引长度的数据进行分组。
3.通过字典进行分组
传入表示分组规则的字典,将字典作为分组键进行分组,df.groupby(by=dic ),注意指定轴
4.通过函数进行分组
可以通过内置函数进行分组,例如len()函数
聚合
1.使用内置统计方法聚合函数
| 函数名 | 描述 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的中位数 |
| std, var | 标准差和方差 |
| min, max | 非NA的最小值,最大值 |
| prod | 非NA值的乘积 |
| first, last | 非NA值的第一个,最后一个 |
2.面向列的聚合方式
内置方法不能满足聚合要求时,可以自定义函数,传给agg()方法(aggregate()),实现聚合
d_g.agg(func,axis=0,*args,**kwargs):func----用于汇总数据的函数;axis----函数作用于轴的方向,0或index表示应用与每一列,1或columns表示应用到每一行,默认为0
①对同一列应用同一个函数:d_g.agg(函数)
②对某列应用不同的函数:d_g.agg([('生成的列名',函数1),('生成的列名',函数2)])
③对不同的列应用不同的函数:d_g.agg({'列名1':'函数名1','列名2':'函数名2',....}),传入{‘列名’:‘函数名’}的字典
八、文件操作
写入文件 :df.to_csv('df.csv')
1.分块读取大文件
df=pd.read_csv(file,【chunksize=n】,【iterator=True】):读取文件的n行数据,产生一个可迭代对象,每次df.get_chunk(m) 后得到的数据为上一次的后m行,省略m时默认为n行;
iterator=True:产生可迭代对象
九、时间序列
创建固定频率的时间序列
Datetimeindex:时间戳
pd.data_range(start=None,end=None,periods=None,freq='D')
start:开始时间
end:结束时间
periods:个数,表示生成多少个时间戳索引值
freq:指定计时单位,M\D\H\T\S…
①start和end以及freq 配合能够生成start和end范围内以频率freq的一组时间索引
②start和periods以及freq 配合能够生成从start开始的频率为freq的periods个时间索引
将字符串转化为时间序列: df[列名]=pd.datetime(df[列名] , format=" "),format参数大部分情况下可以不用写,但是对于pandas无法格式化的时间字符串,我们可以使用该参数,比如包含中文。
时间序列的基础频率
| 别名 | 说明 |
|---|---|
| M | 每月最后一个日历日 |
| BM | 每月最后一个工作日 |
| MS | 每月第一个日历日 |
| BMS | 每月第一个工作日 |
| D | 每日历日 |
| B | 每工作日 |
| H | 每小时 |
| T或min | 每分 |
| S | 每秒 |
| L或ms | 每毫秒 |
| U | 每微秒 |
时间重采样
重采样: 指的是将时间序列从一个频率转化为另一个频率进行处理的过程,将高频率数据转化为低频率数据为降采样 (比如从天到月),低频率转化为高频率为升采样 (从月到天)
t.resample( '新的计时单位')
创建时期对象
PeriodIndex:时间段,(能将分开的时间字段组合起来)转换为pandas的时间类型
pd.PeriodIndex(year=' ' , month=' ' , day=' ' , hour=' ' ,freq=' H ' )
Python time strftime() 函数 接收以时间元组,并返回以可读字符串表示的当地时间,格式由参数 format 决定。
time.strftime(format[ , t ])
format:格式字符串。
t:可选的参数t是一个struct_time对象。
返回以可读字符串表示的当地时间