《Mysql必知必会》读书笔记
1.on和where的区别
mysql内外连接时,on跟where的区别 - jarjune - 博客园
都是先on后where on是筛选出两表关联的数据,where在on之后筛选出两表都符合的数据
内连接是取两表交集,外连接是以主表为准,如左连接不管on条件是否成立都会返回左表符合where条件的所有数据,外连接的on只对从表进行筛选。内连接因为要去两个表交集,要多主从表都进行筛选

2.聚合函数和distinct
加了distinct之后就只对不同的结果进行聚合
比如{1,1,2,2,3,3} 那因为先distinct再avg 就1+2+3=6 那sum(distinct)=6
select avg(distinct allocation_amount) from ep_apply_demand_item_fee;
select sum(distinct allocation_amount) from ep_apply_demand_item_fee;
select count(distinct allocation_amount) from ep_apply_demand_item_fee;avg 59329.020833333333
sum 5695586
count 96依然满足avg(distinct)*count(distinct)=sum(distinct)
3.只存数字的字符型
1.比较大小 1在10前边,10在2前边 因为比较时候会一个字符一个字符的比较,第一个字符一样大才会比较下一个
2.A-Z的ASCII码小于a-z的ASCII码
4.数字类型
int和decimal是number的子类型
整型:int(4)可以写成number4
金额型:decimal(10,2)可以写成number(10,2)
number(n,m) 其中n代表总的最大长度,m代表小数最大位数,则整数最大位数就是n-m
如number(10,2)就是小数最大长度是2,整数最大长度是8
5.insert select
正常insert into 表名 (colunm1,column2)values(1,2),(3,4),(5,6)
但是后边跟select 就不用values关键字了
而且insert into后边建议把列名都写上,以便于和values或者select形成意义对应关系,一目了然并且安全
insert into public.ep_entrance_category
select nextval('seq$ep_entrance_category$entrance_category_id'),
ec.category_id,
16 as entrance_id,
52281, '2022-06-10 11:41:26.132000', 52281, '2022-06-10 12:45:47.443000', 'VALID', '2022-06-10 12:45:47.443000', null
from ep_category ec
where ec.category_id in ('150048', '150049') or ec.parent_category = '150050';insert into ep_business_executive
select
nextval('seq$executive$executive_id'),
220613, 'ALL', 52281, '2022-06-15 16:11:15.153000', null, null, 'VALID', '2022-06-15 16:11:15.153000', null, 'COST_CENTER',
t.entrance_category_id
from ep_entrance_category t
where t.category_id in
(select ec.category_id from ep_category ec where ec.category_id in ('150048', '150049') or ec.parent_category = '150050')6.分页
1.mybatis的pagehelper插件,会把分页参数放到threadLocal中
2.mybatis会根据底层数据库的厂商不同,走不同的dialect处理拼接分页sql,比如mysqlDialect(图1),oracleDialect(图2)
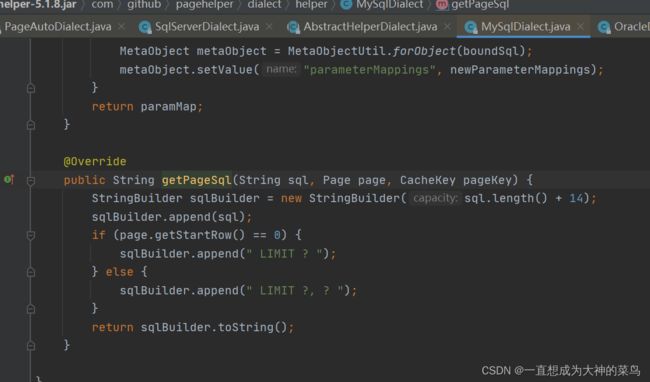
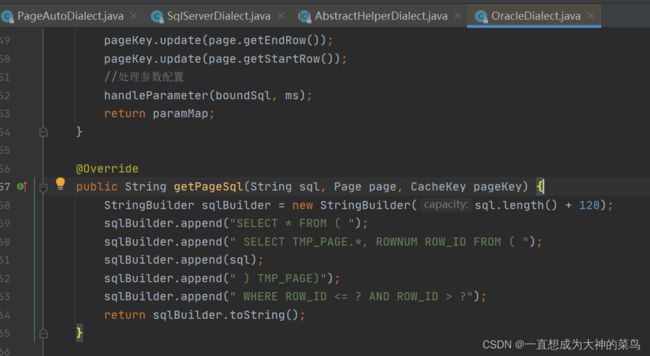
3.mybatis会取得xml中要执行的sql和threadlocal中分页参数(页码,条数)去组装分页sql,所以xml的sql如果是要分页的,那么不要以分号;结尾,否则组装出来的sql没法放到数据库执行,会报错
7.聚合函数和null
1.nulls last和nulls first
执行null数据的排序,如
order by info.submittedDate desc nulls last, info.createDate desc, info.updateDate desc2.count(*)能统计出来包含null的,但是count指定字段不会统计出来该字段为Null的
3.同样sum,avg,max,min也不会统计null数据
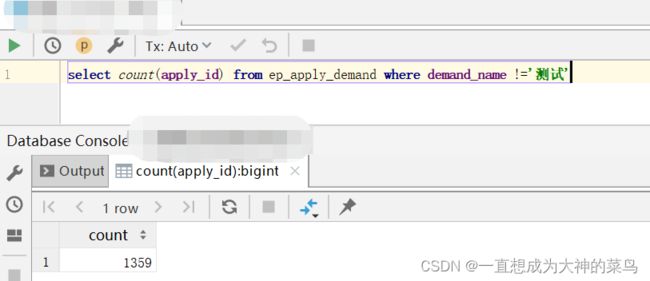
4.查where a = null 或者where a!=null是查不出来Null数据的,而是要用a is null 或者 a is not null
5.用a !='测试'也查不出来null数据,而是要加上or a is null
如图 不加or a is null查询得到的数据明显比加上少,少的这一部分就是Null数据

8.查看执行计划
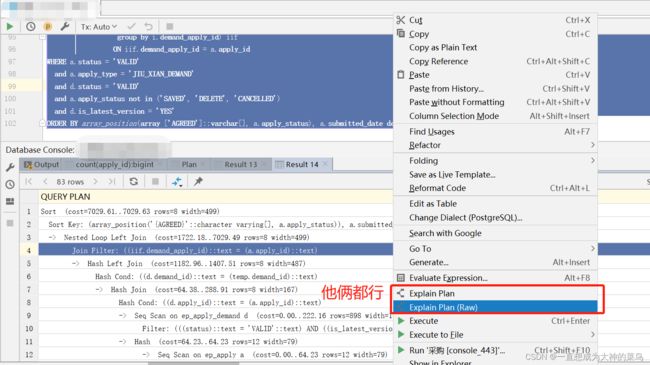
9.exists和in
9.1.exists是相关子查询
exists后跟着的查询条件肯定和外边的表有关系,外边的表有多少条数据,那么exists中的查询就执行多少次,根据exists返回true还是false来决定这条数据是否会出现在结果集中
9.2.in是普通子查询
不管外边有多少条数据,in查询就执行一次
9.3.sql调试
根据分块调试的方法,in可以独立出来执行,但是exists不能
9.4.in和exist的选择
MySQL的EXISTS一定比IN快吗? - 简书
9.4.1外边是大表,里边是小表,选择in,in走外表索引
9.4.2外边是小表,里边是大表,选择exists,exists走内表索引
 9.4.3不管大表小表,not exits>not in
9.4.3不管大表小表,not exits>not in
9.4.4优化sql时要分情况讨论还有自己尝试,并没有绝对的某个效率一定快或者某个效率一定慢
exist 比in效率高吗? - SegmentFault 思否

9.5.exists用法举例
他不返回一个具体结果集 你可以写select 1 select 2
SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id);SELECT
aa.sensor_id,aa.part_id,aa.flag
FROM
TEST_TB01 aa
WHERE NOT EXISTS
(SELECT 1 FROM
TEST_TB02 bb
WHERE aa.sensor_id = bb.sensor_id);10.自连接和pg
有内连接外连接还有自连接,我用过的自连接就是把一个表中的两个字段值进行交换
update pftest a,pftest b
set a.attrId = b.test,a.test = b.attrId
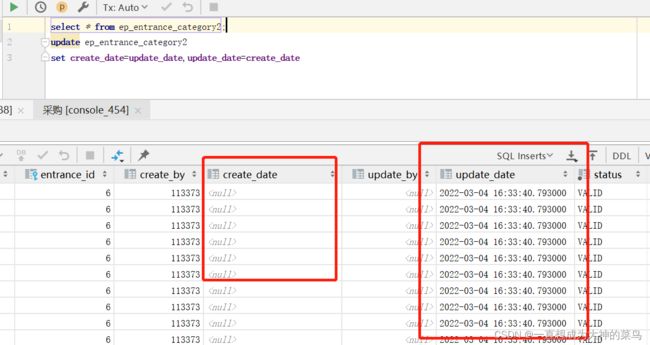
where a.attrId=b.attrId and b.test is not null但是Postgre数据库不能update后边跟多个表,那怎么实现交换两个字段数据呢?老简单了
update ep_entrance_category2
set create_date = update_date,update_date=create_date亲测有效截图

11.复合主键
拿多个字段拼接作为主键,叫复合主键,同主键的要求一样,多个字段拼接的结果也要唯一的
ALTER TABLE 多个主键 ADD PRIMARY KEY (NAME,TYPE) ;12.char
1.char是定长字段,varchar是不定长字段
定长字段是你如果存入小于指定长度的,那余位会自动空格补齐
如char(4),但是你存入的长度只有3,如'123',那么实际存入库中的是‘123 ’,后边加了个空格
2.坑
因为自动空格补齐,你再查询where a='123'你是查不到数据的
3.定长字段的效率更高
char比varchar效率高,但是varchar比char灵活
varchar与char有什么区别?——[面试系列]_慢悠悠的丑小鸭的博客-CSDN博客_varchar和char
13.truncate和delete
1.truncate是把表删除重新建个表,没法加where条件
2.delete可以加where条件,而且delete是一行一行数据的删
3.truncate比delete快
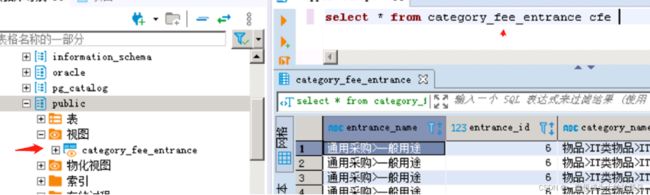
14.视图
14.1视图其实就是一个查询语句,一般有两种用法
1.外系统需要提供给我们一个视图,这个视图可能有表和表之间的关联,可能比较复杂,这个业务逻辑只有维护这个系统的人知道,那维护人员就帮我们写个sql放在视图里,然后把这个视图开个select权限给我们,我们就可以把这个视图当作表去正常查询,连接查询都可以
将视图的查询权限授权给C用户 grant select B.v_users to C;2.本系统有一个需要关联表的数据偶尔需要导出或者去查看,但是不想每次都写sql,就建个视图,下次想看就直接双击这个视图就行
14.2视图须知
1.视图不是表,他不存储数据,她只是一个sql,我们查询视图的时候会执行sql,获得的数据都是实时的
2.视图使用方式和表一样,但是不管是外系统提供给我们的视图名称还是我们自己创建的视图,都不能和我们数据库中表的名称重复,不然你查询的时候到底是在查视图还是在查表呢
3.创建视图
CREATE VIEW <视图名> AS
4.举例