Spring事务和事务传播机制
目录
1.为什么需要事务?
2、Spring 中事务的实现
2.1 MySQL 中的事务使用(回顾)
2.2 ⼿动操作事务(编程式事务)
2.3 声明式事务(利用注解自动开启和提交事务)
2.3.1 @Transactional 作⽤范围
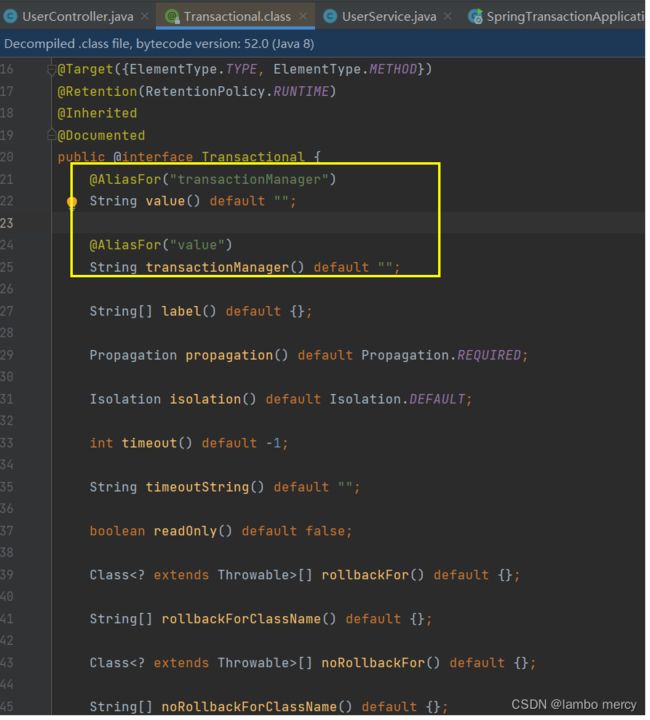
2.3.2 @Transactional 参数说明
1 value/transactionManager
2 propagation(事务的传播级别):
3 isolation 参数 && 事务的隔离级别
4 timeout
5 readOnly
6 rollbackFor (类型)/ rollbackForClassName(String类型)
7 noRollbackFor(类型) / noRollbackFor ClassName(String类型)
注意事项
@Transactional 在异常被捕获的情况下,不会进⾏事务⾃动回滚
@Transactional ⼯作原理
3 Spring 事务传播机制
3.1 事务传播机制是什么?
3.2 为什么需要事务传播机制?
3.3 事务传播机制有哪些?
3.4 Spring 事务传播机制使用和各种场景演示
3.4.1 ⽀持当前事务(REQUIRED)
3.4.2 不⽀持当前事务(REQUIRES_NEW)
3.4.3 不支持当前事务(NOT_SUPPORTED)
3.4.4 支持事务嵌套(NESTED)
1.为什么需要事务?
事务定义将⼀组操作封装成⼀个执⾏单元(封装到⼀起),要么全部成功,要么全部失败。
简单来说:事务诞生的目的就是为了把若干个独立的操作给打包成一个整体。
我们需要注意的是: Spring 的事务 相比于 MySQL 中的事务,要复杂一些!
MySQL 的事务 无非就是 事务可以并发执行,需要考虑隔离性的问题。
但是!MySQL 的事务 非常单纯!
它不会说出现事务嵌套的问题。
比如:事务 A 嵌套了 事务 B,事务 B 嵌套了 事务 C,事务 C。。。。。
这种情况,在MySQL事务中是不会出现的。
Spring 的事务,就大不一样了!
在 Spring 时代的时候,或者说,在我们敲代码的时候,那个的事务,就不能保证不会出现嵌套的情况了。
因为我们代码,通常完成一个业务逻辑(事务),需要调用多个方法(事务),才能执行。
而多个方法又可能依赖于其他的方法,才得以实现。
这种情况,在 代码中 是非常常见的。
如果程序中出现这中嵌套的现象的话。
不问题的话,那还好,没有问题,
但是!万一出现了问题,那我们其它事务(方法)应该怎么去处理呢?
是相互不影响吗? 一个事务(方法)出现了问题,其它的事务不受影响。
还是 “引火上身”呢?一个事务牵扯到 ABC 三个事务,如果 一个事务出现了问题,其它的事务是无法执行的。直接给你 进行 事务回滚了!
这个就涉及到 Spring 事务传播的机制是怎么设置的了。
Spring 事务传播的机制,它是有七种类型的。
所以说很复杂!
2、Spring 中事务的实现
Spring 中的事务操作分为两类:
1、编程式事务(⼿动写代码操作事务)
编程式事务:通过代码来控制事务的 开启 和 提交,或者是 回滚。
2、 声明式事务(利用注解自动开启和提交事务)
声明式事务:就是加个注解,注解会在进入方法之前,自动开启事务,或者在方法执行之后,自动进行事务的回滚。【回滚使用的是 @Transactional】
声明式事务的便利性是非常好的,但是它的问题也是最多的!
有一个参数,或者与一个地方没有调整好,就会出问题。而且,没有提示。
所以,很难解决!
而 编程式事务,因为代码操作的,所以,相比之下,要简单一些。
在开始讲解它们之前,咱们先来回顾事务在 MySQL 中是如何使⽤的?
2.1 MySQL 中的事务使用(回顾)
开启事务:start transaction
简单来说
1、当我们将要执行多句SQL时,先输入 start transaction;
2、之后,便是执行多行 sql 语句。
3、最后 执行完之后,我们要以 rollback / commit 作为返回,
rollback 代表执行失败,进行“回滚”,而 commit 就是执行成功提交的意思。
start transaction;
// transaction 与 commit 之间,就是事务中的若干操作
-- 阿里巴巴账户减少2000
update accout set money=money-2000 where name = '阿里巴巴';
-- 四十大盗账户增加2000
update accout set money=money+2000 where name = '四十大盗';
commit;2.2 ⼿动操作事务(编程式事务)
Spring ⼿动操作事务和上⾯ MySQL 操作事务类似,它也是有 3 个重要操作步骤:
1、开启事务(获取事务)。
2、提交事务。
3、回滚事务。
实现上面的3个操作,需要依赖两个重要的对象。
这两个对象 在 SpringBoot 中,被内置了:
DataSourceTransactionManager ⽤来获取事务(开启事务)、提交或回滚事务的.
⽽ TransactionDefinition 是事务的属性,在获取事务的时候需要将TransactionDefinition 传递进去从⽽获得⼀个事务 TransactionStatus
在演示之前,我们需要创建一个 SSM 项目。
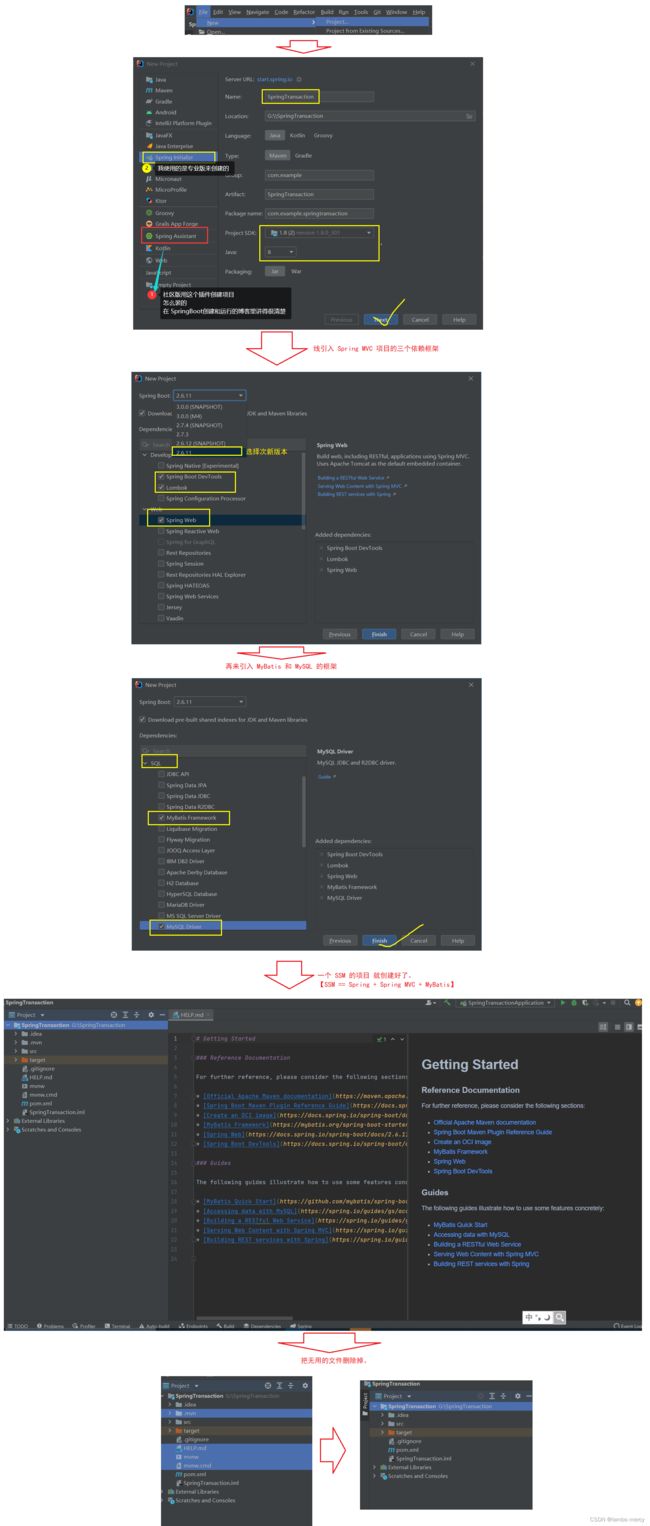
然后我们就需要配置一下 配置文件中信息。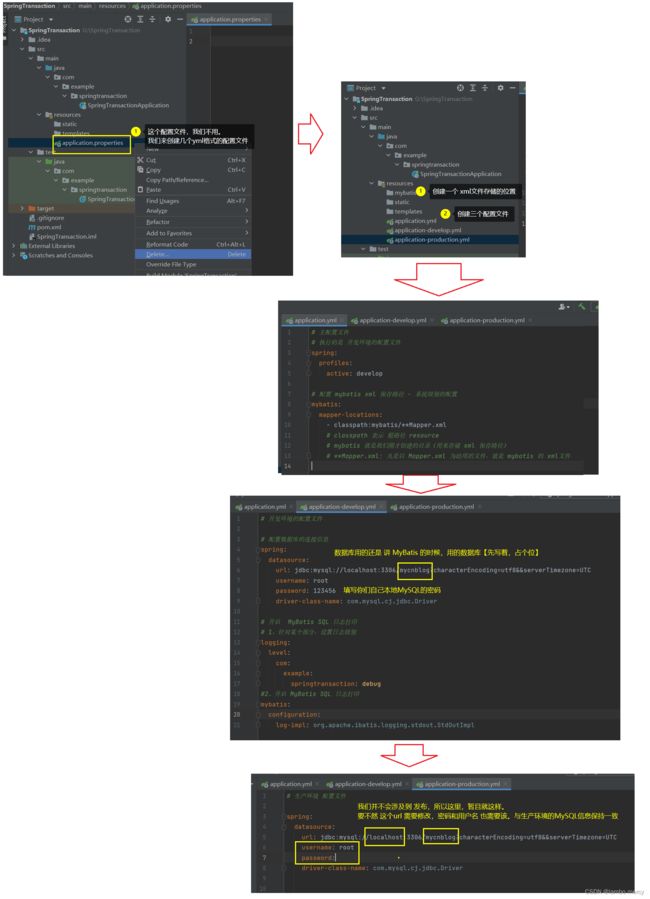
此时,我们 SSM 项目,就可以使用了。
下面,我们就来实现一个添加用户的功能。
MyBatis 的接口 和方法已经定义好了。下面就是创建 xml 文件,并且在里面拼接SQL了
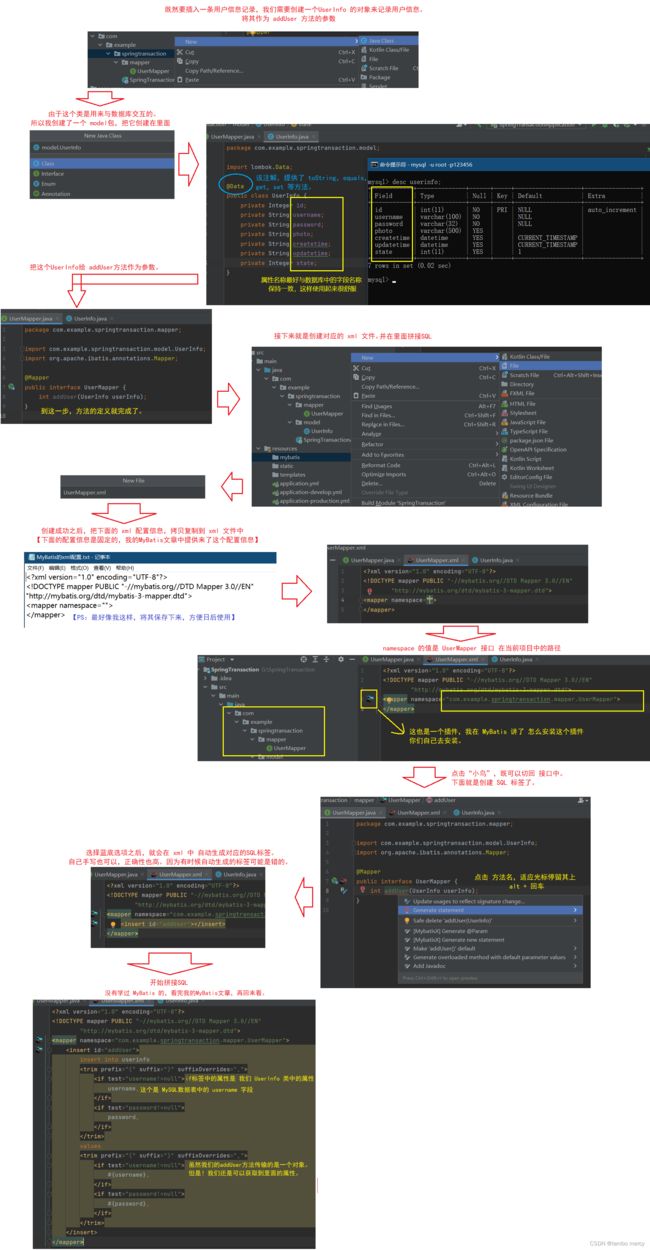
下面,就是完善程序了,去创建一个负责和前端交互的类(controller),以及 定义 一个能 调用对应接口中的方法 的类(service)。
现在,我们要给这个程序添加事务成分了。
也就是说:上面的代码,需要做出改变,不能再这么去写了。
至此,编程式事务,我们也就实现了!
通过上述的操作,我们实现了 编程式事务,但是还是觉得有点 “ 麻烦 ”。
那有没有更简单的方法呢?
肯定是有的,就是下面我们要开始讲的 声明式事务。
2.3 声明式事务(利用注解自动开启和提交事务)
学到这里了,大家对 spring 框架已经与了一定了解。
几乎所有的问题,都是使用 注解 来解决的。
事务,也是同样可以使用注解 来完成的
我们在进行单元测试的时候,想在 “不污染” 数据库中数据的前提下,完成测试。
使用到了一个注解 @Transactional 。在单元测试完之后,会进行一个事务回滚操作。
但是!这只是在单元测试里面,是这样的效果。
在 实际操作中,它的行为完全是相反的。
在实际操作中,如果被修饰的方法执行成功了,它就会自动提交事务。
只有当 方法 报出异常的时候,才会进行回滚操作。
需要注意的是: @Transactional 没有我们想的那么加单!
我们这里只是演示了一下 @Transactional 最基础的 用法。
下面,我们来对 @Transactional 进行扩展。
2.3.1 @Transactional 作⽤范围
@Transactional 可以⽤来修饰⽅法或类:
修饰⽅法时:需要注意只能应⽤到 public ⽅法上,否则不⽣效。推荐此种⽤法。
修饰类时:表明该注解对该类中所有的 public ⽅法都⽣效。
那么,有人可能会问:为什么@Transactional 只对 public 的方法有效?
这里就需要和大家讲一个知识点了。
@Transactional 的作用范围,只能应用在public 方法上。
也就是说:@Transactional 注解,只有在 public 修饰的方法上,才能生效。
其他的修饰词的方法,是不生效的。
2.3.2 @Transactional 参数说明

1 value/transactionManager
这两个属性的作用是一样的。
如果有多个事务管理器时,可以使用 该属性指定选择哪个事务管理器。
2 propagation(事务的传播级别):
事务的传播级别就是:我有多个事务存在嵌套的情况,那么,我多个事务之间的行为模式,就叫做事务的传播机制。
多个事务之间的行为:
我是把所有的这些小事务看作一个大的事务;
还是说,每个事务都是独立的存在,即使某个事务出现了问题,也不会影响到其它事务的执行 ;
或者,你这个里面有事务,我里面没有事务,然后我就不使用事务。。。。
具体是那种行为,是由这个 propagation 属性(参数)决定的。
也就是我们可以通过 配置 propagation 参数,来决定 当出现了 嵌套事务的时候,多个事务之间的行为模式。
它的行为模式有七种。
【事务的传播级别有七种】
这个先暂且搁置,后面会细讲。
3 isolation 参数 && 事务的隔离级别
isolation 参数 是用来设置 事务的隔离级别。
事务有 四大特性:ACID【回顾】
A -> Atomic:原子性
⼀个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执⾏过程中发⽣错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执⾏过⼀样
C -> Consistency : 一致性
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写⼊的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以⾃发性地完成预定的⼯作。
I -> Isolation:隔离性
数据库允许多个并发事务同时对其数据进⾏读写和修改的能⼒,隔离性可以防⽌多个事务并发执⾏时,由于交叉执⾏⽽导致数据不⼀致的情况。
事务隔离分为不同级别,包括:
读未提交(Read uncommitted):存在脏读 + 不可重复读 + 幻读问题
读提交(read committed):存在 不可重复读 + 幻读问题。
可重复读(repeatable read):存在 幻读 问题。
串⾏化(Serializable):不存在问题,但是 执行效率最低。
MySQL 的事务没有很复杂,它们的事务都很 “ 单纯 ”,只做一件事。
因此,不会涉及到事务嵌套的问题。
事务的隔离性,只是调整事务的执行方式,为了贴合实际的应用,提高事务的执行效率。
但是,事务传播机制就不一样了!
当整个调用链上,有一个程序里面有多个方法的时候,然后,多个方法相互调用的时候,并且这多个方法,都具有事务的时候,这个情况,就是 事务嵌套的问题。
也就是说:当程序中出现嵌套事务之后,那么,这些嵌套事务之间的行为模式 ,就是传播机制。
所以说:它们讲的维度是不一样的!
隔离性,针对的是: 不存在事务嵌套 的 前提下。
传播机制:针对是 存在 事务嵌套 的前提下。
从出发点来看,它们就不一样!
隔离性,讲的是:
多个事务并发执行,但不会存在嵌套事务的问题,就好像每个人都在自己的跑道上奔跑,互不干扰。
传播机制,讲的是:
在一个调用链上,多个方法里面有多个事务,而这多个事务在相互调用的时候 ,使用的行为模式。
可能上面有点绕,简单来说:
传播机制就是:
多个事务都在 “ 一条线上 ” ,然后,以什么样的行为(方式)去进行事务传播(调用事务)。
事务的隔离性:
多个事务不在 “ 一条线上 ” 的,走着各自的路线,互不影响D -> Durability:持久性
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
简单来说:就是把数据存储到硬盘里。
那么,问题来了: Spring 事务的隔离性 与 MySQL 事务的隔离性 ,有没有什么区别?还是说是一样的?
不一样!
如果说 Spring 事务的隔离性 与 MySQL 事务的隔离性,都是小汽车的话。
那么, Spring 和 MySQL,就可以认为是 小汽车 的品牌,不同品牌的汽车,外观,内饰,发动机都是不一样的。只是说本质上都是一样的,都是一辆车(隔离级别)。
Spring 中 事务的隔离级别,一共五种, 比 MySQL 的隔离级别数量多一个。
我们先来看 MySQL 的 隔离级别。
虽然上面简单提了一下,但是还是给你们回顾一下。
MySQL 事务隔离级别有 4 种:
1、 READ UNCOMMITTED:读未提交,也叫未提交读。
该隔离级别的事务可以看到其他事务中未提交的数据。
该隔离级别因为可以读取到其他事务中未提交的数据,⽽未提交的数据可能会发⽣回滚,因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读。
2、READ COMMITTED:读已提交,也叫提交读。
该隔离级别的事务能读取到已经提交事务的数据,因此它不会有脏读问题。
但由于在事务的执⾏中可以读取到其他事务提交的结果,所以在不同时间的相同 SQL 查询中,可能会得到不同的结果(可能有老六修改了提交的数据),这种现象叫做不可重复读。
3、REPEATABLE READ:可重复读。
是 MySQL 的默认事务隔离级别,它能确保同⼀事务多次查询的结果是⼀致的。
但也会有新的问题。
⽐如:
此级别的事务正在执⾏时,另⼀个事务成功的插⼊了某条数据,在下一次 以同样的 SQL 查询的时候,突然发现多出一条记录。无缘无故 多出一个条记录,好神奇,这就叫幻读(Phantom Read)。
4、SERIALIZABLE:序列化。
事务最⾼隔离级别,它会强制事务排序,使之不会发⽣冲突,从⽽解决了脏读、不可重复读和幻读问题,但因为执⾏效率低,所以真正使⽤的场景并不多。●脏读:
⼀个事务读取到了另⼀个事务修改的数据之后,后⼀个事务⼜进⾏了回滚操作,从⽽导致第⼀个事务读取的数据是错误的。
●不可重复读:
⼀个事务两次查询得到的结果不同,因为在两次查询中间,有另⼀个事务把数据修改了。
● 幻读:
⼀个事务两次查询中得到的结果集不同,因为在两次查询中另⼀个事务有新增了⼀部分数据。
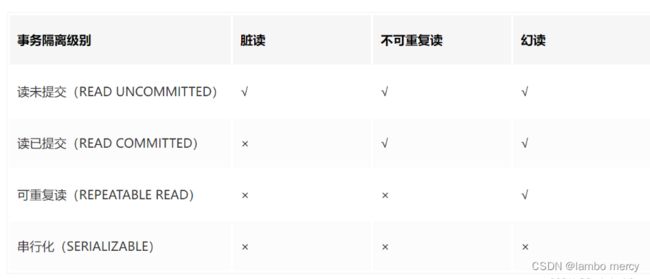
Spring 事务隔离级别有 5 种:
⽽ Spring 中事务隔离级别包含以下 5 种:
1、Isolation.DEFAULT:以连接的数据库的事务隔离级别为主。
2、 Isolation.READ_UNCOMMITTED:读未提交,可以读取到未提交的事务,存在脏读。
3、 Isolation.READ_COMMITTED:读已提交,只能读取到已经提交的事务,解决了脏读,存在不可重复读。
4、 Isolation.REPEATABLE_READ:可重复读,解决了不可重复读,但存在幻读(MySQL默认级别)。
5、 Isolation.SERIALIZABLE:串⾏化,可以解决所有并发问题,但性能太低。
注意事项:
1、当 Spring 中设置了事务隔离级别 和 连接的数据库(MySQL)事务隔离级别 发生冲突的时候,那么,会以 Spring 的为主。
2、Spring 中的 事务隔离级别机制的实现,是依靠 连接的数据库中 支持的事务隔离级别 为基础。
简单来说:虽然我们在项目中设置了隔离级别,但是!项目中的隔离级别是否生效,还是要看 连接的数据库 是否支持 项目中设置的隔离级别。
这好比我们月入 8k,却希望过着 月入 8 万 的生活。
可能吗?不可能!!!! 对不对。
项目中设置的隔离级别,就好比是 那 8 w,我们连接的数据库中支持的隔离级别,就好比是 那8k,很明显我们的数据库是无法支持 我们项目中对隔离级别设置的
4 timeout
事务的超时时间,默认值为 -1。
-1,表示的是 没有时间限制。
【没有规定 超过多少时间算超时。】
如果设置了超时时间,并超过了该时间。
也就是说: 事务 到了规定的时间,还没有执行完。
此时,就会认为这个事务无法完成,自动回滚事务。
5 readOnly
指定事务是否为只读事务,默认值为 false.(默认指定的事务不是 只读事务)
只读事务,表示该事务只能被读取。不能进行其它操作。
为了忽略那些不需要事务的方法,比如:读取数据的操作。
可以设置 read-only 为 true。
这就涉及到了 线程安全问题,多个线程只读取数据,是不会涉及到 线程安全的问题。
只有涉及到 修改/删除/新增 操作的时候,才需要 加锁(synchronized)
这个时候,我们就可以使用读写锁 ReadWriteLock。
那么,问题来了:有了 ReentrantLock,为什么还需要 ReadWriteLock 呢?
这样做的目的:就是为了读和写分离,可以让它们维度更加清晰。
可以保证在读读操作的时候,它会一起执行,不会真的去加锁。
因为都是 读操作 ,是线程安全的,我就不加锁了。
虽然代码上是有加锁操作的,但是实际运行中,是不会加锁的。
使用 ReadWriteLock 就可以更大限度的提高程序的执行效率。
只读事务 和 非只读事务 的作用,也是这样的。
也是为了 提高 事务 的执行效率。
这么说吧:如果是一个只读事务,那么,它只会进行读取操作。
那么,我们对于 只读事务,就可以不用去(开启 / 提交 / 回滚 )事务。
因为没必要!
读数据,是不会出现业务问题的。也不会污染数据库中的数据。
那为什么要给 只读事务 开启事务?直接查询呗!
在使用的时候,如果是 只读事务,别说使用@Transactional 的 readOnly 属性,连 @Transactional 直接 都需要加上!
反过来,如果你想让一个 非只读事务 变成一个 只读事务,使用@Transactional 的 readOnly 属性,将其置为 true。
6 rollbackFor (类型)/ rollbackForClassName(String类型)
用于指定能够触发事务回滚的异常类型。
PS:可以指定多个异常类型
当发生某些异常的时候,我能够 执行 事务回滚操作。
7 noRollbackFor(类型) / noRollbackFor ClassName(String类型)
就是 rollbackFor / rollbackForClassName 的 反向操作。
当发生某些异常的时候,不进行 事务回滚操作。
同样,也可以指定多个异常类型。
但是!异常的类型 何其多!(Java 有 一百多种)
使用 rollbackFor / rollbackForClassName 指定那些异常类型发生的视乎,不进行事务回滚,这是很麻烦的!
所以,我们通常使用的是 noRollbackFor / noRollbackFor ClassName 来指定 那些异常类型不用事务回滚,那么剩下来的异常,就全部都是 发生异常 需要 进行事务回滚的咯~
注意事项
由于我们都是使用注解来解决问题的,内部的运行对于我们程序员来说是不可见的(黑盒)。
因此,有些时候,是出现一些意外错误。
@Transactional 在异常被捕获的情况下,不会进⾏事务⾃动回滚
当异常被 tryCatch 捕获时,就不会执行 事务的自动回滚。
它会认为 这个异常 被 tryCatch 解决了(认为被你解决了,既然你敢写,就说明你有能力解决这个问题。)。
不需要进行事务的回滚。
PS:我直接演示 tryCatch 包裹的情况。
不加 tryCatch 的情况, 这个我记得前面演示过了,会触发事务的回滚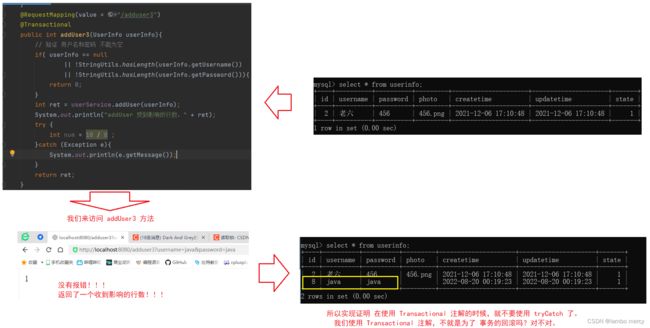
有的人可能会说:有一些错误,确实我们去处理,但是现在 tryCatch 不能用,那我们该怎么做呢?
暴力解决方案1:将异常重新抛出去!
优雅解决方案2:使用代码的方式 手动回滚 当前事务。
使用 TransactionAspectSupport.currentTransactionStatus().setRollbackOnly() 方法,就可以解决问题了。难道你们就不好奇为什么我们加上 @Transactional 注解之后,它就能工作呢?它的工作眼里是什么?
这就下面要学习的东西了。
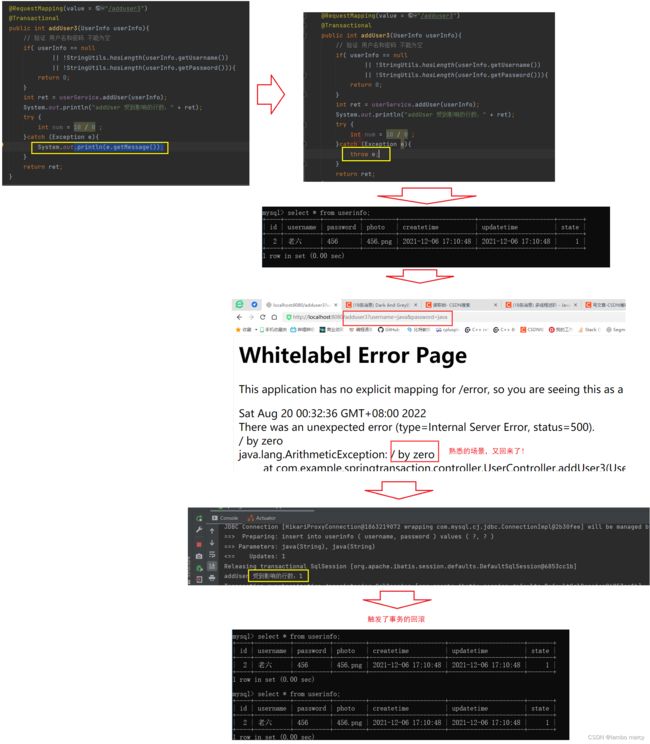
@Transactional ⼯作原理
我们一开始学的时候,学的是定义。
然后,定义学完之后,我们学的是 使用。
使用 学完之后,我们就需要更加深入一层了,去看它理层的知识点。
我们学习一项新东西,无非就是从 概念,使用,以及实现原理,三个方面去学习,依次递进。
@Transactional 是基于 AOP 实现的, AOP ⼜是使⽤动态代理实现的。
如果⽬标对象实现了接⼝,默认情况下会采⽤ JDK 的动态代理,如果⽬标对象没有实现了接⼝,会使⽤ CGLIB 动态代理。
@Transactional 在开始执⾏业务之前,通过代理先开启事务,在执⾏成功之后再提交事务。如果中途遇到的异常,则回滚事务。
@Transactional 实现思路预览:
PS: 切面就是 针对某个功能的实现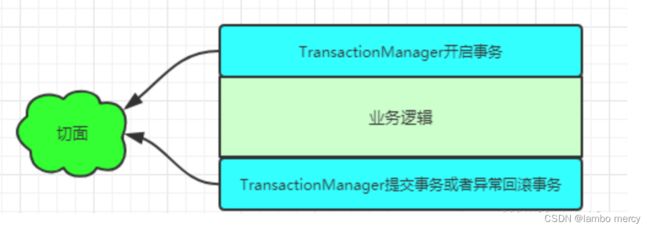
 @Transactional 具体执⾏细节如下图所示:
@Transactional 具体执⾏细节如下图所示: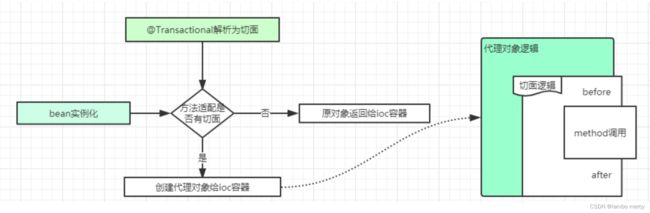
3 Spring 事务传播机制
3.1 事务传播机制是什么?
Spring 事务传播机制定义了多个包含了事务的⽅法,相互调⽤时,事务是如何在这些⽅法间进⾏传递的。
我们之前学习的事务都很简单,都是单个的事务。
各个事务之间是没有关联关系,并且不存在相互调用的情况。
但是!这种美好的情况,只是发生在 我们学习 Spring 框架之前。
之前我们的事务 是在数据库里面去操作的,没有问题!
单个事务,很简单。很纯粹!
对于程序员来说很幸福!
但是呢,我们现在到了具体的业务方法里面,具体框架里面,它的业务场景就会变成复杂很多!
就比如:A方法调用 B 方法,B方法里面又调用了 C 方法。。。。
ABC。。。都有事务.
现在问你: 事务,它应该怎么样进行传递 和 怎么样去执行。
是每个事务各自运行,互不影响;
还是几个事务 组成一个大事务;
还是说,我不以事务的方式执行。
这种可能性是完全可能存在的。
比如:
A 调用 B,B 调用 C,C 调用 D.
然后呢,A有事务,B有事务,C 没事务,D 有事务。
好,这个时候,我们该怎么办?
我的事务要不要传,毕竟 C 没有事务,中间 “ 断了 ”。
这样的话,情况就异常复杂了。
这就是一个应用级程序 的 特性。
这东西很复杂!
因为 它没有那么纯粹,没有那么简单!好,就此打住。
我们在理解了 事务传播机制的定义之后,下面我们再来看看 为什么需要事务传播机制。
3.2 为什么需要事务传播机制?
事务隔离级别是保证多个并发事务执⾏的可控性的(稳定性的).
而事务传播机制,是保证⼀个事务在多个调⽤⽅法间的可控性的(稳定性的)。
例⼦:
像新冠病毒⼀样,它有不同的隔离⽅式(酒店隔离还是居家隔离),是为了保证疫情可控。
在每个⼈的隔离过程中,会有很多个执⾏的环节。
⽐如:酒店隔离,需要负责⼈员运送、物品运送、消毒原⽣活区域、定时核算检查和定时送餐等很多环节。
⽽事务传播机制就是保证⼀个事务在传递过程中是可靠的,是稳定的。
回到本身案例中就是保证每个⼈在隔离的过程中可控的。
现在来思考问题:为什么需要事务传播机制?
其实,需要事务传播机制,就和 我们需要 事务是一样的。
大家有没有想过 为什么 MySQL 中 需要事务,为什么 Spring 中 需要事务 ?
无非就是因为:使用事务,可以增加程序的稳定性。
事务的传播机制也是一样,也是为了保证 程序的稳定性。
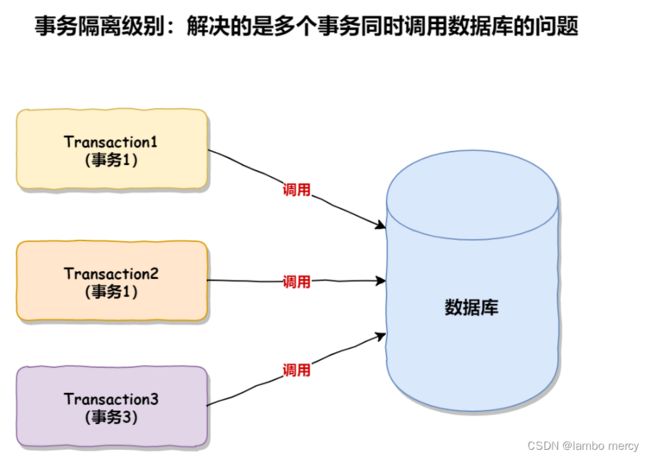
事务隔离级别解决的是多个事务同时调⽤⼀个数据库的问题,如下图所示:
⽽事务传播机制解决的是⼀个事务在多个节点(⽅法)中传递的问题,如下图所示:
如果是多个事务,在相互调用的情况,也很好理解!
事务的传播机制,在多个事务相互调用的时候,对其进行“行为控制”,让其结果能够达到我们预期的效果。
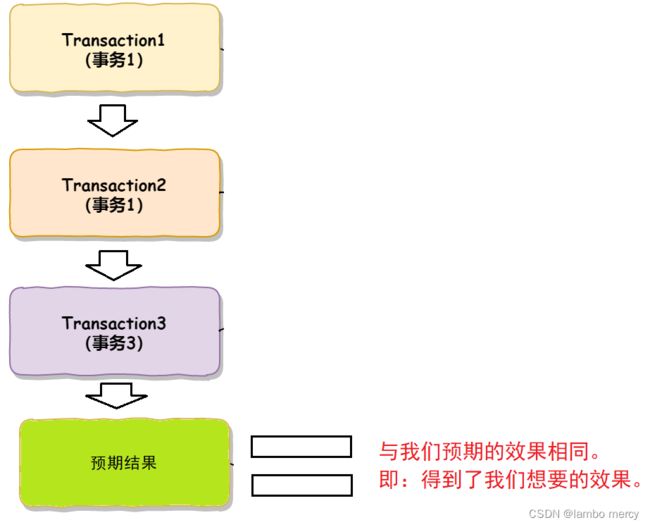
我们还可以发现,在事务的传播机制中,多个事务都在 “一条线上”。
那么,问题来了:
正如我们前面所说: 如果这三个事务中,有一个事务 只是一个普通方法,不具备事务。使其 事务的传递 中断,我们该怎么做?
是全部回滚,将数据恢复到未操作状态。
还是说,那个事务出现了问题,就回滚那个事务。
或者,不回滚。
这些都是不确定的因数!
这些都是:婆说婆有理,公说公有理。
无论你怎么说,你都有你的道理。
但是!不管怎么说,我们都需要一个统一行为,或者说 一个统一的管理模式。【放在上面例子中,就是要有一个 客观的标准】
这就必须要依靠事务传播机制,依靠 设置 和 规定,来去处理。
3.3 事务传播机制有哪些?
Spring 事务传播机制包含以下 7 种:
1、 Propagation.REQUIRED:
默认的事务传播级别,它表示如果当前存在事务,则加⼊该事务;如果当前没有事务,则创建⼀个新的事务。
这就跟现在结婚的现状是一样的,房子(事务)是必须项、
女方就是 隔离级别 Propagation.REQUIRED
男方有房子,我就住进去。
反之,男方没有房子,也没关系。
一起奋斗买间房。
总之,房子必须有。
2、 Propagation.SUPPORTS:
如果当前存在事务,则加⼊该事务;如果当前没有事务,则以⾮事务的⽅式继续运⾏。
放在上面的例子中,这种女生更难求。
就是说:男方有没有房子都无所谓,就想和他结婚。
至于房子如果有,我就住。
没有,租房也行。
3、Propagation.MANDATORY:
(mandatory:强制性)如果当前存在事务,则加⼊该事务;如果当前没有事务,则抛出异常。
这种情况,就非常的现实。
如果男方没有房,就不结婚,甚至直接分手。
反之,女方就直接住进去。【加名,迟早会提出来的。】
总之,房子必须有,男方全款买。
4. Propagation.REQUIRES_NEW:
表示创建⼀个新的事务,如果当前存在事务,则把当前事务挂起。
也就是说不管外部⽅法是否开启事务,Propagation.REQUIRES_NEW 修饰的内部⽅法会新开启⾃⼰的事务,且开启的事务相互独⽴,互不⼲扰。
这种情况,女生非常作!
男生已经买了房,只不过可能有个 一两年的历史
女方表示必须是新房,旧房我不住!
不是新房,我不接了!!!
5. Propagation.NOT_SUPPORTED:
以⾮事务⽅式运⾏,如果当前存在事务,则把当前事务挂起。
这种情况,女方比较奇葩。
就算男方有房子,也不住。
我就是要住 租的房子!
6. Propagation.NEVER:
以⾮事务⽅式运⾏,如果当前存在事务,则抛出异常。
这种就更奇葩。
男方有房子,这婚我不接了!分手!
男方没有房子,真好!我要和你结婚。
7. Propagation.NESTED:
如果当前存在事务,则创建⼀个事务作为当前事务的嵌套事务来运⾏;
如果当前没有事务,则该取值等价于 PROPAGATION_REQUIRED(创建一个新事物)。
这种就是 白富美剧情。
男方有房,女方家里又给了一套房。
如果男方没有房,女方家里表示我可以送一套!
以上 7 种传播⾏为,可以根据是否⽀持当前事务分为以下 3 类: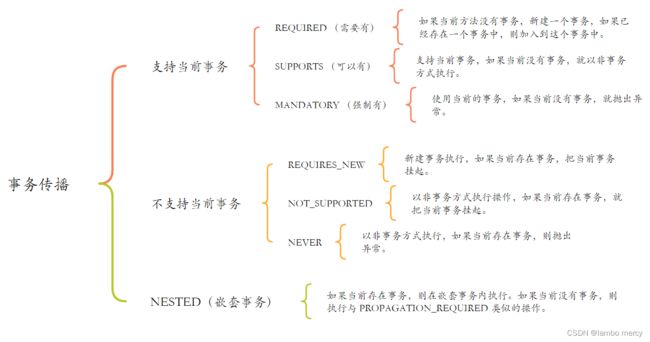
以情侣关系为例来理解以上分类: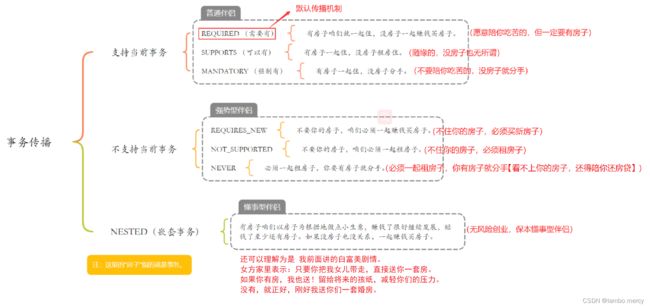
3.4 Spring 事务传播机制使用和各种场景演示
我相信尽管我们前面讲的很详细,很生动,
依然会有人迷茫,不怪你,每个嗯吸收的效果是不一样的。
所以,就有了这一个环节,用代码的形式给你们演示一下,几个经典 传播级别的使用场景。
加深你们对它的了解。
3.4.1 ⽀持当前事务(REQUIRED)
我们需要创建两张表,用户表 和 日志表,这样搭配起来,才能突出事务嵌套的情况。方便我们去模拟事务嵌套的情况。
我们在给用户表添加一条用户信息的时候,同时也日志表添加一条日志。
两者存在事务嵌套的关系。
然后,我们就去观察一下。
我们就在 controller 里面申明当前的事务的传播级别为 REQUIRED。
也就是说:有事务我就加入,没有事务,就创建一个新事物。
也就说: 添加日志的事务 加入了 添加用户的事务,成为了 添加用户事务 的 一部分。
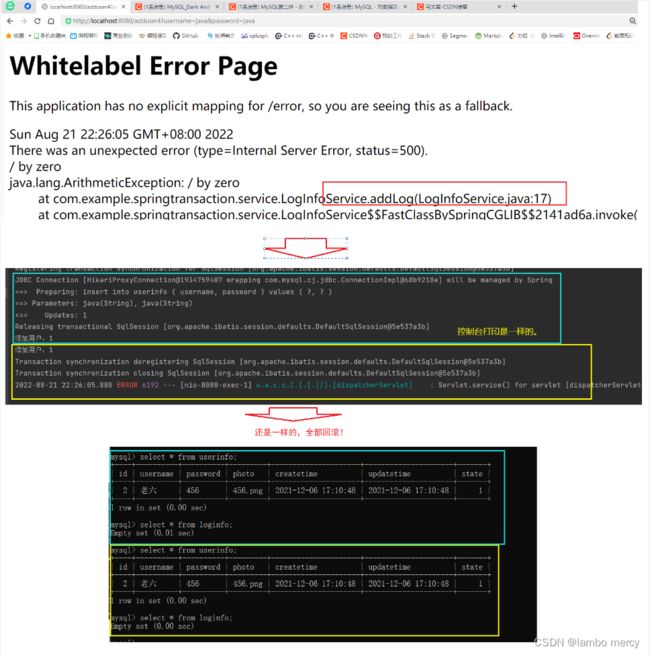
我们让添加用户的事务执行成功,让添加日志的事务报出异常。
我就来观察一下, 添加用户的事务,会不会因为 添加日志事务 执行的失败,而触发回滚。毕竟,它们现在是处于一体的关系。
如果 添加用户事务发生了回滚,则说明 这两个事务确实合并成一个事务了。
两者中有一个出现异常,就会触发事务回滚,这也正是 @Transactional 的特性。
用户表,我们是创建好了的,并且添加用户的方法,我们也写好了。
现在,主要就是准备 日志表 和 关于日志表的操作。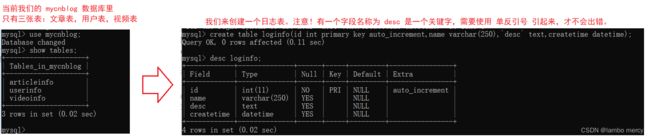
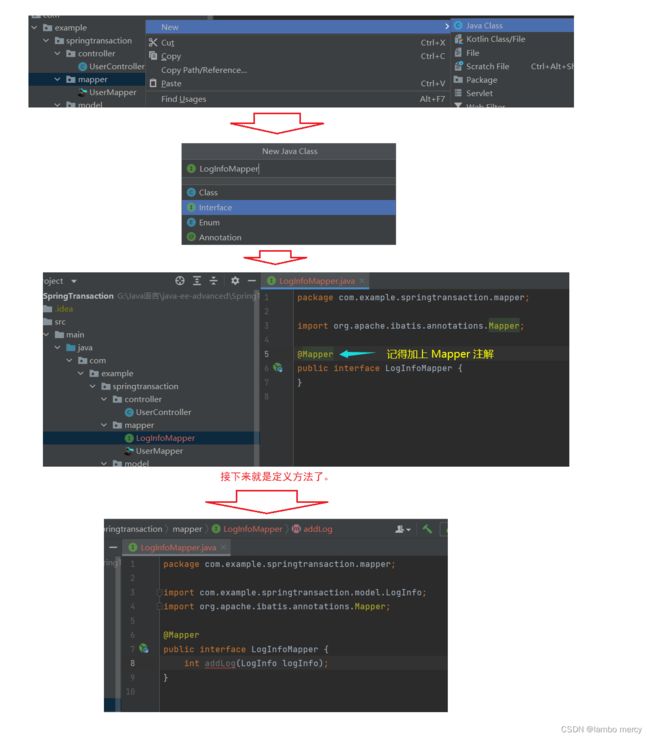
接下来就是编写操作日志的MyBatis代码了。
先来创建一个日志表的实体类。
接着我们来日志表,创建一个 MyBatis 的接,并在里面定义 操作 日志表的方法。
紧接着,我们来创对应 XML 文件,并在里面拼接SQL。
这里需要注意的是:
虽然我们写程序的时候,讲究分层,保持程序功能的单一性。
通常我们会分为三层,就和前面演示的一样,还需要在 service 和 controller 中创建调用类。
但是!我们的 日志不用这样做。
因为日志,在添加具体的业务的时候,去添加 service 的。(嵌套执行)
所以,它呢,一般情况下不需要再去写一个 service 的。
现在,我们在UserService 里面,还需进行 添加日志的 操作。

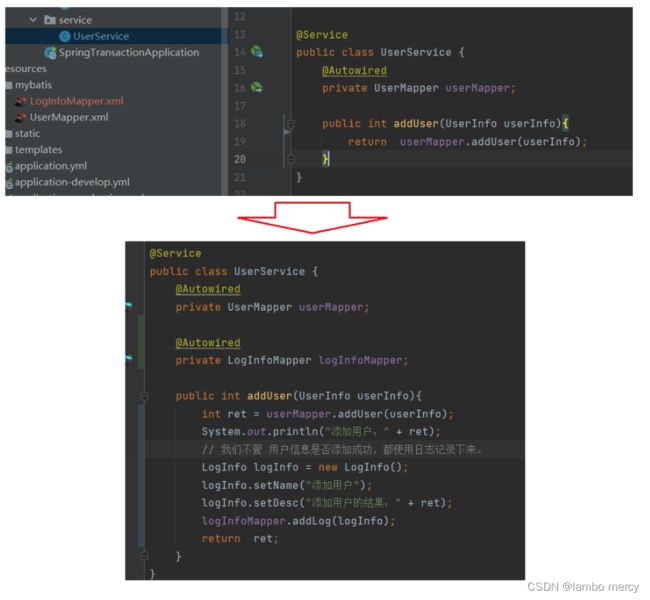
虽然代码写完了。
但是!我们写的这个代码还存在一些问题。
虽然事务的组装是在 service 层进行的,但是呢,它不太符合我们的一个业务场景。
我们的业务场景是要在 有方法的传递和调用的!
那我们要去写三个事务(方法),在一个事务里面去调用另外两个事务。
然后一个事务没有问题,另一个事务有问题。
而我们只有两个方法,很显然是不满足条件的。
所以,我们还是将上面的代码分开去写,写两个service 的代码。
我们就不去考虑业务的合理性,主要目的在于演示。
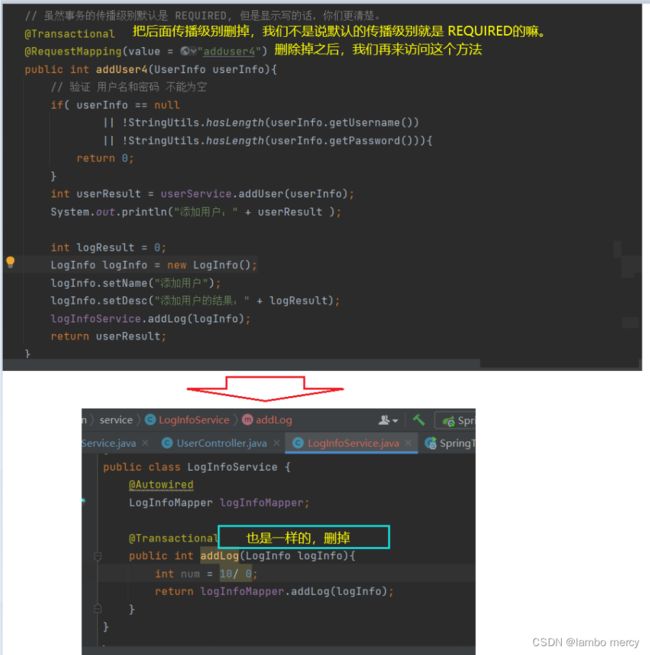
3.4.2 不⽀持当前事务(REQUIRES_NEW)
不管你现在有没有事务,我都要创建一个新的事务。
为什么挑它呢?因为它的可操作性更强!
同样的代码,我们把 LogInfoService的 addLog 和 UserService 的 addUser方法 ,它们的@Transactional 后面的 事务传播级别的设置删除掉了,其它的代码都不改。
我们再来看效果!
3.4.3 不支持当前事务(NOT_SUPPORTED)
这个更狠一下,只能以非事务的方式运行。
我们就把上面的代码中addLog 和 addUser 的事务传播级别 改成 NOT_SUPPORTED。
此时,这两个方法 “异常头铁”!
将其当成一个普通方法执行,代码执行到哪里,任务就完成到哪里。
不会存在 事务回滚的现象。
也就是说 addLog 方法,虽然出现异常,但是 操作数据库的 addLog 方法,已经被执行了。
数据已经到 longinfo 表里去了,没有回滚!
3.4.4 支持事务嵌套(NESTED)
还是以上面的例子为例。
这个时候,我们把主事务(UserController 中的 addUser5), UserService的 addUser 和 LogInfoService 的 addLog 事务。它们的传播级别设置为 NESTED。
此时, addUser 和 addLog 事务, 这两个事务就算嵌入 主事务中了。
注意! 是嵌入,而不是加入。
加入:与主事务合并。
嵌入:类似买东西的时候,送的 附赠品。
此时,我们来启动项目,看个效果。
虽然我们在测试 加入 的时候,报出了异常,是有点问题的。
但是,效果是一样的。
之所以,会报出这个异常,是因为本来这个异常,是由主事务(addUser5)来进行回滚的,结果被我们截胡。所以,才会出现意外回滚异常。
简单来说:就是有个老六把我们的吃的抢走,还吃了。这我们不得bb它?
另外,上述代码其实回滚了两次,一次是我们手动回滚。
一次是因为异常 回滚,虽然第二次回滚没什么用,但是结果是我们想要的就行了。
如果你不想看到这个异常,那也简单了。
把tryCatch 删掉,使用最原始的算术异常,就行了,
效果是一样的。
那么,问题来了:为什么我们的事务能够实现嵌套呢?
嵌套事务只所以能够实现部分事务的回滚,是因为事务中有⼀个保存点(savepoint)的概念.
保存点:
就类似于玩单机游戏的时候,保存当前游戏进度。如果你后面的剧情没通过,不至于重头再来。
在代码中,就是在每个事务执行之前,先“存一份档”,如果事务执行不成功,就回档。
这样就不会影响到其它事务的运行。
不至于全部事务都回滚,只回滚当前执行失败的事务。
嵌套事务进⼊之后相当于新建了⼀个保存点,⽽滚回时只回滚到当前保存点,因此之前的事务是不受影响的,这⼀点可以在 MySQL 的官⽅⽂档汇总找到相应的资料