Flink - Java篇
文章目录
- 前言
- 一、概述
-
- 1 Flink是什么
- 2 架构分层
- 3 数据处理流水线
- 4 运行组件
-
- TaskManager
- JobManager
- ResourceManager
- Dispatcher
- 5 其他流式计算框架
- 二、入门与使用
-
- 1 Flink基本安装
-
- 1.1 Linux
- 1.2 Java
- 1.3 Scala(待补充)
- 1.4 集群模式
- 2 常用API
-
- 2.1 DataStream 流处理
-
- DataSource
- Transformation
- Sink
- 示例一:自定义数据源(SourceFunction)
- 示例二:自定义分区
- 示例三:Socket通信示例
- 示例四:RabbitMQ作为数据源
- 示例五:自定义Sink
- 2.2 DataSet 批处理
- 2.3 Table API / SQL(待补充)
- 2.4 关于序列化
- 三、进阶使用
-
- 1 Flink中对于变量的高级用法
-
- Broadcast
- Accumulator
- 分布式缓存
- 总结
- 2 状态管理与恢复(待补充)
- 3 窗口(待补充)
-
- 窗口类型
- 窗口函数
- 参考文章
- 4 时间(待补充)
-
- 固定乱序长度策略
- 单调递增时间戳策略
- 不生成水印策略
- 关于水印延迟/窗口允许延迟
- 5 并行度
- 四、原理解析(待补充)
- 总结
前言
目前本人是Java开发工程师,所以里面大部分的学习笔记都是以Java代码为主,Scala后面我再学所以后续再进行补充。
| 文章目录 |
|---|
| 《Flink入门与实战》 - 徐葳 |
| / |
一、概述
1 Flink是什么
Apache Flink,内部是用Java及Scala编写的分布式流数据计算引擎,可以支持以批处理或流处理的方式处理数据,在2014年这个项目被Apache孵化器所接受后,Flink迅速成为ASF(ApacheSoftware Foundation)的顶级项目之一,在2019年1月,阿里巴巴集团收购了Flink创始公司(DataArtisans),打造了阿里云商业化的实时计算Flink产品。
它有如下几个特点
- 低延迟
- 高吞吐
- 支持有界数据/无界数据的处理,数据流式计算
- 支持集群,支持HA,可靠性强
什么是有界数据/无界数据?
- 有界数据:数据是有限的,一条SELECT查询下的数据不会是源源不断的
- 无界数据:数据源源不断,不知道为什么时候结束,例如监控下的告警
2 架构分层
| 名称 | 描述 |
|---|---|
| Deploy 部署方式 | 本地/集群/云服务部署。 |
| Core 分布式流处理模型 | 计算核心实现,为API层提供基础服务。 |
| API 调用接口 | 提供面向无界数据的流处理API及有界数据的批处理API,其中流处理对应DataStream API,批处理对应DataSet API。 |
| Library 应用层 | 提供应用计算框架,面向流处理支持CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作),面向批处理支持FlinkML(机器学习库)、Gelly(图处理)、Table 操作。 |
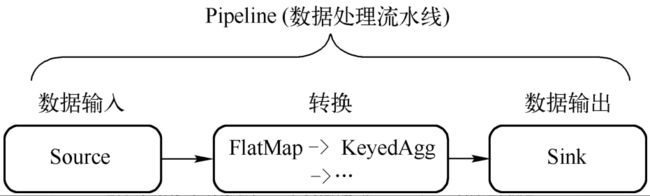
3 数据处理流水线
一个Flink任务 = DataSource + Transformation + DataSink
DataSource :数据源
Transformation :数据处理
DataSink:计算结果输出
而Flink在网络传输中通过缓存块承载数据,可以通过设置缓存块的超时时间,变相的决定了数据在网络中的处理方式。
4 运行组件
| 文章目录 |
|---|
| Flink-运行时架构中的四大组件-SmallScorpion的CSDN博客 |
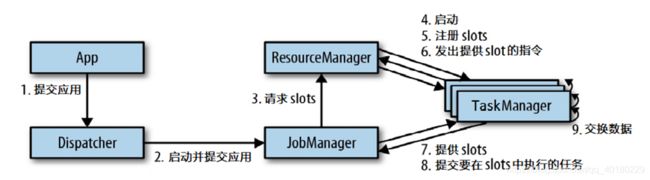
Flink运行时主要有四个大组件
- TaskManager - 任务管理器(1)
- JobManager - 任务管理器(2)
- ResourceManager - 资源管理器
- Dispatcher - 分配器
下面来聊聊关于这四个组件的作用
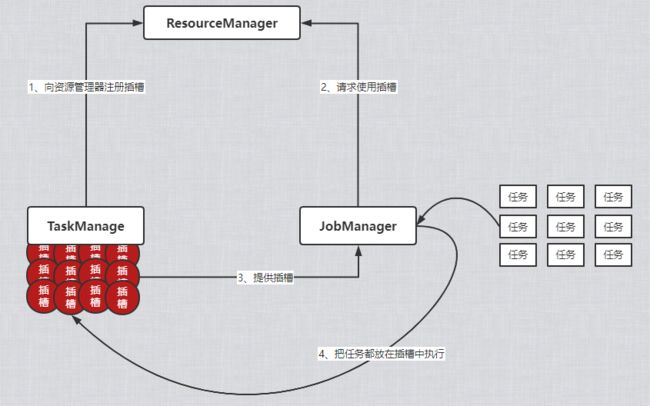
TaskManager
工作进程,通常在一个Flink节点内会有多个TaskManager运行,而在每个TaskManager中又包含了多个插槽(slots),插槽的数量代表了TaskManager能够执行的任务数量。
进程启动后,TaskManager会向ResourceManager(资源管理器)注册自己的插槽,JobManager通过从ResourceManager请求到的插槽信息,来分配任务执行。
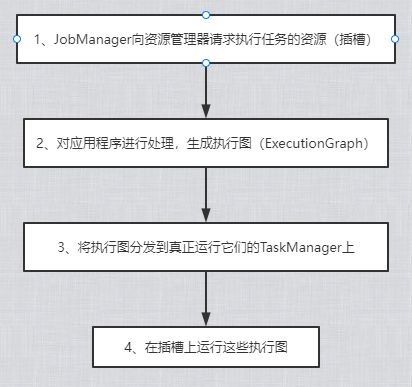
JobManager
控制一个应用程序执行的主进程,一个应用程序只会对应一个JobManager。
一个应用程序包括:
- 作业图 - JobGraph
- 逻辑数据流图 - logical dataflow graph
- 含有打包完的所需资源的Jar包
大致的流程是这样
ResourceManager
负责管理TaskManager的slot(插槽),插槽指处理资源单元,当JobManager申请插槽资源时,ResourceManager会把目前已经注册上来的空闲的插槽信息分配给JobManager。
如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。
Dispatcher
- 提供Web UI,展示及监控任务执行信息
- 非必须组件,取决于应用提交运行的方式
- 当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager
- 可以跨作业运行,它为应用提交提供了REST接口
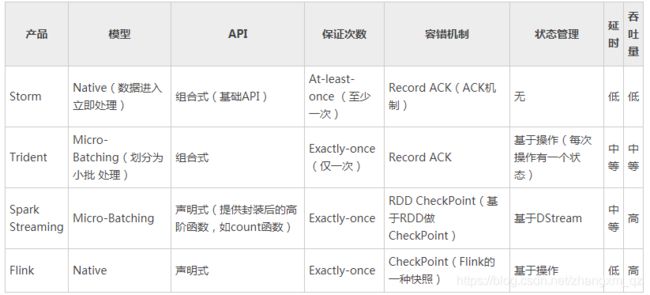
5 其他流式计算框架
| 文章目录 |
|---|
| Flink介绍、特点及和与其他大数据框架对比_zhangxm_qz的CSDN博客 |
二、入门与使用
1 Flink基本安装
前置描述:xxxxxxxxxxxxx
1.1 Linux
| 下载链接 |
|---|
| Index of /dist/flink/flink-1.14.3 (apache.org) |
首先去apache官网下载部署的软件包,下载完成之后进行解压
## 解压
tar -zxvf flink-1.14.3-bin-scala_2.12.tgz
## 进入bin目录 启动
./start-cluster.sh
## Flink提供的WebUI的端口是8081 此时可以去看看是否启动完成
netstat -anp |grep 8081
接着通过页面访问8081端口来个初体验
关于Linux下的Flink Shell终端的使用
| 文章目录 |
|---|
| flink~使用shell终端_cai_and_luo的博客-CSDN博客 |
1.2 Java
| 文章目录 |
|---|
| Flink入门之Flink程序开发步骤(java语言)_胖虎儿的博客-CSDN博客 |
导入依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.14.3version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>1.14.3version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_2.12artifactId>
<version>1.14.3version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-coreartifactId>
<version>1.14.3version>
dependency>
入门Demo
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class DemoApplication {
public static void main(String[] args) throws Exception {
/**
* 大致的流程就分为
* 1.环境准备
* 设置运行模式
* 2.加载数据源
* 3.数据转换
* 4.数据输出
* 5.执行程序
*/
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置运行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.加载数据源
DataStreamSource<String> elementsSource = env.fromElements("java,scala,php,c++",
"java,scala,php", "java,scala", "java");
// 3.数据转换
DataStream<String> flatMap = elementsSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String element, Collector<String> out) throws Exception {
String[] wordArr = element.split(",");
for (String word : wordArr) {
out.collect(word);
}
}
});
// DataStream 下边为DataStream子类
SingleOutputStreamOperator<String> source = flatMap.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
});
// 4.数据输出
source.print();
// 5.执行程序
env.execute();
}
}
关于在设置运行模式的代码上,有三种选择
/**
* Runtime execution mode of DataStream programs. Among other things, this controls task scheduling,
* network shuffle behavior, and time semantics. Some operations will also change their record
* emission behaviour based on the configured execution mode.
*
* @see
* https://cwiki.apache.org/confluence/display/FLINK/FLIP-134%3A+Batch+execution+for+the+DataStream+API
*/
@PublicEvolving
public enum RuntimeExecutionMode {
/**
* The Pipeline will be executed with Streaming Semantics. All tasks will be deployed before
* execution starts, checkpoints will be enabled, and both processing and event time will be
* fully supported.
*/
/** 流处理模式 */
STREAMING,
/**
* The Pipeline will be executed with Batch Semantics. Tasks will be scheduled gradually based
* on the scheduling region they belong, shuffles between regions will be blocking, watermarks
* are assumed to be "perfect" i.e. no late data, and processing time is assumed to not advance
* during execution.
*/
/** 批处理模式 */
BATCH,
/**
* Flink will set the execution mode to {@link RuntimeExecutionMode#BATCH} if all sources are
* bounded, or {@link RuntimeExecutionMode#STREAMING} if there is at least one source which is
* unbounded.
*/
/** 自动模式 */
AUTOMATIC
}
1.3 Scala(待补充)
与Java一样都在IDEA编译器上做,此时引入依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-scala_2.12artifactId>
<version>1.14.3version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId