NoSQL数据库Hbase之Phoenix与Sqoop
目录
Phoenix
简介和优势
功能特性
搭建与部署
shell操作Phoenix
java使用jdbc调用phoenix
使用springboot+mybatis方式来调用phoenix
代码仓库
Sqoop
简介
Sqoop Import
Sqoop Export
搭建部署
版本问题
部署
下载mysql jar
操作mysql数据库
将mysql数据导入HDFS
将mysql数据导入HBase
Phoenix
无论nosql再牛逼,如果不落地到sql,那么就很难适应大众,毕竟sql上手简单,受众群体广泛,前面博客也看到了HBase的demo,简直是繁琐,即便用javaAPI,也是麻烦的一B。
简介和优势
- Phoenix应运而生,它是构建在HBase上的中间件,可使用sql的方式执行操作Hbase,性能强劲,支持二级索引,查询效率很高~
- 支持完整的ACID事务与JDBC API
- 可以和hadoop其他如spark、hive、MapReduce、pig、flume等产品集成
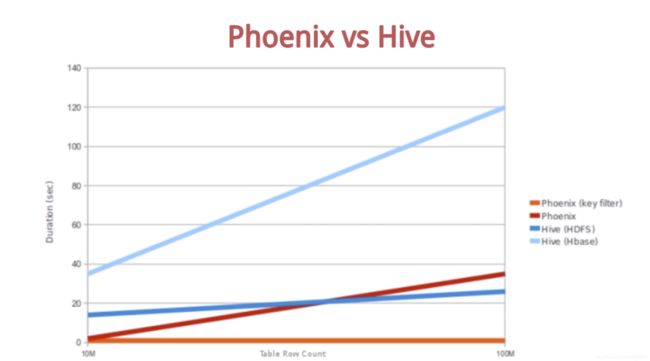
可以看到Phoenix的性能非常优秀:
Phoenix通过协处理器在服务端进行操作,从而最大限度减少客户端与服务端的传输(类似于存储过程直接在sql执行)
Phoenix通过定制的过滤器对数据做处理
使用HBase的API,而不是MapReduce的框架(Hive是使用MR的),这样可以极大减少启动成本
功能特性
稍微介绍一下

- 多租户
可以通过多租户表和租户专用的链接,使用户只能访问到用户自己的数据,多用于权限控制
- 二级索引
我们可以自由的根据列或者表达式形成一个备用的行健,进行快速查找(而之前索引是以RowKey作为索引,用过滤器筛选方式)
- 用户定义函数
用户可以自己实现UDF,像其内置的函数(select、delete等)一样使用
- 行时间戳列
Phoenix提供的RowTimestap,它可以将每行的时间戳映射成Phoenix的一个列,
- 分页查询
Phoenix支持标准的sql分页
- 视图
Phoenix支持标准的视图,但是Phoenix使用多个虚拟表共享底层的物理HBase表
搭建与部署
下载安装包
wget http://mirror.bit.edu.cn/apache/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
解压顺便改个名字:
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /root
mv apache-phoenix-5.0.0-HBase-2.0-bin/ phoenix
将jar拷贝至每个HBase节点的 hbase_home/lib 下
cp phoenix-core-5.0.0-HBase-2.0.jar /root/hbase/lib/
cp phoenix-5.0.0-HBase-2.0-server.jar /root/hbase/lib/
rsync -av /root/hbase/lib/ node1:/root/hbase/lib/ (也可以使用scp哦)
rsync -av /root/hbase/lib/ node2:/root/hbase/lib/
然后重启整个hbase:
hbase_home/bin/stop-hbase.sh
hbase_home/bin/start-hbase.sh
进入phoenix/bin,执行启动操作,链接hbase:
./sqlline.py
这里默认链接localhost,也可以指定 ./sqlline.py localhost
来试一下,输入==!tables==查看所有表:

搭建大功告成~~
shell操作Phoenix
先来创建一个表:
create table demo(id integer not null primary key, name varchar(50),sex integer);
使用 !tables, 发现创建成功
插入一条数据
upsert into demo(id, name,sex) values(1,‘zhangsan’,18);
查询:select * from demo; 果然可以查询的到
java使用jdbc调用phoenix
这个就是炒鸡简单了,我们先用最普通的方法来调用一发:
首先上pom:
org.apache.phoenix
phoenix-core
5.0.0-HBase-2.0
org.apache.htrace
htrace-core4
org.apache.htrace
htrace-core4
4.0.1-incubating
org.apache.hadoop
hadoop-common
2.8.4
然后来创建一个main, 查询上面博主创建的demo表数据:
package codemperor.phoenix;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class Main {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
//这里博主的电脑配置了hosts:master、node1、node2
Connection connection = DriverManager.getConnection("jdbc:phoenix:master:2181");
PreparedStatement preparedStatement = connection.prepareStatement("select * from demo");
ResultSet resultSet = preparedStatement.executeQuery();
while (resultSet.next()) {
System.out.println("id:" + resultSet.getString("id") +
"name:" + resultSet.getString("name") +
"sex:" + resultSet.getString("sex")
);
}
preparedStatement.close();
connection.close();
}
}
运行之后查到了之前插入的数据。ok斯密达,是不是非常之简单
使用springboot+mybatis方式来调用phoenix
首先引入spring和相关的jar:
org.apache.phoenix
phoenix-core
5.0.0-HBase-2.0
org.apache.htrace
htrace-core4
org.apache.htrace
htrace-core4
4.0.1-incubating
org.apache.hadoop
hadoop-common
2.8.4
org.springframework.boot
spring-boot-starter-web
ch.qos.logback
logback-classic
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.2
tk.mybatis
mapper-spring-boot-starter
2.0.2
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
然后我们创建一个BaseMapper(tkmapper标配):
package codemerpor.phoenix.demo.mapper;
import tk.mybatis.mapper.common.Mapper;
import tk.mybatis.mapper.common.MySqlMapper;
/**
* @author codemperor
*/
public interface BaseMapper extends Mapper, MySqlMapper {
}
Ok这里成功一大半,我们创建Demo和DemoMapper
package codemerpor.phoenix.demo.mapper;
import codemerpor.phoenix.demo.entity.Demo;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Component;
import tk.mybatis.mapper.common.MySqlMapper;
/**
* @author codemperor
*/
@Component
@Mapper
public interface DemoMapper extends BaseMapper {
}
package codemerpor.phoenix.demo.entity;
public class Demo {
private Integer id;
private String name;
private Integer sex;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getSex() {
return sex;
}
public void setSex(Integer sex) {
this.sex = sex;
}
@Override
public String toString() {
final StringBuilder sb = new StringBuilder("{");
sb.append("\"id\":")
.append(id);
sb.append(",\"name\":\"")
.append(name).append('\"');
sb.append(",\"sex\":")
.append(sex);
sb.append('}');
return sb.toString();
}
}
come on baby,再来一发配置文件:
spring:
datasource:
driver-class-name: org.apache.phoenix.jdbc.PhoenixDriver
url: jdbc:phoenix:master:2181
username:
password:
mybatis:
configuration:
map-underscore-to-camel-case: true
ok,来写一发测试类
package codemerpor.phoenix.demo;
import codemerpor.phoenix.demo.entity.Demo;
import codemerpor.phoenix.demo.mapper.DemoMapper;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringBootTest(classes = Application.class)
@Slf4j
public class PhoenixSpringBootTest {
@Autowired
private DemoMapper demoMapper;
@Test
public void test() {
List demoList = demoMapper.selectAll();
System.out.println(demoList.toString());
}
}
运行之后,直接查出了刚才博主在demo表中插入的数据。so,你可以使用insert、delete、update等等。
代码仓库
附上代码仓库:https://gitee.com/_madi/hadoop-demo.git 其中phoenix-demo就是啦。
Sqoop
简介
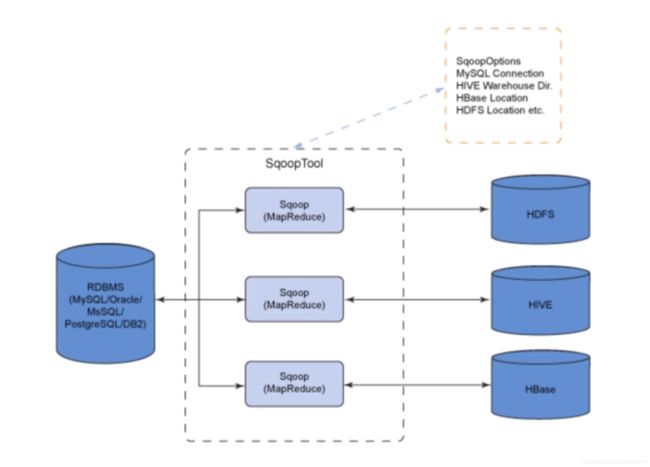
- 用于在Hadoop与传统数据库(mybatis)进行数据传输(运输工)
- 可以通过hadoop的MapReduce把数据从关系型数据库导入hadoop集群
- 传输结构化或者非结构化数据时,全部是自动化的
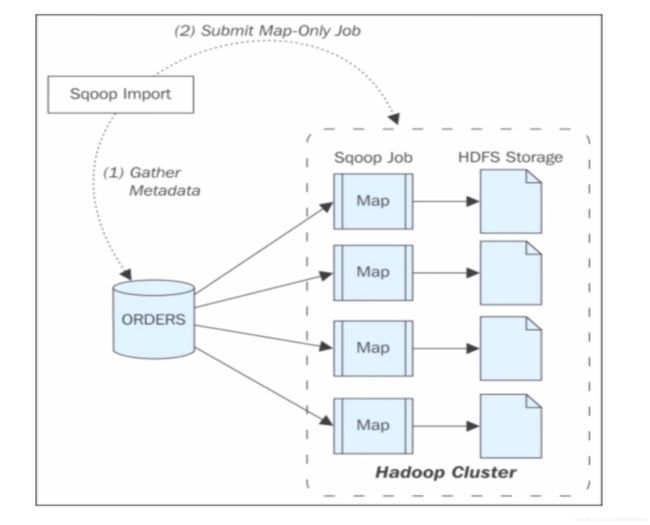
Sqoop Import
我们来看一下它的导入数据的流程
Sqoop Export

搭建部署
版本问题
首先推荐一个版本介绍博客:https://blog.csdn.net/lilychen1983/article/details/80241368
因为博主在生产环境有团队自己的LoggerCenter,我们的数据(哪怕是非业务的实时数据)都是通过日志方式进行收集,So,sqoop博主这里就选择sqoop1来安装,然后粗略的实现将mysql数据入hdfs或者hbase,目前博主团队还没有业务场景需要直接将mysql数据扔进hdfs,就算有,也是量不大的,搭建一整套传输机制的成本还是有滴~~
部署
下载安装包 然后解压
wget https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /root
顺便换个名字:mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop
再顺便可以用help命令,在sqoop/bin下面:./sqoop help
下载mysql jar
我们既然要把mysql数据导入到hdfs中,我们得先来一个mysql-connector-java-5.1.46.jar, 进入sqoop/lib中,下载jar
wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.46/mysql-connector-java-5.1.46.jar
操作mysql数据库
我们先查看有多少个schema(博主的数据库是阿里云rds)
./sqoop list-databases --connect jdbc:mysql://你的数据库ip:3306/ --username root -P
然后回车之后输入密码之后,现实所有schema list
然后尝试一把,将某个表里的数据查询出来:
./sqoop eval --connect jdbc:mysql://数据库ip:3306/demo --username demo -P --query “select * from api”
最终查询出了数据
将mysql数据导入HDFS
./sqoop import --connect jdbc:mysql://数据库ip:3306/demo --username demo -P --table api --target-dir /sqoop/api --num-mappers 1
执行完成之后,查看hadoop中是否有这张表的数据

果然有数据,查询之后发现的确是表中的数据(默认列用逗号分割开了)
将mysql数据导入HBase
这次我们不直接导入表了,我们通过sql语句导入到hbase($CONDITIONS这个必须加哦):
./sqoop import --connect jdbc:mysql://数据库ip:3306/demo --username demo -P --query "select * from api where 1=1 and $CONDITIONS " --hbase-table api --hbase-create-table --hbase-row-key uri --split-by create_time --column-family family1
然后执行完毕之后,我们去hbase里面看看。