大数据系列(五)NoSQL数据库Hbase之搭建使用
目录
- 首语
- Hbase简介
-
- 特点和应用场景
- 和关系型数据库的结构对比
- Hbase的架构体系
- Hbase表结构
-
- 按照关系型数据库来看Hbase的表结构
- Hbase部署搭建
-
- 下载相关的软件包
- Zookeeper的搭建
-
- 设置时间同步
- 解压重命名, 建立相关的目录
- 修改配置文件
- 创建myid
- 启动zk集群(所有节点都需要启动)
- Hbase搭建
-
- 解压并建立相关目录
- 修改启动文件hbase-env.sh
- 添加所有的region服务器到regionservers文件中
- 配置hbase-site.xml
- 把hbase复制到其他节点
- 启动hbase集群
- 测试
首语
博主Hbase相关的链接系列:
shell以及java springboot使用hbase实例:https://blog.csdn.net/zl592886931/article/details/90143356
性能优化、监控容错: https://blog.csdn.net/zl592886931/article/details/90217681
phoenix搭建与使用(包含java jdbc、springboot mybatis)以及sqoop搭建与使用(mysql到hdfs与hbase): https://blog.csdn.net/zl592886931/article/details/90340763
Hbase简介
Hbase是一个分布式的、面向列的开源数据库,在Hadoop之上实现了BigTable的能力。它适合非结构化数据存储.Hbase适合存储超大数据并且进行大数据的实时查询
特点和应用场景
- 容量大:Hbase但表支持百亿行、百万列的量级(mysql一般情况下单表不超过500w,列不超过30列)
- 面向列:在条件范围下可以极大减少读取数据的量,并且列可以随着数据动态扩展
- 多版本:Hbase每一列的数据存储有多个Version
- 稀疏性:为空的列不占用空间,表可以设计的很稀疏
- 扩展性:底层依赖与HDFS,所以可以动态增加节点
- 高可靠性:WAL机制保证了数据写入时不会因为集群异常而导致数据丢失;Replication保障了数据存储在多个副本之上,基于HDFS,大家懂得。
- 高性能:底层LSM数据结构和RowKey有序排列等架构设计,让Hbase具有非常高的写入性能;Region切分、主键索引和缓存机制使得Hbase在海量数据下具备一定的随机读取性能,针对RowKey查询可以达到毫秒级
和关系型数据库的结构对比
首先我们来看一下mysql中的数据结构:
| ID | username | password |
|---|---|---|
| 1 | Tonny | 123456 |
| 2 | Sam | 67890 |
而在Hbase里面如何存储呢,如下:
| RowKey | Column Family |
|---|---|
| rk_id | cf:id1=1 cf:id2=2 |
| rk_username | cf:username1=Tonny cf:username=Sam |
| rk_password | cf:password 1=123456 cf:password =67890 |
Hbase列是动态增加的,数据可以自动切分存储,支持高并发读取,但是mysql关系型数据库是无法做到这些的。但是HBase不支持条件查询,只支持RowKey查询。
Hbase的架构体系
先来一张图:

可以看到,在分布式Hbase集群中,有以下三个东西组成:
- Master(HMaster):是集群的中央节点,将==Region(Hbase最小存储单元)==分配给RegionServer,协调RegionServer的负载并维护集群的状态 ,并且维护表和Region的元数据,不参与数据的输入输出过程
- RegionServer:维护被分配的Region,处理对这些Region的IO请求, 并且负责切分运行过程中变的过大的Region
- Zookeeper:是集群的协调器,保证至少一个HMaster是active状态,并且维护了HMaster的信息,提供RegionServer的信息
关于架构体系详细描述,推荐一篇博客:https://www.cnblogs.com/steven-note/p/7209398.html
Hbase表结构
按照关系型数据库来看Hbase的表结构
我们来一个统计个人信息的表,如果按照msyql,肯定是n个列,每一行对一个人,但是有些字段,比如工作经历,他是不确定有多少次的,再比如教育经历,有些人是没上过博士的,所以这样就导致列个数不固定,如果使用mysql,肯定需要在做一个关系表存放一些其他信息,而Hbase,其实指定列簇之后,可以在其中任意扩展列信息

我们来一张有数据的Hbase表:
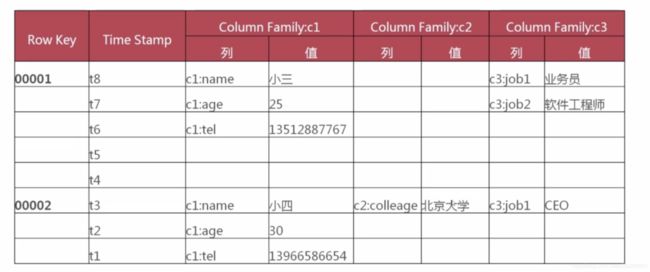
有了数据我们就能更清晰了。我们可以看到上面表中两个人,每行数据其实就是上面说到mysql中的列。
习惯了mysql这样的存储,肯定有人会问,列蔟不够,不还是要增加吗?那不就是mysql中的列吗?不是还要修改数据结构吗?
一张表中列蔟不会超过5个,每个列蔟中的列是没有限制的,列只有插入数据才会存在。
Hbase部署搭建
Hbase需要两个外置服务:HDFS与Zookeeper,关于hadoop的搭建可以参考博主之前的博客,这里不在赘述,主要讲解zk与hbase的搭建
下载相关的软件包
zk包:wget http://apache.claz.org/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
Hbase:wget http://mirror.bit.edu.cn/apache/hbase/2.1.4/hbase-2.1.4-bin.tar.gz
Zookeeper的搭建
设置时间同步
博主依然使用的是阿里云,阿里云自带同步,如果小伙伴们需要设定,可以自行百度。
解压重命名, 建立相关的目录
解压: tar -zxvf zookeeper-3.4.14.tar.gz -C /root
然后我们把名称重新命名:mv zookeeper-3.4.14/ zookeeper
建立相关数据目录:mkdir /root/zookeeper/data
修改配置文件
在==/root/zookeeper/conf==之下找到zoo_sample.cfg,复制一份出来
复制:cp zoo_sample.cfg zoo.cfg
修改:vi zoo.cfg
加入以下配置
dataDir=/root/zookeeper/data
server.1=master:2888:3888
server.2=node1:2888:3888
server.3=node2:2888:3888
复制给各个子节点:
scp -r zookeeper/ node1:/root/
scp -r zookeeper/ node2:/root/
创建myid
依次在各个zookeeper/data下面创建myid文件,写入内容:
第一种方式:
在zookeeper的data下面
mkdir myid
vi myid
三个节点内容为:master为1,node1为2,node2为3
第二种(这个快一些,毕竟命令):
ssh master
touch /root/zookeeper/data/myid
echo 1 > /root/zookeeper/data/myid
ssh node1
touch /root/zookeeper/data/myid
echo 2 > /root/zookeeper/data/myid
ssh node2
touch /root/zookeeper/data/myid
echo 3 > /root/zookeeper/data/myid
启动zk集群(所有节点都需要启动)
在所有节点分别执行:
/root/zookeeper/bin/zkServer.sh start
ok~启动成功
可以使用下面命令查看zk状态:
/root/zookeeper/bin/zkServer.sh status
Hbase搭建
解压并建立相关目录
解压:tar -zxvf hbase-2.1.4-bin.tar.gz -C /root
修改名称: mv hbase-2.1.4/ hbase
建立日志目录: mkdir /root/hbase/logs
修改启动文件hbase-env.sh
在hbase/conf中找到hbase-env.sh:
– 添加如下内容
– 1、设置java安装路径
export JAVA_HOME=/usr/java/default
– 2、设置hbase的日志地址
export HBASE_LOG_DIR=/root/hbase/logs
– 3、设置是否使用hbase管理zookeeper(因使用zookeeper管理的方式,故此参数设置为false)
export HBASE_MANAGES_ZK=false
– 4、设置hbase的pid文件存放路径
export HBASE_PID_DIR=/root/hadoop/pids
添加所有的region服务器到regionservers文件中
vim /root/hbase/conf/regionservers
– 删除localhost,新增如下内容
master
node1
node2
注:hbase在启动或关闭时会依次迭代访问每一行来启动或关闭所有的region服务器进程
配置hbase-site.xml
vim /root/hbase/conf/hbase-site.xml
内容如下:
hbase.rootdir
hdfs://master:9000/hbase
hbase.cluster.distributed
true
hbase.master
hdfs://master:60000
hbase.tmp.dir
/root/hbase/tmp
hbase.unsafe.stream.capability.enforce
false
hbase.zookeeper.quorum
master,node1,node2
hbase.zookeeper.property.dataDir
/root/zookeeper/data
hbase.zookeeper.property.clientPort
2181
hbase.master.info.port
16010
hbase.regionserver.info.port
16030
把hbase复制到其他节点
scp -r /root/hbase node1:/root
scp -r /root/hbase node2:/root
启动hbase集群
/root/hbase/bin/start-hbase.sh
测试
先进入hbase:
/root/hbase/bin/hbase shell
创建一个user表
create ‘user’,‘userdetail’
发现报错了: KeeperErrorCode = NoNode for /hbase/master, 我们去日志里发现启动是失败的,错误日志是:
Caused by: java.lang.ClassNotFoundException: org.apache.htrace.SamplerBuilder
我们找到这个:hbase/lib/htrace-core4-4.2.0-incubating.jar, 把这个jar拷贝到lib下,还是继续报错,然后博主把这个jar换成里==htrace-core-3.1.0-incubating.jar ==
重新试一下刚才的操作:
create ‘user’,‘userDetail’
成功:
Took 2.4336 seconds
=> Hbase::Table - user
来个插入:
put ‘user’,‘row1’,‘userDetail:name’,‘zhangsan’
然后查询一把看看:
get ‘user’,‘row1’,‘userDetail:name’
得到结果如下:
hbase(main):005:0> get ‘user’,‘row1’,‘userDetail:name’
COLUMN CELL
userDetail:name timestamp=1557561251324, value=zhangsan
1 row(s)
Took 0.0661 seconds
我们去webUI看看我们创建的表:

至此全部成功斯密达,撒花~~