flink的架构原理常用代码实现
文章目录
-
- 1.1 什么是flink
- 1.2 flink特点
- 1.3 编程API
- 二 flink架构
-
- 2.1 架构图
- 2.2 含义
- 三 flink和其他框架对比
-
- 3.1 与spark角色对比
- 3.2 三大实时计算框架整体对比
- 四 flink环境搭建
-
- 4.1 standalone模式
-
- 4.1.1 架构
- 4.1.2 搭建步骤
- 4.1.3 启动集群并检测
- 4.1.4 提交flink任务
- 4.2 flink on yarn
-
- 4.2.1 官网资料
- 4.2.2配置
- 4.2.3 flink run
-
- 4.2.3.1 任务提交
- 4.2.3.2 提交结果
- 4.2.3.3 测试
- 4.2.3.4 yarn杀进程及查看日志命令
- 4.2.4 yarn-session
- 4.2.5 flink on yarn流程图
- 4.3 localhost模式查看webUI
-
- 4.3.1新增依赖
- 4.3.2 创建环境
- 4.3.3 启动日志
- 4.3.4 访问页面
- 五 flink项目模板下载
-
- 5.1 java模板
- 5.2 scala模板
- 六 flink入门程序
-
- 6.1 编程模型
- 6.2 DataStream实时wordcount
- 6.3 DataSet 离线wordcount
- 七 flink算子
-
- 7.1 map
- 7.2 RichMapFunction
- 7.3 flatMap
- 7.4 filter
- 7.5 keyBy
-
- 7.5.1 单个字段keyby
- 7.5.2 多个字段keyBy(过时API)
- 7.5.3 多个字段KeyBy(新API,Tuple封装)
- 7.5.4 多个字段KeyBy(POJO封装,终极)
- 7.6 reduce
- 7.7 Aggregations
-
- 7.7.1 sum
- 7.7.2 min
- 7.7.3 max
- 7.7.4 minBy
- 7.7.5 maxBy
- 7.8 union
- 八 Window
-
- 8.1 Time(Flink中涉及的时间)
- 8.2 window类型
-
- 8.2.1 TimeWindow(按照时间生成Window)
-
- 8.2.1.1 滚动窗口
-
- 8.2.1.1.1 timeWindowAll(全局数据,默认Processing Time)
- 8.2.1.1.2 timeWindow(窗口滚动的时候,所有组都要执行,并行处理,默认Processing Time)
- 8.2.1.1.3 timeWindowAll(全局数据,使用Event Time)
- 8.2.1.1.4 timeWindow(分组数据,使用Event Time)
- 8.2.1.2 滑动窗口
-
- 8.2.1.2.1 全局滑动(默认Processing Time)
- 8.2.1.2.2 分组滑动(默认Processing Time)
- 8.2.1.3 会话窗口
-
- 8.2.1.3.1 不分组(默认Processing Time)
- 8.2.1.3.2 分组(单个组出发,不是全部触发,默认Processing Time)
- 8.2.1.3.3 不分组(使用Event time)
- 8.2.1.3.4分组(使用Event time)
- 8.2.2 GlobalWindow(CountWindow)
-
- 8.2.2.1 countWindowAll
- 8.2.2.2 countWindow
- 九 watermark
-
- 9.1 基本概念
- 9.2 引入watermark
- 9.3生成watermark的两种方式
- 9.4 EventTimeWindow API
-
- 9.4.1 滚动窗口(TumblingEventTimeWindows)
- 9.4.2 滑动窗⼝(SlidingEventTimeWindows)
- 9.4.3 会话窗⼝(EventTimeSessionWindows)
- 十 flink 原理解读
-
- 10.1 Task和subtask
-
- 10.1.1 概念
- 10.1.2 如何划分task
- 10.1.3 区别
- 10.2 startNewChain的使用
- 10.3 disableChain的使用
- 10.4 共享资源槽
- 10.5 任务重启策略
- 10.6 chekpoint
-
- 10.6.1 定义
- 10.6.2 配置checkpoint
- 10.7 Barrier
- 10.8 state
-
- 10.8.1 概念
- 10.8.2 分类
- 10.8.3 应用
- 10.8.4 operator state和keyed state的一致性
- 10.9 stateBackEnd
-
- 10.9.1 MemoryStateBackend
- 10.9.2 FsStateBackend
- 10.9.4 RocksDBStateBackend
- 10.10 flink如何保证ExactlyOnce的
- 10.11 flink背压机制
- 10.12 两段提交原理
-
- 10.12.1 原理
- 10.12.2 mysql分两段提交代码实现
- 十一 flink整合kafka
-
- 11.1 kafka-->flink-->redis
-
- 11.1.1 增加依赖
- 11.1.2 代码实现
- 11.1.3 自定义RedisSink
- 11.2 kafka-->flink-->mysql
-
- 11.2.1 增加依赖
- 11.2.2 代码实现
- 十二 table API
-
- 12.1 依赖
- 12.2 代码实现
- 十三 双流join
-
- 13.1 window join
- 13.2 interval join
- 十四 侧流输出
-
- 14.1 数据流拆分
- 14.2 获取窗口延迟数据
- 十五 异步IO
-
- 15.1 Httpclient
-
- 15.1.1 官方示例
- 15.1.2 通过HttpClient访问高德接口
- 15.2 Mysql
一 flink简介
1.1 什么是flink
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
1.2 flink特点
- 批流统一
- 支持高吞吐、低延迟、高性能的流处
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 支持迭代计算
- Flink在JVM内部实现了自己的内存管理
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
1.3 编程API

二 flink架构
2.1 架构图

2.2 含义
- JobManager
也称之为Master,用于协调分布式执行,它用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master,如果配置高可用模式则会存在多个master,它们其中有一个是leader,而其他的都是standby。
- TaskManager
也称之为Worker,用于执行一个dataflow的task、数据缓冲和Data Streams的数据交换,Flink运行时至少会存在一个TaskManager。JobManager和TaskManager可以直接运行在物理机上,或者运行YARN这样的资源调度框架,TaskManager通过网络连接到JobManager,通过RPC通信告知自身的可用性进而获得任务分配。
- Client
Flink用来提交任务的客户端,可以用命令提交,也可以用浏览器提交
- Task
Task是一个阶段多个功能相同suntask的集合,类似spark中的taskset
- Subtask
Subtask是flink中任务执行最小单元,是一个java类的实例,这份java类中有属性和方法,完成具体的计算逻辑
- Operator chain
没有shuffle的多个算子合并在一个subtask中就形成了Operator chain,类似spark中的pipeline
- Slot
Flink中计算资源进行隔离的单元,一个slot中可以运行多个subtask,但是这些subtask必须是来自同一个job的不同task的subtask
- State
Flink任务运行过程中计算的中间结果
- Checkpoint
Flink用来将中间结果持久化的指定的存储系统的一种定期执行的机制
- stateBackend
Flink用来存储中间计算结果的存储系统,flink支持三种statebackend。分别是memory,fsbackend,rocksDB
三 flink和其他框架对比
3.1 与spark角色对比
| Spark Streaming | Flink |
|---|---|
| DStream | DataStream |
| Trasnformation | Trasnformation |
| Action | Sink |
| Task | SubTask |
| Pipeline | Oprator chains |
| DAG | DataFlow Graph |
| Master + Driver | JobManager |
| Worker + Executor | TaskManager |
3.2 三大实时计算框架整体对比
| 框架 | 优点 | 缺点 |
|---|---|---|
| Storm | 低延迟 | 吞吐量低、不能保证exactly-once、编程API不丰富 |
| Spark Streaming | 吞吐量高、可以保证exactly-once、编程API丰富 | 延迟较高 |
| Flink | 低延迟、吞吐量高、可以保证exactly-once、编程API丰富 | 快速迭代中,API变化比较快 |
Spark就是为离线计算而设计的,在Spark生态体系中,不论是流处理和批处理都是底层引擎都是Spark Core,Spark Streaming将微批次小任务不停的提交到Spark引擎,从而实现准实时计算,SparkStreaming只不过是一种特殊的批处理而已。
Flink就是为实时计算而设计的,Flink可以同时实现批处理和流处理,Flink将批处理(即有有界数据)视作一种特殊的流处理。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E7jpO900-1607091411386)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]
四 flink环境搭建
4.1 standalone模式
standalone模式是Flink自带的分布式集群模式,不依赖其他的资源调度框架
4.1.1 架构
4.1.2 搭建步骤
1.下载安装包 下载地址:https://archive.apache.org/dist/flink/flink-1.11.1/
2.解压安装包(tar -zxvf flink-1.11.1-bin-scala_2.11.tgz)
3.修改conf下面的flink-conf.yaml文件
#指定jobmanager的地址
jobmanager.rpc.address: 192.168.xx.xx
#指定taskmanager的可用槽位的数量
taskmanager.numberOfTaskSlots: 6
4.修改conf目录下workers配置文件,指定taskmanager所在节点
192.168.xx.xx
5.将配置好的-flink拷贝到其他节点
4.1.3 启动集群并检测
4.1.3.1 启动
bin/start-cluster.sh
4.1.3.2 查看进程
在ndoe-1上可用看见StandaloneSessionClusterEntrypoint进程即JobManager,在其他的节点上可用看见到TaskManagerRunner 即TaskManager
4.1.3.3 访问UI界面(端口8081)
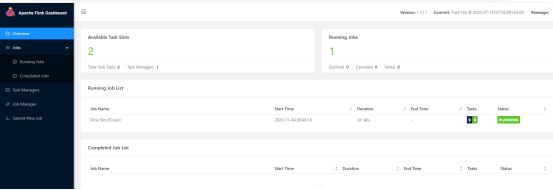
4.1.4 提交flink任务
4.1.4.1 命令行提交
bin/flink run
-m 192.168.xx.xx:8081
-p 4
-c com.wedoctor.flink.WordCountDemo /home/pgxl/liuzc/flink-project-scala-1.0.jar
--hostname 192.168.xx.xx
--port 8888
参数说明:
-m指定主机名后面的端口为JobManager的REST的端口,而不是RPC的端口,RPC通信端口是6123
-p 指定是并行度
-c 指定main方法的全类名


4.1.4.2 web界面提交
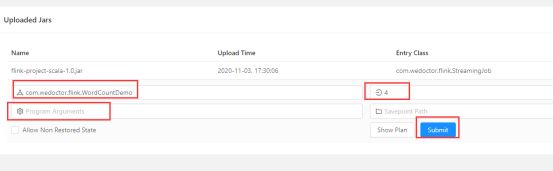
测试:

4.2 flink on yarn
4.2.1 官网资料
https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/yarn_setup.html
4.2.2配置
# export HADOOP_CLASSPATH=`hadoop classpath`# export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
如果没有配置,则会报错:
The program finished with the following exception:java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment & Operations" section of the official Apache Flink documentation.at org.apache.flink.yarn.cli.FallbackYarnSessionCli.isActive(FallbackYarnSessionCli.java:59)at org.apache.flink.client.cli.CliFrontend.validateAndGetActiveCommandLine(CliFrontend.java:1090)at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:218)at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:916)at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:992)at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30)at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:992)
flink提交失败,原因是Flink发布了新版本1.11.0,增加了很多重要新特性,包括增加了对Hadoop3.0.0以及更高版本Hadoop的支持,不再提供“flink-shaded-hadoop-*” jars,而是通过配置YARN_CONF_DIR或者HADOOP_CONF_DIR和HADOOP_CLASSPATH环境变量完成与yarn集群的对接。
4.2.3 flink run
Flink run直接在YARN上提交运行Flink作业(Run a Flink job on YARN),这种方式的好处是一个任务会对应一个job,即没提交一个作业会根据自身的情况,向yarn申请资源,直到作业执行完成,并不会影响下一个作业的正常运行,除非是yarn上面没有任何资源的情况下。
一般生产环境是采用此种方式运行。这种方式就需要确保集群资源足够。
4.2.3.1 任务提交
官方自带案例
./bin/flink run
-m yarn-cluster
-yqu root.wedw
-p 4
-yjm 4096m
-ytm 4096m examples/batch/WordCount.jar
开发案例
./bin/flink run
-m yarn-cluster
-yqu root.wedw
-p 4
-yjm 4096m
-ytm 4096m /home/pgxl/liuzc/flink-project-scala-1.0.jar
4.2.3.2 提交结果

4.2.3.3 测试
4.2.3.4 yarn杀进程及查看日志命令
#杀进程
yarn application -kill application_id
#查看日志
yarn logs -applicationId application_id
4.2.4 yarn-session
yarn seesion(Start a long-running Flink cluster on YARN)这种方式需要先启动集群,然后在提交作业,接着会向yarn申请一块空间后,资源永远保持不变。
如果资源满了,下一个作业就无法提交,只能等到yarn中的其中一个作业执行完成后,释放了资源,那下一个作业才会正常提交.
这种方式资源被限制在session中,不能超过,比较适合特定的运行环境或者测试环境。
bin/yarn-session.sh -s 2 -jm 1024 -tm 1024 -qu root.wedw
Usage: Optional
-D Dynamic properties
-d,--detached Start detached
-jm,--jobManagerMemory Memory for JobManager Container with optional unit (default: MB)
-nm,--name Set a custom name for the application on YARN
-at,--applicationType Set a custom application type on YARN
-q,--query Display available YARN resources (memory, cores)
-qu,--queue Specify YARN queue.
-s,--slots Number of slots per TaskManager
-tm,--taskManagerMemory Memory per TaskManager Container with optional unit (default: MB)
-z,--zookeeperNamespace Namespace to create the Zookeeper sub-paths for HA mode
如果您不想一直保持Flink YARN客户端运行,也可以启动一个分离的YARN会话。该参数称为-d或--detached。
在这种情况下,Flink YARN客户端只会将Flink提交到群集,然后自行关闭。
bin/yarn-session.sh -s 2 -d -jm 1024 -tm 1024 -qu root.wedw
#为了正常停止Flink群集,请使用以下命令:echo "stop" | ./bin/yarn-session.sh -id 。也可以通过YARN的网络界面或实用程序杀死Flink yarn application -kill 。但是请注意,杀死Flink可能不会清除所有作业工件和临时文件。
4.2.5 flink on yarn流程图

YARN客户端需要访问Hadoop配置以连接到YARN资源管理器和HDFS。它使用以下策略确定Hadoop配置:
测试是否YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH设置(按顺序)。如果设置了这些变量之一,则将其用于读取配置。
如果以上策略失败(在正确的YARN设置中应该不是这种情况),则客户端正在使用HADOOP_HOME环境变量。如果已设置,则客户端尝试访问 H A D O O P H O M E / e t c / h a d o o p ( H a d o o p 2 ) 和 HADOOP_HOME/etc/hadoop(Hadoop 2)和 HADOOPHOME/etc/hadoop(Hadoop2)和HADOOP_HOME/conf(Hadoop 1)。
在启动新的Flink YARN会话时,客户端首先检查所请求的资源(ApplicationMaster的内存和vcore)是否可用。之后,它将包含Flink和配置的jar上传到HDFS(步骤1)。
客户端的下一步是请求YARN容器(步骤2)以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定计算机上运行的YARN的NodeManager将负责准备容器(例如下载文件)。完成后,将启动ApplicationMaster(AM)。
该JobManager和AM在同一容器中运行。一旦成功启动,AM就会知道JobManager(自己的主机)的地址。它正在为TaskManager生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件还上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这使用户可以并行执行多个Flink YARN会话。
之后,AM开始为Flink的TaskManager分配容器,这将从HDFS下载jar文件和修改后的配置。完成这些步骤后,便会设置Flink并准备接受Jobs。
4.3 localhost模式查看webUI
4.3.1新增依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-runtime-web_${scala.binary.version}artifactId> <version>${flink.version}version>
dependency>
4.3.2 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
4.3.3 启动日志
4.3.4 访问页面
http://localhost:8081/

五 flink项目模板下载
5.1 java模板
5.1.1 maven命令下载模板
mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-java \ -DarchetypeVersion=1.11.1 \ -DgroupId=com.wedoctor.flink \ -DartifactId=flink-project-java \ -Dversion=1.0 \ -Dpackage=com.wedoctor.flink \-DinteractiveMode=false

5.1.2 curl下载模板
curl https://flink.apache.org/q/quickstart.sh | bash -s 1.11.1
5.2 scala模板
5.2.1 maven命令下载模板
mvn archetype:generate \ -DarchetypeGroupId=org.apache.flink \ -DarchetypeArtifactId=flink-quickstart-scala \ -DarchetypeVersion=1.11.1 \ -DgroupId=com.wedoctor.flink \ -DartifactId=flink-project-scala \ -Dversion=1.0 \ -Dpackage=com.wedoctor.flink \-DinteractiveMode=false
5.2.2 curl下载模板
curl https://flink.apache.org/q/quickstart-scala.sh | bash -s 1.11.1
六 flink入门程序
6.1 编程模型

Flink提供了不同级别的编程抽象,通过调用抽象的数据集调用算子构建DataFlow就可以实现对分布式的数据进行流式计算和离线计算,DataSet是批处理的抽象数据集,DataStream是流式计算的抽象数据集,他们的方法都分别为Source、Transformation、Sink
- Source主要负责数据的读取
- Transformation主要负责对数据的转换操作
- Sink负责最终计算好的结果数据输出。
6.2 DataStream实时wordcount
package com.wedoctor.flink import org.apache.flink.streaming.api.scala._
object WordCountDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val lines: DataStream[String] = env.socketTextStream("192.168.xx.xx",9999)
val words: DataStream[String] = lines.flatMap(_.split(" "))
val wordWithOne: DataStream[(String, Int)] = words.map((_,1))
val keyedData: KeyedStream[(String, Int), String] = wordWithOne.keyBy(_._1)
val sumData: DataStream[(String, Int)] = keyedData.sum(1)
sumData.print()
env.execute("Flink WordCount")
}
}
6.3 DataSet 离线wordcount
package com.wedoctor.flink import org.apache.flink.api.scala._
object WordCountDemo2 {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val words: DataSet[Int] = env.fromElements(1,2,3)
val tt: DataSet[Int] = words.map(t=>t*2)
tt.print()
}
}
七 flink算子
7.1 map
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class MapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<String> words = lines.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
});
words.print();
env.execute();
}
}
7.2 RichMapFunction
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichMapTest {
//RichMapFunction
//1.可以获取运行时上下文,可以得到很多的信息,subTaskIndex、状态数据等
//2.还可以使用两个生命周期方法、open和close
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.XX.XX", 9999);
SingleOutputStreamOperator<String> map = lines.map(new RichMapFunction<String, String>() {
//构造对象完成后,map方法执行之前,执行一次
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//此处可以建立连接
}
@Override
public String map(String value) throws Exception {
//处理数据
return value + "222222222";
}
//subtask在停止之前,执行一次
@Override
public void close() throws Exception {
super.close();
//关闭连接
}
});
map.print();
env.execute();
}
}
7.3 flatMap
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector; public class FlatMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> collector) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
collector.collect(word);
}
}
});
flatMap.print();
env.execute();
}
}
7.4 filter
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class RichMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<String> filter = lines.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.length() == 2;
}
});
filter.print();
env.execute();
}
}
7.5 keyBy
7.5.1 单个字段keyby
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class KeyByDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999); SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
});
//按照单个字段分组 keyby
KeyedStream<Tuple2<String, Integer>, Tuple> keyBy = flatMap.keyBy(0);
KeyedStream<Tuple2<String, Integer>, String> keyBy1 = flatMap.keyBy(t -> t.f0);
keyBy.print();
keyBy1.print();
env.execute();
}
}
7.5.2 多个字段keyBy(过时API)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KeyByDemo {
public static void main(String[] args) throws Exception {
// jack 01 1232
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999); SingleOutputStreamOperator<Tuple3<String, String, Integer>> map = lines.map(new MapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public Tuple3<String, String, Integer> map(String s) throws Exception {
String[] words = s.split(" ");
String userId = words[0];
String monthId = words[1];
Integer orderCnt = Integer.parseInt(words[2]);
return Tuple3.of(userId, monthId, orderCnt);
}
});
KeyedStream<Tuple3<String, String, Integer>, Tuple> key = map.keyBy(0, 1);
SingleOutputStreamOperator<Tuple3<String, String, Integer>> summed = key.sum(2);
summed.print();
env.execute();
}
}
7.5.3 多个字段KeyBy(新API,Tuple封装)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class KeyByDemo {
public static void main(String[] args) throws Exception {
// jack 01 1232
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<Tuple3<String, String, Integer>> map = lines.map(new MapFunction<String, Tuple3<String, String, Integer>>() {
@Override
public Tuple3<String, String, Integer> map(String s) throws Exception {
String[] words = s.split(" ");
String userId = words[0];
String monthId = words[1];
Integer orderCnt = Integer.parseInt(words[2]);
return Tuple3.of(userId, monthId, orderCnt);
}
});
KeyedStream<Tuple3<String, String, Integer>, String> keyBy = map.keyBy(t -> t.f0 + t.f1);
SingleOutputStreamOperator<Tuple3<String, String, Integer>> summed = keyBy.sum(2);
summed.print();
env.execute();
}
}
7.5.4 多个字段KeyBy(POJO封装,终极)
package com.wedoctor.flink;
public class WordCount {
public String word;
public Integer count;
public WordCount(String word, Integer count) {
this.word = word; this.count = count;
}
public WordCount() {
}
public static WordCount of(String word,Integer count){
return new WordCount(word,count); }
@Override
public String toString() {
return "WordCount{" + "word='" + word + '\'' + ", count=" + count + '}';
}
}
package com.wedoctor.flink;
public class WordCount {
public String word;
public Integer count;
public WordCount(String word, Integer count) {
this.word = word;
this.count = count; }
public WordCount() {
}
public static WordCount of(String word,Integer count){
return new WordCount(word,count);
}
@Override
public String toString() {
return "WordCount{" + "word='" + word + '\'' + ", count=" + count + '}';
}
}
7.6 reduce
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class ReduceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
String[] words = s.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1));
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = flatMap.keyBy(t -> t.f0).reduce(new
ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
});
reduce.print();
env.execute();
}
}
7.7 Aggregations
7.7.1 sum
7.7.2 min
7.7.3 max
7.7.4 minBy
7.7.5 maxBy
7.8 union
package com.wedoctor.flink;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class UnionDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//调用Source创建DataStream
DataStreamSource<Integer> s1 = env.fromElements(1, 2, 3, 4, 5);
DataStreamSource<Integer> s2 = env.fromElements(5, 7, 8, 9, 10);
DataStream<Integer> unioned = s1.union(s2);
unioned.print();
env.execute();
}
}
八 Window
streaming流式计算是⼀种被设计用于处理⽆限数据集的数据处理引擎,而⽆限数据集是指一种不断增长的本质上无限数据集,⽽window是一种切割无限数据为有限块进行处理的手段。Window是无限数据流处理的核心,Window将⼀个⽆限stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
8.1 Time(Flink中涉及的时间)
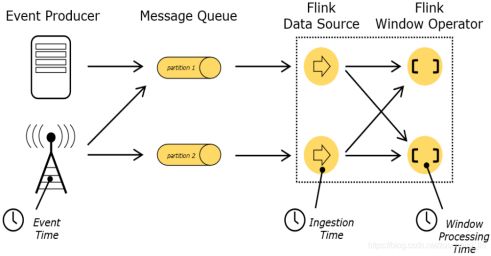
- Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每⼀条⽇志都会记录⾃己的生成时间,Flink通过时间戳分配器访问事件时间戳。
- Ingestion Time:是数据进入Flink的时间。
- Processing Time:是每⼀个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
8.2 window类型
8.2.1 TimeWindow(按照时间生成Window)
TimeWindow是将指定时间范围内的所有数据组成⼀个window,⼀次对一个window⾥面的所有数据进行计算。
8.2.1.1 滚动窗口
Flink默认的时间窗⼝根据Processing Time 进⾏窗⼝的划分,将Flink获取到的数据根据进入Flink的时间划分到不同的窗口中。
将数据依据固定的窗⼝⻓度对数据进行切片。
特点:时间对⻬,窗口⻓度固定,没有重叠。
滚动窗⼝分配器将每个元素分配到⼀个指定窗⼝⼤小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个5分钟大小的滚动窗口,如下图所示:
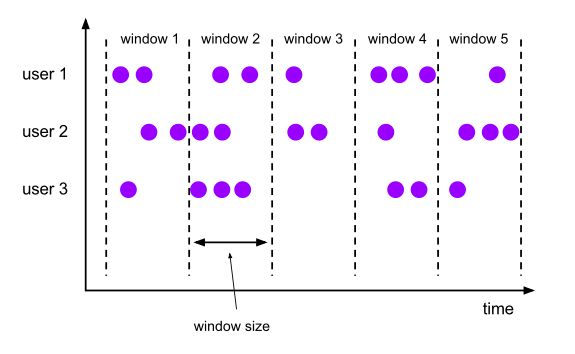
适用场景:适合做BI统计等(做每个时间段的聚合计算)。
8.2.1.1.1 timeWindowAll(全局数据,默认Processing Time)
package com.wedoctor.flink;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class TumblingTimeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//默认的CountWindow是⼀个滚动窗⼝,只需要指定窗⼝⼤小即可,当元素数量达到窗口⼤小时,就会触发窗⼝的执⾏。
SingleOutputStreamOperator<Integer> num = lines.map(Integer::parseInt);
//划分窗口
AllWindowedStream<Integer, TimeWindow> timeWindowAll = num.timeWindowAll(Time.seconds(5));
//对窗口数据进行计算
SingleOutputStreamOperator<Integer> sum = timeWindowAll.sum(0);
sum.print();
env.execute();
}
}
8.2.1.1.2 timeWindow(窗口滚动的时候,所有组都要执行,并行处理,默认Processing Time)
package com.wedoctor.flink;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class TumblingTimeWindow2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//默认的CountWindow是⼀个滚动窗⼝,只需要指定窗⼝⼤小即可,当元素数量达到窗口⼤小时,就会触发窗⼝的执⾏。
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = lines.map(line -> {
String[] fileds = line.split(",");
return Tuple2.of(fileds[0], Integer.parseInt(fileds[1]));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndCount.keyBy(t -> t.f0);
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> timeWindow = keyedStream.timeWindow(Time.seconds(5));
timeWindow.sum(1)
.print();
env.execute();
}
}
8.2.1.1.3 timeWindowAll(全局数据,使用Event Time)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import java.text.ParseException;
import java.text.SimpleDateFormat;
public class EventTimeTumbingWindwAllDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//创建一个DataStream //2020-11-08 18:22:43,1
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//提取数据中的时间
SingleOutputStreamOperator<String> watermarksDataStream = lines.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Override
public long extractTimestamp(String element) {
long timestamp = 0;
try {
timestamp = sdf.parse(element.split(",")[0]).getTime();
} catch (ParseException e) {
timestamp = System.currentTimeMillis();
} return timestamp;
}
});
SingleOutputStreamOperator<Integer> nums = watermarksDataStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return Integer.parseInt(value.split(",")[1]);
}
});
AllWindowedStream<Integer, TimeWindow> windowed = nums.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
SingleOutputStreamOperator<Integer> summed = windowed.sum(0);
summed.print();
env.execute();
}
}
8.2.1.1.4 timeWindow(分组数据,使用Event Time)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class EventTimeTumblingWindowDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1000,hadoop,1
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<String> watermarksDataStream = lines.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
@Override
public long extractTimestamp(String element) {
return Long.parseLong(element.split(",")[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = watermarksDataStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] fileds = value.split(",");
String word = fileds[1];
int count = Integer.parseInt(fileds[2]);
return Tuple2.of(word, count);
}
});
//先分组
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndCount.keyBy(t -> t.f0);
//划分窗口
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window =
keyed.window(TumblingEventTimeWindows.of(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = window.sum(1);
summed.print();
env.execute();
}
}
8.2.1.2 滑动窗口
滑动窗⼝是固定窗口的更⼴义的⼀种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,有重叠
该滑动窗口分配器分配元件以固定长度的窗口。与翻滚窗口分配器类似,窗口大小由窗口大小参数配置。附加的窗口滑动参数控制滑动窗口的启动频率。因此,如果幻灯片小于窗口大小,则滑动窗口可以重叠。在这种情况下,元素被分配给多个窗口。
例如,您可以将大小为10分钟的窗口滑动5分钟。有了这个,你每隔5分钟就会得到一个窗口,其中包含过去10分钟内到达的事件,如下图所示。

适⽤场景:对最近⼀个时间段内的统计(求某接口最近5min的失败率来决定是否要报警)。
8.2.1.2.1 全局滑动(默认Processing Time)
package com.wedoctor.flink;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class TumblingTimeWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999); //默认的CountWindow是⼀个滚动窗⼝,只需要指定窗⼝⼤小即可,当元素数量达到窗口⼤小时,就会触发窗⼝的执⾏。
SingleOutputStreamOperator<Integer> num = lines.map(Integer::parseInt);
//划分滑动窗口
AllWindowedStream<Integer, TimeWindow> timeWindowAll = num.timeWindowAll(Time.seconds(10),Time.seconds(5));
//对窗口数据进行计算
SingleOutputStreamOperator<Integer> sum = timeWindowAll.sum(0);
sum.print();
env.execute();
}
}
8.2.1.2.2 分组滑动(默认Processing Time)
package com.wedoctor.flink;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class TumblingTimeWindow2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//默认的CountWindow是⼀个滚动窗⼝,只需要指定窗⼝⼤小即可,当元素数量达到窗口⼤小时,就会触发窗⼝的执⾏。
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = lines.map(line -> {
String[] fileds = line.split(",");
return Tuple2.of(fileds[0], Integer.parseInt(fileds[1]));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndCount.keyBy(t -> t.f0);
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> timeWindow = keyedStream.timeWindow(Time.seconds(10),Time.seconds(5));
timeWindow.sum(1).print();
env.execute();
}
}
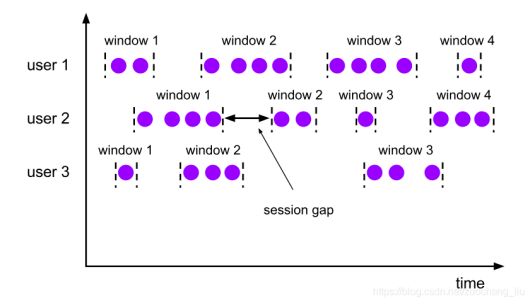
8.2.1.3 会话窗口
由⼀系列事件组合⼀个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间⽆对⻬。
在会话窗口中按活动会话分配器组中的元素。会话窗口不重叠,没有固定的开始和结束时间,与翻滚窗口和滑动窗口相反。相反,当会话窗口在一段时间内没有接收到元素时,即当发生不活动的间隙时,会关闭会话窗口。会话窗口分配器可以配置静态会话间隙或 会话间隙提取器功能,该功能定义不活动时间段的长度。当此期限到期时,当前会话将关闭,后续元素将分配给新的会话窗口。
8.2.1.3.1 不分组(默认Processing Time)
package com.wedoctor.flink;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class ProcessingTimeSessionWindowAllDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<Integer> nums = lines.map(Integer::parseInt);
//不分组,划分会话窗口
AllWindowedStream<Integer, TimeWindow> windowed =
nums.windowAll(ProcessingTimeSessionWindows.withGap(Time.seconds(5)));
//划分完窗口要调用WindowFunction对窗口内的数据进行计算
SingleOutputStreamOperator<Integer> summed = windowed.sum(0);
summed.print();
env.execute();
}
}
8.2.1.3.2 分组(单个组出发,不是全部触发,默认Processing Time)
package com.wedoctor.flink;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class ProcessingTimeSessionWindwDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//spark,3 //hadoop,2 //flink,1
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = lines.map(line -> {
String[] fields = line.split(",");
return Tuple2.of(fields[0], Integer.parseInt(fields[1]));
}).returns(Types.TUPLE(Types.STRING, Types.INT));
//先分组
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndCount.keyBy(t -> t.f0);
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowed =
keyed.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = windowed.sum(1);
summed.print();
env.execute();
}
}
8.2.1.3.3 不分组(使用Event time)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class EventTimeSessionWindowAllDemo {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1000,1
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//提取数据中的时间
SingleOutputStreamOperator<String> watermarksDataStream = lines.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
@Override
public long extractTimestamp(String element) {
return Long.parseLong(element.split(",")[0]);
}
});
SingleOutputStreamOperator<Integer> nums = watermarksDataStream.map(new MapFunction<String, Integer>() {
@Override
public Integer map(String value) throws Exception {
return Integer.parseInt(value.split(",")[1]);
}
});
//不分组划分窗口
AllWindowedStream<Integer, TimeWindow> windowed =
nums.windowAll(EventTimeSessionWindows.withGap(Time.seconds(5)));
windowed.sum(0).print();
env.execute();
}
}
8.2.1.3.4分组(使用Event time)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class EventTimeSessionWindowDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1000,spark,1
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
SingleOutputStreamOperator<String> watermarksDataStream = lines.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(0)) {
@Override
public long extractTimestamp(String element) {
return Long.parseLong(element.split(",")[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = watermarksDataStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] fileds = value.split(",");
String word = fileds[1];
int count = Integer.parseInt(fileds[2]);
return Tuple2.of(word, count);
}
});
//先分组
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndCount.keyBy(t -> t.f0);
//划分窗口
keyed.timeWindow(Time.seconds(5));
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window =
keyed.window(EventTimeSessionWindows.withGap(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = window.sum(1);
summed.print();
env.execute();
}
}
8.2.2 GlobalWindow(CountWindow)
按照指定的数据条数生成⼀个Window,与时间无关
8.2.2.1 countWindowAll
全部数据发送到一个task里面 并不是分布式执行
package com.wedoctor.flink;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
public class CountWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//默认的CountWindow是⼀个滚动窗⼝,只需要指定窗⼝⼤小即可,当元素数量达到窗口⼤小时,就会触发窗⼝的执⾏。
SingleOutputStreamOperator<Integer> num = lines.map(Integer::parseInt);
//划分窗口
AllWindowedStream<Integer, GlobalWindow> windowd = num.countWindowAll(5);
//对窗口数据进行计算
SingleOutputStreamOperator<Integer> sum = windowd.sum(0);
sum.print();
env.execute();
}
}
8.2.2.2 countWindow
分组满足触发条件即可,并不是触发后每个分区都会执行
package com.wedoctor.flink;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
public class CountWindow2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> lines = env.socketTextStream("192.168.xx.xx", 9999);
//默认的CountWindow是⼀个滚动窗⼝,只需要指定窗⼝⼤小即可,当元素数量达到窗口⼤小时,就会触发窗⼝的执⾏。
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = lines.map(line -> {
String[] fileds = line.split(",");
return Tuple2.of(fileds[0], Integer.parseInt(fileds[1]));
}).returns(Types.TUPLE(Types.STRING,Types.INT));
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordAndCount.keyBy(t -> t.f0);
WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> countWindow =
keyedStream.countWindow(5);
countWindow.sum(1).print();
env.execute();
}
}
九 watermark
9.1 基本概念
Flink中可以让window延迟触发的一种机制
我们知道,流处理从事件产⽣,到流经source,再到operator,中间是有⼀个过程和时间的,虽然⼤部分情况下,流到operato的数据都是按照事件产⽣的时间顺序来的,但是也不排除由于⽹络、背压等原因,导致乱序的产⽣,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
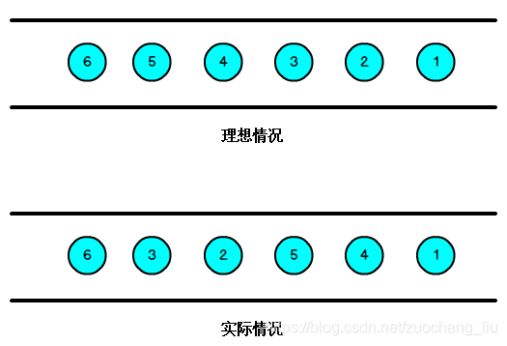
那么此时出现⼀个问题,⼀旦出现乱序,如果只根据eventTime决定window的运⾏,我们不能明确数据是否全部到位,但⼜不能⽆限期的等下去,此时必须要有个机制来保证⼀个特定的时间后,必须触发window去进⾏计算了,这个特别的机制,就是Watermark。Watermark是⼀种衡量Event Time进展的机制,它是数据本身的⼀个隐藏属性,数据本身携带着对应Watermark。
Watermark是⽤于处理乱序事件的,⽽正确的处理乱序事件,通常⽤Watermark机制结合window来实现。数据流中的Watermark⽤于表示timestamp⼩于Watermark的数据,都已经到达了,因此,window的执⾏也是由Watermark触发的。
Watermark可以理解成⼀个延迟触发机制,我们可以设置Watermark的延时时⻓t,每次系统会校验已经到达的数据中最⼤的maxEventTime,然后认定eventTime⼩于maxEventTime- t的所有数据都已经到达,如果有窗⼝的停⽌时间等于maxEventTime – t,那么这个窗⼝被触发执⾏。
有序流的Watermarker如下图所示:(Watermark设置为0)

乱序流的Watermarker如下图所示:(Watermark设置为2)

当Flink接收到每一条数据时,都会产⽣一条Watermark,这条Watermark就等于当前所有到达数据中的maxEventTime - 延迟时⻓长,也就是说,Watermark是由数据携带的,一旦数据携带的Watermark比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于Watermark是由数据携带的,因此,如果运行过程中⽆法获取新的数据,那么没有被触发的窗口将永远都不不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是1s5s,窗口2是6s10s,那么时间戳为7s的事件到达时的Watermarker恰好触发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
9.2 引入watermark
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调⽤时刻开始给env创建的每⼀个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = env.readTextFile("eventTest.txt")
.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[String](Time.milliseconds(200)) {
override def extractTimestamp(t: String): Long = {
// EventTime是⽇志⽣成时间,我们从⽇志中解析
EventTime t.split(" ")(0).toLong
}
})
9.3生成watermark的两种方式
定义了抽取时间戳,以及生成 watermark 的方法,有两种类型
- AssignerWithPeriodicWatermarks
- 周期性的生成 watermark:系统会周期性的将 watermark 插入到流中默认周期是200毫秒,可以使用
ExecutionConfig.setAutoWatermarkInterval()方法进行设置。升序和前面乱序的处理 BoundedOutOfOrderness ,都是基于周期性watermark 的。 - AssignerWithPunctuatedWatermarks
- 没有时间周期规律,可打断的生成 watermark
9.4 EventTimeWindow API
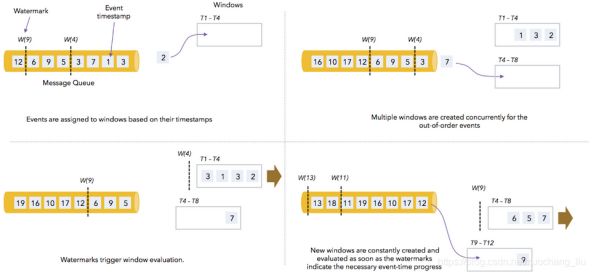
当使⽤EventTimeWindow时,所有的Window在EventTime的时间轴上进⾏划分,也就是说,在Window启动后,会根据初始的EventTime时间每隔⼀段时间划分⼀个窗⼝,如果Window⼤⼩是3秒,那么1分钟内会把Window划分为如下的形式:
[00:00:00,00:00:03)
[00:00:03,00:00:06)
...
[00:00:57,00:01:00)
如果Window⼤⼩是10秒,则Window会被分为如下的形式:
[00:00:00,00:00:10)
[00:00:10,00:00:20)
...
[00:00:50,00:01:00)
注意,窗⼝是左闭右开的,形式为:[window_start_time,window_end_time)。
Window的设定⽆关数据本身,⽽是系统定义好了的,也就是说,Window会⼀直按照指定的时间间隔进⾏划分,不论这个Window中有没有数据,EventTime在这个Window期间的数据会进⼊这个Window。
Window会不断产⽣,属于这个Window范围的数据会被不断加⼊到Window中,所有未被触发的Window都会等待触发,只要Window还没触发,属于这个Window范围的数据就会⼀直被加⼊到Window中,直到Window被触发才会停⽌数据的追加,⽽当Window触发之后才接受到的属于被触发Window的数据会被丢弃。
Window会在以下的条件满⾜时被触发执⾏:
l watermark时间 >= window_end_time;
l 在[window_start_time,window_end_time)中有数据存在。
我们通过下图来说明Watermark、EventTime和Window的关系。
9.4.1 滚动窗口(TumblingEventTimeWindows)
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
;public class WaterMarkDemo1 { public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1000,spark,1
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//直接对Source提取EventTime
SingleOutputStreamOperator<String> watermarksDataStream = lines.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
@Override
public long extractTimestamp(String element) {
//当前分区中数据中最大的EventTime - 延迟时间 = 该分区的WaterMark
return Long.parseLong(element.split(",")[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = watermarksDataStream.map(
new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] fileds = value.split(",");
String word = fileds[1];
int count = Integer.parseInt(fileds[2]);
return Tuple2.of(word, count);
}
});
//先分组
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndCount.keyBy(t -> t.f0);
//划分窗口 //keyed.timeWindow(Time.seconds(5));
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window =
keyed.window(TumblingEventTimeWindows.of(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = window.sum(1);
summed.print();
env.execute();
}
}
结果是按照Event Time的时间窗⼝计算得出的,⽽⽆关系统的时间(包括输⼊的快慢)。
9.4.2 滑动窗⼝(SlidingEventTimeWindows)
// 获取执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironmentenv
.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 创建
SocketSourceval stream = env.socketTextStream("localhost", 11111)
// 对stream进⾏处理并按key聚合
val streamKeyBy = stream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[String](Time.milliseconds(0)) {
override def extractTimestamp(element: String): Long = {
val sysTime = element.split(" ")(0).toLong
println(sysTime)
sysTime
}
}).map(item => (item.split(" ")(1), 1)).keyBy(0)
// 引⼊滚动窗⼝
val streamWindow = streamKeyBy.window(SlidingEventTimeWindows.of(Time.seconds(10),Time.seconds(5)))
// 执⾏聚合操作
val streamReduce = streamWindow.reduce( (a,b) => (a._1, a._2 + b._2))
// 将聚合数据写⼊⽂件
streamReduce.print
// 执⾏程序
env.execute("TumblingWindow")
9.4.3 会话窗⼝(EventTimeSessionWindows)
相邻两次数据的EventTime的时间差超过指定的时间间隔就会触发执⾏。如果加⼊Watermark,那么当触发执⾏时,所有满⾜时间间隔⽽还没有触发的Window会同时触发执⾏。
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
public class WaterMarkDemo3 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置EventTime作为时间标准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1000,spark,1
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//直接对Source提取EventTime
SingleOutputStreamOperator<String> watermarksDataStream = lines.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
@Override
public long extractTimestamp(String element) {
//当前分区中数据中最大的EventTime - 延迟时间 = 该分区的WaterMark
return Long.parseLong(element.split(",")[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndCount = watermarksDataStream.map(
new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] fileds = value.split(",");
String word = fileds[1];
int count = Integer.parseInt(fileds[2]);
return Tuple2.of(word, count);
}
});
//先分组
KeyedStream<Tuple2<String, Integer>, String> keyed = wordAndCount.keyBy(t -> t.f0);
//分组后划分EventTime的SessionWindow
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowed =
keyed.window(EventTimeSessionWindows.withGap(Time.seconds(5)));
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = windowed.sum(1);
summed.print();
env.execute();
}
}
十 flink 原理解读
10.1 Task和subtask
10.1.1 概念
- Task(任务):Task 是一个阶段多个功能相同 subTask 的集合,类似于 Spark 中的 TaskSet。
- subTask(子任务):subTask 是 Flink 中任务最小执行单元,是一个 Java 类的实例,这个 Java 类中有属性和方法,完成具体的计算逻辑。
- Operator Chains(算子链):没有 shuffle 的多个算子合并在一个 subTask 中,就形成了 Operator Chains,类似于 Spark 中的 Pipeline。
- Slot(插槽):Flink 中计算资源进行隔离的单元,一个 Slot 中可以运行多个 subTask,但是这些 subTask 必须是来自同一个 application 的不同阶段的 subTask。
10.1.2 如何划分task
Task的并行度发生变化
调用Keyby这样产生shuffle的算子
调用startNewChain
调用disableChaining
处理分区器 Rebalance Shuffle Broadcast Rescale

10.1.3 区别

上图并行数据流,一共有 3个 Task,5个 subTask。(红框代表Task,黑框代表subTask)
10.2 startNewChain的使用
Forward no shuffle
Begin a new chain, starting with this operator. The two mappers will be chained, and filter will not be chained to the first
mapper.someStream.filter(...).map(...).startNewChain().map(...);
10.3 disableChain的使用
将该算子前面和后面的链都断开
Do not chain the map operatorsomeStream.map(...).disableChaining();
10.4 共享资源槽
- Flink的任务资源草默认名称是default
- 可以通过调用slotSharingGroup方法指定槽位的名称
- 如果改变共享槽位的名称后,后面的没有再设置共享槽位的名称,那么跟上一次改变槽位的名称一致
- 槽位名称不同的subtask不能在一个槽位中执行
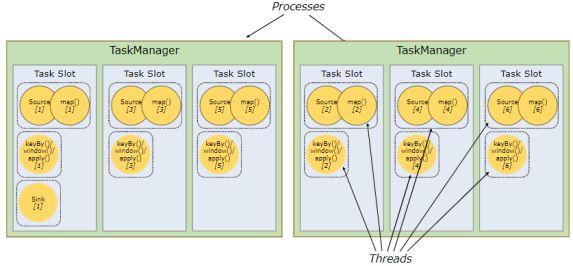
每个工作程序(TaskManager)是一个JVM进程,并且可以在单独的线程中执行一个或多个子任务。为了控制一个worker接受多少个任务,一个worker有一个所谓的任务槽(至少一个)。
每个任务槽代表TaskManager的资源的固定子集。例如,具有三个插槽的TaskManager会将其托管内存的1/3专用于每个插槽。分配资源意味着子任务不会与其他作业的子任务竞争托管内存,而是具有一定数量的保留托管内存。请注意,此处没有发生CPU隔离。当前插槽仅将任务的托管内存分开。
通过调整任务槽的数量,用户可以定义子任务如何相互隔离。每个TaskManager具有一个插槽,意味着每个任务组都在单独的JVM中运行(例如,可以在单独的容器中启动)。具有多个插槽意味着更多子任务共享同一JVM。同一JVM中的任务共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。

默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一作业即可。结果是一个插槽可以容纳整个作业流水线。允许此插槽共享有两个主要好处:
- Flink集群所需的任务槽数与作业中使用的最高并行度恰好一样。无需计算一个程序总共包含多少个任务(并行度各不相同)。
- 更容易获得更好的资源利用率。如果没有插槽共享,则非密集型 source / map()子任务将阻塞与资源密集型窗口子任务一样多的资源。通过插槽共享,我们示例中的基本并行度从2增加到6,可以充分利用插槽资源,同时确保沉重的子任务在TaskManager之间公平分配。
10.5 任务重启策略
Flink开启checkpoint功能,同时就开启了重启策略,默认是不停重启
如果不开启checkpoint功能,也是可以配置重启策略的(不能容错)
Flink的重启策略可以配置成启动固定次数且每次延迟指定时间启动
Flink出现异常后,会根据配置的重启策略重新启动,将原来的subtask释放,重新生成subtask并调度到taskmanage的slot中运行
Flink任务重启后,重新生成的subtask被调度到taskmanage中,会从stagebackend中恢复上一次checkpoint的状态
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, 30000));
10.6 chekpoint
10.6.1 定义
Flink的 Checkpoint 默认是关闭的,当Flink程序的checkpoint被激活时,状态会被持久化到checkpoint,以防止数据丢失和无缝恢复。状态在内部如何组织和它们如何以及在哪持久化,依赖于所选的状态后端。
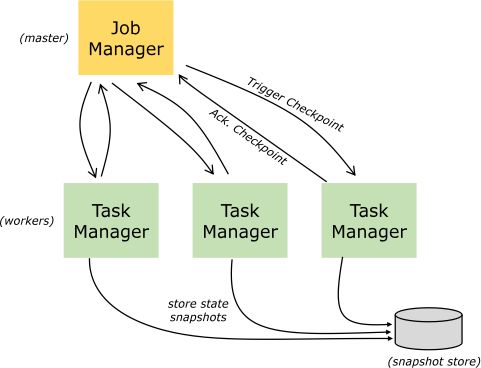
Flink默认状态是存储在 JM(JobManager)的 JVM内存中,当然也可以存储在远程文件系统如HDFS,只有将状态的快照持久化的保存起来,才能提供有利的保证,否则存储在 JM 的内存中,JM挂了之后状态就丢失了。
Fkink实时计算为了容错,可以将中间数据定期保存起来,这种定期出发保存中间结果的机制叫checkpointing,它是周期性执行的,具体的过程是JobManager定期的向TaskManager中的SubTask发送RPC消息,subTask将其计算的state保存到stateBackEnd中,并且向JobManager响应checkpointing是否成功,如果程序出现异常或重启,TaskManager中饭的SubTask可以从上一次成功的checkPointing的state恢复
10.6.2 配置checkpoint
StreamExecutionEnvironment env
=StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(10000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2 个 Checkpoint 之间最少是要等 500ms,也就是刚做完一个 Checkpoint。比如某个 Checkpoint 做了700ms,按照原则过 300ms 应该是做下一个 Checkpoint,因为设置了 1000ms 做一次 Checkpoint 的,但是中间的等待时间比较短,不足 500ms 了,需要多等 200ms,因此以这样的方式防止 Checkpoint 太过于频繁而导致业务处理的速度下降。
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
env.getCheckpointConfig().setCheckpointTimeout(6000);
//程序异常退出或人为cancel掉,不删除checkpoint数据(默认是会删除)
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//设置存储位置覆盖默认方式
env.setStateBackend(new FsStateBackend(args[0]));
10.7 Barrier
Flink的容错机制主要是通过持续产生快照的方式实现的,对应的快照机制的实现主要由2部分组成,一个是屏障(Barrier),另一个是状态(state)
对齐机制
流屏障(barrier)是Flink分布式快照中的核心元素。这些屏障将注入到数据流中,并与记录一起作为数据流的一部分流动。壁垒从不超越记录,它们严格按照顺序进行。屏障将数据流中的记录分为进入当前快照的记录集和进入下一个快照的记录集。每个屏障都带有快照的ID,快照的记录已推送到快照的前面。屏障不会中断流的流动,因此非常轻便。来自不同快照的多个障碍可以同时出现在流中,这意味着各种快照可能会同时发生。

流屏障在流源处注入并行数据流中。快照n的屏障被注入的点(我们称其为 S n)是快照中覆盖数据的源流中的位置。例如,在Apache Kafka中,此位置将是分区中最后一条记录的偏移量。该位置S n 被报告给检查点协调器(Flink的JobManager)。
然后,屏障向下游流动。当中间操作员从其所有输入流中收到快照n的屏障时,它会将快照n的屏障发射到其所有输出流中。接收器运算符(流式DAG的末尾)从其所有输入流接收到屏障n后,便将快照n确认给检查点协调器。所有接收器都确认快照后,就认为快照已完成。
一旦完成快照n,该作业将不再向源请求S n之前的记录,因为此时这些记录(及其后代记录)将通过整个数据流拓扑。
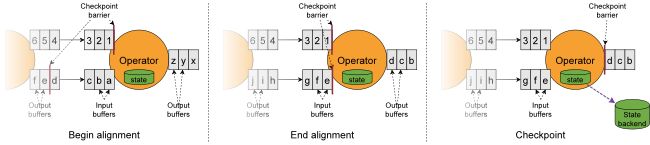
接收多个输入流的操作员需要在快照屏障上对齐输入流。上图说明了这一点:
1.操作员一旦从传入流接收到快照屏障n,就无法处理该流中的任何其他记录,直到它也从其他输入接收到屏障n为止。否则,它将混合属于快照n的记录和属于快照n + 1的记录。
2.一旦最后一个流接收到屏障n,操作员将发出所有未决的传出记录,然后自身发出快照n屏障。
3.它快照状态并恢复所有输入流中的记录处理,在处理来自流中的记录之前,先处理输入缓冲区中的记录。
4.最后,操作员将状态异步写入状态后端。
请注意,所有具有多个输入的运算符以及经过洗牌后的运算符使用多个上游子任务的输出流时,都需要对齐。
10.8 state
10.8.1 概念
State是flink计算过程的中间结果和状态信息,为了容错,必须把状态持久化到一个外部的系统中
State可以是多种类型的,默认是保存在jobManage的内存中,也可以保存到taskmanage本地文件系统或者HDFS这样的分布式文件系统中
10.8.2 分类
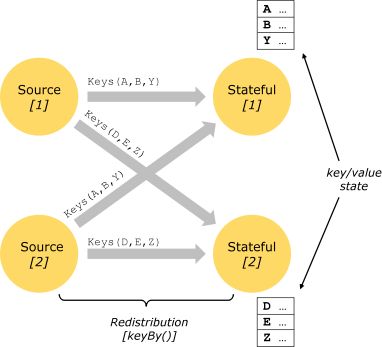
- Keystate
调用keyby方法后,每个分区中相互独立的state
- Operatorstate
没有分组,每一个subtask自己维护一个状态
与Keyed State不同,Operator State跟一个特定operator的一个并发实例绑定,整个operator只对应一个state。相比较而言,在一个operator上,可能会有很多个key,从而对应多个keyed state。而且operator state可以应用于非keyed stream中。
举例来说,Flink中的Kafka Connector,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射。
- Broadcast state
广播state,一个可以通过connect方法获取广播流的数据,广播流的特点是可以动态更新
广播state通常作为字典数据,维度数据关联,广播到属于该任务的所有taskmanager的每个taskslot中,类似于map
10.8.3 应用
1.先定义一个状态描述器
//广播数据的状态描述器 MapStateDescriptor
2.通过context获取state
3.对数据处理后要更新数据
10.8.4 operator state和keyed state的一致性
参考10.7 Barrier
10.9 stateBackEnd
用来保存state的存储后端就叫做stateBackEnd,默认是保存在JobManager的内存中,也可以保存在本地文件系统或者HDFS这样的分布式文件系统
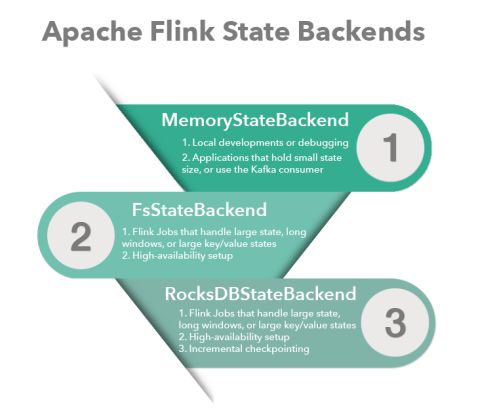
在没有配置的情况下,系统默认使用 MemoryStateBackend。
尽管有checkpoint保证exactly-once,但对于实时性要求高的业务场景,每次重启所消耗的时间都可能会导致业务不可用。也许你也经常遇到这样的情况,checkpoint又失败了?连续失败?task manager 内存爆了?这些情况都很容易导致Flink任务down了,这时候需要思考下你所处的业务场景下,选用的Flink State Backends是否合理?
10.9.1 MemoryStateBackend
Checkpoint 的存储,第一种是内存存储,即 MemoryStateBackend,构造方法是设置最大的StateSize,选择是否做异步快照,这种存储状态本身存储在 TaskManager 节点也就是执行节点内存中的,因为内存有容量限制,所以单个 State maxStateSize 默认5M,且需要注意 maxStateSize <= akka.framesize 默认 10 M。Checkpoint 存储在 JobManager 内存中,因此总大小不超过 JobManager 的内存。推荐使用的场景为:本地测试、几乎无状态的作业,比如 ETL、JobManager 不容易挂,或挂掉影响不大的情况。不推荐在生产场景使用。
10.9.2 FsStateBackend
存储在文件系统上的 FsStateBackend ,构建方法是需要传一个文件路径和是否异步快照。State 依然在 TaskManager 内存中,但不会像 MemoryStateBackend 有 5 M 的设置上限,Checkpoint 存储在外部文件系统(本地或 HDFS),打破了总大小 Jobmanager 内存的限制。容量限制上,单 TaskManager 上 State 总量不超过它的内存,总大小不超过配置的文件系统容量。推荐使用的场景、常规使用状态的作业、例如分钟级窗口聚合或 join、需要开启HA的作业。
10.9.4 RocksDBStateBackend
存储为 RocksDBStateBackend ,RocksDB 是一个 key/value 的内存存储系统,和其他的 key/value 一样,先将状态放到内存中,如果内存快满时,则写入到磁盘中,但需要注意 RocksDB 不支持同步的 Checkpoint,构造方法中没有同步快照这个选项。不过 RocksDB 支持增量的 Checkpoint,也是目前唯一增量 Checkpoint 的 Backend,意味着并不需要把所有 sst 文件上传到 Checkpoint 目录,仅需要上传新生成的 sst 文件即可。它的 Checkpoint 存储在外部文件系统(本地或HDFS),其容量限制只要单个 TaskManager 上 State 总量不超过它的内存+磁盘,单 Key最大 2G,总大小不超过配置的文件系统容量即可。推荐使用的场景为:超大状态的作业,例如天级窗口聚合、需要开启 HA 的作业、最好是对状态读写性能要求不高的作业。
10.10 flink如何保证ExactlyOnce的
使用执行exactly-once的数据源,如kafka
开启checkpoint,并且设置checkpointingMode.EXACTLY_ONCE,不让消费者自动提交偏移量
存储系统支持覆盖(redis,Hbase,ES),使用其幂等性,将原来的数据覆盖
Barrier(隔离带)可以保证一个流水线中的所有算子都处理完成了在对该条数据做checkpoint
存储系统支持事务
Jobmanager定时出发checkpoint的定时器(checkpointCodination)给有状态的subtask做checkpoint
Checkpoint成功后,将数据写入statebackend中
写成功后向jobmanager发送ack应答
Jobmanager接收到所有subtask的响应后,jobmanager向所有实现了checkpointListener的subtask发送notifycompleted方法成功的消息
把数据写入kafka,提交事务,即使提交事务失败,也没关系,会重启从checnkpoint恢复再写
10.11 flink背压机制
Flink 在运行时主要由 operators 和 streams 两大组件构成。每个 operator 会消费中间态的流,并在流上进行转换,然后生成新的流。对于 Flink 的网络机制一种形象的类比是,Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。还记得经典的线程间通信案例:生产者消费者模型吗?使用 BlockingQueue 的话,一个较慢的接受者会降低发送者的发送速率,因为一旦队列满了(有界队列)发送者会被阻塞。Flink 解决反压的方案就是这种感觉。
在 Flink 中,这些分布式阻塞队列就是这些逻辑流,而队列容量是通过缓冲池(LocalBufferPool)来实现的。每个被生产和被消费的流都会被分配一个缓冲池。缓冲池管理着一组缓冲(Buffer),缓冲在被消费后可以被回收循环利用。这很好理解:你从池子中拿走一个缓冲,填上数据,在数据消费完之后,又把缓冲还给池子,之后你可以再次使用它。
10.12 两段提交原理
10.12.1 原理
Jobmanager定时出发checkpoint的定时器(checkpointCodination)给有状态的subtask做checkpoint;Checkpoint成功后,将数据写入statebackend中;写成功后向jobmanager发送ack应答;Jobmanager接收到所有subtask的响应后,jobmanager向所有实现了checkpointListener的subtask发送notifycompleted方法成功的消息.
把数据写入kafka,提交事务,即使提交事务失败,也没关系,会重启再写.
10.12.2 mysql分两段提交代码实现
package com.wedoctor.flink;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
public class DruidConnectionPool {
private transient static DataSource dataSource = null;
private transient static Properties props = new Properties();
static {
props.put("driverClassName", "com.mysql.jdbc.Driver");
props.put("url", "jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8");
props.put("username", "root");
props.put("password", "123456");
try {
dataSource = DruidDataSourceFactory.createDataSource(props);
} catch (Exception e) {
e.printStackTrace();
}
}
private DruidConnectionPool() { }
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
}
package com.wedoctor.flink;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.typeutils.base.VoidSerializer;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer;
import org.apache.flink.streaming.api.functions.sink.TwoPhaseCommitSinkFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class MySqlTwoPhaseCommitSink extends TwoPhaseCommitSinkFunction<Tuple2<String, Integer>, MySqlTwoPhaseCommitSink.ConnectionState, Void> {
public MySqlTwoPhaseCommitSink() {
super(new KryoSerializer<>(MySqlTwoPhaseCommitSink.ConnectionState.class, new ExecutionConfig()), VoidSerializer.INSTANCE);
}
@Override
protected MySqlTwoPhaseCommitSink.ConnectionState beginTransaction() throws Exception {
System.out.println("=====> beginTransaction... ");
Connection connection = DruidConnectionPool.getConnection();
connection.setAutoCommit(false);
return new ConnectionState(connection);
}
@Override
protected void invoke(MySqlTwoPhaseCommitSink.ConnectionState connectionState, Tuple2<String, Integer> value, Context context) throws Exception {
Connection connection = connectionState.connection;
PreparedStatement pstm = connection.prepareStatement("INSERT INTO t_wordcount (word, counts) VALUES (?, ?) ON DUPLICATE KEY UPDATE counts = ?");
pstm.setString(1, value.f0);
pstm.setInt(2, value.f1);
pstm.setInt(3, value.f1);
pstm.executeUpdate();
pstm.close();
}
@Override
protected void preCommit(MySqlTwoPhaseCommitSink.ConnectionState connectionState) throws Exception {
System.out.println("=====> preCommit... " + connectionState);
}
@Override protected void commit(MySqlTwoPhaseCommitSink.ConnectionState connectionState) {
System.out.println("=====> commit... ");
Connection connection = connectionState.connection;
try {
connection.commit();
connection.close();
} catch (SQLException e) {
throw new RuntimeException("提交事物异常");
}
}
@Override
protected void abort(MySqlTwoPhaseCommitSink.ConnectionState connectionState) {
System.out.println("=====> abort... ");
Connection connection = connectionState.connection;
try {
connection.rollback();
connection.close();
} catch (SQLException e) {
throw new RuntimeException("回滚事物异常");
}
}
static class ConnectionState {
private final transient Connection connection;
ConnectionState(Connection connection) {
this.connection = connection;
}
}
}
十一 flink整合kafka
11.1 kafka–>flink–>redis
11.1.1 增加依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_2.11artifactId>
<version>1.10.0version>
dependency>
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.1-SNAPSHOTversion>
dependency>
11.1.2 代码实现
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class KafkaSourceToRedis {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//本地环境读取hdfs需要设置,集群上不需要
System.setProperty("HADOOP_USER_NAME","root");
//默认情况下,检查点被禁用。要启用检查点
env.enableCheckpointing(30000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//程序异常退出或人为cancel掉,不删除checkpoint数据(默认是会删除)
env.getCheckpointConfig()
.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setStateBackend(new FsStateBackend(args[0]));
//设置重启策略 默认不停重启
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, 30000));
Properties properties = new Properties();
properties.setProperty("bootstrap.servers",
"com.wedoctor:9092,com.wedoctor:9092,com.wedoctor:9092");
properties.setProperty("group.id", args[1]);
properties.setProperty("auto.offset.reset", "earliest");
//properties.setProperty("enable.auto.commit", "false");
//如果没有开启checkpoint功能,为了不重复读取数据,FlinkKafkaConsumer会将偏移量保存到了Kafka特殊的topic中(__consumer_offsets)
//这种方式没法实现Exactly-Once
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<String>(args[2], new
SimpleStringSchema(), properties); //在Checkpoint的时候将Kafka的偏移量保存到Kafka特殊的Topic中,默认是true
flinkKafkaConsumer.setCommitOffsetsOnCheckpoints(false);
DataStreamSource<String> lines = env.addSource(flinkKafkaConsumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(
new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyed.sum(1);
//Transformation 结束
//调用RedisSink将计算好的结果保存到Redis中
//创建Jedis连接的配置信息
FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder()
.setHost(args[3])
.setPassword(args[4])
.build();
summed.addSink(new RedisSink<>(conf, new RedisWordCountMapper()));
env.execute("KafkaSourceDemo");
}
public static class RedisWordCountMapper implements RedisMapper<Tuple2<String, Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
//指定写入Redis中的方法和最外面的大key的名称
return new RedisCommandDescription(RedisCommand.HSET, "wc");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> data) {
return data.f0;
//将数据中的哪个字段作为key写入
}
@Override
public String getValueFromData(Tuple2<String, Integer> data) {
return data.f1.toString();
//将数据中的哪个字段作为value写入
}
}
}
11.1.3 自定义RedisSink
package com.wedoctor.flink;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import redis.clients.jedis.Jedis;
public class MyRedisSink extends RichSinkFunction<Tuple3<String,String,String>> {
private transient Jedis jedis;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
jedis = new Jedis("192.168.1.1", 6379, 5000);
jedis.auth("123456");
jedis.select(0);
}
@Override public void invoke(Tuple3<String, String, String> value, Context context) throws Exception {
if (!jedis.isConnected()){
jedis.connect();
}
jedis.hset(value.f0,value.f1,value.f2);
}
@Override
public void close() throws Exception {
super.close(); jedis.close();
}
}
11.2 kafka–>flink–>mysql
11.2.1 增加依赖
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
11.2.2 代码实现
package com.wedoctor.flink;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class MySqlSink extends RichSinkFunction<Tuple2<String, Integer>> {
private Connection connection = null;
@Override
public void open(Configuration parameters) throws Exception {
//可以创建数据库连接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456");
}
@Override
public void invoke(Tuple2<String, Integer> value, Context context) throws Exception {
PreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO test VALUES (?, ?) ON DUPLICATE KEY UPDATE counts = ?");
preparedStatement.setString(1, value.f0);
preparedStatement.setLong(2, value.f1);
preparedStatement.setLong(3, value.f1);
preparedStatement.executeUpdate();
preparedStatement.close();
}
@Override
public void close() throws Exception {
connection.close();
}
}
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class KafkaSourceToMySQL {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//如果开启Checkpoint,偏移量会存储到哪呢?
env.enableCheckpointing(30000);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);
//就是将job cancel后,依然保存对应的checkpoint数据
env.getCheckpointConfig() .enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.setStateBackend(new FsStateBackend(args[0]));
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(10, 30000));
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "node-1.51doit.cn:9092,node-2.51doit.cn:9092,node-3.51doit.cn:9092");
properties.setProperty("group.id", args[1]);
properties.setProperty("auto.offset.reset", "earliest");
//properties.setProperty("enable.auto.commit", "false");
//如果没有开启checkpoint功能,为了不重复读取数据,FlinkKafkaConsumer会将偏移量保存到了Kafka特殊的topic中(__consumer_offsets)
//这种方式没法实现Exactly-Once
FlinkKafkaConsumer<String> flinkKafkaConsumer = new FlinkKafkaConsumer<String>(args[2], new SimpleStringSchema(), properties);
//在Checkpoint的时候将Kafka的偏移量保存到Kafka特殊的Topic中,默认是true
flinkKafkaConsumer.setCommitOffsetsOnCheckpoints(false);
DataStreamSource<String> lines = env.addSource(flinkKafkaConsumer);
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
SingleOutputStreamOperator<Tuple2<String, Integer>> summed = keyed.sum(1);
//Transformation 结束
//调用MySQLSink将计算好的结果保存到MySQL中
summed.addSink(new MySqlSink());
env.execute("KafkaSourceToMySQL"); } }
十二 table API
12.1 依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_2.11artifactId>
<version>1.11.2version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner_2.11artifactId>
<version>1.11.2version>
dependency>
12.2 代码实现
package com.wedoctor.flink;
public class WC {
public String word;
public Integer cnt;
public WC(String word, Integer cnt) {
this.word = word;
this.cnt = cnt;
}
public WC() { }
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public Integer getCnt() {
return cnt;
}
public void setCnt(Integer cnt) {
this.cnt = cnt;
}
@Override
public String toString() {
return "WC{" + "word='" + word + '\'' + ", cnt=" + cnt + '}'; }
public static WC of(String word, Integer cnt) {
WC wc = new WC(); wc.word = word; wc.cnt = cnt; return wc;
}
}
package com.wedoctor.flink;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.BatchTableEnvironment;
public class WordCountTableApi {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tEnv = BatchTableEnvironment.create(env);
DataSet<WC> input = env.fromElements(
WC.of("spark", 1),
WC.of("kafka", 1),
WC.of("java", 1),
WC.of("flink", 1),
WC.of("flink", 1)
);
tEnv.registerDataSet("WordCount", input, "word, cnt");
//执行SQL,并结果集做为一个新表
Table table = tEnv.sqlQuery("SELECT word, SUM(cnt) as cnt FROM WordCount GROUP BY word");
DataSet<WC> result = tEnv.toDataSet(table, WC.class);
result.print();
}
}
十三 双流join
13.1 window join
Window join如果并行的不为,任务不会触发执行,自定义一个trigger,trigger中有2个方法 onElement(来一条数据就执行该方法),onEventTime,waterMark => 窗口结束边界执行
左表迟到 侧流输出,查询数据库关联右表数据
右表迟到 直接查询数据库关联右表数据
将正常的数据和迟到的数据union到一起写入es,hbase或者clickhouse
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.AllWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.sql.*;
public class OrderJoinAdv {
public static void main(String[] args) throws Exception {
ParameterTool parameters = ParameterTool.fromPropertiesFile(args[0]);
FlinkUtilsV2.getEnv().setParallelism(1);
//使用EventTime作为时间标准
FlinkUtilsV2.getEnv().setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<String> orderMainLinesDataStream = FlinkUtilsV2.createKafkaDataStream(parameters, "ordermain", "g1", SimpleStringSchema.class);
DataStream<String> orderDetailLinesDataStream = FlinkUtilsV2.createKafkaDataStream(parameters, "orderdetail", "g1", SimpleStringSchema.class);
//对数据进行解析
SingleOutputStreamOperator<OrderMain> orderMainDataStream = orderMainLinesDataStream.process(new ProcessFunction<String, OrderMain>() {
@Override
public void processElement(String line, Context ctx, Collector<OrderMain> out) throws Exception {
//flatMap+filter
try {
JSONObject jsonObject = JSON.parseObject(line);
String type = jsonObject.getString("type");
if (type.equals("INSERT") || type.equals("UPDATE")) {
JSONArray jsonArray = jsonObject.getJSONArray("data");
for (int i = 0; i < jsonArray.size(); i++) {
OrderMain orderMain = jsonArray.getObject(i, OrderMain.class);
orderMain.setType(type);
//设置操作类型
out.collect(orderMain);
}
}
} catch (Exception e) {
//e.printStackTrace();
//记录错误的数据
}
}
});
//对数据进行解析
SingleOutputStreamOperator<OrderDetail> orderDetailDataStream = orderDetailLinesDataStream.process(new ProcessFunction<String, OrderDetail>() {
@Override
public void processElement(String line, Context ctx, Collector<OrderDetail> out) throws Exception {
//flatMap+filter
try {
JSONObject jsonObject = JSON.parseObject(line);
String type = jsonObject.getString("type");
if (type.equals("INSERT") || type.equals("UPDATE")) {
JSONArray jsonArray = jsonObject.getJSONArray("data");
for (int i = 0; i < jsonArray.size(); i++) {
OrderDetail orderDetail = jsonArray.getObject(i, OrderDetail.class);
orderDetail.setType(type);
//设置操作类型
out.collect(orderDetail);
}
}
} catch (Exception e) {
//e.printStackTrace();
//记录错误的数据
}
}
});
int delaySeconds = 2;
int windowSize = 5;
//提取EventTime生成WaterMark
SingleOutputStreamOperator<OrderMain> orderMainStreamWithWaterMark = orderMainDataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<OrderMain>(Time.seconds(delaySeconds)) {
@Override
public long extractTimestamp(OrderMain element) {
return element.getCreate_time().getTime();
}
});
SingleOutputStreamOperator<OrderDetail> orderDetailStreamWithWaterMark = orderDetailDataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<OrderDetail>(Time.seconds(delaySeconds)) {
@Override
public long extractTimestamp(OrderDetail element) {
return element.getCreate_time().getTime();
}
});
//定义迟到侧流输出的Tag
OutputTag<OrderDetail> lateTag = new OutputTag<OrderDetail>("late-date") {
};
//对左表进行单独划分窗口,窗口的长度与cogroup的窗口长度一样
SingleOutputStreamOperator<OrderDetail> orderDetailWithWindow =
orderDetailStreamWithWaterMark.windowAll(TumblingEventTimeWindows.of(Time.seconds(windowSize))) .sideOutputLateData(lateTag)
//将迟到的数据打上Tag
.apply(new AllWindowFunction<OrderDetail, OrderDetail, TimeWindow>() {
@Override
public void apply(TimeWindow window, Iterable<OrderDetail> values, Collector<OrderDetail> out) throws Exception {
for (OrderDetail value : values) {
out.collect(value);
}
}
});
//获取迟到的数据
DataStream<OrderDetail> lateOrderDetailStream = orderDetailWithWindow.getSideOutput(lateTag); //应为orderDetail表的数据迟到数据不是很多,没必要使用异步IO,直接使用RichMapFunction
SingleOutputStreamOperator<Tuple2<OrderDetail, OrderMain>> lateOrderDetailAndOrderMain = lateOrderDetailStream.map(new RichMapFunction<OrderDetail, Tuple2<OrderDetail, OrderMain>>() { @Override
public Tuple2<OrderDetail, OrderMain> map(OrderDetail detail) throws Exception {
return Tuple2.of(detail, null);
}
});
//Left Out JOIN,并且将订单明细表作为左表
DataStream<Tuple2<OrderDetail, OrderMain>> joined = orderDetailWithWindow.coGroup(orderMainStreamWithWaterMark)
.where(new KeySelector<OrderDetail, Long>() {
@Override
public Long getKey(OrderDetail value) throws Exception {
return value.getOrder_id();
}
})
.equalTo(new KeySelector<OrderMain, Long>() {
@Override
public Long getKey(OrderMain value) throws Exception {
return value.getOid();
}
})
.window(TumblingEventTimeWindows.of(Time.seconds(windowSize)))
.apply(new CoGroupFunction<OrderDetail, OrderMain, Tuple2<OrderDetail, OrderMain>>() {
@Override
public void coGroup(Iterable<OrderDetail> first, Iterable<OrderMain> second, Collector<Tuple2<OrderDetail, OrderMain>> out) throws Exception {
for (OrderDetail orderDetail : first) {
boolean isJoined = false;
for (OrderMain orderMain : second) {
out.collect(Tuple2.of(orderDetail, orderMain));
isJoined = true;
}
if (!isJoined) {
out.collect(Tuple2.of(orderDetail, null));
}
}
}
});
joined.union(lateOrderDetailAndOrderMain).map(new RichMapFunction<Tuple2<OrderDetail, OrderMain>, Tuple2<OrderDetail, OrderMain>>() {
private transient Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
//可以创建数据库连接
connection = DriverManager.getConnection("jdbc:mysql://172.16.100.100:3306/doit?characterEncoding=UTF-8", "root", "123456");
}
@Override
public Tuple2<OrderDetail, OrderMain> map(Tuple2<OrderDetail, OrderMain> tp) throws Exception { //每个关联上订单主表的数据,就查询书库
if (tp.f1 == null) {
tp.f1 = queryOrderMainFromMySQL(tp.f0.getOrder_id(), connection);
}
return tp;
}
@Override
public void close() throws Exception {
//关闭数据库连接
}
}).print();
FlinkUtilsV2.getEnv().execute();
}
private static OrderMain queryOrderMainFromMySQL(Long order_id, Connection connection) throws Exception {
PreparedStatement preparedStatement = connection.prepareStatement("SELECT * ordermain WHERE oid = ?");
//设置参数
preparedStatement.setLong(1, order_id);
//执行查询
ResultSet resultSet = preparedStatement.executeQuery();
//取出结果
long oid = resultSet.getLong("oid");
Date createTime = resultSet.getDate("create_time");
double totalMoney = resultSet.getDouble("total_money");
int status = resultSet.getInt("status");
OrderMain orderMain = new OrderMain();
orderMain.setOid(oid);
orderMain.setStatus(status);
return orderMain;
}
}
13.2 interval join
先keyBy 再进行join
十四 侧流输出
14.1 数据流拆分
Flik中,可以将一个流中的数据根据数据的不同属性进行if判断或者模式匹配,然后给各个流打上标签,以后可以根据标签的名字,取出想要的,类型的数据流,侧流输出的优点是比filter效率高,不必对数据进行多次处理,就可以将不同类型的数据拆分
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = new OutputTag<String>("side-output"){}; SingleOutputStreamOperator<Integer> mainDataStream = input.process(new ProcessFunction<Integer, Integer>() { @Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// emit data to regular output
out.collect(value);
// emit data to side output
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});
package com.wedoctor.flink;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/** * 1.将数据整理成Tuple3 * 2.然后使用侧流输出将数据分类 */
public class SideOutputsDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// view,pid,2020-03-09 11:42:30
// activity,a10,2020-03-09 11:42:38
// order,o345,2020-03-09 11:42:38
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
OutputTag<Tuple3<String, String, String>> viewTag = new OutputTag<Tuple3<String, String, String>>("view-tag") { };
OutputTag<Tuple3<String, String, String>> activityTag = new OutputTag<Tuple3<String, String, String>>("activity-tag") { };
OutputTag<Tuple3<String, String, String>> orderTag = new OutputTag<Tuple3<String, String, String>>("order-tag") { };
//直接调用process方法
SingleOutputStreamOperator<Tuple3<String, String, String>> tpDataStream = lines.process(new ProcessFunction<String, Tuple3<String, String, String>>() {
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public void processElement(String input, Context ctx, Collector<Tuple3<String, String, String>> out) throws Exception {
//1.将字符串转成Tuple2
String[] fields = input.split(",");
String type = fields[0];
String id = fields[1];
String time = fields[2];
Tuple3<String, String, String> tp = Tuple3.of(type, id, time);
//2.对数据打标签
//将数据打上标签
if (type.equals("view")) {
//输出数据,将数据和标签关联
ctx.output(viewTag, tp);
//ctx.output 输出侧流的
} else if (type.equals("activity")) {
ctx.output(activityTag, tp);
} else {
ctx.output(orderTag, tp);
}
//输出主流的数据
out.collect(tp);
}
});
//输出的测流只能通过getSideOutput
DataStream<Tuple3<String, String, String>> viewDataStream = tpDataStream.getSideOutput(viewTag);
//分别处理各种类型的数据。
viewDataStream.print();
env.execute();
}
}
14.2 获取窗口延迟数据
package com.wedoctor.flink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;
public class WindowLateDataDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//1000,hello
//2000,jerry
DataStreamSource<String> lines = env.socketTextStream("localhost", 8888);
//设置了窗口的延迟时间为2秒
SingleOutputStreamOperator<String> linesWithWaterMark = lines.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
@Override
public long extractTimestamp(String element) {
return Long.parseLong(element.split(",")[0]);
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = linesWithWaterMark.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
//切除时间字段,保留单词
return Tuple2.of(value.split(",")[1], 1);
}
});
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
OutputTag<Tuple2<String, Integer>> lateDataTag = new OutputTag<Tuple2<String, Integer>>("late-data"){};
SingleOutputStreamOperator<Tuple2<String, Integer>> summed =
keyed.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sideOutputLateData(lateDataTag)
.sum(1);
//获取迟到数据的侧流
DataStream<Tuple2<String, Integer>> lateDataStream = summed.getSideOutput(lateDataTag);
//summed.print("准时的数据: ");
//lateDataStream.print("迟到的数据:");
SingleOutputStreamOperator<Tuple2<String, Integer>> result =
summed.union(lateDataStream).keyBy(0).sum(1);
result.print();
env.execute();
}
}
十五 异步IO
15.1 Httpclient
15.1.1 官方示例

15.1.2 通过HttpClient访问高德接口
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.7version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpasyncclientartifactId>
<version>4.1.4version>
dependency>
<dependency>
<groupId>commons-httpclientgroupId>
<artifactId>commons-httpclientartifactId>
<version>3.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.57version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.7version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpasyncclientartifactId>
<version>4.1.4version>
dependency>
<dependency>
<groupId>commons-httpclientgroupId>
<artifactId>commons-httpclientartifactId>
<version>3.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.57version>
dependency>
15.2 Mysql
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.0.18version>
dependency>
package com.wedoctor.flink;
import com.alibaba.druid.pool.DruidDataSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Collections;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.function.Supplier;
public class AsyncMysqlRequest extends RichAsyncFunction<String,String> {
private transient DruidDataSource dataSource;
private transient ExecutorService executorService;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
executorService = Executors.newFixedThreadPool(20);
dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUsername("root"); dataSource.setPassword("123456");
dataSource.setUrl("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8");
dataSource.setInitialSize(5); dataSource.setMinIdle(10);
dataSource.setMaxActive(20); }
@Override
public void close() throws Exception {
super.close();
dataSource.close();
executorService.shutdown();
}
@Override
public void asyncInvoke(String id, ResultFuture<String> resultFuture) throws Exception {
Future<String> future = executorService.submit(() -> {
return queryFromMysql(id);
});
CompletableFuture.supplyAsync(new Supplier<String>() {
@Override
public String get() {
try {
return future.get();
} catch (Exception e) {
return null;
}
}
}).thenAccept( (String dbResult) -> {
resultFuture.complete(Collections.singleton(dbResult));
});
}
private String queryFromMysql(String param) throws SQLException {
String sql = "select name from info where id = ?";
String result = null;
Connection connection = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
connection = dataSource.getConnection();
stmt = connection.prepareStatement(sql);
stmt.setString(1,param);
rs = stmt.executeQuery();
while (rs.next()){
result = rs.getString("name");
}
}finally {
if (rs != null){
rs.close();
}
if (stmt != null){
stmt.close();
}
if (connection != null){
connection.close();
}
}
if (result != null){
//可以放入缓存中
}
return result;
}
}