目标检测算法(二)OverFeat精细分析和讲解并附源码地址
《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》OverFeat:用卷积网络同时进行图像识别、定位和检测。
目录
目录
背景:
OverFeat的网络结构和技术创新
计算机视觉领域的基本任务
OverFeat的网络结构
全卷积网络
多尺度滑窗检测器
模型设计和训练
过程设计
部分具体参数
Feature Extractor 特征提取器
Multi-Scale Classification 多尺度的分类方法
本文的多尺度分类方法
Offset技术
OverFeat的实验及评价指标
物体检测任务的评价指标
OverFeat实验结果
定位任务
OverFeat的优缺点及改进方向
总结
源码地址(Github):点击此处跳转链接
背景:
OverFeat的论文背景主要是针对当时物体检测和分类任务的挑战和瓶颈进行的研究。在当时,物体检测和分类是计算机视觉领域中的一个重要研究方向,但是传统的方法通常需要手工设计特征和分类器,因此很难实现端到端的训练和优化。同时,传统的方法还存在一些问题,如计算复杂度高、准确率不高、对目标的尺度、旋转和视角变化等因素敏感等。
为了解决这些问题,OverFeat的作者提出了一种基于卷积神经网络的端到端的物体检测和分类方法,该方法可以自动学习图像中的特征,并进行目标检测和分类。此外,作者还使用了全卷积网络和滑动窗口等技术,使得模型可以对输入图像进行密集预测和定位,从而提高了模型的性能和效率。同时,OverFeat还在实验中比较了不同的模型和方法,在多个数据集上取得了优秀的表现,进一步验证了该方法的有效性和可靠性。
总的来说,OverFeat的论文背景主要是针对当时物体检测和分类任务的瓶颈和挑战,提出了一种端到端的、基于卷积神经网络的物体检测和分类方法,具有较高的准确率和效率,为后续的物体检测和分类研究提供了重要的参考和启示。
OverFeat的网络结构和技术创新
计算机视觉领域的基本任务
在开始之前我们先来进行一个基础知识的普及以方便对后面内容的理解
(i) 分类: 在计算机视觉领域中,分类是指将输入的图像分为不同的预定义类别。通常情况下,分类任务的输出是一个标签,标识出输入图像所属的类别。分类是计算机视觉中最基础和最重要的任务之一,广泛应用于图像识别、人脸识别、自然语言处理等领域。
(ii) 定位: 定位是指在给定的图像中定位出目标物体的位置。与分类任务不同的是,定位需要输出目标物体的位置信息,通常用一个矩形框标识出目标物体的位置。在实际应用中,定位和分类常常结合使用,即在图像分类的基础上,进一步确定目标物体的位置。
(iii) 检测: 检测是指在给定的图像中检测出所有目标物体的位置和类别。与定位任务不同的是,检测任务需要同时处理多个目标物体,因此通常需要使用目标检测算法。目标检测算法可以分为两类:基于区域提取的方法和基于全卷积的方法。其中,基于区域提取的方法通常需要进行目标区域提取、特征提取、分类和位置回归等步骤,比较复杂;而基于全卷积的方法可以直接对整幅图像进行处理,更加简单和高效。
OverFeat是一种基于全卷积神经网络的物体检测算法,可以实现目标物体的分类、定位和检测。其使用了多尺度滑窗和全卷积神经网络相结合的方法,在多个数据集上取得了非常优秀的成绩。
OverFeat的网络结构
好的,接下来我将详细分析一下OverFeat的网络模型结构。
OverFeat是一个基于卷积神经网络的端到端的物体检测模型,它由两个主要部分组成:全卷积网络和多尺度滑窗检测器。在全卷积网络中,OverFeat通过卷积和池化操作对输入的图像进行特征提取,从而得到一组全局的特征图;在多尺度滑窗检测器中,OverFeat将不同大小的滑窗应用到特征图中,从而实现了对不同大小的物体的检测。
接下来,我将分别介绍这两个部分的具体结构。
全卷积网络
全卷积网络是OverFeat的核心组成部分,它由多个卷积层和池化层组成。在卷积层中,OverFeat使用了多个大小不同的卷积核对输入的图像进行卷积,从而实现了对图像的特征提取。在池化层中,OverFeat使用了最大池化的方法对卷积后的特征图进行下采样,从而减小特征图的尺寸,提高模型的计算效率。
全卷积网络中的卷积层和池化层的具体结构如下:
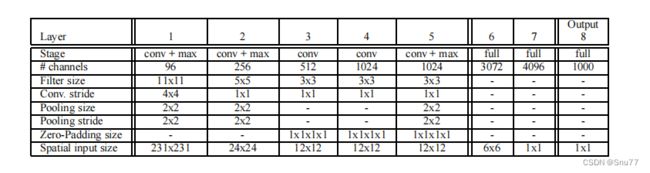
- 卷积层1:7x7大小的卷积核,步长为2,输出通道数为96。
- 池化层1:3x3大小的最大池化,步长为2。
- 卷积层2:5x5大小的卷积核,步长为2,输出通道数为256。
- 池化层2:3x3大小的最大池化,步长为2。
- 卷积层3:3x3大小的卷积核,步长为1,输出通道数为512。
- 卷积层4:3x3大小的卷积核,步长为1,输出通道数为512。
- 卷积层5:3x3大小的卷积核,步长为1,输出通道数为512。
- 池化层5:3x3大小的最大池化,步长为2。
这些卷积层和池化层共同构成了一个全卷积网络,可以对输入的图像进行特征提取。
多尺度滑窗检测器
多尺度滑窗检测器是OverFeat的另一个重要组成部分,它通过将不同大小的滑窗应用到全卷积网络中提取到的特征图中,实现了对不同大小的物体的检测。具体来说,OverFeat在特征图中对于每个特征点,使用不同大小的滑窗生成多个候选框,并对这些候选框进行分类和回归。多尺度滑窗检测器的具体结构如下:
- 输入特征图:由全卷积网络生成的特征图。
- 多尺度滑窗:不同大小的滑窗应用到特征图中,生成多个候选框。
- 全连接层:对每个候选框进行分类和回归。
- 分类器:采用softmax函数对每个候选框进行分类,得到物体的类别概率分布。
- 回归器:对每个候选框进行回归,得到物体的位置和大小信息。
需要注意的是,OverFeat中的多尺度滑窗是通过对输入图像进行多次缩放来实现的,而不是对特征图进行缩放。具体来说,OverFeat将输入图像缩放到不同的尺度,然后对每个尺度的图像应用同样大小的滑窗,生成多个候选框。
在OverFeat中,每个候选框都会被分类为属于某个物体类别或者背景类别,并通过回归器得到它的位置和大小信息。OverFeat使用了多任务学习的方法,将分类和回归任务作为一个整体进行训练。具体来说,OverFeat将分类和回归任务的损失函数进行加权和,从而实现了对两个任务的同时优化。
总的来说,OverFeat的网络模型结构非常简单而有效,它通过全卷积网络和多尺度滑窗检测器相结合的方式实现了端到端的物体检测,成为了物体检测领域的重要里程碑。
模型设计和训练
过程设计
训练数据集是ImageNet2012(120万张图片,1000个类别标签)。采用Krizhevsky等人建议的方式使用固定大小的输入,但是正如下文描述的一样,在训练的过程中将变为多尺度的。每个图像都进行下采样,以便最小尺寸为256像素。然后随机截取 5个大小为221*221的图像
部分具体参数
-
数据集:ILSVRC2012
-
数据增强:随机裁剪、颜色变换
-
初始学习率:0.01
-
学习率衰减:每隔3个epoch衰减为原来的0.1
-
正则化参数:0.0005
-
批量大小:128
-
训练迭代次数:35000
-
优化算法:批量梯度下降法
Feature Extractor 特征提取器
我们设计了快速型和准确型两个网络,下面两个表格详细的展示了这两个网络的层次结构和大小。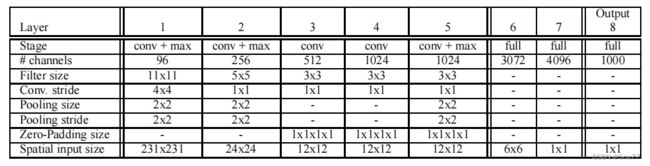
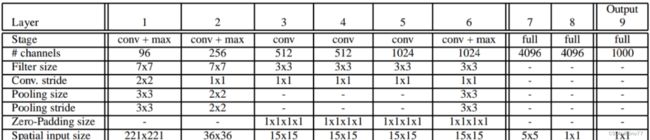 在训练过程中我们还是采用和传统ConvNet相同的训练方式,不产生空间信息(输出特征图尺寸还是1x1),但是测试阶段(推理阶段)我们会采用卷积滑窗的形式进行空间密集型预测,输出的结果带有空间信息。网络的前5层和Krizhevsky等人设计的网络类似,使用RELU激活函数和最大池化层,但是有以下区别:
在训练过程中我们还是采用和传统ConvNet相同的训练方式,不产生空间信息(输出特征图尺寸还是1x1),但是测试阶段(推理阶段)我们会采用卷积滑窗的形式进行空间密集型预测,输出的结果带有空间信息。网络的前5层和Krizhevsky等人设计的网络类似,使用RELU激活函数和最大池化层,但是有以下区别:
- 没有使用局部响应归一化层;
- 没有使用overlapping-pooling,池化区域不重合
- 第一层和第二层使用了较小的步长,原来为4,现在为2。步长越大速度越快,但有损精度。
Multi-Scale Classification 多尺度的分类方法
多尺度分类是一种在多个分辨率或尺度上对对象或数据点进行分类的方法。在这种方法中,使用不同尺度下的特征进行分类。
多尺度方法在图像分类中特别有用,因为对象可能在图像中的不同尺度下出现。例如,在一张图像中,汽车在接近相机时可能会显得很大,在远离相机时则会显得更小。通过在多个尺度下提取特征,分类器可以更准确地识别所有尺度下的汽车。
进行多尺度分类有几种方法,包括基于金字塔的方法和基于小波的方法。在基于金字塔的方法中,图像被重复下采样,以创建不同尺度的图像金字塔。然后从每个金字塔层次提取特征并用于分类。在基于小波的方法中,图像被分解为不同尺度的小波系数,然后从每个尺度提取特征。
多尺度分类可以提高分类的准确性,特别是在对象可能以不同尺度或分辨率出现的情况下。但是,它也可能需要大量的计算资源,因为需要提取和分类多个级别的特征。
本文的多尺度分类方法
-
多尺度卷积操作:该网络使用多个不同大小的卷积核对输入图像进行卷积操作,以从不同尺度上提取特征。这些卷积核的大小可以根据任务的不同而有所不同,但通常情况下会使用一些常见的卷积核大小(例如3x3和5x5)。
-
特征提取:通过多尺度卷积操作,该网络可以从输入图像中提取出不同尺度的特征。这些特征可以代表不同的图像元素,例如边缘、角点或纹理等。
-
最大池化操作:对于每个尺度上的特征图,该网络会使用最大池化操作对其进行降采样。最大池化操作会对每个小区域内的特征进行聚合,并选取其中最大的值作为该区域的代表特征。这可以帮助网络在一定程度上保留图像的空间结构信息,并降低计算成本。
-
特征图的交错排列:经过最大池化操作后,每个尺度上的特征图会变得更小,但其特征数量并未减少。接下来,该网络会将这些特征图交错排列,以创建一个新的三维特征图。这个三维特征图由所有尺度上的特征图按照顺序组成。
-
去除分辨率的损失:在交错排列的三维特征图中,每个特征都可以在水平、垂直和深度方向上与其周围的特征进行比较。为了避免分辨率的损失,该网络使用了offset技术来纠正相邻特征之间的距离。
-
分类:最后,该网络使用一个全连接层对交错排列的三维特征图进行分类。全连接层会将特征图压缩成一维向量,并将其输入到一个softmax激活函数中,以生成最终的分类结果。
综上所述,先使用多尺度卷积和最大池化操作从输入图像中提取特征,交错排列这些特征以生成一个三维特征图,并使用offset技术来去除分辨率的损失,最后通过全连接层进行分类。
Offset技术
Offset技术是在Mask R-CNN论文中提出的一种图像分割技术,主要用于解决分割结果中边界模糊的问题。传统的卷积神经网络通常采用滑动窗口或全卷积等方式,对每个像素点进行分类,这样会导致分割结果的边界模糊,不够精确。
Offset技术的基本思想是对于每个像素点,通过预测偏移量来修正其位置,从而提高分割的精度。具体来说,Offset技术在Mask R-CNN的特征金字塔网络中引入了一个新的分支,该分支会学习预测每个像素点相对于原始位置的偏移量。通过将原始位置和偏移量相加,可以得到修正后的位置,从而得到更加精确的分割结果,参考下图。

OverFeat的实验及评价指标
物体检测任务的评价指标
物体检测任务的评价指标包括精度、召回率和平均准确率(mAP)。其中,精度指检测出的物体中真正属于该类别的比例,召回率指在所有真实物体中检测出的比例,mAP则是综合考虑了精度和召回率的指标。对于物体检测任务,不同应用场景需要不同的指标。例如,在无人驾驶领域,对于行人、车辆等物体的准确检测是至关重要的,需要保证高的精度和召回率;而在广告投放领域,需要快速准确地检测出感兴趣的物体,这时候需要追求高的mAP。
OverFeat实验结果
在下面表格中,实验了不同的方法,并且和Krizhevsky等人设计的网络做比较。6种不同scales的上述方法取得了13.6%的top-5的错误率。和想象中一样,较少的scales有损性能:使用singlescale的模型top-5错误率比16.97%还差。

在下图中描述的精细步长技术(offset max-pooling技术)对于单一scale的网络带来了相对小的改进,但是对于此处显示的多scales网络也很重要。【我们带有6scales的网络在K20x GPU上处理一张图片大概需要2秒】
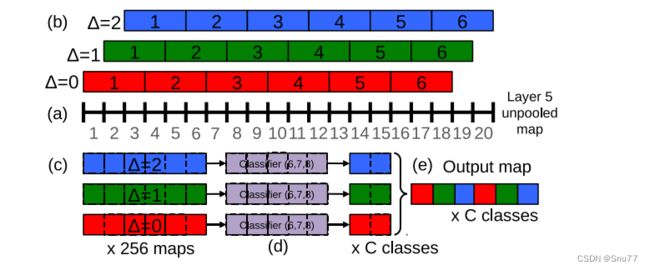
在进行特征提取的过程中,使用了多尺度卷积操作,并利用offset技术去除了分辨率的损失。具体来说,在输入不同尺寸的图像后,对每一张特征图进行了大小为(3,3)的池化操作,得到了3x3=9幅不同的池化结果图,用于下一步的特征提取。
在进行分类前,需要将特征图转化为与训练时相同的形式,即将它们展平为一维向量。为此,该架构使用了全卷积网络(FCN)的技巧,将最后一层卷积层视为全连接层,从而得到了一个大小为4096x(1x1)的特征图。在分类时,这个特征图的大小会因输入图像的不同尺寸而有所变化,因此需要将它们送入一个大小为5x5的卷积核中进行卷积,以得到相应的输出特征图。
最后,对于每个尺度,得到一个C x N的预测值矩阵,其中每列表示该图像属于某一类别的概率值。通过求取每列的最大值,可以得到该尺度下每个类别的概率值。对六个尺度得到的结果进行平均后,即可得到最终的分类结果。
至此分类任务结束了
定位任务
在定位任务中,我们需要通过网络输出的特征图来预测物体的边界框。为此,我们需要重新设计分类层(layer 6~output)使其变成回归层。在训练时,我们保持用于分类的特征提取层的参数不变,只训练后面的回归层参数。网络的输出包括四个值,分别对应于边界框的左上角和右下角的坐标值。为了训练这个回归层,我们使用L2损失函数进行优化。
OverFeat的优缺点及改进方向
OverFeat的优点在于创新地将图像分类和物体检测任务联合训练,同时引入滑动窗口的方式实现对不同大小物体的检测,从而提高了检测的准确率和召回率。另外,OverFeat的全卷积网络和分类器网络是端对端训练的,使得模型的学习过程更加高效。同时,OverFeat还在物体检测任务中取得了较好的成果,成为了物体检测领域的里程碑之一。
然而,OverFeat也存在一些缺点。首先,OverFeat的滑动窗口方式会导致计算复杂度较高,同时需要对同一物体进行多次检测,降低了检测速度;其次,OverFeat的分类器网络仅仅适用于特定的物体类别,不能直接用于新的物体类别的检测。因此,对于改进OverFeat,可以从以下几个方面入手:
(1)改进滑动窗口的方式,降低计算复杂度,并提高检测速度;
(2)引入更加灵活的分类器网络,实现对新的物体类别的检测;
(3)优化网络结构,进一步提高检测的准确率和召回率;
(4)结合其他领域的技术,例如语义分割、目标跟踪等,实现更加精细的物体检测和识别。
值得一提的是,随着深度学习的发展,物体检测领域也在不断发展,涌现出了更多优秀的模型。例如,Faster R-CNN、YOLO、SSD等模型在检测速度和准确率上都有不错的表现,并且都引入了一些新的思想和技术。因此,在应用OverFeat时,需要根据实际情况选择适合的模型,或者结合多个模型的优点进行改进,从而实现更加准确、高效的物体检测。
总的来说,OverFeat是一个非常有价值的物体检测模型,它的创新性思想和优秀的性能为物体检测领域的发展提供了重要的参考和借鉴。但是,OverFeat也存在一些局限性,需要在实际应用中进行改进和完善。我们相信,在未来的发展中,物体检测领域会不断涌现出更加优秀的模型和算法,为实际应用带来更大的效益。
总结
本文从多个方向全面系统地介绍了OverFeat这篇论文,包括论文的背景、创新点、实验结果等方面。通过对论文的分析,我们可以发现,OverFeat提出了一种新的物体检测思路,即将物体检测问题转化为对物体的全局特征的提取和分类,从而实现了物体检测和识别的同时进行。同时,OverFeat还提出了一个基于卷积神经网络的端到端的训练框架,以及一些特殊的卷积核设计和正则化策略,从而进一步提高了检测的准确率和召回率。
尽管OverFeat在物体检测领域取得了不错的成果,但是它也存在一些局限性,例如检测速度较慢、对小目标的检测效果不佳等。随着深度学习的不断发展,物体检测领域也在不断涌现出新的模型和算法,例如Faster R-CNN、YOLO、SSD等模型,它们在检测速度和准确率上都有不错的表现。因此,在实际应用中,我们需要根据具体情况选择适合的模型,并结合实际问题进行改进和优化,从而实现更加准确、高效的物体检测和识别。
总之,OverFeat是一个非常有价值的物体检测模型,它的创新性思想和优秀的性能为物体检测领域的发展提供了重要的参考和借鉴。