【AI模型】首个Joy 模型诞生!!!全民生成Joy大片

接上一篇文章 “只要10秒,AI生成IP海报,解放双手”,这次是全网第一个“共享joy 模型”,真的赚到了
经过这段时间无数次的探索、试错、实验,最终积累了非常多的训练经验,在不同IP角色的训练上实际上需要调试非常多的参数以及素材。本次成功完成了Joy的Lora模型,虽然在泛化以及场景上未来还有着很多的空间,但是本次的模型已经可以帮助大家完成大部分的运用场景,今天无论你是设计师,还是产品,还是运营,还是研发,你都将可以实现Joy的海报生成,接下来我将为大家讲一讲如何实现。
老样子先来看看实际的效果吧!!!
生成过程
模型生成海报







接下来就来和大家讲一讲如何通过SD来生成Joy吧~
1、准备工作(在开始之前,请大家下载好本次生成需要使用到的模型)
1、底模:revAnimated_v122EOL.safetensors
2、VAE:vae-ft-mse-840000-ema-pruned
3、京东Joy-Lora模型
4、京东Joy-起手式(prompt模版)
2、放置模型
1、底模:stable-diffusion-webui——models——Stable-diffusion
2、VAE:stable-diffusion-webui——models——VAE
3、京东Joy-Lora模型:stable-diffusion-webui——models——Lora
4、京东Joy-起手式:stable-diffusion-webui
3、打开SD(⚠️如果还不知道如何配置SD的同学可以看我之前的文章:“只要10秒,AI生成IP海报,解放双手”)
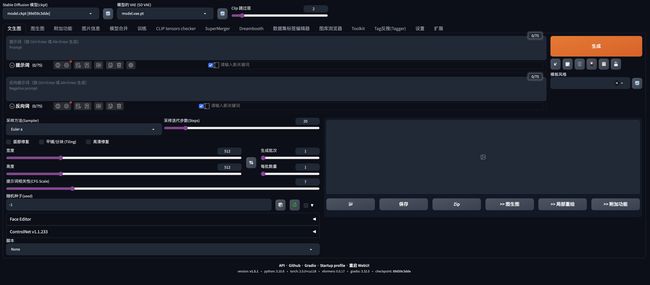
4、模型设置

1、我们需要在Stable Diffusion模型中选择我们下载好的模型:revAnimated_v122EOL(当然这是我目前测试下来效果较好的底膜,你也可以下载并使用别的底膜进行尝试)
2、在模型的VAE中选择:vae-ft-mse-840000-ema-pruned(这个VAE的饱和度比较好一些,其他的VAE会使画面较灰)
5、Prompt使用

本次我已将Joy的基础Prompt设置成了模版(Joy起手式),后续大家可以根据自己想要的画面进行调整,我会讲一下本次Prompt的基础构成
1、正向词:正向词中只要分为3类,触发词+提示词+LoRA(越靠前的词汇权重就会越高)
•Joy的触发词为joy\(ip\):只有输入这个触发词,画面中才会出现joy的形象
•提示词:在提示词中主要分为自然语言+单词描述:用自然语言来形容Joy具体在做什么(如:joy ip is standing on the stone,jumping,sitting等,建议使用进行时);用单词来形容画面中其他需要的元素(如:outdoors, day, grass, leaf, tree, flower, sunshine,等)
•Lora权重:权重进过我的测试,最高的效果是0.7,所以在Joy的lora模型上无脑设置0.7
2、负向词:主要描述你不想要的内容(如:lowres, bad anatomy, bad eyes, bad hands等,如果在生成过程中出现了你不想要的内容也可以在后续继续补充)
6、设置采样方式、采样迭代步数、尺寸、生成批次&数量
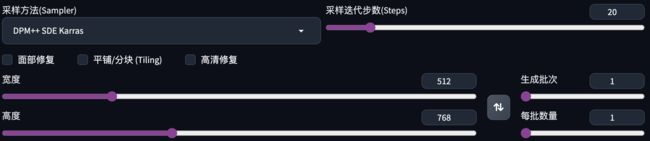
•采样方式上我们选择:DPM++ SDE Karras
•采样迭代步数:24-28之间(更具画面的复杂程度进行调试,如果画面元素较多则可以以4的倍数向上增加,需要注意在改变了步数以后会让画面产生变化)
•尺寸:一般使用64的倍数,常用的尺寸如512*768(2:3),768*512(3:2),512*512(1:1),768*1152(2:3),1152*768(3:2),不限于这些尺寸,只是说这些尺寸下抽卡出现好画面的几率更高一些
•生成批次、每批数量:在前期抽卡阶段(没有开高清修复阶段),可以把生成数量提高,来寻找喜欢的画面,在找到自己喜欢的画面后则需要设1去更精细化的抽卡
7、提示词相关性
![]()
1、提示词相关性:3-5之间效果更佳,如果没有出现IP可能是因为场景权重过高导致IP消失,可以尝试降低相关性或减少场景描述,提示词相关性是影响画面元素的非常重要的参数之一(其他影响的因素还有,迭代步数,重绘幅度,以及尺寸)
8、抽卡环节(快乐时间来了)
我们只需要嗑着瓜子,看着电视或者坐着别的事情,去挑一个动作、构图、元素、画面大致满意的底图(来作为后续打开高清的基础)
9、开启高清修复(完成一幅Joy大作)
在我们选出我们满意的底图后,需要做的就是锁定我们的seed,打开高清修复,调整我们的重绘幅度(重回幅度会影响画面变化的幅度,越低则变化越小,越高则变化越大)
•锁定我们的seed值

•将我们的放大算法改为:R-ESRGAN 4x+,调整重绘幅度0.1-0.7

•保存我们想要的图
如果你已经使用Joy模型并抽到了一些好的效果,可在评论区留言反馈,也希望和大家有更多的交流和学习,感谢大家支持哦!!