【Mysql】主从复制的搭建和原理
【Mysql】主从一致
- (一)主从复制
-
- 【1】什么是主从复制
- 【2】主从复制的用途
- 【3】有些场景是不适合用主从复制的
- 【4】使用场景的具体瓶颈
- 【5】认识binlog的主从同步原理
-
-
- (1)什么是binlog
- (2)binlog有三种记录模式
-
- 【6】mysql主从复制原理细节
-
- (1)原理介绍
- (2)也就是说
- (3)为什么需要中继日志,而不是让从库读取后直接重发?
- (4)注意
- 【7】主从复制的流程描述
- 【8】mysql主从形式
- (二)主从复制延迟问题分析
-
- 【1】主从复制的延迟底层原因
-
-
- (1)读写binlog是顺序的,重放binlog是随机的
- (2)重放binlog时出现锁和事务
-
- 【2】主从复制产生延迟的原因总结
- 【3】MTS多线程并行复制原理(multi-thread-slave)
-
-
- (1)MTS并行复制的过程描述
- (2)那么如何判定哪些事件可以并行回放?
- (3)如何知道哪些事务处于prepare状态?
- (4)在binlog中如何标注哪些事务是同一组的?
- (5)MTS并发复制流程详细总结
-
- 【4】基于GTID的主从复制问题
- 【5】复制延迟问题和解决方案
- (三)具体操作过程
-
-
- (1)首先在虚拟机服务器上安装mysql,进行简单的配置
- (2)mac使用mysql命令没有效果的解决方案
- (3)使用mac本地的mysql作为主服务器,虚拟机的mysql作为从服务器
- (4)从机配置
-
- (四)虚拟机搭建一主多从的具体操作过程
-
- 【1】搭建一台主虚拟机服务器,然后再克隆两台从服务器
- 【2】配置服务器的静态ip和hosts文件
- 【3】每个服务器上安装mysql
-
- (1)删除残留的mysql
- (3)安装mysql
- 【4】主服务器上配置mysql
- 【5】两台从服务器上配置mysql
- 【6】测试主从复制的数据是否一致
- (五)本机Navicat连接虚拟机Mysql
(一)主从复制
【1】什么是主从复制
mysql的主从复制是指数据可以从一个mysql数据库服务器主节点复制到一个或者多个从节点。mysql默认采用异步复制方式,这样从节点不用一致访问主服务器来更新自己的数据,数据的更新可以在远程链接上进行,从节点可以复制主数据库中的所有数据库或者特定的数据库,或者特定的表。
【2】主从复制的用途
(1)读写分离
在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么久很影响运行中业务,使用主从复制,可以让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作
一般都是一主多从,通过负载均衡,读的请求会比写的多,读的请求放在多个服务器里,通过负载均衡去访问不同读从库
(2)做数据的热备,防止单点故障
也就是从库给主库做数据的备份存储。发生单点故障,数据全丢失(备份也可以解决)
(3)负载均衡
架构的扩展,业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个集齐的I/O性能。
(4)高可用HA
master服务器挂了,slave服务器可以成为主服务器
【3】有些场景是不适合用主从复制的
并不是所有的场景都适合主从复制,一般情况下是读要远远多于写的应用,同时读的实效性要求不那么高的场景。
如果真实场景中真的要求立马读取到更新之后的数据,那么就只能强制读取主库的数据,所以在进行实现的时候要考虑到主从复制延迟的问题,考虑实际的应用场景。
【4】使用场景的具体瓶颈
【5】认识binlog的主从同步原理
(1)什么是binlog
bin log是我们实现主从同步的核心,同时也是我们实现数据备份、数据同步的基础,因此理解bin log是必须的。bin log本身其实就是一个二进制的日志文件,它用于记录数据表结构变化、数据变化。但是不会记录查询等操作,因为查询操作本质上不会引起数据变化。
binlog默认是关闭的,因为其本身的数据记录是会额外消耗性能的,因此我们如果不需要数据备份、同步。那么也不需要开启bin log。
(2)binlog有三种记录模式
(1)ROW: 行记录形式,会记录每一行的数据变化情况。优点是记得细,能够重现实现数据修改细节。缺点是会产生大量日志,消耗性能
(2)STATEMENT:状态记录形式,会记录每一条执行的SQL,然后通过SQL重放来实现数据同步。优点是节约资源,产生日志量会少很多,缺点是某些情况会导致数据不一致,比如执行的sql中
(3)MIXED:混合模式,一般情况使用STATEMENT,当STATEMENT不能满足的则自动切换为ROW进行记录
ROW和STATEMENT的区别:
比如我现在执行的操作是 update user set level=5 where age>30。满足age>30的数据有10W条。那么statement模式记录的日志就是update user set level=5 where age>30
,而row模式记录的日志则是 update user set level=5 where id=xxx1; update user set level=5 where id=xxx2; … update user set level=5 where id=xxxN; 这里的xxxN就是age>30的行数据的id。也就是说它按照每行单独去记录变化情况
但是很多情况下,因为我们要实现主从同步,要保重主从库数据的一致性,必须要求使用ROW,才能完全体现数据变化的日志细节。
【6】mysql主从复制原理细节
(1)原理介绍
(1)master服务器将数据的改变记录二进制binlog日志,当master上的数据发生改变时,就把这些数据的改变写入二进制日志中;
问题:如何提高主从复制的速度?
(2)从库定期检测binlog文件是否有发生变化(检测是不需要读取文件详细内容的,可以通过文件最近修改时间和Etag来实现),如果有变化则开启一个IO线程来获取主库binlog数据
(3)同时主节点为每个IO线程启动一个dump线程,用于向其发送二进制事件(也就是binlog日志数据),并且保存到从节点本地的中继日志(relay log)中,从节点就会启动sql线程从中继日志(relay log)中读取二进制日志,在本地重放,使得其数据和主节点的保持一致
(4)执行完成后,IO线程和dump线程进行睡眠状态,等待下一次数据同步再被唤醒
(2)也就是说
(1)从库会生成两个线程,一个IO线程,一个sql线程
(2)IO线程会去请求主库的binlog日志,并且把得到的binlog写到本地的relay-log中继日志文件中
(3)主库会生成一个log dump线程,用来给从库IO线程传binlog
(4)sql线程,会读取relay log我呢间中的日志,并且解析成sql语句逐一执行
(5)执行完成后,IO线程和sql线程进行睡眠状态,等待下一次数据同步再被唤醒
(3)为什么需要中继日志,而不是让从库读取后直接重发?
(1)缓冲!让数据先放到中继文件中,攒够一波之后再统一处理,这样能减少IO,提高效率,这是很多中间文件的作用,但是并不是这里中继文件的作用!!!为什么?因为我们要求实时同步,等不了~ 所以攒够一波再处理的概念肯定是不通过的
(2)解耦!这才是中继文件真正的作用。我们利用发证法,假如没有中继日志,那么这个线程很明显要处理一条龙的服务,从读取binlog到重放binlog,这个操作会让这个线程很容易阻塞,因为重发sql时可能会涉及锁表、锁行的操作,不可避免的会造成一些延迟,因此我们读binlog的时候就不能重发,先将binlog实时同步过来,然后再单开一个SQL线程来重放binlog,这才是正确的处理方式。因此我们需要一个日志来帮我们先把同步的binlog记录一下,SQL线程就可以放心的做自己的重放工作,数据同步完成后中继日志会被删除。
(4)注意
(1)master把操作语句记录到binlog日志中,然后授予slave远程连接的权限
master一定要开启binlog二进制日志功能;通常为了数据安全考虑,slave也开启binlog功能
(2)slave开启两个线程:IO线程和sql线程。其中:IO线程负责读取master的binlog内容到中继日志relay log里;sql线程负责从relay log日志里读出binlog内容,并且更新到slave的数据库里,这样就能保证slave数据和master数据保持一致了
(3)mysql复制至少需要两个mysql的服务,当然mysql服务可以分布在不同的服务器上,也可以在一台服务器上启动多个服务
(4)mysql复制最好确保master和slave服务器上的mysql版本相同,如果不能满足版本一致,那么要保证master主节点的版本要低于slave从节点的版本
(5)master和slave两节点荐时间需要同步
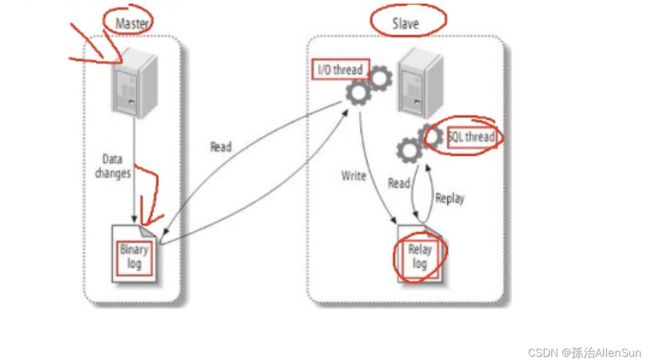
【7】主从复制的流程描述
(1)从库通过手工执行change master to 语句连接主库,提供了连续的用户一切条件(user、password、port、ip),并且让从库知道,二进制日志的起点位置(file名 position号);
(2)从库的IO线程和主库的dump线程建立连接
(3)从库根据change master to语句提供的file名和position号,IO线程向主库发起binlog的请求
(4)从库dump线程根据从库的请求,将本地binlog以events的方式发给从库IO线程
(5)从库IO线程接收binlog events,并存放到本地relay-log中,传送过来的信息,会记录到master.info中
(6)从库sql线程应用的relay-log,并且把应用过得记录到relay-log.info中,默认情况下,已经应用过得relay会自动被清理purge
【8】mysql主从形式
(1)一主一从
(2)主主复制:互相作为主服务器和从服务器
使用场景:如果是一主一从,那么当主服务器挂掉的时候,所有服务器只能用来读,不能用来写了
但是使用主主复制,每个服务器都同时具备读写的功能,两台服务器互相备份
(3)一主多从(多用)
主用来承担写的需求
从用来承担读的请求
(4)多主一从(多用)
(5)联级复制
进行数据灾备
(二)主从复制延迟问题分析
【1】主从复制的延迟底层原因
(1)读写binlog是顺序的,重放binlog是随机的
同样是1G的文件,1G的视频文件的传输速度比1G零散的HTML文件要快,涉及到随机读写和顺序读写的问题,如果是随机的就要进行不停的寻址操作,这个寻址相比较而言是比较浪费时间的。sql执行完成后写入binlog的时候是顺序的append,例如kafka的消息队列数据是放入磁盘的,只支持一个操作就是append尾部追加,以此来保证文件的顺序读写。所以binlog的读写是比较快的,几乎损耗不了多少时间,所以延迟不是在写入binlog日志的时候发生的。
接下来开始IO Thread到主库的binlog日志读取文件,这里的读也是顺序读,所以也几乎损耗不了多少时间。
接下来开始IO thread把读过来的binlog内容写到relay log里,这个写过程依然是顺序写,依然不损耗什么时间。
接下来是sql thread从relay log读取sql内容,依然是顺序的读,但是sqlThread在重执行sql的时候就成随机的了,一旦到了随机模式,就会涉及到太多的寻址而导致延迟。这里的随机不是sql执行的顺序的随机,而是查找到sql中数据的效果是随机的。

为什么重放binlog是随机的而不是顺序的?
这里的顺序和随机指的是磁盘IO的读写顺序和随机。因为写入binlog时,是预先申请好磁盘空间的,其空间是连续的,因此写入的binlog在磁盘物理位置上是挨在一起的,即是顺序的。而重发binlog时,相当于我们重新执行sql,其sql操作的数据存放位置基本上是不可能在磁盘中连续的,也就是说起存放位置随机分布,因此我们说是随机的。随机的读写相比较于顺序的读写所需耗费的时间肯定更多。
(2)重放binlog时出现锁和事务
从库SQL线程在重放binlog时,当同时有查询操作出现时,可能会出现锁表、锁行等锁操作,那么就需要等待锁释放的时间,而SQL线程又是单线程的,IO线程依旧在同步binlog,SQL线程这边还在等待着,延迟自然而然就产生了
【2】主从复制产生延迟的原因总结
(1)在某些部署环境中,备库所在的机器性能要比主库所在的机器性能差,此时如果机器的资源不足的话就会影响备库同步的效率。
(2)备库充当了读库,一般情况下主要写的压力在于主库,那么备库会提供一部分读的压力,而如果备库的查询压力过大的话,备库的查询消耗了大量的CPU资源,那么必不可少的就会影响同步的速度。
(3)大事务执行,如果主库的一个事务执行了10分钟,而binlog的写入必须要等待事务完成之后,才会传入备库,那么此时在开始执行的时候就已经延迟了10分钟了。
(4)主库的写操作是顺序写binlog的,从库单线程去主库顺序读binlog,从库取到binlog之后在本地执行。mysql的主从复制都是单线程的操作,但是由于主库是顺序写,所以效率很高,而从库也是顺序读取主库的日志,此时的效率也是比较高的,但是当数据啦去回来之后变成了随机的操作,而不是顺序的,所以此时成本会提高。
(5)从库在同步数据的同时,可能跟其他查询的线程发生锁抢占的情况,此时也会发生延时。
(6)当主库的TPS并发非常高的时候,产生的DDL数量超过了一个线程所能承受的范围的时候,那么也可能带来延迟
(7)在进行binlog日志传输的时候,如果网络带宽不是很好,那么网络延迟也可能造成数据同步延迟
!!!3-大事务问题,无解,所以要尽量避免大事务
!!!4和6是有解的,主要解决的也就是这两部分的问题
【3】MTS多线程并行复制原理(multi-thread-slave)
(1)MTS并行复制的过程描述
MTS:Multi-Threaded Slave,并行复制,实际上早在mysql5.6版本时就有基于库的并行复制,但是5.6版本的基于库的并行复制的性能并不高,当只有一个库时,其性能甚至还不如单线程,因此5.7版本时,做出了优化,推出了真正的并行复制
MTS的核心概念在于多线程并行重放binlog,但是并不是所有的binlog都能并行重放,有些操作可能涉及锁竞争,那么就不能并行执行。
MTS中除了SQL线程,还创建了多个WORK线程,IO线程不断接收bin log,写入到relay log中,SQL线程读取relay log,并且判断哪些事件可以并行回放,哪些只能串行回放。并行回放的会分发给WORK线程并行回放。串行回放的就由SQL线程自己回放。
(2)那么如何判定哪些事件可以并行回放?
通过组提交来实现,即对事务进行分组,我们认为一个组提交的事务都是可以并行回放的,那么怎么判定事务可以处于同一个组呢?那就是看主库中事务执行时,是否能够同时提交成功,或者说同时处于prepare阶段的所有事务,都是可以同时提交的
这里需要大家了解mysql事务两阶段提交的流程,简单来说就是一个事务提交完成是需要经历两个阶段的,事务执行,将数据更新到内容后,会先写入redo log,这时事务处于prepare状态,再写入bin log,然后提交事务,并将redo log标注为commit状态,这样整个事务才算提交完成。经历了prepare,commit两个阶段
只要能同时处于prepare状态的事务,说明事务间是没有锁竞争的,那么就是可以并行执行的,同时也是可以并行回放的。如果有锁竞争的,那么该事务肯定要等待竞争事务先执行完,释放锁后才能执行,也就不可能同时处于prepare状态
(3)如何知道哪些事务处于prepare状态?
mysql5.7引入了两个变量
(1)sequence_number
: 序列号,每个事务对应一个,顺序增长,当事务提交后便会得到自己的sequence_number
(2)last_committed
: 表示事务提交时,上次事务提交的编号,事务进入prepare阶段后,会将自己的last_committed更新为上次提交事务的sequence_number,这样有相同last_committed的事务就是同一组。
这两个变量都会记录到bin log中,并且其作用域是文件范围内,也就是说换了一个bin log文件,其值就会从0开始计算。于是乎通过last_committed我们也就知道了哪些事务是同一组的。
(4)在binlog中如何标注哪些事务是同一组的?
其实我们上面已经讲到了,是通过last_committed信息来标注,但这里我们要拓展一下,mysql5.7中将sequence_number和last_committed信息属于组提交信息,组提交信息是存放到GTID事件中的,每个事务会有自己的GTID事件。
GTID默认是关闭的,如果关闭时会讲组提交信息存放到匿名GTID事件中(Anonymous_Gtid),如果开启了,就会存储到每个事务自己的GTID事件中,每个事务执行前都会添加一个GTID事件,用于记录当前的全局事务ID
(5)MTS并发复制流程详细总结
(1)主库将数据的变化写入到binlog中
(2)从库定期检测binlog文件是否有发生变化,如果有变化则开启一个IO线程来获取主库binlog数据
(3)同时主库会为每个IO线程启动一个dump线程,用于先IO线程发送二进制事件(也就是binlog日志数据)。发送获取的数据并不会直接给到从库进行重放,而是先放到一个中继日志(relay log)中
(4)从库的SQL线程从relay log中读取事务后,会获取该事务的组信息,拿到sequence_number和last_committed
(5)从库会记录已经执行了的事务的sequence_number的最小值,将其存放到low water mark变量中,简称lwm
(6)lwm与取出事务的last_committed比较,如果last_committed比lwm更小,说明取出事务与当前执行组为同组(本组事务的sequence_number的最小值肯定大于last_committed)。则SQL线程会找到一个空闲的WORK线程,如果有空闲的,就会直接重放这个事务,如果没有空闲的,SQL线程就会处于等待状态,直到有一个空闲的WORK线程为止。
(7)如果last_committed等于大于lwm,则说明取出事务与当前执行组不是同一组,则取出事务需要等待。
如下图所示,当获取到事务4时,因为已经执行的事务的最小sequence_number是3,则lwm是3 而事务4的last_committed为3,是等于lwm的,则知道事务3和事务4不是一组
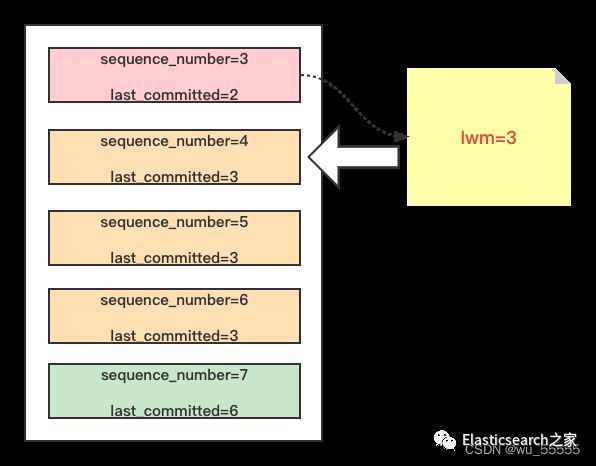
当继续执行到事务5时,因为已经执行过事务4了,则lwm=4,而事务5的last_committed=3,小于lwm,则事务5与事务4同组,可以并发复制

【4】基于GTID的主从复制问题
【5】复制延迟问题和解决方案
(1)问题一:主库的从库太多,导致复制延迟
从库数量以3~5个为宜,要复制的从节点数量过多,会导致复制延迟。
(2)问题二:从库硬件比主库差,导致复制延迟。
查看Master和Slave的系统配置,可能会因为机器配置不当,包括磁盘I/O,CPU,内存
等各方面因素造成复制的延迟。这一般发生在高并发大数据量写入场景中。
(3)问题三:慢SQL语句太多
假如一条SQL语句执行时间是20秒,那么从执行完毕到从库上能查到数据至少需要20
秒,这样就延迟20秒了。
一般要把SQL语句的优化作为常规工作,不断的进行监控和优化,如果单个SQL的写入时
间长,可以修改后分多次写入。通过查看慢查询日志或show full processlist命令,找出
执行时间长的查询语句或大的事务。
(4)问题四:主从复制的设计问题
例如,主从复制单线程,如果主库写并发太大,来不及传送到从库,就会导致延迟。
更高版本的MySQL可以支持多线程复制,门户网站则会自己开发多线程同步功能。
(5)问题五:主从库之间的网络延迟
主从库的网卡,网线,连接的交换机等网络设备都可能成为复制的瓶颈,导致复制延
迟,另外,跨公网主从复制很容易导致主从复制延迟。
(6)问题六:主库读写压力大,导致复制延迟。
主库硬件要搞好一点,架构的前端要加buffer及缓存层。
避免出现大事务
(三)具体操作过程
(1)首先在虚拟机服务器上安装mysql,进行简单的配置
虚拟机安装mysql5.7的过程文件:https://blog.csdn.net/u012318074/article/details/103377958
注意的是mysql5.7在修改密码时会要求安全等级,这时候要改一些配置
set global validate_password_policy=0;
set global validate_password_length=1;
SET PASSWORD FOR ‘root’@‘localhost’= “123456”;
(2)mac使用mysql命令没有效果的解决方案
主要是因为电脑没有配置mysql的路径
参考的信息:https://www.cnblogs.com/hzaixt/p/13713962.html
1-进入路径
cd /usr/local/opt/mysql@5.7/bin
2-编辑配置文件
vim ~/.bash_profile
3-添加mysql配置路径
# Mysql
export MYSQL_HOM="/usr/local/opt/mysql@5.7/bin”
4-退出后保存更新
source ~/.bash_profile
5-再使用 mysql -uroot -p 就可以登录了
(3)使用mac本地的mysql作为主服务器,虚拟机的mysql作为从服务器
配置mac主机和虚拟机从机的参考文件:https://blog.csdn.net/weixin_68588547/article/details/125322887?spm=1001.2014.3001.5506
(1)打开虚拟机服务器的3306端口的防火墙权限
查看防火墙信息: firewall-cmd --list-all
添加端口号: sudo firewall-cmd --add-port=3306/tcp --permanent
重启防火墙: firewall-cmd --reload
再查看防火墙信息:firewall-cmd --list-all
(2)配置mac上的mysql配置文件
打开终端,输入下面命令,打开并修改mysql配置文件,配置开启二进制日志
vim /usr/local/etc/my.cnf
#主从复制的配置如下
log-bin=master-bin #二进制文件名称
binlog-format=ROW #二进制日志格式
server-id=1 #要求各个服务器的id必须不一样
binlog-do-db=msb #同步的数据库名称
(3)重新启动mysql
创建主库msb
create database msb;
(经过上面的配置以后,可以直接使用命令来重启了:mysql.server restart)
1. 启动MySQL服务 /usr/local/opt/mysql@5.7/bin/mysql.server start
2. 停止MySQL服务 /usr/local/opt/mysql@5.7/bin/mysql.server stop
3. 重启MySQL服务 /usr/local/opt/mysql@5.7/bin/mysql.server restart
(4)登录主库mysql,执行sql进行授权
执行sql:GRANT REPLICATION SLAVE ON *.* to ‘username’@‘%’ identifiled by ‘password’;
创建一个用户username,密码为password,并且给username用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才可以通过该用户复制。
(执行下面这四行代码)
修改设置密码的安全等级
把副本的权限授权给所有地址的从服务器
set global validate_password_policy=0;
set global validate_password_length=1;
grant replication slave on *.* to 'root'@'%' identified by '123456’;
flush privileges;
(5)查看主库的状态
show master status;
position
binlog_do_db:指定同步的数据库

接下来的主机就有了复制副本的功能了
(4)从机配置
打开mysql的配置文件
vim /etc/my.cnf
添加下面的内容
[mysqld]
log-bin=master-bin #二进制文件的名称
binlog-format=ROW #二进制文件的格式
server-id=2 #服务器的id
保存后重启mysql
service mysqld restart
重新登录mysql
mysql -uroot -p123456
执行下面的sql
change master to
master_host='主库的ip地址',
master_user='之前设置master时的username',
master_password='之前设置master时的password',
master_log_file='查看master状态时的file名',
master_log_pos='查看master状态时的position';
change master to
master_host='192.168.0.***',
master_user='root',
master_password='123456’,
master_log_file='master-bin.000001',
master_log_pos=154;
mac查看ip地址的位置
执行完上面sql之后,输入命令开始主从复制
start slave;
查看从数据库的状态
show slave status\G

slave_IO_Running是用来拉取数据的
Slave_SQL_Running是用来执行sql的
这两个结果都要为yes才行
(四)虚拟机搭建一主多从的具体操作过程
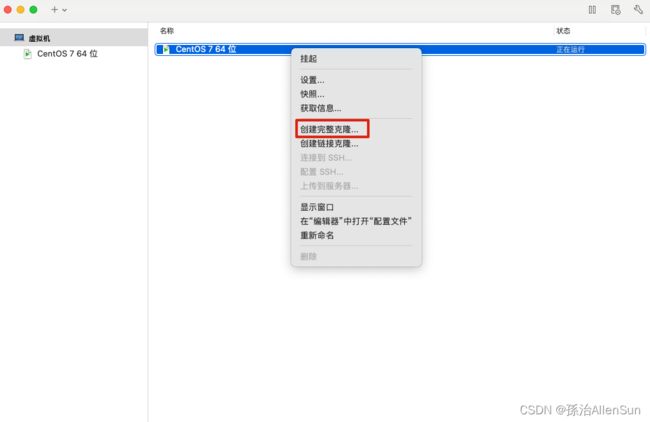
【1】搭建一台主虚拟机服务器,然后再克隆两台从服务器
【2】配置服务器的静态ip和hosts文件
(1)查看虚拟机的ip地址

在宿主机mac上的终端里连接虚拟机
ssh root@192.168.19.2
登陆成功

网络模式选择NAT模式,然后开始配置静态ip
mac终端输入ifconfig查看vmnet8的IP地址
(2)在mac本地打开网卡配置文件
cat /Library/Preferences/VMware\ Fusion/vmnet8/nat.conf
结果如下
# NAT gateway address
ip = 192.168.19.1 # 后面要用,nat模式需要设置网关,就是这个
netmask = 255.255.255.0

(3)在虚拟机编辑 /etc/sysconfig/network-scripts/*ens33
vim /etc/sysconfig/network-scripts/*ens33

IPADDR=192.168.19.11 # 三台虚拟机设置时只改这个参数,其他一样,我另两台是末尾的11分别改为22,33,你们随意,只要处于一个网段就行
NETMASK=255.255.255.0
GATEWAY=192.168.19.1 # 设置和VMWave同一网关,之前一直无法联网就是因为这个参数不对
DNS1=192.168.19.1 # 和GATEWAY一样,也可以设置其他能访问的DNS服务
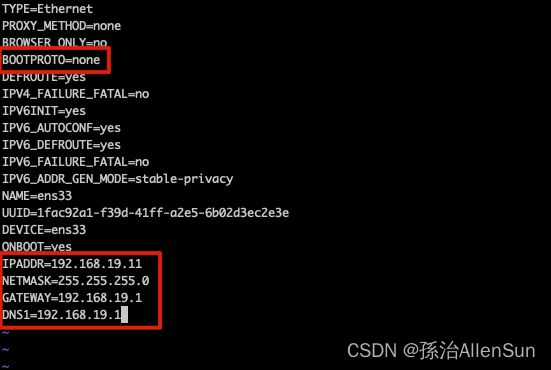
保存退出,重启mysql服务
# 保存上面更改的文件后重启服务
service network restart
或者:
systemctl restart network
重新登录时要用
ssh root@192.168.19.11
查看ip address,修改成功
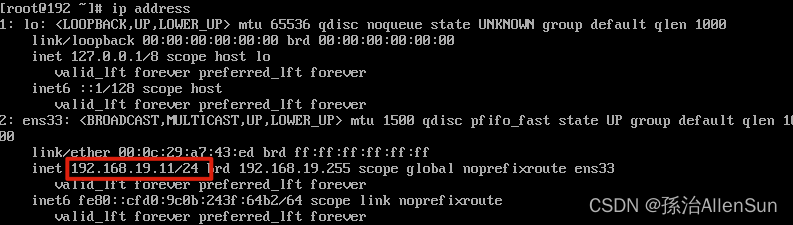
(4)配置hosts文件,创建ip和别名的映射,使得虚拟机之前可以通过别名互相访问,三个虚拟机下进行一模一样的操作:
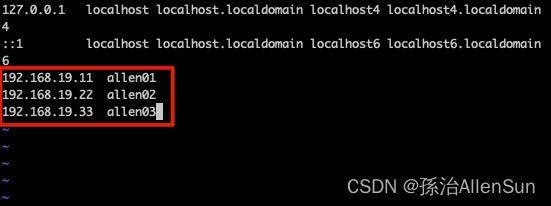
vim /etc/hosts
# 输入
192.168.19.11 allen01
192.168.19.22 allen02
192.168.19.33 allen03
# 每台虚拟机下可以直接ping别名来替代ip
ping 192.168.19.11 ? ping allen01
(5)其他两台从服务器做同样的操作
【3】每个服务器上安装mysql
(1)删除残留的mysql
查看当前安装的mysql情况
rpm -qa|grep -i mysql
如果有,全部删除所列的内容,直至rpm -qa|grep -i mysql 时没有内容
rpm -ev mysql-community-libs-5.6.37-2.el7.x86_64
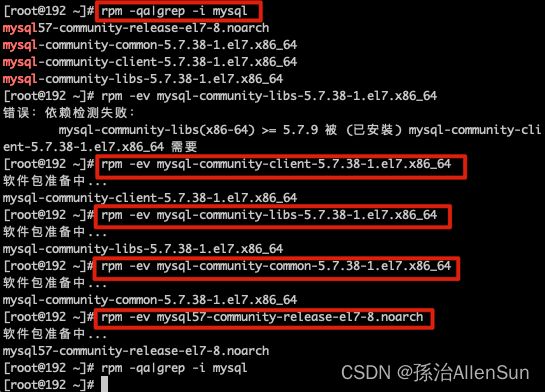
查找mysql相对应的文件夹
find / -name mysql
用rm-rf命令删除所有文件夹
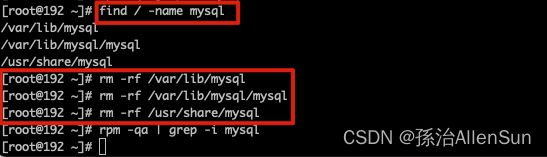
再用rpm -qa | grep -i mysql查看时候,如果什么也没出现那么说明已经将mysql删除
(3)安装mysql
下载mysql的repo源
wget http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm
升级 GPG
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
安装rpm包
rpm -ivh mysql57-community-release-el7-8.noarch.rpm --nodeps --force
安装mysql
yum install mysql-server
启动服务
systemctl start mysqld
查看状态
service mysqld status
重置root密码
grep 'temporary password' /var/log/mysqld.log
mysql -u root -p
mysql> Enter password: (输入刚才查询到的随机密码)
(修改密码时会要求安全等级)
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=1;
(MySQL版本5.7.6版本以前:SET PASSWORD = PASSWORD(‘123456');)
(MySQL版本5.7.6版本以后:ALTER USER USER() IDENTIFIED BY ‘123456';)
mysql> ALTER USER USER() IDENTIFIED BY '123456';
mysql> exit;
重新登录,成功!
其他两台服务器做相同的操作!
【4】主服务器上配置mysql
打开并修改mysql配置文件,配置开启二进制日志
vim /etc/my.cnf
#主从复制的配置如下
log-bin=master-bin #二进制文件名称
binlog-format=ROW #二进制日志格式
server-id=1 #要求各个服务器的id必须不一样
binlog-do-db=test_master_slaver #同步的数据库名称
保存后,创建主库test_master_slaver,重启mysql,重新登录
create database test_master_slaver;
service mysqld restart
mysql -uroot -p
登录主库mysql,执行sql进行授权
执行sql:GRANT REPLICATION SLAVE ON *.* to ‘username’@‘%’ identifiled by ‘password’;
创建一个用户username,密码为password,并且给username用户授予REPLICATION SLAVE权限。常用于建立复制时所需要用到的用户权限,也就是slave必须被master授权具有该权限的用户,才可以通过该用户复制。
(执行下面这四行代码)
修改设置密码的安全等级
把副本的权限授权给所有地址的从服务器
set global validate_password_policy=0;
set global validate_password_length=1;
grant replication slave on *.* to 'copy'@'%' identified by 'copy';
flush privileges;
查看主库的状态
show master status;
position
binlog_do_db:指定同步的数据库

【5】两台从服务器上配置mysql
打开并修改mysql配置文件,配置开启二进制日志
vim /etc/my.cnf
[mysqld]
log-bin=master-bin #二进制文件的名称
binlog-format=ROW #二进制文件的格式
server-id=2 #服务器的id
保存后重启mysql,重新登录
service mysqld restart
mysql -uroot -p
执行下面的sql
change master to
master_host='主库的ip地址',
master_user='之前设置master时的username',
master_password='之前设置master时的password',
master_log_file='查看master状态时的file名',
master_log_pos='查看master状态时的position';
change master to
master_host='192.168.19.11',
master_user='copy',
master_password='copy',
master_log_file='master-bin.000001',
master_log_pos=154;
执行完上面sql之后,输入命令开始主从复制
start slave;
查看从数据库的状态
show slave status\G
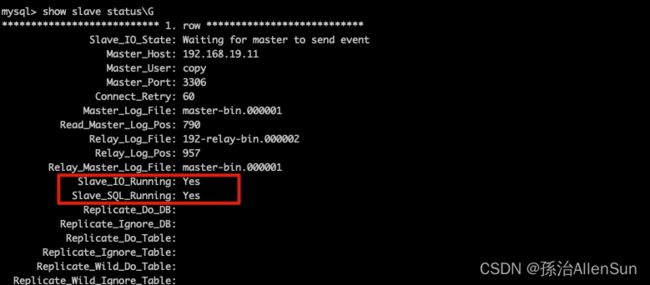
slave_IO_Running是用来拉取数据的
Slave_SQL_Running是用来执行sql的
这两个结果都要为yes才行
在从库中查找数据库,能看到刚才在主库里创建的test_master_slaver表

同样步骤配置另一台从服务器,主要是server-id=3 #服务器的id,要不一样,其他跟上面的从服务器01一致
vim /etc/my.cnf
[mysqld]
log-bin=master-bin #二进制文件的名称
binlog-format=ROW #二进制文件的格式
server-id=3 #服务器的id
【6】测试主从复制的数据是否一致
创建表hero
use test_master_slaver;
CREATE TABLE hero (
id int(11) AUTO_INCREMENT,
name varchar(30) ,
hp float ,
damage int(11) ,
PRIMARY KEY (id)
) DEFAULT CHARSET=utf8;
插入数据
insert into hero values (null, '盖伦', 616, 100);
查看两个从服务器的数据库,看到数据已经完成同步
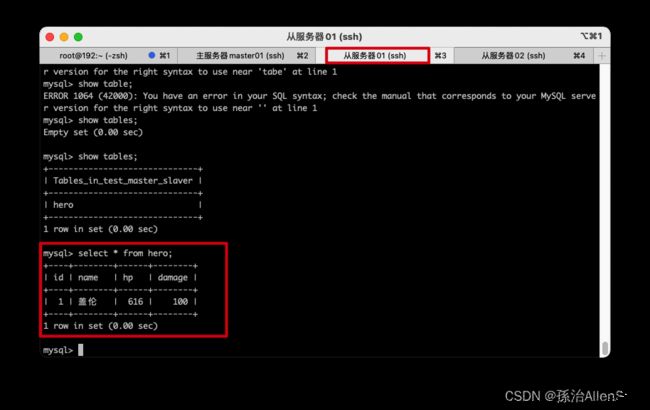
(五)本机Navicat连接虚拟机Mysql
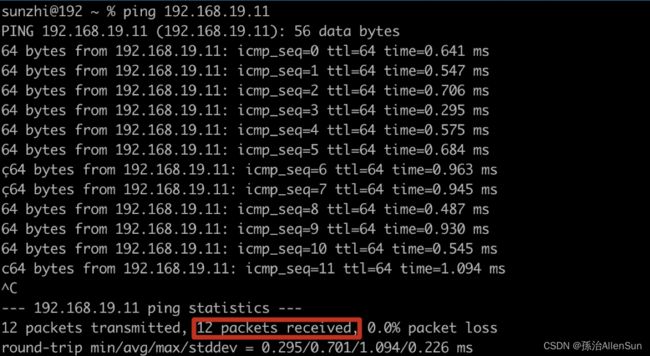
(1)测试能不能ping通
ping 192.168.19.11
(2)查看防火墙是否开启

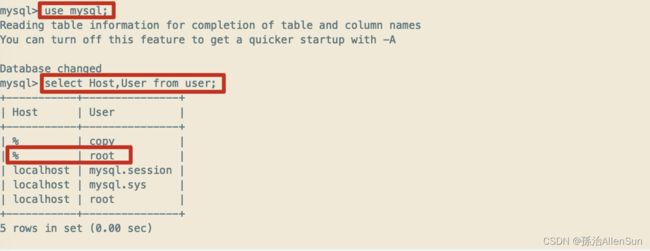
(3)查看mysql的远程连接权限
(4)Navicat连接虚拟机mysql


(5)测试主从复制的效果
确认修改之前三个库的表数据是一致的
 修改主库的数据,然后查看两个从库的数据是否对应发生了修改
修改主库的数据,然后查看两个从库的数据是否对应发生了修改
 可以看到从库里的数据也完成了数据复制
可以看到从库里的数据也完成了数据复制

本文参考文章:
(1)https://www.modb.pro/db/429572
(2)https://www.modb.pro/db/424397