JAVA—— Linux(二)
文章目录
- 1 Linux文件管理
-
- 1.1 touch命令
- 1.2 vi与vim命令
-
- 1.2.1 vi/vim介绍
- 1.2.2 vi/vim模式
- 1.2.3 打开和新建文件
- 1.2.4 三种模式切换
- 1.2.5 文件查看
-
- 1) cat命令
- 2) grep命令
- 3) tail命令
- 4)less命令
- 1.2.6 vim定位行
- 1.2.7 异常处理
- 1.2.8 操作扩展
- 1.3 echo 命令
-
-
-
- 第二步: 将**命令的成功结果** **追加** 指定文件的后面
- 第三步: 将**命令的失败结果** **追加** 指定文件的后面
-
-
- 1.4 awk命令
- 1.5 软连接
- 1.6 find查找
- 1.7 read命令
- 1.8 总结
- 2 Linux备份压缩
-
- 2.1 gzip命令
- 2.2 gunzip命令
- 2.3 tar命令
- 2.4 zip命令
- 2.5 unzip命令
- 2.6 bzip2命令
- 2.7 bunzip2命令
- 2.8 总结
- 3 网络与磁盘管理
-
- 3.1 网络命令
-
- 3.1.1 ifconfig命令
- 3.1.2 ping命令
- 3.1.3 netstat命令
- 3.2 磁盘命令
-
- **3.2.1 lsblk命令**
- 3.2.2 df命令
- 3.2.3 mount命令
- 3.3 总结
- 4 shell与安装
-
- 4.1 yum使用
-
- 4.1.1 安装tree
- 4.1.2 移除tree
- 4.1.3 yum查找
- 4.1.4 yum源
- 4.2 rpm使用
- 4.3 shell使用
-
- 4.3.1 shell入门
- 4.3.2 shell注释
- 4.3.3 shell变量
- 4.3.4 shell数组
- 4.3.5 shell运算符
- 4.3.6 shell流程控制
- 4.3.7 shell函数
- 4.3.8 总结
目标
- 能够熟练编写文件相关命令
- 能够熟练编写文件解压缩命令
- 能够熟练编写网络查看简单命令
- 能够熟练编写查看磁盘命令、挂载命令
- 能够知道如何使用命令进行分区、格式化
- 能够熟练使用yum进行查找、安装、卸载软件
- 能够熟练使用rpm进行查找、安装、卸载软件
- 能够熟练编写常用的shell脚本
1 Linux文件管理
1.1 touch命令
在Windows系统中,我们如果想创建一个文本文档或者word文件的时候,通常的做法是
鼠标右键---新建---文本文档,这样的话,我们就成功的创建了一个文件,而在Linux中,我们可以通过字符命令的形式进行创建
touch命令用于创建文件、修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
ls -l 可以显示档案的时间记录
使用者权限:所有权限用户
语法
touch [-acfm][-d<日期时间>][-r<参考文件或目录>] [-t<日期时间>][--help][--version][文件或目录…]
- 参数说明:
- a 改变档案的读取时间记录。
- m 改变档案的修改时间记录。
- c 假如目的档案不存在,不会建立新的档案。与 --no-create 的效果一样。
- f 不使用,是为了与其他 unix 系统的相容性而保留。
- r 使用参考档的时间记录,与 --file 的效果一样。
- d 设定时间与日期,可以使用各种不同的格式。
- t 设定档案的时间记录,格式与 date 指令相同。
- –no-create 不会建立新档案。
- –help 列出指令格式。
- –version 列出版本讯息。
使用 touch 创建一个空文件
在 Linux 系统上使用 touch 命令创建空文件,键入 touch,然后输入文件名。如下所示
touch czbk-devops.txt
查看
ls -l czbk-devops.txt
执行效果如下图

使用 touch 创建批量空文件
在实际的开发过程中可能会出现一些情况,我们必须为某些测试创建大量空文件,这可以使用 touch 命令轻松实现
touch czbk-{1..10}.txt
在上面的例子中,我们创建了 10 个名为 czbk-1.txt到czbk-10.txt` 的空文件,你可以根据需要更改名称和数字
执行查看命令
ls -l
执行效果如下
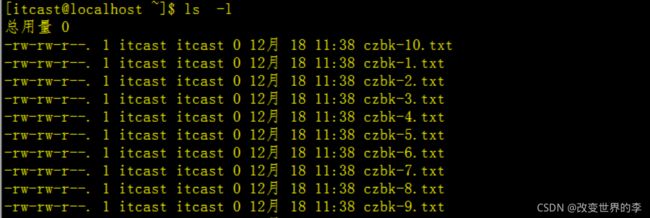
由上图我们发现,我们通过批量命令创建了10个txt文件
改变/更新文件访问时间
假设我们想要改变名为 czbk-devops.txt 文件的访问时间,在 touch 命令中使用 -a 选项,然后输入文件名。如下所示:
1、我们先 查看下czbk-devops.txt的时间属性
ls -l czbk-devops.txt
执行效果如下
![]()
我们发现,最后的访问时间是12月 18 11:34
更新时间属性,如下
touch czbk-devops.txt
执行ls命令查看,如下
ls -l czbk-devops.txt
![]()
我们发现,访问时间变成了 12月 18 13:50
我们也可以使用stat命令进行查看,如下:
stat czbk-devops.txt
执行效果如下图
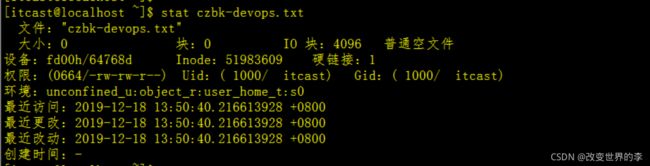
由上图可知:czbk-devops.txt的文件属性、包含访问时间、更改时间、最近改动时间都显示出来了。
关于stat命令:
stat命令用于显示inode内容。
stat以文字的格式来显示inode的内容。
语法
stat [文件或目录]
1.2 vi与vim命令
1.2.1 vi/vim介绍
使用vi/vim其实就相当于我们在Windows系统中创建文件、打开文件、编辑文件、保存文件操作
1、vi介绍
vi是 visual interface的简称, 是linux中最经典的文本编辑器。
- vi的特点
- 只能是编辑 文本内容, 不能对 字体 段落进行排版
- 不支持鼠标操作
- 没有菜单
- 只有命令
- vi编辑器在 系统管理 服务器管理 编辑文件时, 其功能永远不是图形界面的编辑器能比拟的
2、vim介绍
vim:是从 vi (系统内置命令)发展出来的一个文本编辑器。代码补全、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。
简单的来说, vi 是老式的字处理器,不过功能已经很齐全了,但是还是有可以进步的地方。
vim 则可以说是程序开发者的一项很好用的工具。
1.2.2 vi/vim模式
vi/vim模式主要分为以下三种:
命令模式:在Linux终端中输入“vim 文件名”就进入了命令模式,但不能输入文字。
编辑模式: 在命令模式下按i就会进入编辑模式,此时就可以写入程式,按Esc可回到命令模式。
末行模式: 在命令模式下按:进入末行模式,左下角会有一个冒号出现,此时可以敲入命令并执行。
下面是三种模式的简单分析图:

上图总结
上面的三种模式简单总结下就是:
1、vim 开始进入时是命令模式
2、按下I的时候会进入编辑模式
3、按下ESC然后在按下:的时候是末行模式
1.2.3 打开和新建文件
使用vim不但可以打开一个现存的文件;也可以生成(vim后的文件不存在的情况下)一个文件;有点类似于我们在Windows中输入notepad命令一样,我们输入notepad后就会打开一个文本文档,然后进行编辑--另存为。
使用者权限:当前文件的权限用户
- 在终端中输入vim在后面跟上 文件名 即可
vim txtfile.txt
- 如果文件已经存在, 会直接打开该文件
- 如果文件不存在, 保存且退出时 就会新建一个文件
注意
我们通过下面的三种模式切换详细阐述vim的用法
1.2.4 三种模式切换
1、进入命令模式
上接上面的例子,我们执行下面的命令其实就是进入了命令模式
vim txtfile.txt
执行效果如下图

2、进入编辑模式
上接上面的例子,按i进入插入模式
- 在 vi 中除了常用
i进入编辑模式 外, 还提供了一下命令同样可以进入编辑模式
| 命令 | 英文 | 功能 | 常用 |
|---|---|---|---|
| i | insert | 在当前字符前插入文本 | 常用 |
| I | insert | 在行首插入文本 | 较常用 |
| a | append | 在当前字符后添加文本 | |
| A | append | 在行末添加文本 | 较常用 |
| o | 在当前行后面插入一空行 | 常用 | |
| O | 在当前行前面插入一空行 | 常用 |
上图可以表现为以下形式,如下图
执行效果如下图

由上图左下角我们看到【插入】(英文版为INSERT),说明我们进入了编辑模式
我们在里面插入数据,如下图
因为我们是一个空文件,所以使用【I】或者【i】都可以
如果里面的文本很多,要使用【A】进入编辑模式,即在行末添加文本

3、进入末行模式
编辑模式不能保存文件
必须先推到命令模式
先按Esc键退出到命令模式
然后按小写的 :wq 正常保存退出
进入末行模式—》按符号: 鼠标跑到屏幕的最后一行,执行效果如下图
然后按小写的 :wq 正常保存退出
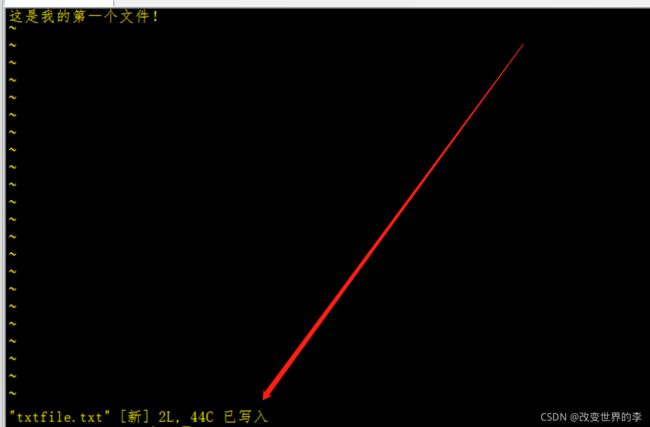
退出后显示【已写入】
以下为其他的退出模式:
:q 当vim进入文件没有对文件内容做任何操作可以按"q"退出
:q! 当vim进入文件对文件内容有操作但不想保存退出
:wq 正常保存退出
:wq! 强行保存退出,只针对与root用户或文件所有人生
总结
三种模式的切换,其实就完成了文件创建、编辑、保存、退出四个步骤
那么接下来,我们学习下一个命令
查看刚才新创建的文件
1.2.5 文件查看
比如查看一个txt文档,在windows中,我们通常是打开一个文件,通过鼠标滚动查看文件不同节选的内容,而在Linux中,通过下面的命令,可以减少在Windows中手工查找的步骤,在Linux中通过命令+参数的形式进行定位查看、搜索查看
以下5个为文件查看命令,我们只讲4个常用的命令,head不在赘述
| 序号 | 命令 | 对应英文 | 作用 |
|---|---|---|---|
| 01 | cat 文件名 | concatenate | 查看小文件内容 |
| 02 | less -N 文件名 | less | 分频 显示大文件内容 |
| 03 | head -n 文件名 | 查看文件的前一部分 | |
| 04 | tail -n 文件名 | 查看文件的最后部分 | |
| 05 | grep 关键字 文件名 | grep | 根据关键词, 搜索文本文件内容 |
总结:
以上5个命令都可以查询文件的内容,他们的功能如下
通过
cat会一次显示所有的内容, 适合 查看内容较少 的文本文件
less命令适合查看 内容较多 的文本文件通过
head命令查看文档的前几行内容通过
tail -10f 文件命令 查看文档(日志)的后几行内容通过
grep命令 搜索存在 关键字 的行
1) cat命令
使用cat命令类似于我们在Windows中查看小型(太大的时候打开会卡死)的文件,cat常用的功能其实就等价于Windows中的
txt---打开--查看
cat 是一个文本文件查看和连接工具。查看一个文件的内容,用cat比较简单,就是cat 后面直接接文件名,如cat txtFiles.txt
使用者权限:当前文件的权限用户
语法格式
cat [-AbeEnstTuv] [--help] [--version] fileName
查看文件名为txtfile.txt的内容
cat txtfile.txt
执行效果如下图

查看文件名为txtfile.txt的内容(加入行号)
cat -n txtfile.txt
执行效果如下图

2) grep命令
grep命令在使用的时候类似于我们的程序中的查询,或者在txt文档中通过ctr+f查找
grep除了能对文件操作为还可以查看我们的进程信息,类似于我们在Windows系统的任务管理器(任务栏--右键---启动任务管理器--进程)下的进程
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
grep 命令用于查找文件里符合条件的字符串,语法如下:
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
使用者权限:当前文件的权限用户
我们还是使用上面的txtfile.txt文件,如下图

为了测试效果,我们新增了其他数据
增加过程不在赘述
1、搜索 存在关键字【eeee】 的行的文件
grep eeee txtfile.txt
执行效果如下

2、搜索 存在关键字【eeee】 的行 且 显示行号
grep -n eeee txtfile.txt

3、忽略大小写 搜索 存在关键字 的行
grep -i EEEE txtfile.txt
执行效果如下

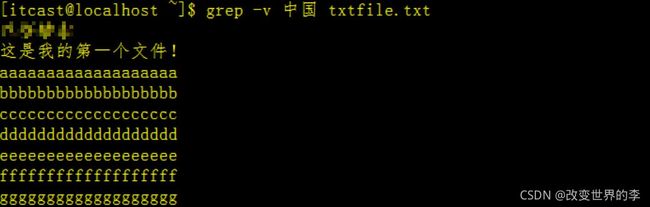
4、搜索 不存在关键字 的行
grep -v 中国 txtfile.txt
执行效果如下
5、查找指定的进程信息(包含grep进程)
ps -ef | grep sshd
执行效果如下

说明
除最后一条记录外,其他的都是查找出的进程;最后一条记录结果是grep进程本身,并非真正要找的进程
6、查找指定的进程信息(不包含grep进程)
ps aux | grep sshd | grep -v "grep"
执行效果如下

7、查找进程个数
ps -ef|grep -c sshd
执行效果如下
![]()
由上图可知sshd的进程个数为4(包含grep进程本身)
3) tail命令
tail命令类似于我们在windows中通过鼠标手工查找,比如查看文件最后10行,从第2行一直查看到文件末尾,或者只查看文件末尾的一些信息,这些windows中都是通过人为干预的方式进行查找,在Linux中我们可以通过tail命令实现
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。
tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。
使用者权限:当前文件的权限用户
命令格式:
tail [参数] [文件]
1、要显示 txtfile.txt 文件的最后 3 行,请输入以下命令:
tail -3 txtfile.txt
原始文件内容如下

最后3行内容如下

2、动态显示文档的最后内容,一般用来查看日志,请输入以下命令:
tail -f txtfile.txt
执行效果如下:
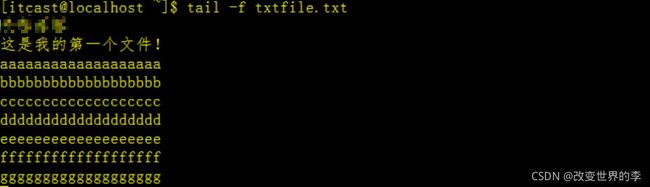
此命令显示 txtfile.txt 文件的最后 10 行。当将某些行添加至 txtfile.txt 文件时,tail 命令会继续显示这些行。 显示一直继续,直到您按下(Ctrl-C)组合键停止显示。
如果要显示最后4行,命令如下:
tail -4f txtfile.txt
执行效果如下

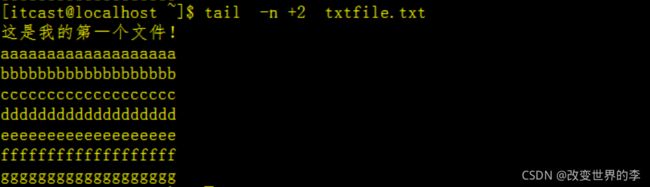
3、显示文件txtfile.txt 的内容,从第 2 行至文件末尾
tail -n +2 txtfile.txt
执行效果如下
4、显示文件 txtfile.txt的最后 10 个字符:
tail -c 45 txtfile.txt
执行效果如下

总结
在tail使用的过程中,我们使用最多的就是查看文件末尾多多少行
使用tail -nf txtfile.txt
通常都是在查看日志信息(报错调试时使用)
4)less命令
less命令也是查看文件的,只不过它适合查看 内容较多的文本文件,它也可以用于分屏显示文件内容, 每次只显示一页内容,有点类似我们做分页查询
less用于查看文件,但是less 在查看之前不会加载整个文件。
使用者权限:当前文件的权限用户
语法
less [参数] 文件
1、查看txtfile.txt文件
less txtfile.txt
执行效果如下

2、查看命令历史使用记录并通过less分页显示
[itcast@localhost ~]$ history | less
1 ifconfig
2 reboot
3 ifconfig
4 reboot
5 ifconfig
6 su root
7 ifconfig
8 ping www.baidu.com
9 \
10 ifconfig
11 date
12 hwclock --systohc
13 su root
......略
我们输入【j】可以前进行
输入【k】可以后退行
输入【G】可以 移动到最后一行
输入【g】可以移动到第一行
输入【ctrl + F】 向前移动一屏(类似于我们在浏览器中的数据分页的下一页)
输入【ctrl + B】 向后移动一屏(类似于我们在浏览器中的数据分页的上一页)
其他命令
1.全屏导航
- ctrl + F - 向前移动一屏
- ctrl + B - 向后移动一屏
- ctrl + D - 向前移动半屏
- ctrl + U - 向后移动半屏
2.单行导航
- j - 向前移动一行
- k - 向后移动一行
3.其它导航
- G - 移动到最后一行
- g - 移动到第一行
- q / ZZ - 退出 less 命令
1.2.6 vim定位行
在日常工作中,有可能会遇到打开一个文件,并定位到指定行的情况
例如: 在开发时, 知道某一行代码有错误,可以快速定位到出错误代码的位置
这个时候,可以使用以下命令打开文件
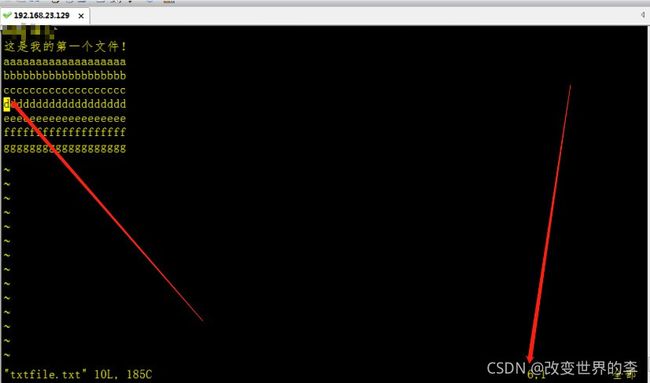
由于我们这里还没有学到上传文件的命令,所以我们这里还是使用上面的txtfile.txt例子,我们打开文件定位到第6行,如下:
vim txtfile.txt +6
执行效果如下图
1.2.7 异常处理
- 如果 vim异常退出, 在磁盘上可能会保存有 交换文件
- 下次再使用 vim 编辑文件时, 会看到以下屏幕信息,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xWUtdgc6-1632103912628)(assets/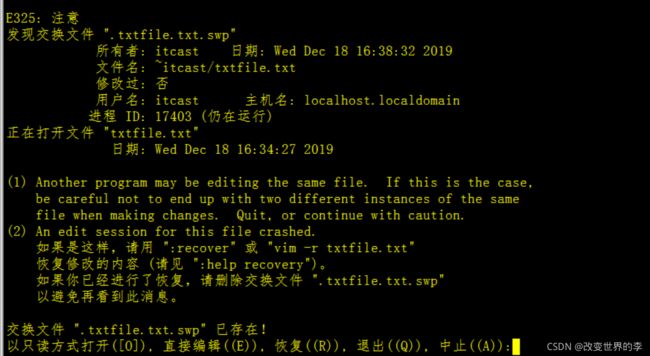
.png)]
解决方案:
将后缀名为.swp的文件删除即可恢复
![]()
再次编辑文件不在出现提示警告!
1.2.8 操作扩展
要熟练使用vi/vim, 首先应该学会怎么在 命令模式下 快速移动光标
编辑操作命令 能够和移动命令一起使用
1) 上 下 左 右

| 命令 | 功能 | 手指 |
|---|---|---|
| h | 向左 | 食指 |
| j | 向下 | 食指 |
| k | 向上 | 中指 |
| l | 向右 | 无名指 |
也可以使用键盘上的上下左右箭头,这个更有方向感。
2) 行内移动
| 命令 | 英文 | 功能 |
|---|---|---|
| w | word | 向后移动一个单词 |
| b | back | 向前移动一个单词 |
| 0 | 行首 | |
| ^ | 行首, 第一个不是空白字符的位置 | |
| $ | 行尾 |
3) 行数移动
| 命令 | 英文 | 功能 |
|---|---|---|
| gg | go | 文件顶部 |
| G | go | 文件末尾 |
| 数字gg | go | 移动到 数字 对应行数 |
| 数字G | go | 移动到 数字 对应行数 |
| : 数字 | 移动到数字对应的 行数 |
4) 屏幕移动
| 命令 | 英文 | 功能 |
|---|---|---|
| Ctrl + b | back | 向上翻页 |
| Ctrl + f | forward | 向下翻页 |
| H | Head | 屏幕顶部 |
| M | Middle | 屏幕中间 |
| L | Low | 屏幕底部 |
5) 选中文本(可视模式)
- 学习 复制 命令前, 应该先学会 怎么样选中 要复制的代码
- 在 vi/vim 中要选择文本, 需要显示 visual 命令切换到 可视模式
- vi/vim 中提供了 三种 可视模式, 可以方便程序员的选择 选中文本的方式
- 按 ESC 可以放弃选中, 返回到 命令模式
| 命令 | 模式 | 功能 |
|---|---|---|
| v | 可视模式 | 从光标位置开始按照正常模式选择文本 |
| V | 可视化模式 | 选中光标经过的完整行 |
| Ctrl + v | 可是块模式 | 垂直方向选中文本 |
6) 撤销和恢复撤销(保命指令)
在学习编辑命令之前,先要知道怎样撤销之前一次 错误的 编辑操作
| 命令 | 英文 | 功能 |
|---|---|---|
| u | undo | 撤销上次的命令(ctrl + z) |
| Ctrl + r | uredo | 恢复撤销的命令 |
7) 删除文本
| 命令 | 英文 | 功能 |
|---|---|---|
| x | cut | 删除光标所在的字符,或者选中的文字 |
| d(移动命令) | delete | 删除移动命令对应的内容 |
| dd | delete | 删除光标所在行, 可以删除多行 |
| D | delete | 删除至行尾 |
提示: 如果使用 可视模式 已经选中了一段文本, 那么无论使用 d 还是 x, 都可以删除选中文本
删除命令可以和移动命令连用, 以下是常见的组合命令(扩展):
| 命令 | 作用 |
|---|---|
| dw | 从光标位置删除到单词末尾 |
| d} | 从光标位置删除到段落末尾 |
| ndd | 从光标位置向下连续删除 n 行 |
8) 复制和剪切
- vi/vim 中提供有一个 被复制文本的缓冲区
- 复制 命令会将选中的文字保存在缓冲区
- 删除 命令删除的文字会被保存在缓冲区
- 在需要的位置, 使用 粘贴 命令可以将缓冲对的文字插入到光标所在的位置
| 命令 | 英文 | 功能 |
|---|---|---|
| yy | copy | 复制行 |
| d(剪切命令) | delete | 剪切 |
| dd(剪切) | delete | 剪切一行, 可以 ndd 剪切n行 |
| p | paste | 粘贴 |
提示:
- 命令 d 、x 类似于图形界面的 剪切操作 – ctrl + x
- 命令 y 类似于 图形界面的 复制操作 – Ctrl +
- 命令 p 类似于图形界面的 粘贴操作 – Ctrl + v
- vi中的文本缓冲区只有一个,如果后续做过 复制、剪切操作, 之前缓冲区中的内容会被替换.
注意
- vi中的 文本缓冲区 和 系统的 剪切板 不是同一个
- 所以在其他软件中使用
Ctrl + C复制的内容, 不能再vi中通过p命令粘贴 - 可以在 编辑模式 下使用 鼠标右键粘贴
9) 替换
| 命令 | 英文 | 功能 | 工作模式 |
|---|---|---|---|
| r | replace | 替换当前字符 | 命令模式 |
| R | replace | 替换当前行光标后的字符 | 替换模式 |
R命令可以进入 替换模式, 替换完成后, 按下ESC, 按下ESC可以回到 命令模式- 替换命令 的作用就是不用进入 编辑模式, 对文件进行 轻量级的修改
10) 缩排和重复执行
| 命令 | 功能 |
|---|---|
| >> | 向右增加缩进 |
| << | 向左减少缩进 |
| . | 重复上次命令 |
- 缩进命令 在开发程序时, 统一增加代码的缩进 比较有用!
- 一次性 在选中代码前增加 4 个空格, 就叫做 增加缩进
- 一次性 在选中代码前删除 4 个空格, 就叫做 较少缩进
- 在 可视模式 下, 缩排命令 主需要使用 一个
>或者<
在程序中, 缩进 通常用来表示代码的归属关系
- 前面空格越少, 代码的级别越高
- 前面空格越多, 代码的级别越低
11) 查找
常规查找
| 命令 | 功能 |
|---|---|
| /str | 查找str |
- 查找到指定内容之后, 使用
Next查找下一个出现的位置n: 查找下一个N: 查找上一个
- 如果不想看到高亮显示, 可以随便查找一个文件中不存在的内容即可
- 单词快速匹配
| 命令 | 功能 |
|---|---|
| * | 向后查找当前光标所在单词 |
| # | 向前查找当前光标所在单词 |
- 在开发中, 通过单词快速匹配, 可以快速看到这个单词在其他位置使用过
12) 查找并替换
- 在
vi/vim中查找和替换命令需要在 末行模式 下执行 - 记忆命令格式
:%s///g
- 全局替换
-
一次向 替换文件中的 所有出现的旧文本
-
命令格式如下
:%s/旧文本/新文本/g
- 可视区域替换
- 先选中 要替换文字的 范围
- 命令格式如下
:s/旧文本/新文本/g
- 确认替换:
c confirm 确认
-
如果把末尾的
g改成gc在替换的时候, 会有提示! 推荐使用 -
命令格式如下
:%s/旧文本/新文本/gc
y-yes替换n-no不替换a-all替换所有q-quit退出替换l-last最后一个, 并把光标移动到行首^E向下滚屏^Y向上滚屏
1.3 echo 命令
echo命令有点类似于我们在java se阶段学习的 System.out.print("hello")
但是,echo还有一个功能就是追加文件内容到文件,类似于我们在java se阶段学习的append文件流写入一样
使用者权限:所有用户
echo string将字符串输出到控制台 , 通常和 重定向 联合使用
echo hello world
# 如果字符串有空格, 为了避免歧义 请增加 双引号 或者 单引号
echo "hello world"
6.3 重定向 >(覆盖) 和 >> (追加)
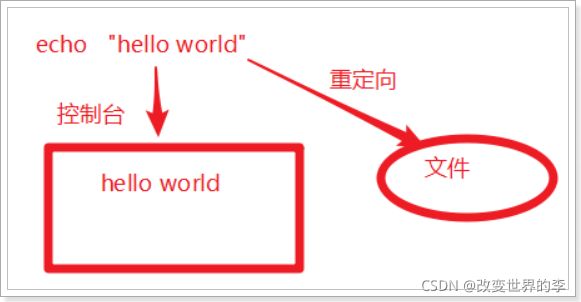
- 默认情况下 命令的结果 输出到 控制台
- 通过 重定向 可以将结果 输出到文件
6.2.3 实现
- 第一步: 将命令的成功结果 覆盖 指定文件内容
echo XXX >czbk-txt.txt
执行结果如下(czbk-txt.txt文件如果没有会自动创建)

| 命令 | 作用 |
|---|---|
| 结果 > 文件名 | > 表示输出, 会覆盖文件的原有内容 |
-
第二步: 将命令的成功结果 追加 指定文件的后面
echo 程序员 >> czbk-txt.txt
执行结果如下

| 命令 | 作用 |
|---|---|
| 命令 >> 文件名 | >> 表示追加, 会将内容追加到已有文件的末尾 |
-
第三步: 将命令的失败结果 追加 指定文件的后面
cat 不存在的目录 &>> error.log
执行效果如下

| 命令 | 作用 |
|---|---|
命令 &>> 文件 |
&>> 表示不区分错误类型 都放到 日志中 |
总结
- 通过
命令 > 文件将命令的成功结果 覆盖 指定文件内容- 通过
命令 >> 文件将命令的成功结果 追加 指定文件的后面- 通过
命令 &>> 文件将 命令的失败结果 追加 指定文件的后面
1.4 awk命令
AWK是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫AWK是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
具体语法如下
awk [选项参数] 'script' var=value file(s)
或
awk [选项参数] -f scriptfile var=value file(s)
1、数据准备:czbk-txt.txt文本内容如下:
zhangsan 68 99 26
lisi 98 66 96
wangwu 38 33 86
zhaoliu 78 44 36
maq 88 22 66
zhouba 98 44 46
2、搜索含有 zhang 和 li 的学生成绩:
cat czbk-txt.txt | awk '/zhang|li/'
执行效果如下

指定分割符, 根据下标显示内容
| 命令 | 含义 |
|---|---|
| awk -F ‘,’ ‘{print $1, $2, $3}’ 文件 | 操作1.txt文件, 根据 逗号 分割, 打印 第一段 第二段 第三段 内容 |
选项
| 选项 | 英文 | 含义 |
|---|---|---|
-F ',' |
field-separator | 使用 指定字符 分割 |
$ + 数字 |
获取第几段内容 | |
$0 |
获取 当前行 内容 | |
NF |
field | 表示当前行共有多少个字段 |
$NF |
代表 最后一个字段 | |
$(NF-1) |
代表 倒数第二个字段 | |
NR |
代表 处理的是第几行 |
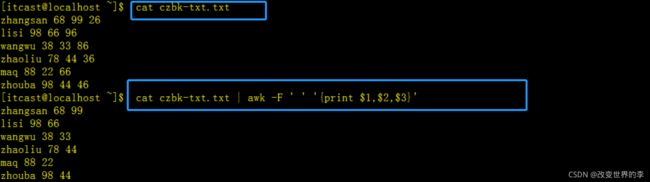
# 查看文档内容
cat czbk-txt.txt
#直接输出
cat score.txt | awk -F ' ' '{print $1,$2,$3}'
执行效果如下
指定分割符, 根据下标显示内容
| 命令 | 含义 |
|---|---|
| awk -F ’ ’ ‘{OFS="==="}{print $1, $2, $3}’ 1.txt | 操作1.txt文件, 根据 逗号 分割, 打印 第一段 第二段 第三段 内容 |
选项
| 选项 | 英文 | 含义 |
|---|---|---|
OFS="字符" |
output field separator | 向外输出时的段分割字符串 |
| 转义序列 | 含义 |
|---|---|
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 制表符 |
# 按照 === 进行分割, 打印 第一段 第二段 第三段
cat czbk-txt.txt | awk -F ' ' '{OFS="==="}{print $1,$2,$3}'
# 按照 制表符tab 进行分割, 打印 第一段 第二段 第三段
cat czbk-txt.txt| awk -F ' ' '{OFS="\t"}{print $1,$2,$3}'
执行效果如下


调用 awk 提供的函数
| 命令 | 含义 |
|---|---|
| awk -F ‘,’ ‘{print toupper($2)}’ 1.txt | 操作1.txt文件, 根据 逗号 分割, 打印 第一段 第二段 第三段 内容 |
常用函数如下:
| 函数名 | 含义 | 作用 |
|---|---|---|
| toupper() | upper | 字符 转成 大写 |
| tolower() | lower | 字符 转成小写 |
| length() | length | 返回 字符长度 |
# 打印第一段内容
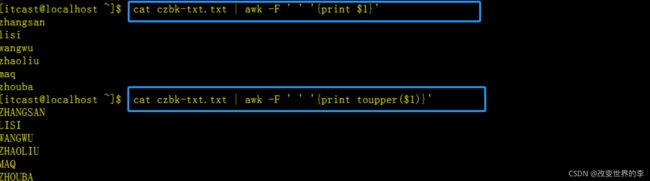
cat czbk-txt.txt | awk -F ' ' '{print $1}'
# 将第一段内容转成大写 且 显示
cat czbk-txt.txt | awk -F ' ' '{print toupper($1)}'
执行效果如下
求指定学科平均分
| 命令 | 含义 |
|---|---|
| awk ‘BEGIN{初始化操作}{每行都执行} END{结束时操作}’ 文件名 | BEGIN{ 这里面放的是执行前的语句 } {这里面放的是处理每一行时要执行的语句} END {这里面放的是处理完所有的行后要执行的语句 } |
查看czbk-txt.txt 文件内容
cat czbk-txt.txt
执行效果如下

查看总分
注意:这里计算的是第4列的总分
cat czbk-txt.txt| awk -F ' ' 'BEGIN{}{total=total+$4} END{print total}'
执行效果如下

查看总分, 总人数
注意:这里计算的是第4列的
cat czbk-txt.txt| awk -F ' ' 'BEGIN{}{total=total+$4} END{print total, NR}'
执行效果如下
![]()
查看总分, 总人数, 平均分
注意:这里计算的是第4列的
cat czbk-txt.txt | awk -F ' ' 'BEGIN{}{total=total+$4} END{print total, NR, (total/NR)}'
执行效果如下
![]()
总结
awk在使用过程中主要用作分析
简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理
1.5 软连接
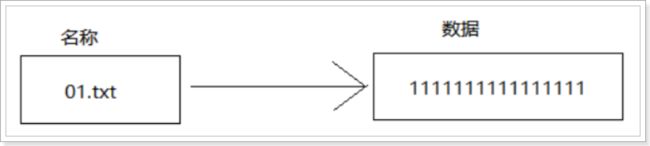
软连接其实就类似于我们在Windows中的【快捷方式】
-
在Linux文件名 和 内容 是两个文件, 分开的!
-
创建软链接的原理, 如下
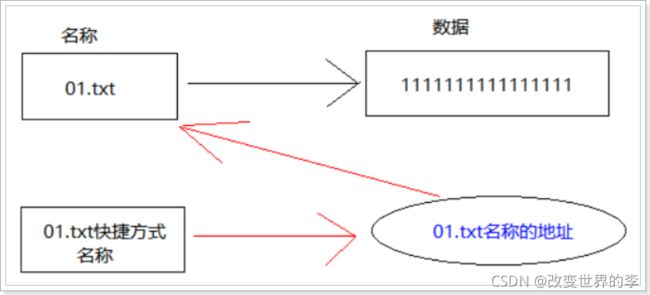
为什么有软连接?
因为 某些文件和目录 的 路径很深, 所以 需要增加 软链接(快捷方式)
使用者权限:所有用户
语法如下:
| 命令 | 英文 | 作用 |
|---|---|---|
| ln -s 目标文件绝对路径 快捷方式路径 | link | 给目标文件增加一个软链接, 通俗讲就是快捷方式 |
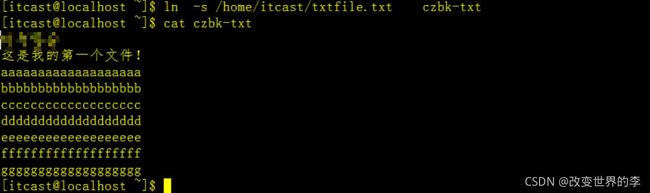
给home/itcast/txtfile.txt文件增加软连接
ln -s /home/itcast/txtfile.txt czbk-txt
上面;我们将/home/itcast/路径下的txtfile.txt文件增加软连接到
czbk-txt,然后通过cat 访问czbk-txt也是可以正常访问的
如下图
总结
通过 `ln -s 源文件的绝对路径 其实就是给目标文件 增加 快捷方式
1.6 find查找
引子
find命令类似与在Windows中全局查找(如下图)

find概念
find命令用来在指定目录下查找文件。
任何位于参数之前的字符串都将被视为欲查找的目录名。如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
语法
find <指定目录> <指定条件> <指定内容>
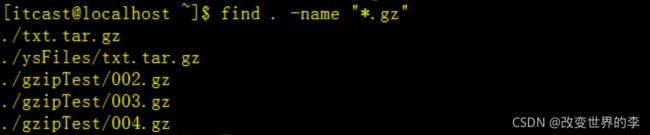
1、将目前目录及其子目录下所有延伸档名是 gz 的文件查询出来
find . -name "*.gz"
执行效果如下图
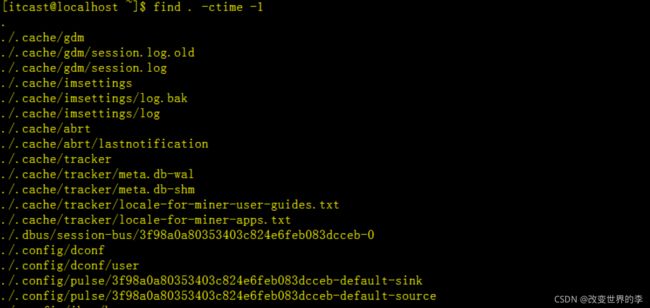
2、将目前目录及其子目录下所有最近 1天内更新过的文件查询出来
find . -ctime -1
执行效果如下
3、全局搜索czbk
/代表是全盘搜索,也可以指定目录搜索
find / -name 'czbk'
执行效果如下

1.7 read命令
注意:
read命令属于文件范畴的命令
在下面的演示中,会涉及到shell,shell章节在最后一章
建议:讲解shell的时候在回过来说下read命令的语法
我们在综合案例中也会降到read
引子:
read命令相当于在java SE阶段我们学习的键盘录入输入Scanner(read命令会比Scanner更强大),开发人员可以动态的与程序交互,
read命令用于从标准输入读取数值。
read 内部命令被用来从标准输入读取单行数据。这个命令可以用来读取键盘输入,当使用重定向的时候,可以读取文件中的一行数据。
语法
read [-ers] [-a aname] [-d delim] [-i text] [-n nchars] [-N nchars] [-p prompt] [-t timeout] [-u fd] [name ...]
1、简单读取
#!/bin/bash
echo "请您输入网站名: "
#读取从键盘的输入
read website
echo "你输入的网站名是 $website"
exit 0 #退出
执行效果如下

3、读取文件
每次调用 read 命令都会读取文件中的 “一行” 文本。当文件没有可读的行时,read 命令将以非零状态退出。
我们可以使用 cat 命令将结果直接传送给包含 read 命令的 while 命令。
测试文件 test.txt 内容如下:
AAAAAAAAAAAAAAAAAAAAAA
BBBBBBBBBBBBBBBBBBBBBB
CCCCCCCCCCCCCCCCCCCCCC
DDDDDDDDDDDDDDDDDDDDDD
================XXX
脚本如下,可以将脚本放到xxx.sh中进行执行
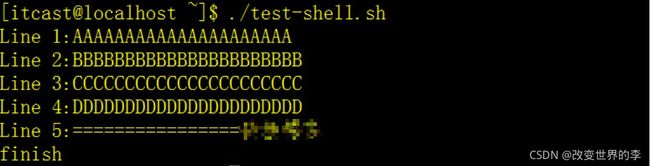
#!/bin/bash
count=1
cat test.txt | while read line
# cat 命令的输出作为read命令的输入,read读到>的值放在line中
do
echo "Line $count:$line"
count=$[ $count + 1 ] # 注意中括号中的空格。
done
echo "finish"
exit 0
执行效果如下
总结
由此可看read命令不仅可以读取键盘输入,而且还可以读取静态文件
1.8 总结
文件命令是我们在开发过程中最经常使用的到的命令,所以,我们在学习过程中一定要认真学习文件的常用命令,比如文件创建、编写、读取命令。
2 Linux备份压缩
在Windows中我们对于一个大文件进行压缩的时候,通常会使用第三方工具,比如360压缩、快压等工具,把一个文件压缩成.zip格式的压缩文件;而在Linux中我们也可以通过各种命令实现压缩的功能。
2.1 gzip命令
压缩/解压缩文件,不能压缩目录
windows下接触的压缩文件大多是.rar,.7z格式,Linux下,不能识别这种格式。
.zip格式的文件在Windows和Linux下都能使用。
压缩文件,能节省磁盘空间,传输时能节省网络带宽
gzip命令用于压缩文件。
gzip是个使用广泛的压缩程序,文件经它压缩过后,其名称后面会多出".gz"的扩展名
使用者权限:所有用户
语法
gzip[参数][文件或者目录]
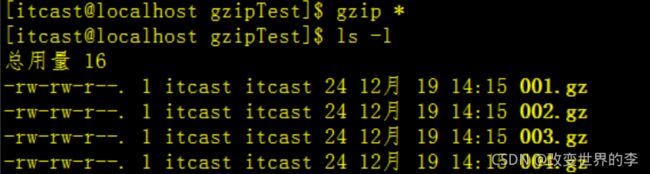
1、压缩目录下的所有文件
数据准备,新建一个目录,里面随便新建4个文件
mkdir gzipTest
cd gzipTest/
touch 001
touch 002
touch 003
touch 004
执行效果如下

1、压缩目录下的所有文件
gzip *
2、 列出详细的信息
解压文件并列出详细信息
gzip -dv *
执行效果如下图

2.2 gunzip命令
gunzip是个使用广泛的解压缩程序,它用于解开被gzip压缩过的文件
gunzip命令用于解压文件。
语法
gunzip[参数][文件或者目录]
gunzip 001.gz
执行效果如下图

001为解压后的文件
2.3 tar命令
tar的主要功能是打包、压缩和解压文件。
tar本身不具有压缩功能。他是调用压缩功能实现的 。
使用者权限:所有用户
语法
tar[必要参数][选择参数][文件]
1、将 txtfile.txt文件打包(仅打包,不压缩)
txtfile.txt文件为上面章节的例子
tar -cvf txt.tar txtfile.txt
执行效果如下
![]()
2、将 txtfile.txt文件打包压缩(打包压缩(gzip))
tar -zcvf txt.tar.gz txtfile.txt
执行效果如下

总结
参数 f 之后的文件档名是自己取的,我们习惯上都用 .tar 来作为辨识。 如果加 z 参数,则以 .tar.gz 或 .tgz 来代表 gzip 压缩过的 tar包
3、查看tar中有哪些文件
tar -ztvf txt.tar.gz
执行效果如下

压缩包中的文件有txtfile.txt
4、将tar 包解压缩
1.新建目录
mkdir ysFiles
2.复制
cp txt.tar.gz ./ysFiles/
3.解压缩
tar -zxvf /home/itcast/ysFiles/txt.tar.gz
解压后的文件如下

2.4 zip命令
引子
zip命令就完全的相当于在Windows下面选中文件右键进行压缩了
zip命令用于压缩文件。
zip是个使用广泛的压缩程序,文件经它压缩后会另外产生具有".zip"扩展名的压缩文件。
使用者权限:所有用户
语法
zip[必要参数][选择参数][文件]
将上面/home/itcast/gzipTest 这个目录下所有文件和文件夹打包为当前目录下的 zFiles.zip:
1.在目录下新建一个005目录
mkdir 005
执行效果如下
开始压缩
2.压缩
zip -q -r zFiles.zip *
执行效果如下
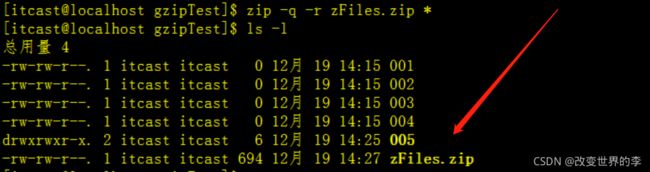
zFiles.zip文件就是我们刚刚压缩后的文件
2.5 unzip命令
引子
unzip命令就完全的相当于在Windows下面选中文件右键进行解压缩了
Linux unzip命令用于解压缩zip文件
unzip为.zip压缩文件的解压缩程序
使用者权限:所有用户
语法
unzip[必要参数][选择参数][文件]
参数:
上接上面的zip的例子
1、查看压缩文件中包含的文件:
unzip -l zFiles.zip
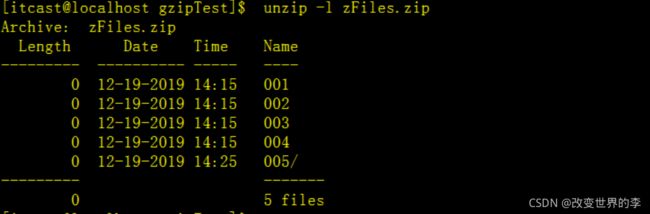
包含了压缩文件里面文件的详细信息
文件大小 日期 时间 文件名称
总数量和总大小
2、如果要把文件解压到指定的目录下,需要用到-d参数
1.新建目录
unFiles
2.解压缩
unzip -d ./unFiles zFiles.zip
执行效果如下
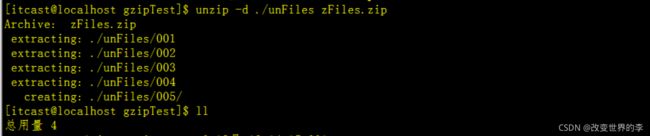
查看解压后的文件,如下图
2.6 bzip2命令
引子
".bz2"格式是 Linux 的另一种压缩格式,从理论上来讲,".bz2"格式的算法更先进、压缩比更好;而 咱们上面学到的".gz"格式相对来讲时间更快
在使用过程中可以根据需求自由选择
bzip2命令是.bz2文件的压缩程序。
bzip2采用新的压缩演算法,压缩效果比传统的LZ77/LZ78压缩演算法来得好。若没有加上任何参数,bzip2压缩完文件后会产生.bz2的压缩文件,并删除原始的文件。
使用者权限:所有用户
语法
bzip2 [-cdfhkLstvVz][--repetitive-best][--repetitive-fast][- 压缩等级][要压缩的文件]
1、压缩文件
1.创建目录
mkdir bzFiles
cd ./bzFiles/
2.创建文件
touch 001
3.压缩
bzip2 001
ll
执行效果如下

如上图001.bz2就是压缩后的文件
2.7 bunzip2命令
引子
Linux bunzip2命令是.bz2文件的解压缩程序。
使用者权限:所有用户
语法:
bunzip2 [-fkLsvV][.bz2压缩文件]
参数:
解压.bz2文件
bunzip2 -v 001.bz2
执行效果如下图

001文件即是被解压后的
2.8 总结
gz:由gzip压缩工具压缩的文件。
.bz2:由bzip2压缩工具压缩的文件。
.tar:由tar打包程序打包的文件(tar没有压缩功能,只是把一个 目录合并成一个文件)
.tar.gz:可理解为先由tar打包,再由gz压缩。
.zip:可理解为由zip压缩工具直接压缩
3 网络与磁盘管理
Tips:
重点讲解内容
3.1 网络命令
3.1.1 ifconfig命令
引子:
ifconfig命令有点类似于Windows的ipconfig命令
ifconfig是Linux中用于显示或配置网络设备的命令,英文全称是network interfaces configuring
ifconfig命令用于显示或设置网络设备。
ifconfig可设置网络设备的状态,或是显示目前的设置。
使用者权限:所有(设置级别的需要管理员)用户
语法
ifconfig [网络设备][down up -allmulti -arp -promisc][add<地址>][del<地址>][<硬件地址>][io_addr][irq][media<网络媒介类型>][mem_start<内存地址>][metric<数目>][mtu<字节>][netmask<子网掩码>][tunnel<地址>][-broadcast<地址>][-pointopoint<地址>][IP地址]
1、显示激活的网卡信息
ifconfig
执行效果如下
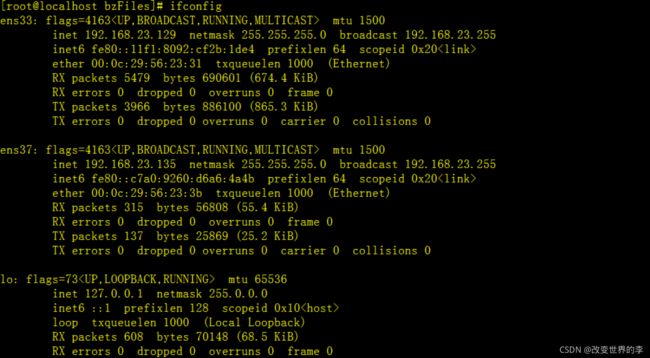

ens33(有的是eth0) 表示第一块网卡。
表示ens33网卡的 IP地址是 192.168.23.129,广播地址,broadcast 192.168.23.255,掩码地址netmask:255.255.255.0 ,inet6对应的是ipv6
ens37 表示第二块网卡
lo 是表示主机的回坏地址,这个一般是用来测试一个网络程序,但又不想让局域网或外网的用户能够查看,只能在此台主机上运行和查看所用的网络接口
启动关闭指定网卡
virbr0是一种虚拟网络接口
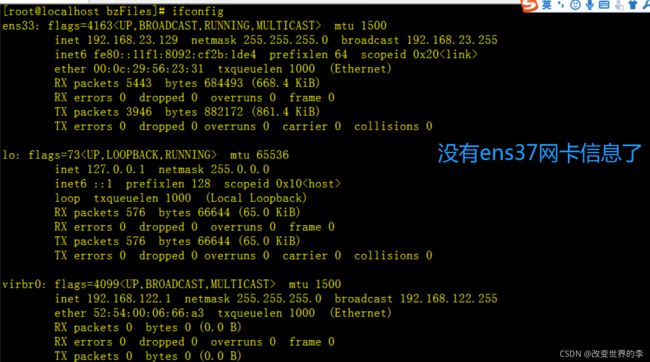
2、关闭网卡(需要切换到管理员账户)
ifconfig ens37 down
执行效果如下
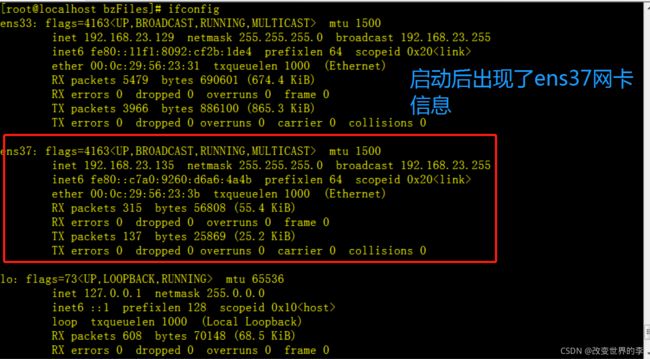
3、启用网卡(需要切换到管理员账户)
ifconfig ens37 up
执行效果如下
4、配置ip信息
// 配置ip地址
ifconfig ens37 192.168.23.199
// 配置ip地址和子网掩码
ifconfig ens37 192.168.23.133 netmask 255.255.255.0
执行效果如下,配置ip地址:
![]()
查看ip,如下图
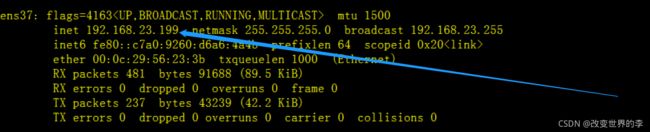
配置ip地址和子网掩码,执行效果如下图
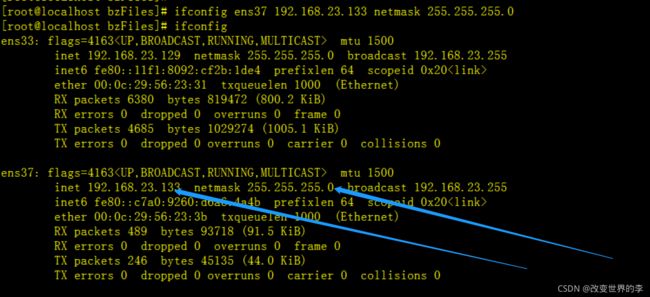
这样的话我们就可以通过命令的方式设置网卡的网络信息了。
3.1.2 ping命令
等价于Windows的ping命令
ping命令用于检测主机。
执行ping指令会使用ICMP传输协议,发出要求回应的信息,若远端主机的网络功能没有问题,就会回应该信息,因而得知该主机运作正常。
使用者权限:所有用户
语法
ping [-dfnqrRv][-c<完成次数>][-i<间隔秒数>][-I<网络界面>][-l<前置载入>][-p<范本样式>][-s<数据包大小>][-t<存活数值>][主机名称或IP地址]
1、检测是否与主机连通
ping www.baidu.com
执行效果如下
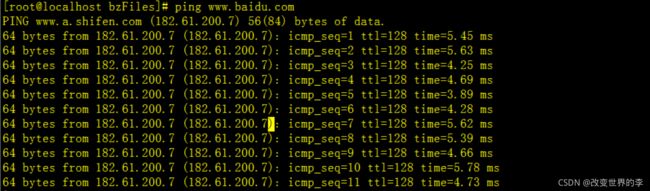
icmp_seq:ping序列,从1开始
ttl:IP生存时间值
time: 响应时间,数值越小,联通速度越快
2、指定接收包的次数
和上面不同的是:收到两次包后,自动退出
ping -c 2 www.baidu.com
执行效果如下图
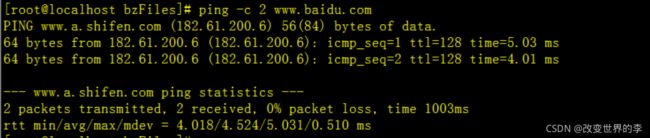
总结:
ping命令也是我们在开发过程中常用到的命令
通常使用 ping xxx.xxx.xxx.xxx命令进行检测本地与目标机器是否连通
3.1.3 netstat命令
利用netstat指令可让你得知整个Linux系统的网络情况
netstat命令用于显示网络状态。
使用者权限:所有用户
语法
netstat [-acCeFghilMnNoprstuvVwx][-A<网络类型>][--ip]
1、显示详细的连接状况
netstat -a
执行效果如下
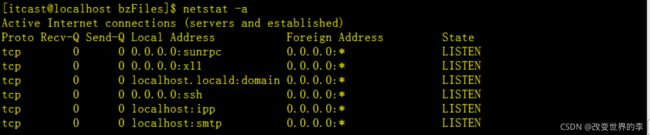
比如上面的【0 0.0.0.0:ssh】它是远程终端连接Linux的ssh服务,默认使用了22端口,它的状态【State】是处于监听状态,属于正常。
2、显示网卡列表
netstat -i
执行效果如下

上图显示的是我们在介绍【ifconfig】命令的时候看到的网卡信息
3.2 磁盘命令
3.2.1 lsblk命令
使用lsblk命令可以以tree的形式展示所有设备的信息
lsblk命令的英文是“list block”,即用于列出所有可用块设备的信息,而且还能显示他们之间的依赖关系,但是它不会列出RAM盘的信息。
语法格式: lsblk [参数]
使用者权限:所有用户
1、lsblk命令默认情况下将以树状列出所有块设备:
lsblk
执行效果如下图

NAME : 这是块设备名。
MAJ:MIN : 本栏显示主要和次要设备号。
RM : 本栏显示设备是否可移动设备。注意,在上面设备sr0的RM值等于1,这说明他们是可移动设备。
SIZE : 本栏列出设备的容量大小信息。
RO : 该项表明设备是否为只读。在本案例中,所有设备的RO值为0,表明他们不是只读的。
TYPE :本栏显示块设备是否是磁盘或磁盘上的一个分区。在本例中,sda和sdb是磁盘,而sr0是只读存储(rom)。
MOUNTPOINT : 本栏指出设备挂载的挂载点。
2、默认选项不会列出所有空设备:
lsblk -f
执行效果如下图
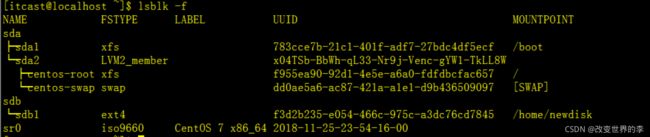
NAME表示设备名称
FSTYPE表示文件类型
LABEL表示设备标签
UUID设备编号
MOUNTPOINT表示设备的挂载点
注意
我们学习这个命令主要是在下面将要学习的fdisk分区中会经常使用到
3.2.2 df命令
引子(如下图):
Linux的df命令类似于在Windows中的【计算机】--【管理】--【磁盘管理】菜单对磁盘的统计情况查看
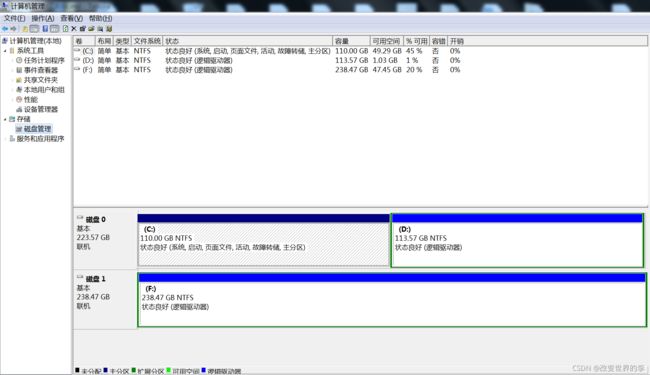
df命令用于显示目前在Linux系统上的文件系统的磁盘使用情况统计。
使用者权限:所有用户
语法
df [选项]... [FILE]...
1、显示磁盘使用情况统计情况
df
执行效果如下图
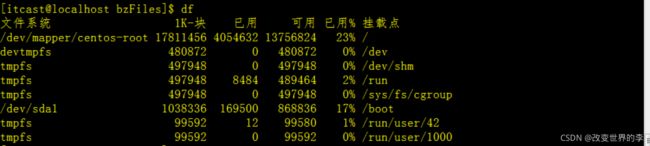
第一列指定文件系统的名称
第二列指定一个特定的文件系统1K-块1K是1024字节为单位的总容量。
已用和可用列分别指定的容量。
最后一个已用列指定使用的容量的百分比
最后一栏指定的文件系统的挂载点。
2、df命令也可以显示磁盘使用的文件系统信息
比如我们df下之前创建过的目录gzipTest的使用情况
df gzipTest/
执行效果如下图

3、df显示所有的信息
df --total
执行效果如下图
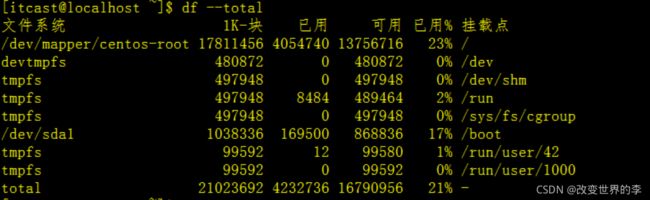
我们看到输出的末尾,包含一个额外的行,显示总的每一列。
4、df换算后显示
df -h
执行效果如下图
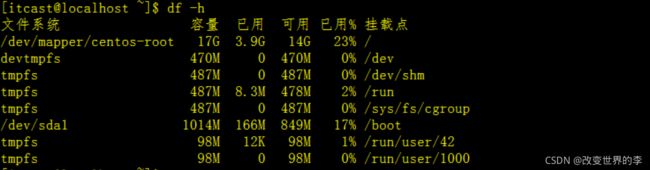
我们可以看到输出显示的数字形式的’G’(千兆字节),“M”(兆字节)和"K"(千字节)。
这使输出容易阅读和理解,从而使显示可读的。请注意,第二列的名称也发生了变化,为了使显示可读的"容量"。
3.2.3 mount命令
在Linux当中所有的存储设备如u盘、光盘、硬盘等,都必须挂载之后才能正常使用。
其实挂载可以理解为Windows当中的分配盘符(重要),只不过windows当中是以英文字母ABCD等作为盘符,而linux是拿系统目录作为盘符,当然linux当中也不叫盘符,而是称为挂载点,而把为分区或者光盘等存储设备分配一个挂载点的过程称为挂载
mount命令是经常会使用到的命令,它用于挂载Linux系统外的文件。
挂载概念
在安装linux系统时设立的各个分区,如根分区、/boot分区等都是自动挂载的,也就是说不需要我们人为操作,开机就会自动挂载。但是光盘、u盘等存储设备如果需要使用,就必须人为的进行挂载。
其实我们在windows下插入U盘也是需要挂载(分配盘符)的,只不过windows下分配盘符是自动的
Linux中的根目录以外的文件要想被访问,需要将其“关联”到根目录下的某个目录来实现,这种关联操作就是“挂载”,这个目录就是“挂载点”,解除次关联关系的过程称之为“卸载”。
注意:“挂载点”的目录需要以下几个要求:
(1)目录事先存在,可以用mkdir命令新建目录;
(2)挂载点目录不可被其他进程使用到;
(3)挂载点下原有文件将被隐藏。
使用者权限:所有用户,设置级别的需要管理员
语法
mount [-hV]
mount -a [-fFnrsvw] [-t vfstype]
mount [-fnrsvw] [-o options [,...]] device | dir
mount [-fnrsvw] [-t vfstype] [-o options] device dir
需求:
比如现在我们要通过挂载的方式查看Linux CD/DVD光驱里面的内容
1、CD/DVD设置
进入【虚拟机】–【设置】
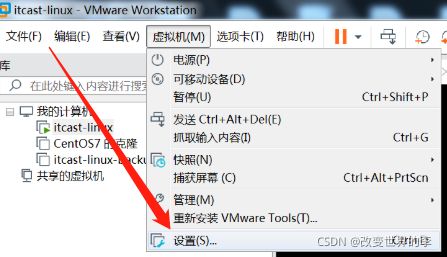
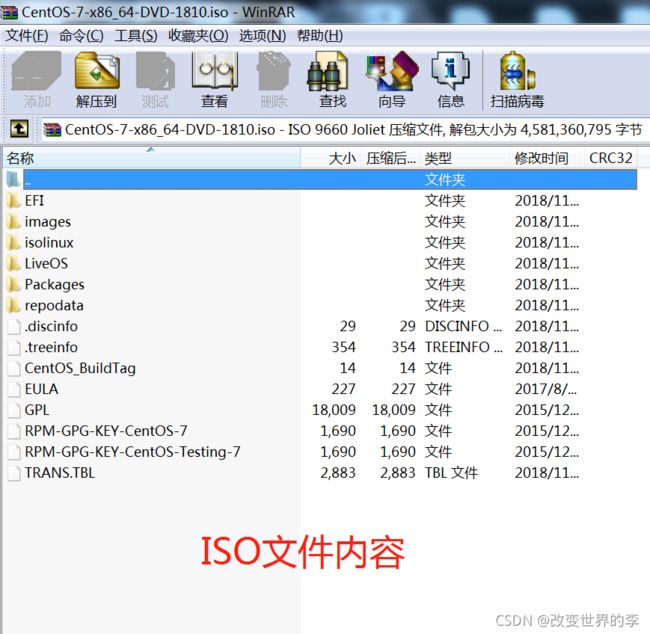
设置CD/DVD的内容,我们这里使用的是F:\CentOS-7-x86_64-DVD-1810.iso

查看F:\CentOS-7-x86_64-DVD-1810.iso;里面的内容
2、创建挂载点
注意:一般用户无法挂载cdrom,只有root用户才可以操作
我们切换到root下创建一个挂载点(其实就是创建一个目录)
mkdir -p mnt/cdrom
3、开始挂载
通过挂载点的方式查看上面的【ISO文件内容】
mount -t auto /dev/cdrom /mnt/cdrom
执行效果如下
![]()
表示挂载成功
4、查看挂载点内容
ls -l -a ./mnt/cdrom/
执行效果如下图

如上图所示,我们通过挂载点查看CD/DVD的文件个数是14个,和上面的【ISO文件内容】个数一致。
5、卸载cdrom
在前面我们将CD/DVD挂载到了文件系统,如果我们不用了,就可以将其卸载掉
umount ./mnt/cdrom/
执行效果如下图

我们发现卸载后,通过挂载点就无法查看CD/DVD里面的数据了。
3.3 总结
关于挂载:用户不能直接访问 硬件设备需要将硬件设备 挂载 到 系统目录上, 才可以让用户访问。
4 shell与安装
tips
重点讲解内容
4.1 yum使用
引子:
yum类似于开发工具idea、eclipse中的在线插件安装商店
我们输入一个将要安装的插件名字,进行搜索、安装的过程。
yum概念
yum( Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器。
yum提供了查找、安装、删除某一个、一组甚至全部软件包的命令,而且命令简洁而又好记。
yum原理
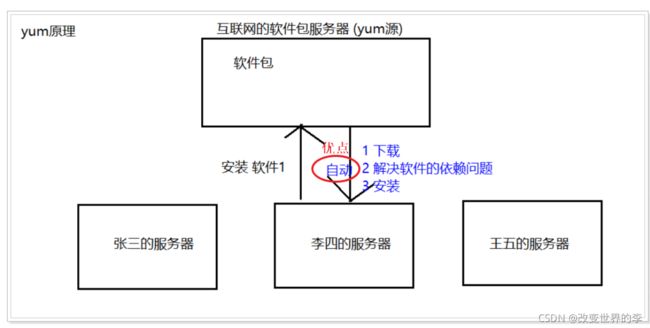
注意:必须联网
不同的服务通过yum命令连接远程yum源进行查找、下载、安装
使用者权限:管理员
语法
yum [options] [command] [package ...]
- options: 可选,选项包括-h(帮助),-y(当安装过程提示选择全部为"yes"),-q(不显示安装的过程)等等。
- command: 要进行的操作。
- package操作的对象。
yum常用命令
- 1.列出所有可更新的软件清单命令:yum check-update
- 2.更新所有软件命令:yum update
- 3.仅安装指定的软件命令:yum install
- 4.仅更新指定的软件命令:yum update
- 5.列出所有可安裝的软件清单命令:yum list
- 6.删除软件包命令:yum remove
- 7.查找软件包 命令:yum search
- 8.清除缓存命令:
- yum clean packages: 清除缓存目录下的软件包
- yum clean headers: 清除缓存目录下的 headers
- yum clean oldheaders: 清除缓存目录下旧的 headers
- yum clean, yum clean all (= yum clean packages; yum clean oldheaders) :清除缓存目录下的软件包及旧的headers
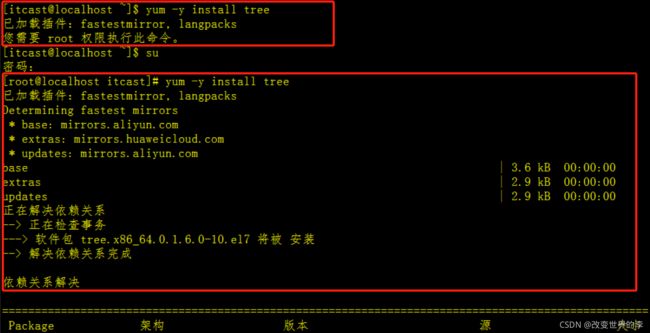
4.1.1 安装tree
yum -y install tree //y当安装过程提示选择全部为"yes"
执行效果如下
注意:第一次在itcast用户执行的时候
提示我们【需要管理员权限】
安装完执行tree命令
tree

4.1.2 移除tree
yum remove tree
执行效果如下
此时,我们在执行tree命令
tree
执行效果如下

如上图,由于我们移除了tree,在执行tree命令的时候发现找不到这个命令了。
4.1.3 yum查找
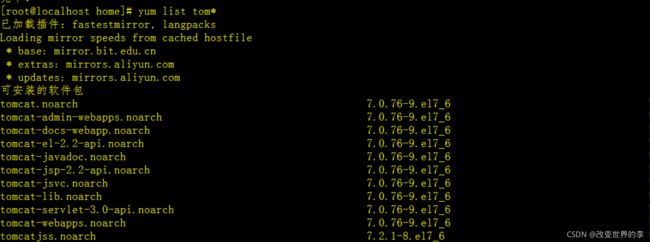
利用 yum 的功能,找出以 tom 为开头的软件名称有哪些
yum list tom*
执行效果如下
4.1.4 yum源
概述
yum需要一个yum库,也就是yum源。
简单的说,我们安装软件的时候需要下载软件,将很多软件放在一起就是源。软件安装包的来源,所以yum源就是软件安装包来源
yum源分类
目前,yum默认使用的是CentOS的yum源,如下
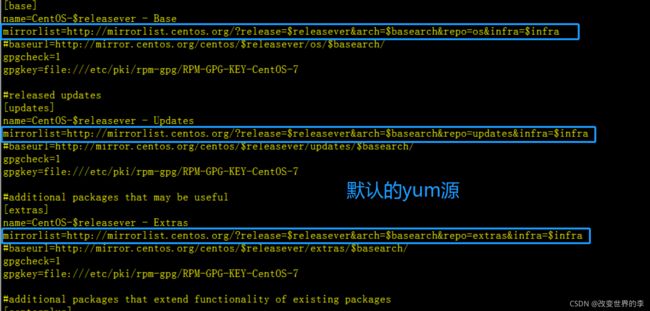

目前,国内有很多不错的yum源,比如阿里、网易、搜狐等
安装阿里yum源
因为默认的yum源服务器在国外,我们在安装软件的时候会受到速度的影响,所以安装国内yum源在下载的时候速度、稳定性会比国外的好很多。
1) 安装wget
yum install -y wget
执行效果如下

安装成功。
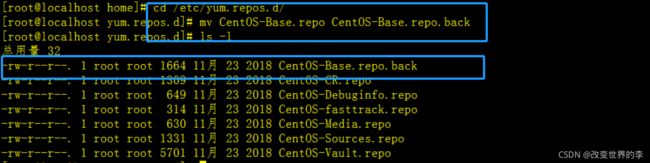
2) 备份/etc/yum.repos.d/CentOS-Base.repo文件
cd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo.back
执行效果如下图
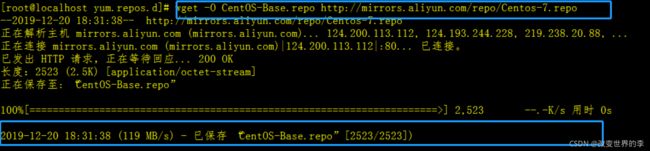
3) 下载阿里云的Centos-7.repo文件
wget -O CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
注意
上面的url中要卸载Centos-7.repo;而不是Centos-6.repo
执行效果如下图
查看下载的阿里云的Centos-6.repo文件
cat CentOS-Base.repo
执行效果如下
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[base]
name=CentOS-$releasever - Base - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/os/$basearch/
http://mirrors.aliyuncs.com/centos/$releasever/os/$basearch/
http://mirrors.cloud.aliyuncs.com/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#released updates
[updates]
name=CentOS-$releasever - Updates - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/updates/$basearch/
http://mirrors.aliyuncs.com/centos/$releasever/updates/$basearch/
http://mirrors.cloud.aliyuncs.com/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/extras/$basearch/
http://mirrors.aliyuncs.com/centos/$releasever/extras/$basearch/
http://mirrors.cloud.aliyuncs.com/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/centosplus/$basearch/
http://mirrors.aliyuncs.com/centos/$releasever/centosplus/$basearch/
http://mirrors.cloud.aliyuncs.com/centos/$releasever/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
#contrib - packages by Centos Users
[contrib]
name=CentOS-$releasever - Contrib - mirrors.aliyun.com
failovermethod=priority
baseurl=http://mirrors.aliyun.com/centos/$releasever/contrib/$basearch/
http://mirrors.aliyuncs.com/centos/$releasever/contrib/$basearch/
http://mirrors.cloud.aliyuncs.com/centos/$releasever/contrib/$basearch/
gpgcheck=1
enabled=0
gpgkey=http://mirrors.aliyun.com/centos/RPM-GPG-KEY-CentOS-7
如上面的命令,之前是【CentOS】,现在是【aliyun】
4) 重新加载yum
yum clean all
清理之前(CentOS)的缓存
执行效果如下

yum makecache
就是把服务器的包信息下载到本地电脑缓存起来,makecache建立一个缓存,以后用install时就在缓存中搜索,提高了速度。
执行效果如下

如上图,元数据缓存已建立,缓存成功。
5、验证yum源使用
yum search tomcat
执行效果如下
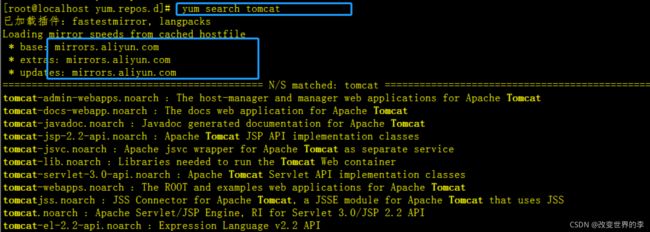
如上图所示,我们发现,现在查找软件信息使用了上面的yum缓存。
Loading mirror speeds from cached hostfile(从缓存的主机文件加载镜像速度)
- base: mirrors.aliyun.com
- extras: mirrors.aliyun.com
- updates: mirrors.aliyun.com
总结
yum -y install 软件包
卸载软件
yum -y remove 软件包查找软件
yum list *
yum源
版本:
比如我们使用的是CentOS7,在下载CentOS-Base.repo的时候要注意它的版本。
4.2 rpm使用
RPM包管理类似于windows下的“添加/删除程序”但是功能却比“添加/删除程序”强大很多
1、rpm介绍
rpm(redhat package manager) 原本是 Red Hat Linux 发行版专门用来管理 Linux 各项套件的程序,由于它遵循 GPL 规则且功能强大方便,因而广受欢迎。逐渐受到其他发行版的采用。RPM 套件管理方式的出现,让 Linux 易于安装,升级,间接提升了 Linux 的适用度。
2、rpm与yum区别
rpm 只能安装已经下载到本地机器上的rpm 包. yum能在线下载并安装rpm包,能更新系统,且还能自动处理包与包之间的依赖问题,这个是rpm 工具所不具备的。
语法如下:
用法: rpm [选项...]
rpm包
注意:
以上为扩展名为.rpm的包
可以理解成是Windows中的.exe文件
安装rpm软件包
rpm -ivh 软件全包名
卸载rpm软件包
rpm -e 软件全包名
列出所有安装过的包
rpm -qa
查询软件包信息
rpm -qi 软件全包名
查看文件安装位置
rpm -ql 软件全包名
4.3 shell使用
shell脚本类似于我们在Windows中编写的批处理文件,它的扩展名是.bat,比如我们启动Tomcat(后面的课程我们会详细讲解)的时候经常启动的startup.bat,就是Windows下的批处理文件。
而在Linux中,shell脚本编写的文件是以.sh结尾的。比如Tomcat下我们经常使用startup.sh来启动我们的Tomcat,这个startup.sh文件就是shell编写的。
4.3.1 shell入门
通过简单的学习,我们编写一个简单的入门shell程序。
我们通过前面学习的echo命令,在shell脚本中打印出一句话。
1) 什么是shell
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。
Shell 脚本(Shell Script)又称 Shell 命令稿、程序化脚本,是一种计算机程序使用的文本文件,内容由一连串的 shell 命令组成,经由 Unix Shell 直译其内容后运作

Shell 被当成是一种脚本语言来设计,其运作方式与解释型语言相当,由 Unix shell 扮演命令行解释器的角色,在读取 shell 脚本之后,依序运行其中的 shell 命令,之后输出结果。利用 shell 脚本可以进行系统管理,文件操作等。
在 Unix 及所有的系统中,如 Linux、FreeBSD 等操作系统,都存在 shell 脚本。依照 Unix shell 的各种不同类型,shell 脚本也有各种不同方言。在 DOS、OS/2、Microsoft Windows 中的批处理文件,跟 shell 脚本有类似的功能。
2) shell环境
java需要虚拟机解释器, 同理 shell脚本也需要解释器
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
查看解释器
cat /etc/shells
执行效果如下
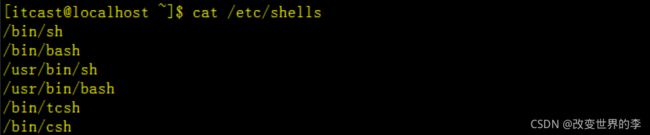
Linux 的 Shell 种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- Bourne Again Shell(/bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
- 等等……
我们当前课程使用的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell
3) 编写第一个shell
现在,我们打开文本编辑器(我们也可以使用 vi/vim 命令来创建文件),新建一个文件 czbk.sh,扩展名为 sh(sh代表shell):
#!/bin/bash --- 指定脚本解释器
echo "你好,XXX !"
//写shell的习惯 第一行指定解释器
//文件是sh为后缀名
//括号成对书写
//注释的时候尽量不用中文注释。不友好。
//[] 括号两端要要有空格。 [ neirong ]
//习惯代码索引,增加阅读性
//写语句的时候,尽量写全了,比如if。。。
1、创建sh文件**
vim czbk.sh
2、编写并保存

3、查看czbk.sh文件
ls -l

如上图,我们发现刚刚编写的czbk.sh文件的的权限是【-rw-rw-r–】,通过我们之前学过的知识,我们发现这个文件并没有执行的权限
我们需要将czbk.sh文件设置下它的执行权限【x】,如果不设置有执行权限,当前的文件不具备文件执行的能力。
通过chmod设置执行权限
chmod +x ./czbk.sh
执行效果如下

我们发现,czbk.sh拥有了【x】执行权限
下面,我们就开始执行czbk.sh
4、执行czbk.sh文件 — bash a.sh0
./czbk.sh
执行效果如下:
![]()
如上图,我们刚刚编写的shell在执行的时候正常打印出来了,说明czbk.sh具备执行的能力
注意:
#! 是一个约定的标记,它告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。
echo 命令用于向窗口输出文本。
4.3.2 shell注释
引子:
在Java SE课程中,我们也学习了注释
比如单行注释我们使用双斜杠//
多行注释我们使用/**开头表示注释多行
而在shell编程中,我们同样也要有注释,注释掉程序中不用的脚本
1、单行注释
以 # 开头的行就是注释,会被解释器忽略。
通过每一行加一个 # 号设置多行注释,如下:
#--------------------------------------------
# 这是一个注释
#--------------------------------------------
##### 开始 #####
#
#
# 这里可以添加脚本描述信息
#
#
##### 结束 #####
如果在开发过程中,遇到大段的代码需要临时注释起来,过一会儿又取消注释,怎么办呢?
每一行加个#符号太费力了,此时,我们可以通过EOF进行多行注释,如下:
2、多行注释
多行注释还可以使用以下格式:
:<<EOF
注释内容...
注释内容...
注释内容...
EOF
EOF 也可以使用其他符号:
:<<'
注释内容...
注释内容...
注释内容...
'
:<<!
注释内容...
注释内容...
注释内容...
!
总结:
我们将在下面的小章节中使用注释,查看注释效果
4.3.3 shell变量
引子:
这里的变量我们可以理解为我们在Java SE阶段定义的变量,比如在SE中我定义一个字符串类型的变量使用String stringStr="";
注意:下面的演示我们还是继续沿用test-shell.sh进行测试
1、定义变量:
variable_name="czbk"
变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
有效的 Shell 变量名示例如下:
RUNOOB
LD_LIBRARY_PATH
_var
var2
无效的变量命名:
?var=123
user*name=runoob
2、使用变量
使用一个定义过的变量,只要在变量名前面加美元符号即可,如:
variable_name="czbk"
echo $variable_name
echo ${variable_name}
执行效果如下

变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
echo "I am good at ${shell-t}Script"
通过上面的脚本我们发现,如果不给shell-t变量加花括号,写成echo "I am good at s h e l l − t S c r i p t " , 解 释 器 s h e l l 就 会 把 shell-tScript",解释器shell就会把 shell−tScript",解释器shell就会把shell-tScript当成一个变量,由于我们前面没有定义shell-t变量,那么解释器执行执行的结果自然就为空了。这里我们推荐给所有变量加上花括号,这也是一个好的编程习惯。
已定义的变量,可以被重新定义,如:
your_name="tom"
echo $your_name
your_name="frank"
echo $your_name
执行效果如下图
![]()
这样写是合法的,但注意,第二次赋值的时候不能写 y o u r n a m e = " f r a n k " , 使 用 变 量 的 时 候 才 加 your_name="frank",使用变量的时候才加 yourname="frank",使用变量的时候才加。
3、只读变量
这里的只读变量其实有点类似于我们在java se阶段课程中定义的final变量,即在程序的上下文中不允许被程序修改
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bash
myUrl="https://www.baidu.com"
readonly myUrl
myUrl="https://cn.bing.com/"
执行效果如下图
![]()
4、删除变量
使用 unset 命令可以删除变量。语法:
unset variable_name
变量被删除后不能再次使用。unset 命令不能删除只读变量。
示例如下
#!/bin/sh
myUrl="https://www.baidu.com"
unset myUrl
echo $myUrl
执行效果如下图
![]()
如上面的shell脚本,我们定义了一个myUrl变量,通过unset删除这个变量,然后通过echo进行输出,结果是就是为空,没有任何的结果输出。
Shell 字符串
字符串是shell编程中最常用也是最有用的数据类型,字符串可以用单引号,也可以用双引号,也可以不用引号,正如我们开篇提到的,在Java SE中我们定义一个字符串可以通过Stirng stringStr=“abc" 双引号的形式进行定义,而在shel中也是可以的。
单引号
str='this is a string variable'
单引号字符串的限制:
- 单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;
- 单引号字串中不能出现单独一个的单引号(对单引号使用转义符后也不行),但可成对出现,作为字符串拼接使用。
双引号
your_name='frank'
str="Hello, \"$your_name\"! \n"
echo -e $str
输出结果为:
![]()
双引号的优点:
- 双引号里可以有变量
- 双引号里可以出现转义字符
拼接字符串
your_name="frank"
# 使用双引号拼接
greeting="hello, "$your_name" !"
greeting_1="hello, ${your_name} !"
echo $greeting $greeting_1
输出结果为:
![]()
获取字符串长度
string="czbk"
echo ${#string}
输出结果:4.表示长度为4

提取字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
string="abcdefghijklmn"
echo ${string:1:4}
执行效果如下
![]()
输出为【bcde】,通过截取我们发现,它的下标和我们在java中的读取方式是一样的,下标也是从0开始。
4.3.4 shell数组
这里的数组和我们在Java SE阶段的数组结果(或是性质)是一样的,只是定义的过程大同小异
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
定义数组
在 Shell 中,用括号来表示数组,数组元素用"空格"符号分割开。如下:
数组名=(值1 值2 ... 值n)
例如:
array_name=(value0 value1 value2 value3)
或者
array_name=(
value0
value1
value2
value3
)
通过下标定义数组中的其中一个元素:
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuen
可以不使用连续的下标,而且下标的范围没有限制。
读取数组
读取数组元素值的一般格式是:
${数组名[下标]}
例如:
valuen=${array_name[n]}
使用 @ 符号可以获取数组中的所有元素,例如:
echo ${array_name[@]}
获取数组的长度
获取数组长度的方法与获取字符串长度的方法相同,例如:
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
下面,我们通过一个例子,定义数组、提取数组元素的例子来验证下
#! /bin/bash
g=(a b c d e f)
echo "数组下标为2的数据为:" ${g[2]}
echo "数组所有数据为:" ${#g[@]}
echo "数组所有数据为:" ${#g[*]}
如下

执行效果如下:

4.3.5 shell运算符
我们在前面课程中学习Java SE中也学到了运算符,比如算术、关系、布尔等,而在sehll编程中同样也有运算符,虽然表达的方式不一样,但是最终的目的都是一样的,都是为了解决编程中现存问题
Shell 和其他编程一样,支持 包括:算术、关系、布尔、字符串等运算符。
原生 bash 不支持 简单的数学运算,但是可以通过其他命令来实现,例如expr。
expr 是一款表达式计算工具,使用它能完成表达式的求值操作。
例如,两个数相加,我们还是利用上面的例子test-shell.sh
1、算数运算符
val=`expr 2 + 2`
echo "相加之后的结果为:" $val
执行效果如下

注意:
表达式和运算符之间要有空格,例如 2+2 是不对的,必须写成 2 + 2。
完整的表达式要被 ` 包含,注意不是单引号。
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为 30。 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 将把变量 b 的值赋给 a。 |
| == | 相等。用于比较两个数字,相同则返回 true。 | [ $a == $b ] 返回 false。 |
| != | 不相等。用于比较两个数字,不相同则返回 true。 | [ $a != $b ] 返回 true。 |
注意: 条件表达式要放在方括号之间,并且要有空格,例如: [ a = = a== a==b] 是错误的,必须写成 [ $a == $b ]。
下面是运算符shell脚本(还是采用之前的例子test-shell.sh )w
#! /bin/bash
#g=(a b c d e f)
#echo "数组下标为2的数据为:" ${g[2]}
#echo "数组所有数据为:" ${#g[@]}
#echo "数组所有数据为:" ${#g[*]}
:<<EOF
val= `expr 2 + 2`
echo "相加之后的结果为:" $val
EOF
a=4
b=20
echo “加法运算” `expr $a + $b`
echo “减法运算” `expr $a - $b`
echo “乘法运算,注意*号前面需要反斜杠” ` expr $a \* $b`
echo “除法运算” `expr $b / $a`
((a++))
echo "a = $a"
c=$((a + b))
d=$[a + b]
echo "c = $c"
echo "d = $d"
上面的shell命令#开头的为单行注释
:<
执行效果如下

2、字符串运算符
下表列出了常用的字符串运算符,假定变量 a 为 “abc”,变量 b 为 “efg”:
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否为0,不为0返回 true。 | [ -n “$a” ] 返回 true。 |
| $ | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
字符串运算符实例如下(还是采用之前的例子test-shell.sh ):
a="abc"
b="efg"
if [ $a = $b ]
then
echo "$a = $b : a 等于 b"
else
echo "$a = $b: a 不等于 b"
fi
if [ $a != $b ]
then
echo "$a != $b : a 不等于 b"
else
echo "$a != $b: a 等于 b"
fi
执行效果如下
![]()
3、关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
下表列出了常用的关系运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
关系运算符(还是采用之前的例子test-shell.sh )
a=10
b=20
if [ $a -eq $b ]
then
echo "$a -eq $b : a 等于 b"
else
echo "$a -eq $b: a 不等于 b"
fi
if [ $a -ne $b ]
then
echo "$a -ne $b: a 不等于 b"
else
echo "$a -ne $b : a 等于 b"
fi
if [ $a -gt $b ]
then
echo "$a -gt $b: a 大于 b"
else
echo "$a -gt $b: a 不大于 b"
fi
if [ $a -lt $b ]
then
echo "$a -lt $b: a 小于 b"
else
echo "$a -lt $b: a 不小于 b"
fi
if [ $a -ge $b ]
then
echo "$a -ge $b: a 大于或等于 b"
else
echo "$a -ge $b: a 小于 b"
fi
if [ $a -le $b ]
then
echo "$a -le $b: a 小于或等于 b"
else
echo "$a -le $b: a 大于 b"
fi
执行效果如下:

4、布尔运算符
下表列出了常用的布尔运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
布尔运算符实例如下(还是采用之前的例子test-shell.sh ):
a=10
b=20
if [ $a != $b ]
then
echo "$a != $b : a 不等于 b"
else
echo "$a == $b: a 等于 b"
fi
if [ $a -lt 100 -a $b -gt 15 ]
then
echo "$a 小于 100 且 $b 大于 15 : 返回 true"
else
echo "$a 小于 100 且 $b 大于 15 : 返回 false"
fi
if [ $a -lt 100 -o $b -gt 100 ]
then
echo "$a 小于 100 或 $b 大于 100 : 返回 true"
else
echo "$a 小于 100 或 $b 大于 100 : 返回 false"
fi
if [ $a -lt 5 -o $b -gt 100 ]
then
echo "$a 小于 5 或 $b 大于 100 : 返回 true"
else
echo "$a 小于 5 或 $b 大于 100 : 返回 false"
fi
执行效果如下

5、逻辑运算符
假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
逻辑运算符实例如下(还是采用之前的例子test-shell.sh ):
a=10
b=20
if [[ $a -lt 100 && $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
if [[ $a -lt 100 || $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
执行效果如下
![]()
4.3.6 shell流程控制
在前面的Java SE课程中,我们学习了很多的流程控制语句,比如有if-else、if else-if else、switch、for、while等语句;
在shell编程中,我们同样也有这些流程控制,只是语法和java SE有所区别,但是目的是一样的。
1、if 语句:
主要用于判断,相当于java se中的if,我们还是采用之前的例子test-shell.sh
if condition
then
command1
command2
...
commandN
fi
比如,我们现在通过前面学习的知识查找一个进程,如果进程存在就打印true
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fi
注意
末尾的fi就是if倒过来拼写
执行效果如下

2、if else 语句:
主要用于判断,相当于java se中的if else,我们还是采用之前的例子test-shell.sh。
if condition
then
command1
command2
...
commandN
else
command
fi
上接上面的例子,如果找不到sshAAA**(此处可以随便输入一个)**进程,我们就打印false
if [ $(ps -ef | grep -c "sshAAA") -gt 1 ]; then echo "true"; else echo "false"; fi
执行效果如下
![]()
3、if else-if else 语句:
主要用于判断,相当于java se中的if else-if else
if condition1
then
command1
elif condition2
then
command2
else
commandN
fi
以下实例判断两个变量是否相等
我们继续使用上面的例子(test-shell.sh )
a=10
b=20
if [ $a == $b ]
then
echo "a 等于 b"
elif [ $a -gt $b ]
then
echo "a 大于 b"
elif [ $a -lt $b ]
then
echo "a 小于 b"
else
echo "没有符合的条件"
fi
执行效果如下
![]()
4、for 循环
主要用于循环,相当于java se中的for循环,我们还是采用之前的例子test-shell.sh
for循环格式为
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
done
顺序输出当前列表中的字母:
for loop in A B C D E F G
do
echo "顺序输出字母为: $loop"
done
执行效果如下

5、while循环
主要用于循环,相当于java se中的while循环
while循环用于不断执行一系列命令,也用于从输入文件中读取数据
语法格式为
while condition
do
command
done
以下是一个基本的while循环,测试条件是:如果int小于等于10,那么条件返回真。int从0开始,每次循环处理时,int加1。
还是采用之前的例子test-shell.sh
#!/bin/bash
int=1
while(( $int<=10 ))
do
echo "输出的值为:"$int
let "int++"
done
执行效果如下图

6、case … esac语句
主要用于分支条件选择,相当于java se中的switch case循环
case … esac 与其他语言中的 switch … case 语句类似,是一种多分枝选择结构,每个 case 分支用右圆括号开始,用两个分号 ;; 表示 break,即执行结束,跳出整个 case … esac 语句,esac(就是 case 反过来)作为结束标记。
还是采用之前的例子test-shell.sh
case … esac 语法格式如下:
case 值 in
模式1)
command1
command2
command3
;;
模式2)
command1
command2
command3
;;
*)
command1
command2
command3
;;
esac
case 后为取值,值可以为变量或常数。
值后为关键字 in,接下来是匹配的各种模式,每一模式最后必须以右括号结束,模式支持正则表达式。
下面通过v的值进行case–esac
v="czbk"
case "$v" in
"czbk") echo "XXX"
;;
"baidu") echo "baidu 搜索"
;;
"google") echo "google 搜索"
;;
esac
执行效果如下
![]()
4.3.7 shell函数
我们将要学习的shell函数,我们可以理解成在Java SE阶段我们学习的方法,它和shell函数的作用是一样的。
函数语法如下:
[ function ] funname [()]
{
action;
[return int;]
}
注意:
- 1、可以使用function fun() 定义函数,也可以直接fun() 定义,不带任何参数。
- 2、函数参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return后跟数值n(0-255
下面我们将定义一个函数,并发生函数调用
还是采用之前的例子test-shell.sh
#!/bin/bash
czbk(){
echo "这是第一个函数!"
}
echo "-----这里是函数开始执行-----"
czbk
echo "-----这里是函数执行完毕-----"
执行效果如下图

下面,我们定义一个带有return语句的函数:
function czbk(){
echo "对输入的两个数字进行相加运算..."
echo "输入第一个数字: "
read aNum
echo "输入第二个数字: "
read anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
return $(($aNum+$anotherNum))
}
czbk
echo "输入的两个数字之和为 $? !"
注意:
函数返回值在调用该函数后通过 $? 来获得。
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
4.3.8 总结
在企业级开发过程中,我们学习Linux主要的目的就是在Linux系统中能够熟练的操作目录、文件,还有就是通过所学的命令系统化的编写sh文件,所以,我们要熟练的编写shell脚本相关命令以及综合案例中的知识点。