Ceph--存储服务质量QoS
Ceph–存储服务质量QoS
对一个存储系统而言, QoS 旨在更加合理地统筹系统有限的I /O 资源,从而实现资源按需分配,对外提供更好的存储服务。
1、dmClock算法原理
1.1 mClock
根据参数reservation 、weight、limit参数对请求打标签,谁的标签小请求谁。标签公式:
Q r = Q r − 1 + 1 / q Q_r = Q_{r-1} + 1/q Qr=Qr−1+1/q
1.2 dmClock 下面有例子
在原基础上增加了可以动态调控的因子 Q r = Q r − 1 + m / q Q_r = Q_{r-1} + m/q Qr=Qr−1+m/q
2、QoS的设计与实现
由于 Ceph 架构的特殊性,通常将 QoS 的实现置于每个 OSD 中 。与之前 BTRFS 的设计方案的不同之处在于:首先,考虑通用性,将 QoS 驻留在 OSD 进程的请求调度部分,而不是在后端本地文件系统中;其次,由于 RADOS 功能和其实现逻辑越来越复杂,存在大量内部触发的 1/0 操作,因此 QoS 功能不仅要处理来自客户端的1/0 请求,还需要考虑系统内部 1/0 操作 。 每个 OSD 通过一个称为 ShardedOpWQ 的 工作 队列,对来自客户端以及系统内部产生的 1/0 操作进行管理 。 下面介绍三种队列:
2.1 优先级队列(prio)
PrioritizedQueue (简称 prio )是一个基于令牌桶的优先级队列,由三个级别组成:第一级是 1/0 类型的优先级 prio ;第二级是客户端级别的 client 队列;第三级是真实的 list请求队列 。 每个元素包含请求 r 及请求数据的大小 cost,

入队
每个请求都包含了消息的优先级 prio、归属的客户端 client、请求消息的大小及消息本身的数据等信息,依据以上信息依次逐级人队,最终挂入请求链表 list 尾部 。 每个 prio队列,在其第一个请求人队时被创建并分配一个大小为 max tokens 的令牌桶 。
出队
依次逐级选择合理的出队元素的过程,出队的策略是整个队列的核心, 主要包含以下几点规则:
1 )选择合理的 prio :从小到大轮询所有 prio ,只要满足条件则被选中 。 即, 该 prio队列的令牌桶中剩余的令牌数足够多(比cost大),可以容纳将被选中的请求(每个请求出队时 ,必须拿到与其大小 cost 相当的令牌个数) 。
2 )选择合理的 client :对同优先级下的 client 进行轮询,即第一个 client 出队一个请求后,将请求的出队权转交给第二个 client,该优先级再次被选中时,从第二个 client 出队请求。
3 )选择合理的请求:从被选中的 client 的请求 list 表中出队一个请求( FIFO 策略 ) 。
当有请求出队时,会释放其令牌,同时将其令牌按照prio权重进行分配,所以prio优先级高的被选中的概率大。同时每次从小prio开始遍历,防止饥饿现象,若都不满足出队条件,则从prio最大的队列中出队。
2.2 权重的优先级队列(wqp)
基于权重的优先级队列与 PrioritizedQueue 的队列结构类似,同样分为优先级 prio 、客户端 client 以及真实的请求 list 三个级别 。 除了不需要创建令牌桶之外,其请求的入队方式也与优先级队列相同,不同之处在于请求的出队机制:
1 )采用权重概率的方式确定 prio 级别,每个队列的优先级 prio 值作为其权重,该prio 队列被选中的概率即为其权重在总权重( 即total_prio ,所有 prio 队列的权重之和)中所占的比重 。 通过随机数对 total_prio 取余的方式(即, rand() % total_prio )得到在[O, total_prio 一 1 ]范围内的完全随机分布,如图 5-5 所示,随机分布落入 prio 值较大的区间的概率更大 。
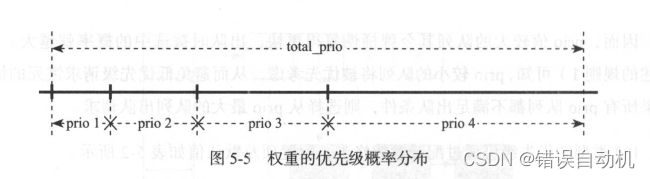
2 )被选中的 prio 队列并不一定能出队请求,还需要根据将要 出队 的请求大小来确定,即是否满足如下条件:r a nd ( )
在 max_cos t <= (max_c os t - ( (r e quest_ size * 9) I 10))
其中, max_cost 指该 prio 队列中最大的请求的大小 。 由 此可知, 较小的请求对应不等式右边的值更大,因而出队的概率更高,相反较大的请求出队的概率更低 。 在不满条件的情况下,则重新进行一轮新的 prio 队列选择 。
3 ) client 级别和真实请求的选择采用与 PrioritizedQueue 相同的方式, 分别为轮询和FIFO 策略 。
2.3 dmClock队列

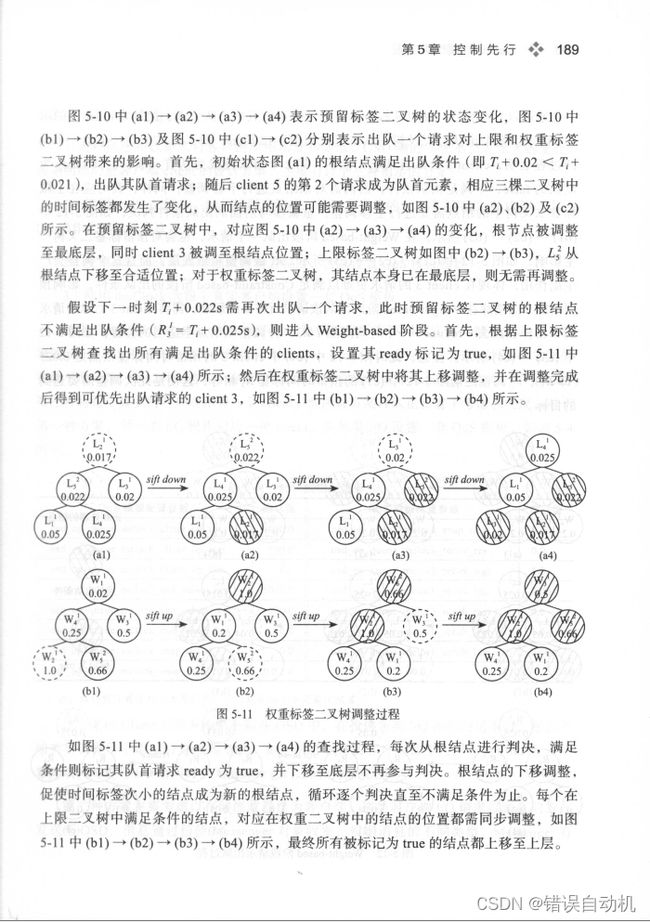
根据时间标签构造二叉搜索树,一共有三棵,而且都不是独立的,一棵树的请求出队后会影响其他两棵树的结构。
出队则是分为Constraint-based (即满足reservation根节点的时间标签小于当前时间),若不满足re阶段则转为weight阶段。具体例子如下:


2.4 Client的设计
- 使用 mClock 作为一种分配调度策略,控制客户端的 1/0 请求和 Ceph 内部产生的1/0 操作之间的优先次序 。
- 使用 dmClock 以存储池或者卷为粒度,为其设置 QoS 模板参数 。
- 使用 dmClock 为每个真实客户端设置一套 QoS 模板 。
三者的区别在于对 client 的定义不同,第一种将所有不同真实客户端作为同一个抽象的 client ,内部的每一类 1/0 操作分别作为一个 client ,重点考虑各类不同 I/O 之间的资源平衡分配;第二种则将每个存储池或存储池中的卷(或称为 image )作为一个 client ;第三种将每个真实的客户端作为一个 client。
3、总结和展望
虽然已经具备QoS功能,但在平衡后端I/O资源的调度策略上还不是特别好。
3.1 合理的模板配置
Ceph是一个基于计算的分布式存储系统,不存在集中的控制点,随意很难对客户端对I/O资源的占用比重进行一个合理的评估。
3.2 I/O带宽的限制
目前 QoS 功能主要从 IOPS 的角度设计,没有直接对 I/O 带宽进行限制 。 系统的IOPS 通常以小块数据(典型的如 4KB)来评估,而 实际I/O 操作的数据块大小不定, dmClock 将大块数据的I/O 操作转化为以小块为单位的 I/O 操作,以间接的方式来限制I/O 带宽,但这种方式对I/O 带宽的控制不太准确 。
3.3 突发的I/O处理
dmClock虽然已经能够处理突发情况,但Ceph如何判断客户端出现了突发I/O访问。目前的做法比较简单,当一个客户端一段时间未产生I/O 请求,则把它的状态置为空闲状态,再次有I/O 请求到来时变为活跃状态,服务端记录了客户端的状态, 当检测到客户端状态从空闲变为活跃时,则认为客户端将出现突发I/O 访问 。 然而不幸的是,这仅仅是突发I/O 可能出现的其中一种情况 。
下一节内容是分布式块存储RBD,因为书上介绍的内容有点记账的感觉又臭又长,看下面这个。
块存储、文件存储和对象存储