力扣OJ(4x)LCR(001-119) 剑指 Offer II
目录
LCR 001. 整数除法
LCR 002. 二进制加法
LCR 003. 前 n 个数字二进制中 1 的个数
LCR 004. 只出现一次的数字
LCR 005. 单词长度的最大乘积
LCR 006. 排序数组中两个数字之和
LCR 007. 数组中和为 0 的三个数
LCR 008. 和大于等于 target 的最短子数组
LCR 009. 乘积小于 K 的子数组
LCR 010. 和为 k 的子数组
LCR 011. 0 和 1 个数相同的子数组
LCR 012. 左右两边子数组的和相等
LCR 013. 二维子矩阵的和
LCR 014. 字符串中的变位词
LCR 015. 字符串中的所有变位词
LCR 016. 不含重复字符的最长子字符串
LCR 017. 含有所有字符的最短字符串
LCR 018. 有效的回文
LCR 019. 最多删除一个字符得到回文
LCR 020. 回文子串
LCR 021. 删除链表的倒数第 n 个结点
LCR 022. 链表中环的入口节点
LCR 023. 两个链表的第一个重合节点
LCR 024. 反转链表
LCR 025. 链表中的两数相加
LCR 026. 重排链表
LCR 027. 回文链表
LCR 029. 排序的循环链表
LCR 030. 插入、删除和随机访问都是 O(1) 的容器
LCR 031. 最近最少使用缓存
LCR 032. 有效的变位词
LCR 033. 变位词组
LCR 035. 最小时间差
LCR 039. 直方图最大矩形面积
LCR 041. 滑动窗口的平均值
LCR 042. 最近请求次数
LCR 044. 二叉树每层的最大值
LCR 046. 二叉树的右侧视图
LCR 049. 从根节点到叶节点的路径数字之和
LCR 053. 二叉搜索树中的中序后继
LCR 054. 所有大于等于节点的值之和
LCR 060. 出现频率最高的 k 个数字
LCR 061. 和最小的 k 个数对
LCR 067. 最大的异或
LCR 068. 查找插入位置
LCR 070. 排序数组中只出现一次的数字
LCR 071. 按权重生成随机数
LCR 072. 求平方根
LCR 073. 狒狒吃香蕉
LCR 074. 合并区间
LCR 076. 数组中的第 k 大的数字
LCR 077. 链表排序
LCR 078. 合并排序链表
LCR 079. 所有子集
LCR 080. 组合
LCR 081. 组合总和
LCR 082. 组合总和 II
LCR 083. 全排列
LCR 084. 全排列 II
LCR 085. 生成匹配的括号
LCR 087. 复原 IP
LCR 088. 爬楼梯的最少成本
LCR 091. 粉刷房子
LCR 093. 最长斐波那契数列
LCR 095. 最长公共子序列
LCR 099. 最小路径之和
LCR 101. 分割等和子集
LCR 103. 最少的硬币数目
LCR 104. 排列的数目
LCR 105. 岛屿的最大面积
LCR 107. 矩阵中的距离
LCR 109. 开密码锁
LCR 113. 课程顺序
LCR 001. 整数除法
给定两个整数 a 和 b ,求它们的除法的商 a/b ,要求不得使用乘号 '*'、除号 '/' 以及求余符号 '%' 。
注意:
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−231, 231−1]。本题中,如果除法结果溢出,则返回 231 − 1
示例 1:
输入:a = 15, b = 2
输出:7
解释:15/2 = truncate(7.5) = 7
示例 2:
输入:a = 7, b = -3
输出:-2
解释:7/-3 = truncate(-2.33333..) = -2
示例 3:
输入:a = 0, b = 1
输出:0
示例 4:
输入:a = 1, b = 1
输出:1
提示:
-231 <= a, b <= 231 - 1
b != 0
同 29. 两数相除 力扣OJ(1-100)_nameofcsdn的博客-CSDN博客
class Solution:
def divide(self, a: int, b: int) -> int:
c = int(a/b)
if c > 2**31-1:
c = 2**31-1
return cLCR 002. 二进制加法
给定两个 01 字符串 a 和 b ,请计算它们的和,并以二进制字符串的形式输出。
输入为 非空 字符串且只包含数字 1 和 0。
示例 1:
输入: a = "11", b = "10"
输出: "101"
示例 2:
输入: a = "1010", b = "1011"
输出: "10101"
提示:
每个字符串仅由字符 '0' 或 '1' 组成。
1 <= a.length, b.length <= 10^4
字符串如果不是 "0" ,就都不含前导零。
def intToStrTmp(a,p):
if a == 0:
return ''
xend = a%p
a = a//p
return intToStrTmp(a,p) + str(xend)
def intToStr(a,p):
if a == 0:
return '0'
return intToStrTmp(a,p)
def strToInt(a,p):
if a == '':
return 0
xend = int(a[-1])
a = a[:-1]
return strToInt(a,p)*p + xend
class Solution:
def addBinary(self, a: str, b: str) -> str:
s = strToInt(a,2) + strToInt(b,2)
return intToStr(s, 2)LCR 003. 前 n 个数字二进制中 1 的个数
338. 比特位计数 力扣OJ(201-400)_nameofcsdn的博客-CSDN博客
LCR 004. 只出现一次的数字
137. 只出现一次的数字 II 力扣OJ(101-200)_nameofcsdn的博客-CSDN博客
LCR 005. 单词长度的最大乘积
给定一个字符串数组 words,请计算当两个字符串 words[i] 和 words[j] 不包含相同字符时,它们长度的乘积的最大值。假设字符串中只包含英语的小写字母。如果没有不包含相同字符的一对字符串,返回 0。
示例 1:
输入: words = ["abcw","baz","foo","bar","fxyz","abcdef"]
输出: 16
解释: 这两个单词为 "abcw", "fxyz"。它们不包含相同字符,且长度的乘积最大。
示例 2:
输入: words = ["a","ab","abc","d","cd","bcd","abcd"]
输出: 4
解释: 这两个单词为 "ab", "cd"。
示例 3:
输入: words = ["a","aa","aaa","aaaa"]
输出: 0
解释: 不存在这样的两个单词。
提示:
2 <= words.length <= 1000
1 <= words[i].length <= 1000
words[i] 仅包含小写字母
def bitFlag(s):
ans = 0
for i in range(len(s)):
n = ord(s[i]) - ord('a')
ans = ans | 1< int:
b = []
for wi in words:
b.append(bitFlag(wi))
ans = 0
for i in range(len(words)):
for j in range (len(words)):
if i LCR 006. 排序数组中两个数字之和
本题与主站 167 题相似(下标起点不同)力扣OJ(101-200)_nameofcsdn的博客-CSDN博客
只需要把fjia(res,1);这一行删掉即可
LCR 007. 数组中和为 0 的三个数
15. 三数之和 力扣OJ(1-100)_nameofcsdn的博客-CSDN博客
LCR 008. 和大于等于 target 的最短子数组
209. 长度最小的子数组 力扣OJ(201-400)_nameofcsdn的博客-CSDN博客
LCR 009. 乘积小于 K 的子数组
给定一个正整数数组 nums和整数 k ,请找出该数组内乘积小于 k 的连续的子数组的个数。
示例 1:
输入: nums = [10,5,2,6], k = 100
输出: 8
解释: 8 个乘积小于 100 的子数组分别为: [10], [5], [2], [6], [10,5], [5,2], [2,6], [5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于100的子数组。
示例 2:
输入: nums = [1,2,3], k = 0
输出: 0
提示:
1 <= nums.length <= 3 * 104
1 <= nums[i] <= 1000
0 <= k <= 106
class Solution:
def numSubarrayProductLessThanK(self, nums: List[int], k: int) -> int:
if k <= 0:
return 0
s = e = 0
p = nums[0]
ans = 0
while s < len(nums):
while e < len(nums) and p < k:
e += 1
if e < len(nums):
p *= nums[e]
ans += max(e-s, 0)
p = p // nums[s]
s += 1
return ansLCR 010. 和为 k 的子数组
给定一个整数数组和一个整数 k ,请找到该数组中和为 k 的连续子数组的个数。
示例 1 :
输入:nums = [1,1,1], k = 2
输出: 2
解释: 此题 [1,1] 与 [1,1] 为两种不同的情况
示例 2 :
输入:nums = [1,2,3], k = 3
输出: 2
提示:
1 <= nums.length <= 2 * 104
-1000 <= nums[i] <= 1000
-107 <= k <= 107
class Solution {
public:
int subarraySum(vector& nums, int k) {
for(int i=1;im;
for(int i=0;i LCR 011. 0 和 1 个数相同的子数组
给定一个二进制数组 nums , 找到含有相同数量的 0 和 1 的最长连续子数组,并返回该子数组的长度。
示例 1:
输入: nums = [0,1]
输出: 2
说明: [0, 1] 是具有相同数量 0 和 1 的最长连续子数组。
示例 2:
输入: nums = [0,1,0]
输出: 2
说明: [0, 1] (或 [1, 0]) 是具有相同数量 0 和 1 的最长连续子数组。
提示:
1 <= nums.length <= 105
nums[i] 不是 0 就是 1
class Solution:
def findMaxLength(self, nums: List[int]) -> int:
x = 0
dict= {0:-1}
ans = 0
for i in range(0,len(nums)):
if nums[i]==0:
x += 1
else :
x -= 1
if dict.get(x, 1234567) == 1234567:
dict[x] = i
if ans < i - dict[x]:
ans = i - dict[x]
return ansLCR 012. 左右两边子数组的和相等
给你一个整数数组 nums ,请计算数组的 中心下标 。
数组 中心下标 是数组的一个下标,其左侧所有元素相加的和等于右侧所有元素相加的和。
如果中心下标位于数组最左端,那么左侧数之和视为 0 ,因为在下标的左侧不存在元素。这一点对于中心下标位于数组最右端同样适用。
如果数组有多个中心下标,应该返回 最靠近左边 的那一个。如果数组不存在中心下标,返回 -1 。
示例 1:
输入:nums = [1,7,3,6,5,6]
输出:3
解释:
中心下标是 3 。
左侧数之和 sum = nums[0] + nums[1] + nums[2] = 1 + 7 + 3 = 11 ,
右侧数之和 sum = nums[4] + nums[5] = 5 + 6 = 11 ,二者相等。
示例 2:
输入:nums = [1, 2, 3]
输出:-1
解释:
数组中不存在满足此条件的中心下标。
示例 3:
输入:nums = [2, 1, -1]
输出:0
解释:
中心下标是 0 。
左侧数之和 sum = 0 ,(下标 0 左侧不存在元素),
右侧数之和 sum = nums[1] + nums[2] = 1 + -1 = 0 。
提示:
1 <= nums.length <= 104
-1000 <= nums[i] <= 1000
class Solution:
def pivotIndex(self, nums: List[int]) -> int:
s = 0
for i in range(0,len(nums)):
s += nums[i]
s2 = 0
for i in range(0,len(nums)):
if s2 + s2 + nums[i] == s:
return i
s2 += nums[i]
return -1LCR 013. 二维子矩阵的和
给定一个二维矩阵 matrix,以下类型的多个请求:
计算其子矩形范围内元素的总和,该子矩阵的左上角为 (row1, col1) ,右下角为 (row2, col2) 。
实现 NumMatrix 类:
NumMatrix(int[][] matrix) 给定整数矩阵 matrix 进行初始化
int sumRegion(int row1, int col1, int row2, int col2) 返回左上角 (row1, col1) 、右下角 (row2, col2) 的子矩阵的元素总和。
示例 1:
输入:
["NumMatrix","sumRegion","sumRegion","sumRegion"]
[[[[3,0,1,4,2],[5,6,3,2,1],[1,2,0,1,5],[4,1,0,1,7],[1,0,3,0,5]]],[2,1,4,3],[1,1,2,2],[1,2,2,4]]
输出:
[null, 8, 11, 12]
解释:
NumMatrix numMatrix = new NumMatrix([[3,0,1,4,2],[5,6,3,2,1],[1,2,0,1,5],[4,1,0,1,7],[1,0,3,0,5]]]);
numMatrix.sumRegion(2, 1, 4, 3); // return 8 (红色矩形框的元素总和)
numMatrix.sumRegion(1, 1, 2, 2); // return 11 (绿色矩形框的元素总和)
numMatrix.sumRegion(1, 2, 2, 4); // return 12 (蓝色矩形框的元素总和)
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 200
-105 <= matrix[i][j] <= 105
0 <= row1 <= row2 < m
0 <= col1 <= col2 < n
最多调用 104 次 sumRegion 方法
class NumMatrix:
def __init__(self, matrix: List[List[int]]):
sums = matrix
for i in range(0,len(sums)):
for j in range(0,len(sums[0])):
if i==0 and j==0:
continue
if i==0:
sums[i][j] += sums[i][j-1]
elif j==0:
sums[i][j] += sums[i-1][j]
else:
sums[i][j] += sums[i][j-1] + sums[i-1][j] - sums[i-1][j-1]
self.sums = sums
def sumRegion2(self, row: int, col) -> int:
if row < 0 or col < 0:
return 0
return self.sums[row][col]
def sumRegion(self, row1: int, col1: int, row2: int, col2: int) -> int:
row1 -= 1
col1 -= 1
return NumMatrix.sumRegion2(self,row2,col2) + NumMatrix.sumRegion2(self,row1,col1) \
- NumMatrix.sumRegion2(self,row1,col2) - NumMatrix.sumRegion2(self,row2,col1)
LCR 014. 字符串中的变位词
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的某个变位词。
换句话说,第一个字符串的排列之一是第二个字符串的 子串 。
示例 1:
输入: s1 = "ab" s2 = "eidbaooo"
输出: True
解释: s2 包含 s1 的排列之一 ("ba").
示例 2:
输入: s1= "ab" s2 = "eidboaoo"
输出: False
提示:
1 <= s1.length, s2.length <= 104
s1 和 s2 仅包含小写字母
import string
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
dict = {'a':'0'}
for c in string.ascii_lowercase:
dict[c] = 0
for c in s1:
dict[c] += 1
if len(s1) > len(s2):
return False
for i in range(0,len(s1)):
dict[s2[i]] -= 1
flag = True
for c in string.ascii_lowercase:
if dict[c] != 0:
flag = False
if flag:
return True
for i in range(len(s1),len(s2)):
dict[s2[i]] -= 1
dict[s2[i-len(s1)]] += 1
flag = True
for c in string.ascii_lowercase:
if dict[c] != 0:
flag = False
if flag:
return True
return FalseLCR 015. 字符串中的所有变位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 变位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
变位词 指字母相同,但排列不同的字符串。
示例 1:
输入: s = "cbaebabacd", p = "abc"
输出: [0,6]
解释:
起始索引等于 0 的子串是 "cba", 它是 "abc" 的变位词。
起始索引等于 6 的子串是 "bac", 它是 "abc" 的变位词。
示例 2:
输入: s = "abab", p = "ab"
输出: [0,1,2]
解释:
起始索引等于 0 的子串是 "ab", 它是 "ab" 的变位词。
起始索引等于 1 的子串是 "ba", 它是 "ab" 的变位词。
起始索引等于 2 的子串是 "ab", 它是 "ab" 的变位词。
提示:
1 <= s.length, p.length <= 3 * 104
s 和 p 仅包含小写字母
import string
class Solution:
def findAnagrams(self, s: str, p: str) -> List[int]:
dict = {'a':'0'}
ans = []
for c in string.ascii_lowercase:
dict[c] = 0
for c in p:
dict[c] += 1
if len(p) > len(s):
return ans
for i in range(0,len(p)):
dict[s[i]] -= 1
flag = True
for c in string.ascii_lowercase:
if dict[c] != 0:
flag = False
if flag:
ans.append(0)
for i in range(len(p),len(s)):
dict[s[i]] -= 1
dict[s[i-len(p)]] += 1
flag = True
for c in string.ascii_lowercase:
if dict[c] != 0:
flag = False
if flag:
ans.append(i-len(p)+1)
return ansLCR 016. 不含重复字符的最长子字符串
剑指 Offer 48. 最长不含重复字符的子字符串 https://blog.csdn.net/nameofcsdn/article/details/113280987
LCR 017. 含有所有字符的最短字符串
76. 最小覆盖子串 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 018. 有效的回文
125. 验证回文串 https://blog.csdn.net/nameofcsdn/article/details/113126834
LCR 019. 最多删除一个字符得到回文
给定一个非空字符串 s,请判断如果 最多 从字符串中删除一个字符能否得到一个回文字符串。
示例 1:
输入: s = "aba"
输出: true
示例 2:
输入: s = "abca"
输出: true
解释: 可以删除 "c" 字符 或者 "b" 字符
示例 3:
输入: s = "abc"
输出: false
提示:
1 <= s.length <= 105
s 由小写英文字母组成
class Solution {
public:
bool isPalindrome(string s)
{
for(int i=0,j=s.length()-1;iLCR 020. 回文子串
647. 回文子串
LCR 021. 删除链表的倒数第 n 个结点
19. 删除链表的倒数第N个节点 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 022. 链表中环的入口节点
142. 环形链表 II https://blog.csdn.net/nameofcsdn/article/details/113126834
LCR 023. 两个链表的第一个重合节点
剑指 Offer 52. 两个链表的第一个公共节点 力扣OJ 剑指 Offer(31-68)_nameofcsdn的博客-CSDN博客
LCR 024. 反转链表
剑指 Offer 24. 反转链表 力扣OJ 剑指 Offer(1-30)_nameofcsdn的博客-CSDN博客
LCR 025. 链表中的两数相加
给定两个 非空链表 l1和 l2 来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储一位数字。将这两数相加会返回一个新的链表。
可以假设除了数字 0 之外,这两个数字都不会以零开头。
示例1:
输入:l1 = [7,2,4,3], l2 = [5,6,4]
输出:[7,8,0,7]
示例2:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[8,0,7]
示例3:
输入:l1 = [0], l2 = [0]
输出:[0]
提示:
链表的长度范围为 [1, 100]
0 <= node.val <= 9
输入数据保证链表代表的数字无前导 0
class Solution {
public:
ListNode* addTwoNumbers(ListNode* p1, ListNode* p2) {
p1 = Reverse(p1);
p2 = Reverse(p2);
ListNode *p3 = p1;
if (GetLength(p1) < GetLength(p2)) {
p1 = p2, p2 = p3;
}
p3 = p1;
int k = 0;
while (p2) {
p1->val += p2->val + k;
k = p1->val / 10, p1->val %= 10;
p1 = p1->next, p2=p2->next;
}
while (p1 && k)
{
p1->val += k;
k = p1->val / 10, p1->val %= 10;
p1 = p1->next;
}
p1 = Reverse(p3);
if (k) {
ListNode* p4 = new ListNode(k);
p4->next = p1, p1 = p4;
}
return p1;
}
};LCR 026. 重排链表
143. 重排链表 https://blog.csdn.net/nameofcsdn/article/details/113126834
LCR 027. 回文链表
234. 回文链表 https://blog.csdn.net/nameofcsdn/article/details/113131253
LCR 029. 排序的循环链表
给定循环单调非递减列表中的一个点,写一个函数向这个列表中插入一个新元素 insertVal ,使这个列表仍然是循环升序的。
给定的可以是这个列表中任意一个顶点的指针,并不一定是这个列表中最小元素的指针。
如果有多个满足条件的插入位置,可以选择任意一个位置插入新的值,插入后整个列表仍然保持有序。
如果列表为空(给定的节点是 null),需要创建一个循环有序列表并返回这个节点。否则。请返回原先给定的节点。
示例 1:
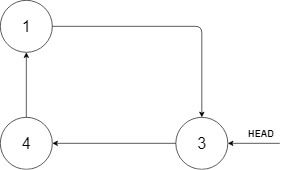
输入:head = [3,4,1], insertVal = 2
输出:[3,4,1,2]
解释:在上图中,有一个包含三个元素的循环有序列表,你获得值为 3 的节点的指针,我们需要向表中插入元素 2 。新插入的节点应该在 1 和 3 之间,插入之后,整个列表如上图所示,最后返回节点 3 。
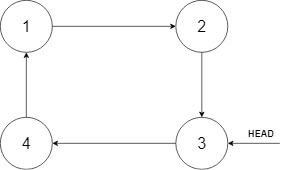
示例 2:
输入:head = [], insertVal = 1
输出:[1]
解释:列表为空(给定的节点是 null),创建一个循环有序列表并返回这个节点。
示例 3:
输入:head = [1], insertVal = 0
输出:[1,0]
提示:
0 <= Number of Nodes <= 5 * 10^4
-10^6 <= Node.val <= 10^6
-10^6 <= insertVal <= 10^6
class Solution {
public:
Node* insert(Node* head, int insertVal) {
Node* np = new Node;
np->val = insertVal;
if (head == NULL) {
head = np, head->next = head;
return np;
}
Node* p = head;
while (head->next->val >= head->val) {
head = head->next;
if (p == head)break;
}
Node* p2 = head;
while (insertVal >= head->next->val) {
head = head->next;
if (head == p2)break;
}
np->next = head->next, head->next = np;
return p;
}
};LCR 030. 插入、删除和随机访问都是 O(1) 的容器
设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构:
insert(val):当元素 val 不存在时返回 true ,并向集合中插入该项,否则返回 false 。
remove(val):当元素 val 存在时返回 true ,并从集合中移除该项,否则返回 false 。
getRandom:随机返回现有集合中的一项。每个元素应该有 相同的概率 被返回。
示例 :
输入: inputs = ["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"]
[[], [1], [2], [2], [], [1], [2], []]
输出: [null, true, false, true, 2, true, false, 2]
解释:
RandomizedSet randomSet = new RandomizedSet(); // 初始化一个空的集合
randomSet.insert(1); // 向集合中插入 1 , 返回 true 表示 1 被成功地插入
randomSet.remove(2); // 返回 false,表示集合中不存在 2
randomSet.insert(2); // 向集合中插入 2 返回 true ,集合现在包含 [1,2]
randomSet.getRandom(); // getRandom 应随机返回 1 或 2
randomSet.remove(1); // 从集合中移除 1 返回 true 。集合现在包含 [2]
randomSet.insert(2); // 2 已在集合中,所以返回 false
randomSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2
提示:
-231 <= val <= 231 - 1
最多进行 2 * 105 次 insert , remove 和 getRandom 方法调用
当调用 getRandom 方法时,集合中至少有一个元素
class RandomizedSet {
public:
/** Initialize your data structure here. */
RandomizedSet() {
}
/** Inserts a value to the set. Returns true if the set did not already contain the specified element. */
bool insert(int val) {
if (saveId[val])return false;
v.push_back(val);
saveId[val] = v.size();
return true;
}
/** Removes a value from the set. Returns true if the set contained the specified element. */
bool remove(int val) {
if (saveId[val] == 0)return false;
saveId[v[saveId[val] - 1] = v[v.size() - 1]] = saveId[val], saveId[val] = 0;
v.erase(v.begin() + v.size() - 1);
return true;
}
/** Get a random element from the set. */
int getRandom() {
int id = rand() % v.size();
return v[id];
}
private:
vectorv;
mapsaveId;
}; LCR 031. 最近最少使用缓存
146. LRU 缓存机制 https://blog.csdn.net/nameofcsdn/article/details/113126834
LCR 032. 有效的变位词
哈希表
LCR 033. 变位词组
49. 字母异位词分组 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 035. 最小时间差
给定一个 24 小时制(小时:分钟 "HH:MM")的时间列表,找出列表中任意两个时间的最小时间差并以分钟数表示。
示例 1:
输入:timePoints = ["23:59","00:00"]
输出:1
示例 2:
输入:timePoints = ["00:00","23:59","00:00"]
输出:0
提示:
2 <= timePoints <= 2 * 104
timePoints[i] 格式为 "HH:MM"
class Solution {
public:
int findMinDifference(vector& timePoints) {
vectorv;
for (auto& ti : timePoints) {
char* ch = (char*)ti.data();
*(ch + 2) = '\0';
int m = atoi(ch + 3);
int h = atoi(ch);
v.push_back(h * 60 + m);
}
sort(v.begin(), v.end());
int ans = 24 * 60 - v[v.size() - 1] + v[0];
for (int i = 1; i < v.size(); i++)ans = min(ans, v[i] - v[i - 1]);
return ans;
}
}; LCR 039. 直方图最大矩形面积
力扣 84. 柱状图中最大的矩形
LCR 041. 滑动窗口的平均值
力扣 346. 数据流中的移动平均值
LCR 042. 最近请求次数
933. 最近的请求次数
LCR 044. 二叉树每层的最大值
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
示例1:
输入: root = [1,3,2,5,3,null,9]
输出: [1,3,9]
解释:
1
/ \
3 2
/ \ \
5 3 9
示例2:
输入: root = [1,2,3]
输出: [1,3]
解释:
1
/ \
2 3
示例3:
输入: root = [1]
输出: [1]
示例4:
输入: root = [1,null,2]
输出: [1,2]
解释:
1
\
2
示例5:
输入: root = []
输出: []
提示:
二叉树的节点个数的范围是 [0,104]
-231 <= Node.val <= 231 - 1
class Solution {
public:
vector largestValues(TreeNode* root) {
vector ans;
if (!root)return ans;
ans = MergeVector(largestValues(root->left), largestValues(root->right));
ans.insert(ans.begin(), root->val);
return ans;
}
}; LCR 046. 二叉树的右侧视图
199. 二叉树的右视图
LCR 049. 从根节点到叶节点的路径数字之和
129. 求根到叶子节点数字之和
LCR 053. 二叉搜索树中的中序后继
285. 二叉搜索树中的中序后继
LCR 054. 所有大于等于节点的值之和
二叉搜索树
LCR 060. 出现频率最高的 k 个数字
347. 前 K 个高频元素
LCR 061. 和最小的 k 个数对
373. 查找和最小的K对数字 https://blog.csdn.net/nameofcsdn/article/details/113131253
LCR 067. 最大的异或
421. 数组中两个数的最大异或值 https://blog.csdn.net/nameofcsdn/article/details/113132857
LCR 068. 查找插入位置
搜索else
LCR 070. 排序数组中只出现一次的数字
540. 有序数组中的单一元素 https://blog.csdn.net/nameofcsdn/article/details/113132857
LCR 071. 按权重生成随机数
给定一个正整数数组 w ,其中 w[i] 代表下标 i 的权重(下标从 0 开始),请写一个函数 pickIndex ,它可以随机地获取下标 i,选取下标 i 的概率与 w[i] 成正比。
例如,对于 w = [1, 3],挑选下标 0 的概率为 1 / (1 + 3) = 0.25 (即,25%),而选取下标 1 的概率为 3 / (1 + 3) = 0.75(即,75%)。
也就是说,选取下标 i 的概率为 w[i] / sum(w) 。
示例 1:
输入:
inputs = ["Solution","pickIndex"]
inputs = [[[1]],[]]
输出:
[null,0]
解释:
Solution solution = new Solution([1]);
solution.pickIndex(); // 返回 0,因为数组中只有一个元素,所以唯一的选择是返回下标 0。
示例 2:
输入:
inputs = ["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"]
inputs = [[[1,3]],[],[],[],[],[]]
输出:
[null,1,1,1,1,0]
解释:
Solution solution = new Solution([1, 3]);
solution.pickIndex(); // 返回 1,返回下标 1,返回该下标概率为 3/4 。
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 1
solution.pickIndex(); // 返回 0,返回下标 0,返回该下标概率为 1/4 。
由于这是一个随机问题,允许多个答案,因此下列输出都可以被认为是正确的:
[null,1,1,1,1,0]
[null,1,1,1,1,1]
[null,1,1,1,0,0]
[null,1,1,1,0,1]
[null,1,0,1,0,0]
......
诸若此类。
提示:
1 <= w.length <= 10000
1 <= w[i] <= 10^5
pickIndex 将被调用不超过 10000 次
class Solution {
public:
vector v;
int s;
Solution(vector& w) {
v.resize(w.size());
s = 0;
for(int i=0;i LCR 072. 求平方根
69. x 的平方根 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 073. 狒狒吃香蕉
875. 爱吃香蕉的珂珂 https://blog.csdn.net/nameofcsdn/article/details/115394990
LCR 074. 合并区间
56. 合并区间 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 076. 数组中的第 k 大的数字
215. 数组中的第K个最大元素 https://blog.csdn.net/nameofcsdn/article/details/113131253
LCR 077. 链表排序
148. 排序链表 https://blog.csdn.net/nameofcsdn/article/details/113126834
LCR 078. 合并排序链表
单链表
LCR 079. 所有子集
给定一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入:nums = [1,2,3]
输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
示例 2:
输入:nums = [0]
输出:[[],[0]]
提示:
1 <= nums.length <= 10
-10 <= nums[i] <= 10
nums 中的所有元素 互不相同
class Solution {
public:
vector> subsets(vector& nums) {
map>options;
for (int i = 0; i < nums.size(); i++)options[i].push_back(INT_MAX);
auto ans = SubMeiJu(nums, nums.size(), options);
Delet(ans, INT_MAX);
return ans;
}
}; LCR 080. 组合
力扣 77. 组合
LCR 081. 组合总和
力扣 39. 组合总和
LCR 082. 组合总和 II
40. 组合总和 II
LCR 083. 全排列
力扣 46. 全排列
LCR 084. 全排列 II
力扣 47. 全排列 II
LCR 085. 生成匹配的括号
22. 括号生成 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 087. 复原 IP
93. 复原IP地址 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 088. 爬楼梯的最少成本
数组的每个下标作为一个阶梯,第 i 个阶梯对应着一个非负数的体力花费值 cost[i](下标从 0 开始)。
每当爬上一个阶梯都要花费对应的体力值,一旦支付了相应的体力值,就可以选择向上爬一个阶梯或者爬两个阶梯。
请找出达到楼层顶部的最低花费。在开始时,你可以选择从下标为 0 或 1 的元素作为初始阶梯。
示例 1:
输入:cost = [10, 15, 20] 输出:15 解释:最低花费是从 cost[1] 开始,然后走两步即可到阶梯顶,一共花费 15 。
示例 2:
输入:cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] 输出:6 解释:最低花费方式是从 cost[0] 开始,逐个经过那些 1 ,跳过 cost[3] ,一共花费 6 。
提示:
2 <= cost.length <= 10000 <= cost[i] <= 999
class Solution {
public:
int minCostClimbingStairs(vector& cost) {
vector ans=cost;
ans.push_back(0);
for(int i=2;i LCR 091. 粉刷房子
数列DP
LCR 093. 最长斐波那契数列
873. 最长的斐波那契子序列的长度 https://blog.csdn.net/nameofcsdn/article/details/115394990
LCR 095. 最长公共子序列
1143. 最长公共子序列 https://blog.csdn.net/nameofcsdn/article/details/113135858
LCR 099. 最小路径之和
64. 最小路径和 https://blog.csdn.net/nameofcsdn/article/details/113124721
LCR 101. 分割等和子集
416. 分割等和子集 https://blog.csdn.net/nameofcsdn/article/details/113132857
LCR 103. 最少的硬币数目
322. 零钱兑换 https://blog.csdn.net/nameofcsdn/article/details/113131253
LCR 104. 排列的数目
力扣 377. 组合总和 Ⅳ
LCR 105. 岛屿的最大面积
695. 岛屿的最大面积
LCR 107. 矩阵中的距离
542. 01 矩阵 https://blog.csdn.net/nameofcsdn/article/details/113132857
LCR 109. 开密码锁
752. 打开转盘锁
LCR 113. 课程顺序
210. 课程表 II https://blog.csdn.net/nameofcsdn/article/details/113131253