XXL-Job分布式任务调度框架-- 汇总篇4
一 xxl-job的总结
1.1 xxl-job作用
XXL-JOB是一个轻量级分布式任务调度平台,XXL-JOB主要提供了任务的动态配置管理、任务监控和统计报表以及调度日志几大功能模块,支持多种运行模式和路由策略,可基于对应执行器机器集群数量进行简单分片数据处理。
组件作用:
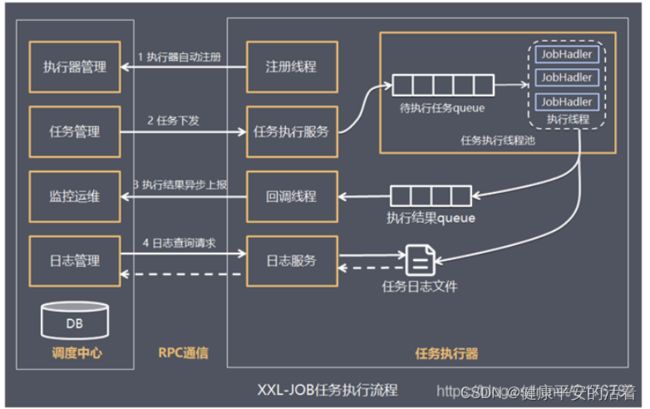
1.调度中心: 任务调度控制台,平台自身并不承担业务逻辑,只是负责任务的统一管理和调度执行,并且提供任务管理平台。如从github下载的xxl-job-admin工程代码。
调度中心就是源码中的 xxl-job-admin 工程,我们需要将其配置成自己需要的调度中心,通过该工程我们能够以图形化的方式统一管理任务调度平台上调度任务,负责触发调度执行。
2.执行器: 负责接收“调度中心”的调度并执行,可直接部署执行器,也可以将执行器集成到现有业务项目中。 通过将任务的调度控制和任务的执行解耦,业务使用只需要关注业务逻辑的开发。如自己编写的工程。 xxl-job-dingshi。在调度中心新增配置的执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
1.2 常见概念
1.路由策略:执行器集群部署时提供丰富的路由策略,包括:_第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移_等;
2.故障转移:任务路由策略选择_故障转移_情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
3.分片广播任务:执行器集群部署时,任务路由策略选择分片广播情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
final ShardingUtil.ShardingVO shardingVo = ShardingUtil.getShardingVo();
index: 当前分片的序号(从0开始)执行器集群列表中当前执行器的序号
total: 总分片数,执行器集群的总机器数量4.动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
1.3 常见面试问题
1.如何避免集群中的多个服务器同时调度任务?当xxl-job应用本身集群部署(实现高可用HA)时,如何避免集群中的多个服务器同时调度任务?
通过mysql悲观锁实现分布式锁(for update语句)
setAutoCommit(false)关闭隐式自动提交事务,启动事务select lock for update(显式排他锁,其他事务无法进入&无法实现for update)- 读
db任务信息 -> 拉任务到内存时间轮 -> 更新db任务信息 commit提交事务,同时会释放for update的排他锁(悲观锁)
2.任务执行器注册中心是如何实现的?
使用db表xxl_job_group记录下执行器的信息:
执行器AppName、执行器名称title、执行器地址列表address_list(多地址逗号分隔)
3.执行器集群部署时提供丰富的路由策略,包括:
第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
4.如何实现任务分片、并行执行?
拉出任务的执行机器列表,逐个设置index / total,把index / total分发到任务执行器
任务执行器可根据index / total参数开发分片任务
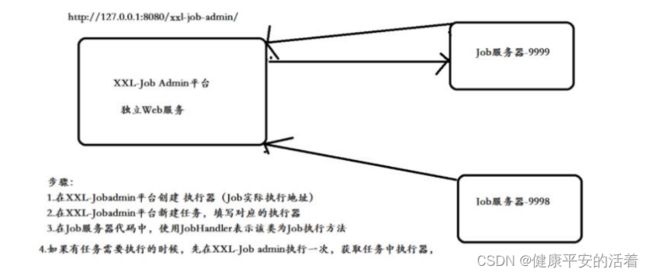
5. XXL-JOB任务调度流程
1:XXL-Jobadmin平台创建执行器(Job实际执行地址)
2:XXL-Jobadmin平台新建任务,填写对应的执行器
3:Job服务器代码中,使用JobHandler表示该类为Job执行方法
4:当任务执行的时候,会现在XXL-Jobadmin调度平台先执行一次,获取任务中的执行器,然后去对应的执行器地址服务器,执行对应的任务
6. (动态)分片与广播
分片:将任务拆分,分发到每个服务器上并发执行,以此增加执行
以执行器为粒度,根据执行器ip自然排序编号,结合任务入参,在发布任务时即可做到某片执行某些数据
分片代码:
for (int i = 0; i < group.getRegistryList().size(); i++) {
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
com.xxl.job.admin.core.trigger.XxlJobTrigger#trigger(…):82
广播: 将完整任务分发每个服务器上(场景:每个执行节点的缓存更新/执行脚本)
-
分片任务:集群部署,每个实例都同时执行一部分数据。分片方式:取模分片,范围分片
-
单机多任务分片:单机模式下,创建同类型任务多个任务计划,手工分片数据作为参数
-
集群任务分片:只有广播模式会通知所有实例都会运行,每个节点取模执行任务
-
6.分片
作业分片是指任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的应用实例分别执行某一个或几个分片项。
如两台服务器,每台服务器跑一个应用实例,为了快速执行作业,可以将作业分成四片,每个应用实例各执行两片。
通过任务合理的分片化,从而达到任务并行处理的效果,最大限度的提高执行作业的吞吐量。
分布式调度一定要避免数据重复处理,因此要保证拿到的数据是不一样的
————————————————
版权声明:本文为CSDN博主「郝开」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41929714/article/details/127924188
最大限度利用资源
将分片设置为大于服务器的数量,最好是大于服务器倍数的数量,这样有利于作业将合理利用分布式资源,动态的分配分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。
如果服务器C宕机,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
————————————————
版权声明:本文为CSDN博主「郝开」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41929714/article/details/127924188
二 配置篇
2.1 执行器
这里需要注意的是:配置执行器的名称、IP地址、端口号,后面如果配置多个执行器时,要防止端口冲突。再就是执行器的名称要和调度中心管理界面进行对应配置。如下图所示

2.2 执行器api
XXL-JOB执行器的相关配置项:
xxl.job.admin.addresses
调度中心的部署地址。若调度中心采用集群部署,存在多个地址,则用逗号分隔。执行器将会使用该地址进行”执行器心跳注册”和”任务结果回调”。
xxl.job.executor.appname
执行器的应用名称,它是执行器心跳注册的分组依据。
xxl.job.executor.ip
执行器的IP地址,用于”调度中心请求并触发任务”和”执行器注册”。执行器IP默认为空,表示自动获取IP。多网卡时可手动设置指定IP,手动设置IP时将会绑定Host。
xxl.job.executor.port
执行器的端口号,默认值为9999。单机部署多个执行器时,注意要配置不同的执行器端口。
xxl.job.accessToken
执行器的通信令牌,非空时启用。
xxl.job.executor.logpath
执行器输出的日志文件的存储路径,需要拥有该路径的读写权限。
- xxl.job.executor.logretentiondays
执行器日志文件的定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保存3天,否则功能不生效。
2.3 配置执行器
点击 执行器管理----》新增执行器---》,如下如下界面,然后填充此表格,点击保存即可。
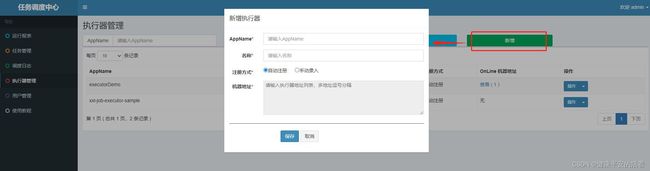
- AppName:是每个执行器集群的唯一标识
AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用; - 名称:执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
- 注册方式:调度中心获取执行器地址的方式,
- 自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
- 手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
- 机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
2.4 调度器任务
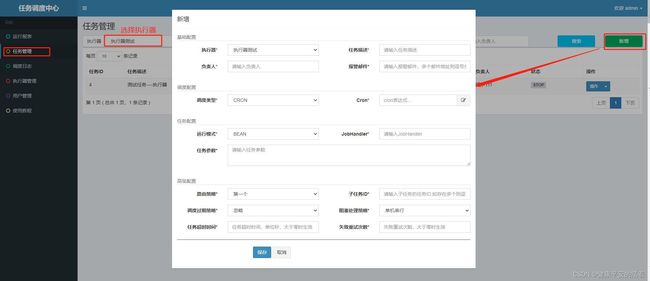
相关参数说明:
- 执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 "执行器管理" 进行设置。
- 任务描述:任务的描述信息,便于任务管理;
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务; - Cron:触发任务执行的Cron表达式;
- 运行模式:
BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 "JobHandler" 属性匹配执行器中任务;
GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本;
GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本;
GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "php" 脚本;
GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本;
GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "PowerShell" 脚本; - JobHandler:运行模式为 "BEAN模式" 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务; - 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
- 负责人:任务的负责人;
- 执行参数:任务执行所需的参数,多个参数时用逗号分隔,任务执行时将会把多个参数转换成数组传入;
三 源码篇
3.1 分片指针和分片总数的获取
//当前的执行器编号 int shardIndex = XxlJobHelper.getShardIndex(); //总的分片数,就是执行器的集群数量 int shardTotal = XxlJobHelper.getShardTotal();
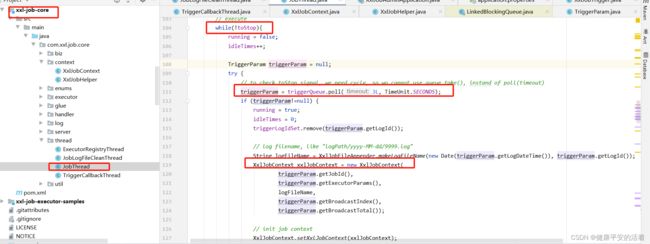
查看源码,通过while循环从
private LinkedBlockingQueuetriggerQueue;
不停拿到最新的分片数目。https://www.cnblogs.com/fantongxue/p/16615093.html