01.ChatGPT原理剖析
目录
- ChatGPT初体验
-
- 对ChatGPT的误解
- ChatGPT的本质
- 模型的训练
- ChatGPT的关键技术
-
- 监督学习
- 预训练(Pre-train)
-
- GPT系列的历史
- 预训练的好处
- 强化学习
- ChatGPT带来的研究问题
部分截图来自原课程视频《2023李宏毅最新生成式AI教程》,B站自行搜索
ChatGPT初体验
ChatGPT:Chat表示聊天,G表示Generative,P表示Pre-train,T表示Transformer。
可以回答问题,但每次回答问题的结果会不同。
可以进行追问。若要清除历史信息,需要开启新对话。
对ChatGPT的误解
1.ChatGPT的回答是从现有的数据(比喻为罐头数据)中copy出来的。否,有些回答还有很明显的生成痕迹,例如讲笑话,笑点和人类明显不同。
2.ChatGPT的回答是从Internet上搜索得来的(类似百科类网站)。否,有些回答会由模型自行捏造,例如问其一些不存在的东西,会得到瞎编的结果。官方也说明该模型是不联网的,模型的答案也不一定正确。
ChatGPT的本质
ChatGPT的本质:文字接龙

模型吃输入后,通过function计算得到下一个字可能的分布,再随机选择top N中的一个作为结果,得到下一个字的结果。由于随机选择这个操作,使得每次结果会有所不一样。

将得到结果与前面的句子作为输入再次丢进模型,并循环,直到模型输出结束为止。
为了让模型能够进行多轮对话,输入通常还会包含当前对话中的历史信息作为上下文。
模型的训练

在训练阶段,需要从Internet上收集大量数据,完成训练后在使用(或者说测试)时则不需要在进行联网,这里老师给出了一个非常形象的比喻:
训练就好比学生平时学习,可以看各种资料,测试就好比闭卷考试,只能凭学习到的知识解题。
ChatGPT的关键技术
ChatGPT的关键技术:预训练(Pre-train),又叫自监督学习(Self-supervised Learning)、基石模型(Foundation Model)
监督学习
一般的机器学习使用的是监督学习,例如在机器翻译任务中,通常先收集大量双语语料:
| 英文 | 中文 |
|---|---|
| This is an apple | 这是一个苹果 |
| That is an orange | 那是一个橘子 |
模型通过大量吃入语料后找出函数,学到:
this
that
apple
orange
几个单词的意思后,模型就能够翻译:
That is an apple|那是一个苹果
如果将监督学习方式用在ChatGPT上,那么就会出现以下形式的训练:
| 输入 | 输出 |
|---|---|
| TW第一高峰是那一座? | 玉山 |
| 帮我修改这段文字:… | 好的,… |
| 教我做坏事… | 这样是不对的 |
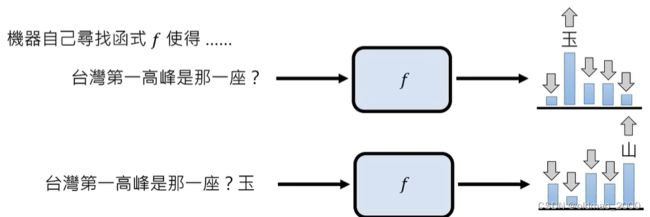
根据监督学习的方式训练出来的生成模型能力非常有限,它的推断能力非常差,由于训练数据的限制(数据对于机器学习非常重要,决定了模型的上限),模型无法回答训练数据中没有出现过的问题,例如:世界第一高峰是哪一座?
当然这个例子在这里有点不太全面,即使是人如果你没教过他世界最高峰是那座,他也无法回答这个问题,这里应该是想表明ChatGPT的推理能力。
预训练(Pre-train)
当然,模型只要参数足够多,就可以记住它看过的各种资料,如何拿到天量的数据对,让模型进行学习呢?答案就是利用Internet上现成的语料。例如有这么一句话:世界第一高峰是喜拉雅山。今天天气真好,我要出去玩。则可将其拆分:
世界第一高峰是 喜拉雅山 今天天气真好 ,我要出去玩 {\color{Blue} 世界第一高峰是}{\color{Red} 喜拉雅山}\\ {\color{Blue} 今天天气真好}{\color{Red} ,我要出去玩} 世界第一高峰是喜拉雅山今天天气真好,我要出去玩
意味着,模型在吃:世界第一高峰是,要学会输出【喜】;
模型在吃:今天天气真好,要学会输出【,】
GPT系列的历史
确定了GPT的训练方式,那么回顾其发展历史:
| GPT | GPT-2 | GPT-3 | |
|---|---|---|---|
| 模型大小 | 117M | 1542M | 175GB |
| 训练数据 | 1GB | 40GB | 570GB |
| 年份 | 2018 | 2019 | 2020 |
GPT-2在CoQA数据集上F1的表现,模型越大,效果越好

GPT-3的训练数据是从45T中筛选出来的570GB,相当于阅读Harry Potter全集(1-7)30万套的数据量。GPT-3还点出写代码的技能点,下面是该模型在42个任务取得的平均准确率。

但它由于只学习从网络上获取的语料,因此其回答问题往往也比较不受控,例如:

明显看到,在学习语料中包含大量的题库,里面有很多选择题,GPT就直接套用了选择题的模式,并没有回答具体问题。
因此,从GPT进化到ChatGPT需要加入监督学习(语料由人工为主),这个过程称为:Finetune。

预训练的好处
通过预训练可以大大加强模型的泛化能力,最明显的例子就是多语言训练,可以使得模型自动具有不同语言任务上的泛化能力。
下面是一个例子,使用的英文QA数据集为SQuAD,中文QA数据集为DRCD
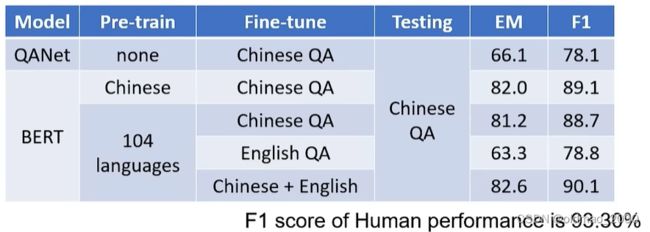
可以看到最后一行使用104中语言进行预训练后,使用中英文数据进行微调,最后的F1为90.1,已经非常接近人类的成绩。
强化学习
在从GPT进化到ChatGPT过程中,除了加入监督学习之外,还加入了强化学习,强化学习在训练时人工介入相对简单,只需要对模型输出结果给出好或者不好的评价即可。
ChatGPT带来的研究问题
1.如何精准提出需求(Prompting)
https://github.com/PlexPt/awesome-chatgpt-prompts-zh
下面是个例子:
请你充当一名论文编辑专家,在论文评审的角度去修改论文摘要部分,使其更加流畅,优美。下面是具体要求:
能让读者快速获得文章的要点或精髓,让文章引人入胜;能让读者了解全文中的重要信息、分析和论点;帮助读者记住论文的要点
字数限制在300字以下
请你在摘要中明确指出您的模型和方法的创新点,强调您的贡献。
用简洁、明了的语言描述您的方法和结果,以便评审更容易理解论文
下文是论文的摘要部分,请你修改它:
…
https://www.rayskyinvest.com/96682/chatgpt-examples
https://www.explainthis.io/zh-hant/ai/website
这个网站的prompting指令是ChatGPT生成的。
2.如何更正错误
由于ChatGPT的预训练数据只截止到2021年,因此最近发生的事情它是不知道的。
例如问,最近一次世界杯足球赛冠军是谁?
回答是:2018年的法国。
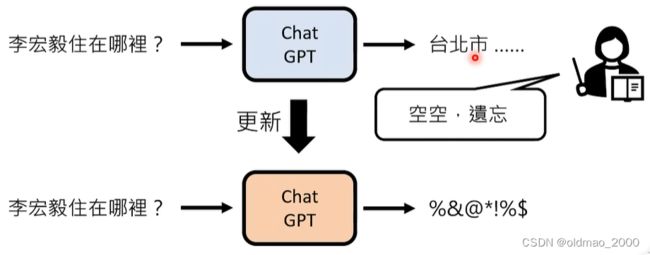
这里如果硬改成阿根廷,那么可能下次同样的问题,模型就会回答2018年的阿根廷。这是因为模型是黑盒,不像人类。
因此如何让模型回答正确,也是一个研究方向:Neutral Editing
3.判断AI生成的物件
物件包括:文字、声音、图片、影像等
思路肯定不能简单的看做是分类任务,将数据丢模型进行判断。
4.是否会泄露机密
为了防止模型泄露个人隐私,有一个研究课题叫:Machine Unlearning