计算机组成与体系结构
计算机组成与体系结构
- 一、数据的表示
-
- 1.1 原码、反码、补码和移码
- 1.2 常用进制的简写
- 1.3 浮点数运算
- 二、计算机结构
-
- 2.1 CPU结构
- 2.2 计算机体系结构分类
- 2.3 指令系统
- 2.4 CPU架构
- 2.5 流水线
-
- 2.5.1 流水线周期及执行时间
- 2.5.2 流水线吞吐率
- 2.5.3 流水线加速比
- 2.5.4 流水线的效率
- 2.6 缓存
- 2.7 局部性原理
- 2.8 主存储器
- 2.9 磁盘
- 2.10 总线
- 2.11 串联系统与并联系统
- 2.12 差错控制
-
- 2.12.1 循环冗余校验CRC
- 2.12.2 海明码校验码/汉明码Hamming Code
- 三、 操作系统基本原理
-
- 3.1 进程
- 3.2 进程管理PV操作
- 3.3 死锁
- 3.4 存储管理
-
- 3.4.1 碎片
- 3.4.2 地址
- 3.4.3 基址加界限寄存器(动态重定位)
- 3.4.4 段式模型
- 3.4.5 页式模型
- 3.4.6 段页式存储
- 3.5 文件管理
- 四、 数据库系统
-
- 4.1 ER图
- 4.2 笛卡尔积
- 4.3 范式
- 引用:
一、数据的表示
1.1 原码、反码、补码和移码
原码无法直接在计算机中进行运算,即原码的负值与原码相加和实际情况不一致。
| 数值1 | 取反 | 数值1加上取反的值 | 备注 | |
|---|---|---|---|---|
| 原码 | 0000 0001 | 1000 0001 | 1000 0010(-2) | 原码正数首位为0,负数首位为1 |
| 反码 | 0000 0001 | 1111 1110 | 1111 1111(-0) | 反码是原码按位取反 |
| 补码 | 0000 0001 | 1111 1111 | 0000 0000(0) | 补码是反码的负值+1 |
| 移码 | 1000 0001 | 0111 1111 | 0000 0000(0) | 移码是对补码首位的取反 |
因为二进制中存在正数和负数,甚至在原码和反码0都有正0和负0。
补码的意义是为了把让减法运算运算时转换成正数和负数加法运算;
移码的存在意义是让正数比负数大;
数值表示范围:
| 类型 | 范围 | 8位为例 |
|---|---|---|
| 原码 | − ( 2 n − 1 − 1 ) 至 ( 2 n − 1 − 1 ) -(2^{n-1}-1) 至 (2^{n-1}-1) −(2n−1−1)至(2n−1−1) | -127 至 127 |
| 反码 | − ( 2 n − 1 − 1 ) 至 ( 2 n − 1 − 1 ) -(2^{n-1}-1) 至 (2^{n-1}-1) −(2n−1−1)至(2n−1−1) | -127 至 127 |
| 补码 | − ( 2 n − 1 ) 至 ( 2 n − 1 − 1 ) -(2^{n-1}) 至 (2^{n-1}-1) −(2n−1)至(2n−1−1) | -128 至 127 |
| 补码比原码和反码的取值范围要大1个,因为在原码和反码中0需要有正0和负0两个,而在补码和移码中0不存在正负0; |
1.2 常用进制的简写
| 进制 | 简写 |
|---|---|
| 十进制 | D |
| 二进制 | B |
| 八进制 | Q |
| 十六进制 | H |
1.3 浮点数运算
浮点数表示: N = M ∗ R e N=M*R^{e} N=M∗Re
其中M为尾数,e为指数,R为基数。
当计算机在进行浮点数运算时,需要经过 对阶 → 尾数计算 → 结果格式化三个步骤
例: 1000 = 1.0 ∗ 1 0 3 1000=1.0*10^{3} 1000=1.0∗103
119 = 1.19 ∗ 1 0 2 119=1.19*10^{2} 119=1.19∗102
在这两个浮点数进行运算时,把阶数小的往高的对(小阶对大阶),即0.119 * 10 ^ 3,然后进行同阶的尾数计算,最后格式化成d.dddd的结果。
二、计算机结构
2.1 CPU结构
主机分为CPU和主存储器(又称内存储器、内存)

运算器部件:
1.算术逻辑单元ALU,是能实现多组算术运算和逻辑运算的组合逻辑电路。
2.累加寄存器AC,是一个通用寄存器,虽然叫累加器,但还支持减法、读出、移位、循环移位、求补等操作。它为ALU提供一个工作区,暂时存放ALU运算的结果信息。
3.数据缓冲寄存器DR,在内存储器(内存)进行读写操作时,将数据放入其。
4.状态条件寄存器PSW,存储在运算过程中的标志位(进位、溢出、为零、为负、终端、方向、单步等)
控制器部件:
1.控制部件:
地址寄存器AR,用来保存当前CPU所访问的内存单元的地址信息。
程序计数器PC,存放指令地址,将指令由内存取到指令寄存器中,且程序计数器更新为下一指令的地址
2.指令部件:
指令寄存器IR,用于暂存当前正在执行的指令;
指令译码器ID,译码呗。
3.时序部件:为指令的执行产生时序信号。

2.2 计算机体系结构分类
1.单指令流单数据流SISD:单控制部分,单处理器,单主存模块;常见于单片机
2.单指令流多数据流SIMD:单控制部分,多处理器,多主存模块;阵列处理器,各处理以异步执行同一条指令,像GPU做矩阵处理时那样。
3.多指令流单数据流MISD:多控制部分,单处理器,多主存模块;没得这种东西。
4.多指令流多数据流MIMD:多控制部分,多处理器,多主存模块;家用计算机
2.3 指令系统
复杂指令集计算机CISC,Complex 复杂的。上世纪用的东西,定制的、占地面积巨大的计算机。
精简指令集计算机RISC,Reduced 减少,缩小。
在CISC指令集的各种指令中,大约有20%的指令会被反复使用,占整个程序代码的80%。而余下的80%的指令却不经常使用,在程序设计中只占20%。
总的来说,
| 指令系统类型 | 指令 | 寻址方式 | 实现方式 | 其他 |
|---|---|---|---|---|
| CISC | 数量多,使用频率差别大,可变长格式 | 支持多种寻址方式 | 微程序控制器(微码) | 研制周期长、有少量专用寄存器 |
| RISC | 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Loadhe Store操作内存 | 支撑方式少 | 硬布线控制器;增加了通用寄存器,适合采用流水线 | 优化编译,可支持高级语言、泛用的暂存器 |
2.4 CPU架构
x86架构,因Intel的处理器型号早期以数字86结尾,因此其架构被称为x86架构,常用与家用计算机中。其早期是16位的,后来AMD与1999年抢先推出了64位元、x86架构的处理器,命名为AMD 64。Intel于2001年紧随其后推出IA-64,是和惠普合作的英特尔安腾处理器,是一种和x86完全不同的架构。后来统称为x86-64或x64。那么x86架构是用的是前文说到的复杂指令集(CISC),windows8以前的操作系统都是仅支持x86架构的。在较为新的微架构中,x86处理器会把x86指令更换为更像RISC那样的微指令再进行执行,提升性能。
ARM架构,英文是AdvancedRISC Machine进阶精简指令集机器。
起初叫AcornRISC Machine,Acorn是公司名字。显而易见是用的RISC复杂指令集,是32位元的处理器。因其节能低耗的特点,常用与嵌入式系统与移动通讯领域(手机芯片)。
MIPS架构,英文是Microprocessorwithout Interlocked Pipeline Stages,无内部互锁流水级微处理器,也是采用RISC的处理器架构。机制是尽量利用软件办法避免流水线中的数据相关问题,强调硬件协同提高性能,同时简化硬件设计。是64位元处理器,支持除法指令
2.5 流水线
流水线是指在程序执行时,多条指令重叠进行操作的一种准并行处理技术,提高各部件的利用率和指令单平均执行速率。
2.5.1 流水线周期及执行时间
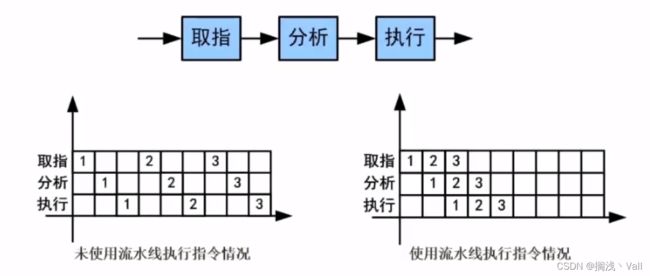
流水线周期:是流水线步骤中最长的一段时间。是执行多条指令时,一条指令的开始到下一条指令的最晚开始时间的总称。私以为可以看图中间的一竖列。
流水线执行时间计算公式:1条指令执行时间 + 剩下的指令数 * 流水线周期
:若指令流水线把一条指令分为取指、分析和执行三部分,且三部分的时间分别是2ns、2ns、1ns。
流水线的周期是:2ns
理论上:
1条指令的执行时间是:2ns + 2ns + 1ns = 5ns
100令的执行时间是:5ns + 99 * 2ns = 203ns
但是!执行时间比周期要小,这就很麻烦,不如统一一下。
实际上:
1条指令的执行时间是:2ns + 2ns + 2ns = 6ns
100令的执行时间是:6ns + 99 * 2ns = 204ns
但是!两种都算对。
2.5.2 流水线吞吐率
流水线吞吐率:是指在单位时间内流水线所完成的任务数量或输出结果的数量。
流水线吞吐率计算公式: 指令条数 / 流水线执行时间
流水线最大吞吐率计算公式: 1条 / 流水线周期,是一个理想状态
流水线的吞吐率为: 100条 / 203ns
流水线的最大吞吐率为: 1条 / 2ns
2.5.3 流水线加速比
流水线加速比公式: 不使用流水线的执行时间 / 使用流水线的执行时间
不使用流水线时间:( 2ns + 2ns + 1ns ) * 100条 = 500ns
使用流水线时间: 203ns
流水线加速比:2.463054
2.5.4 流水线的效率
流水线效率:是指流水线设备的利用率。在时空图上,流水线的效率定义为那个任务占用的时空区与k个流水段总的时空区之比。
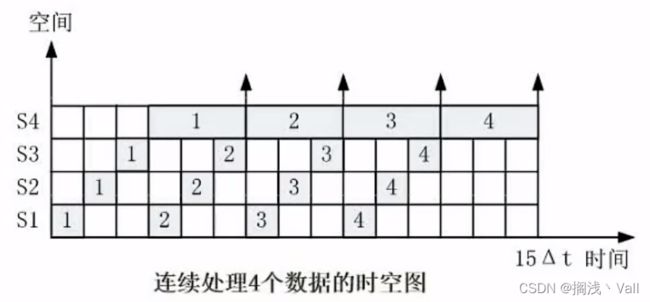 流水线效率公式: 任务占用的时空区(灰的) / 总的时空区(白的)
流水线效率公式: 任务占用的时空区(灰的) / 总的时空区(白的)
已上图为例即(1+1+1+3)* 4 / 15 * 4 = 0.4
2.6 缓存
缓存(cache):缓存是指可以进行高速数据交换的存储器,它先于内存与CPU交换数据,因此速率很快。CPU一般有多层缓存,在计算机存储系统体系中,缓存是访问速度最快的层次。
如果以h代表对Cache的访问命中率,t1表示Cache的周期时间,t2表示主存储器周期时间,以读操作为例,使用“Cache+主存储器”的系统的平均周期为t3,则
t 3 = h ∗ t 1 + ( 1 − h ) ∗ t 2 t_3 = h * t_1 + (1-h) *t_2 t3=h∗t1+(1−h)∗t2
其中(1-h)称为失效率或未命中率

首先,CPU去Cache中取数据,如果Cache里面有则称为命中,没有称为未命中,去内存(主存)中去取。
2.7 局部性原理
在CPU访问寄存器时,无论是存取数据或指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
时间局部性:(循环中)被引用过一次的储存器位置未来会被多次引用
空间局部性:如果一个储存器的位置被引用,那么将来他附近的位置也不会被引用。
工作集理论:程序运行时被频繁访问的页面集合
2.8 主存储器
| 主存储器类别 | 简写 |
|---|---|
| 随机存取存储器(RAM) | DRAM动态、SRAM静态 |
| 只读存储器(ROM) | MROM掩模式、PROM一次可编程、EPROM可擦除、Flash Memory闪存储器(闪存) |
:内存地址从AC000H到C7FFFH,共有112K个地址单元,如果该内存地址按字(16bit)编址,由28片存储芯片构成。已知构成此内存的芯片每片有16K个存储单元,则该芯片每个存储单元存储4bit。
2.9 磁盘
左侧是多叠的磁盘
存取时间 = 寻道时间 + 等待时间(平均定位时间 + 转动延迟)
寻道时间是指磁头移动到磁道所需的时间;
等待时间为等待读写的扇区转到磁头下方所用的实践
:假设某磁盘的每个磁道划分成11个物理块,每块存放1个逻辑记录。逻辑记录R0…R10存放到同一个磁道上,记录的存放顺序如下表所示。
| 物理块 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 逻辑记录 | R0 | R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 |
如果磁盘的旋转周期为33ms,磁头当前处在R0的开始处。若系统是用的单缓冲区顺序处理这些记录,每个记录处理时间为3ms。
Ps:单缓存区意味着只能存放一块逻辑记录,如果没处理完,磁盘可是会接着旋转的。

读取 + 处理R0,定位到R1所消耗时间为:3ms + 33ms = 36ms
那处理到R9,且定位到R10所消耗的时间为:10 * 36ms = 360ms
读取 + 处理R10所消耗的实践为:3ms + 3ms = 6ms
则处理这11个记录的最长(常规)时间为:360ms + 6ms = 366ms

理想态是读取且处理完R0后,磁盘正好转动到R1那里。
即对信息存储进行优化分布后,处理11个记录的最少时间为:66ms
即:[ 3ms(读取)+ 3ms (处理)] * 11 = 66ms
2.10 总线
根据总线所处位置不同,总线通常分为三种:内部总线、系统总线、外部总线。
内部总线:计算机内部各个芯片与处理器之间的总线,类似于CPU与南北桥的线路连接,是芯片级别
系统总线:计算机主板和各个拆线版之间的总线,类似PCIE线,VGA接口线等,是插线板级别,常说的总线就是系统总线。
外部总线:计算机和外设、计算机之间的总线,又称通信总线。
总线分为数据总线、地址总线和控制总线
2.11 串联系统与并联系统
串联系统是组成系统的所有单元中任一单元失效就会导致整个系统失效的系统。
可靠度R:
R = R 1 × R 2 × R 3 . . . . . . . × R n R = R_1 × R_2 × R_3 .......× R_n R=R1×R2×R3.......×Rn
失效率λ:
λ = λ 1 + λ 2 + λ 3 . . . . . . . + λ n λ = λ_1 + λ_2 + λ_3 .......+ λ_n λ=λ1+λ2+λ3.......+λn
并联系统只有当所有子系统失效时,系统才会失效。
可靠度R:
R = 1 − ( 1 − R 1 ) × ( 1 − R 2 ) × ( 1 − R 3 ) . . . . . . . × ( 1 − R n ) R = 1-(1-R_1) × (1-R_2) × (1-R_3) .......× (1-R_n) R=1−(1−R1)×(1−R2)×(1−R3).......×(1−Rn)
失效率λ:
λ = 1 − R λ = 1- R λ=1−R
2.12 差错控制
检错:检查出编码错误
纠错:通过在编码中加入冗余信息(通过增大码距),达到不仅能够检查出错误,还能纠正错误。
码距:一个编码系统的码距是整个系统中任意两个码字的最小距离。
假如将字母A和B进行编码,
A=1,B=0,这样AB之间的最小码距为1,能检错不能纠错。
A=11,B=00,这样AB之间的最小码距为2,能检错不能纠错。
A=111,B=000,这样AB之间的最小码距为3,能检错能纠错
码距d和检错纠错之间的关系。
1.在一个码组内为了检测 a 个误码,要求最小码距应当 d ≥ a + 1
1.在一个码组内为了纠正 a 个误码,要求最小码距应当 d ≥ 2a + 1
2.12.1 循环冗余校验CRC
循环校验码是一种可以进行检错,不能进行纠错的校验码(软考限定,实际上是具有纠错能力的)。通过在编码尾部加入校验信息,让编码后的数据能够进行检错。
将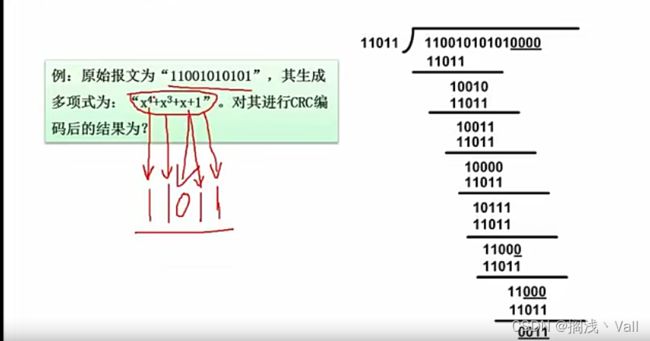
将生成多项式转换成二进制,原始包文补0,补生成多项式长度-1 位。
例题答案:110010101010011
2.12.2 海明码校验码/汉明码Hamming Code
注意:海明码的校验位在2的次方位上,例如1,2,4,8,16位
定义:海明码是一个有多个校验位,拥有检错纠错能力的编码。
基本思想:将有效信息按照某种规律分为若干组,每组安排一个校验位进行就行测试,后产生多位检测信息,并从中得到具体出错位置,将其取反来纠正。
步骤:计算校验位数 → 确定校验码位置 → 确定校验码 → 计算
:求1011的海明码。
1.计算校验位数
假设用 N 表示添加了校验码后整个编码信息的二进制位数长度,用 I 代表其中有效信息位, r 表示添加的校验码位,他们之间的关系应满足:
N = I + r ≤ 2 r − 1 N = I + r ≤ 2^r -1 N=I+r≤2r−1
2 r ≥ I + r + 1 2^r ≥ I + r + 1 2r≥I+r+1
即 4+ r ≤ 2r - 1
2.确定校验码位置
求得校验码位至少为3位,分别放在第20,21,22位。即第1位,第2位和第4位。
| 位数 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|---|
| 信息位 | 1(I4) | 0(I3) | 1(I2) | 1(I1) | |||
| 校验位 | r2 | r1 | r0 |
3.确定校验码
【I4】 7 = 0111 第2,1,0位;即第7位的信息为会影响到 r2 r1 r0
【I3】6 = 0110 第2,1位; 即第6位的信息为会影响到 r2 r1
【I2】5 = 0101 第3,1位;即第5位的信息为会影响到 r2 r0
【I1】3 = 0011 第2,1位;即第3位的信息为会影响到 r1 r0
4.计算
r2 = I4 ⊕ I3 ⊕ I2 = 1 ⊕ 0 ⊕ 1 = 0
r1 = I4 ⊕ I3 ⊕ I1 = 1 ⊕ 0 ⊕ 1 = 0
r0 = I4 ⊕ I2 ⊕ I1 = 1 ⊕ 1 ⊕ 1 = 1
故1011的海明码为1010101
ps:异或运算,同为0,异为1
| a | b | a ⊕ b |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
:纠正海明码1011101的错误。
计算得到的校验码为 100 ,给出的校验码为101,按位异或 得到 001,即第一位错误,将其取反即可,即1011100
三、 操作系统基本原理
3.1 进程
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础,通常一个进程中包含多个线程。有就绪、运行、阻塞三种基本状态。
互斥:在同一时刻,只允许某一个进程使用资源。即同一资源不能同时服务多个资源。反义词是共享。
同步:快的进程等待速度慢的进程。反义词是异步。
生产者 --> /资源/ --> 消费者 //单缓冲区情况
生产者 --> /资源/ /资源/ /资源/ --> 消费者 //多缓冲区情况
单缓冲区只允许消费者或生产者其中之一操作(互斥),多缓冲区不影响生产者往里塞,资源满了生产者才会停下等待,资源空了消费者才会停下来等待(同步)。
3.2 进程管理PV操作
P表示通过的意思,V表示释放的意思,V操作是不具备阻塞的能力的。
临界资源,各个进程中需要抢着使用(互斥)的资源。
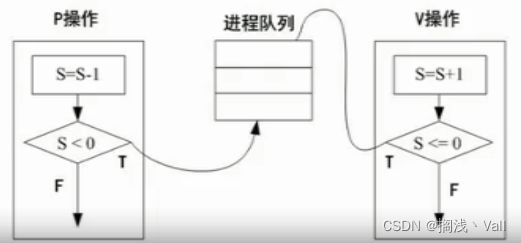
P操作会将信号量S减1,如果S<0则会阻塞进入等待队列,否则继续执行。
V操作会将信号量S加1,如果S≤0则会将进程取出队列,否则继续执行。
:假如S1初值为1,S2初值为0
按时间顺序看如下表格,注意上图是PV操作,不是生产者和消费者别搞蒙了。
| 生产者 | 信号量 | 状态 |
|---|---|---|
| 生产一个产品 P(S1) | S1 = 1 - 1 = 0 | 继续执行 |
| 送产品到缓冲区 V(S2) | S2 = 0 + 1 = 1 | 继续执行 |
| 生产一个产品 P(S1) | S1 = 0 - 1 = -1 | 阻塞进入等待队 |
| 消费者 | 信号量 | 状态 |
|---|---|---|
| P(S2) 从缓冲区取出产品 | S2 = -1 + 1 = 0 | 继续执行 |
| V(S1) 消费产品 | S1 = -1 +1 = 0 | 唤醒生产者继续执行 |
3.3 死锁
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。
:系统有三个进程A,B,C。这三个进程都需要五个系统资源。问系统至少有多少个资源,则不可能发生死锁。
 极端情况:A分配4个资源,B分配4个资源,C分配4个资源,ABC任意一个都不可以运行,所以在加一个资源就可以完成。
极端情况:A分配4个资源,B分配4个资源,C分配4个资源,ABC任意一个都不可以运行,所以在加一个资源就可以完成。
即 (5-1) x 3 + 1 = 13个资源
死锁有四大条件:
互斥,各个进程不能同时使用资源
保持和等待,各个进程不释放自己的资源,等别人的资源
不剥夺,系统不会把已经分配给某个进程的资源调度给其他进程。
环路等待,胡歌三人举枪图.jpg
解决死锁有两种方法:预防和避免,预防是打破四大条件,避免可以通过有序资源分配法和银行家算法进行避免。
银行家算法,思想是以银行放贷的思路来做资源分配。原则如下:
- 当一个进程对资源的最大需求量不超过系统中的资源数时可以接纳该进程
- 进程可以分期请求资源,但请求的总数不能超过最大需求量
- 当系统现有的资源不能满足进程尚需资源数时,对进程的请求可以推迟分配,但总能使进程在有限的时间里得到资源
3.4 存储管理
3.4.1 碎片
碎片分为内部碎片和外部碎片,都是指浪费而不能使用的空间:
内部碎片是指已分配但未被使用的地址空间,操作系统不可利用的空间。
外部碎片是指未分配且未使用的地址空间,该地址空间是可分配的,但是空间过小无法装入资源导致不可用。
3.4.2 地址
物理地址,也是实际地址,物理内存是以字节(8)位为单位编址的。
虚拟地址,为了控制进程之间访问内存不出乱子而定义,是分页时使用的。
线性地址,先简单理解为虚拟地址的同义词,是分页时使用的。
逻辑地址,是分段时使用的。
3.4.3 基址加界限寄存器(动态重定位)
作用:将虚拟地址转换成物理地址,将整个程序作为一个整体,并为每个进程分配一个基址寄存器和界限寄存器,基址寄存器存放该虚拟地址在实际物理地址的起点,而界限寄存器则用以判定程序是否访问非法地址
实际地址 = 虚拟地址 + 基址 实际地址 = 虚拟地址 + 基址 实际地址=虚拟地址+基址
注意:这里的+实际上是拼接

这样会生大量的碎片,村里孩子舍不得。
3.4.4 段式模型
段是信息的逻辑单位,分段是为了满足用户的要求。
分段思想其实就是将基址加界限的概念泛化,在上述例子中,为代码、堆和栈段分别维护一个段基址加段界限寄存器。
分段地址转换与基址加界限的思想大同小异,在分段思想中,程序可能具有多个段,操作系统通过一个段表来维护各段信息:

段基址指该段在物理内存中的起始地址,段长指该段的内存大小。
段表是由段号、段长、基址组成,是二维的
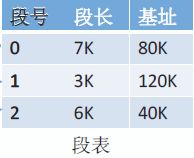
逻辑地址结构是由段号(段名)和段内地址(段内偏移量)所组成。在一个按字节(8位)寻址的系统中,以二进制位表示逻辑地址,假设段号占16位,段内地址占16为,那么他的逻辑地址结构如下图

段表项地址 = 段号 × 段表项大小 + 段表地址
查询该段表项,得到段基址
物理地址 = 段基址 + 段内偏移(段内地址) 物理地址 = 段基址 + 段内偏移(段内地址) 物理地址=段基址+段内偏移(段内地址)

优点:利用保护位(protection bit)为每个段增加了几个位,标识程序是否能够读写该段或执行其中的代码,实现保护和共享功能;按照逻辑分段,符合用户编写代码的逻辑。消除了内部碎片(其实还有但是洒洒水的程度),提高了对物理内存的利用率
缺点:由于分段是离散的在主存内找到空闲的槽块并插,产生过多的外部碎片
ps: 储存分配算法,即如何找空闲的槽块插入的分配算法
- 首次适应法,内存空间地址顺次,找到一个足够分配的空间就用。
- 最佳适应法,将可用内存碎片以空间大小,自小而大排列,找到一个足够分配的空间使用。缺点:产生的碎片多。
- 最差适应法,将可用内存碎片以空间大小,自大而小排列,找到一个足够分配的空间使用。
- 循环首次适应法,将可用内存碎片串起,并排序。第一次用A片区,第二次用B片区,不搁一只羊猛薅。

3.4.5 页式模型
页是信息的物理单位,分页是由于系统管理的需要。
分页思想是将空间分割成较小的、固定长度的分片。分页式管理将程序资源划分为固定大小的页,将每一个虚拟页映射到物理页中。因其固定大小比较整齐,避免了产生了外部碎片。
其次,页在物理内存中也不是连续存在的,进程未使用的页也不会为其分配内存。

物理地址 = 页基址 + 页内偏移 物理地址 = 页基址 + 页内偏移 物理地址=页基址+页内偏移
注意:这里的+实际上是拼接
页式存储中的“页表”是一个一维的表,一个页号就是一个地址。不像分段中既需要段号,也要段地址。
分页式的“逻辑地址”不叫这个名字了,叫虚拟地址,是是页号和页内地址拼成的,结构其实和段式一样,结构如下:

页表是由页号、基址组成,是一维的,由于页式固定每段的段长,所以少了一维。
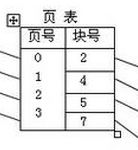
页式地址转换如下:

刚刚说到页表是一个页号对应一个地址,会不会有好些地址导致页表过于庞大捏,存在这种情况,所以发明了多级页表。多级页当前存放的下一级页表的起始地址,并且存在判断下一级页表是否存在的标识。
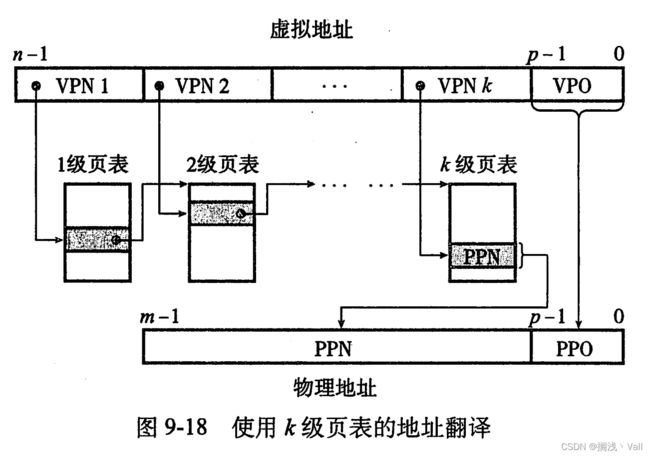
优点:消除了外部碎片,提高了对物理内存的利用率(这半句是废话),利于操作系统管理空闲空间。
缺点:依旧会产生内部碎片,但是每个碎片肯定小于页的大小;页表会很大
3.4.6 段页式存储
思路:将应用程序分段,对每一个段进行页式管理,段页表结构如下:
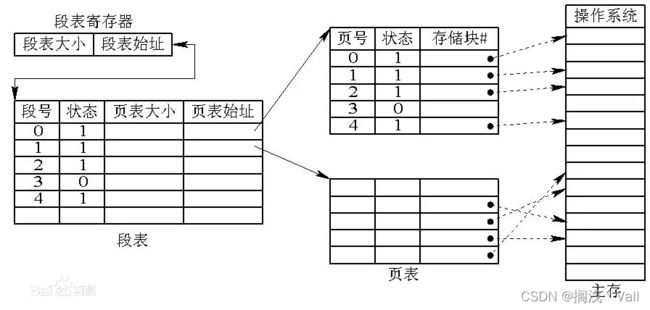
分页式的逻辑地址,由段号、页号、页内地址组成,结构如下

段页式地址转换步骤:
第一次:访问段表,获得页表始址
第二次:访问页表,获取块号,获得指令或数据的物理地址
第三次:按物理地址存取信息

优点:兼具分页分段式的优点
缺点,需要更多硬件支持;如果快表匹配失败,耗时会更久。快表可以理解为一个存放着访问最频繁的虚拟地址到物理地址映射的一个表,是一个硬件设备,由高速缓存器组成。
3.5 文件管理
索引文件结构,引入了一种扩展机制以扩大文件容量。一般的索引文件结构有13个节点,分成了四块索引,直接索引、一级间接索引、二级间接索引、三级间接索引,children套娃结构。

四、 数据库系统
4.1 ER图
ER图中,用椭圆表示属性,用矩形表示实体,菱形表示联系

4.2 笛卡尔积
笛卡尔积(Cartesian product),又称直积,表示为X × Y,是集合的乘积。
4.3 范式
由低到高
第一范式1NF:属性值都是不可分的原子值,即一个属性不能拆分成多个属性
第二范式2NF:消除非主属性
引用:
1.深入解析分段与分页 作者:Happysnaker
2.段式存储管理、段页式存储管理 作者:sHuXnHs