哈啰出行高质量故障复盘法:“3+5+3”(附模板)
# 一分钟精华速览 #
故障复盘指的是及时把过去发生的错误,最大程度转化为未来可以规避的办法,其核心是不断减少失败因子繁衍的温床,将它们牢牢地掌控在不至于引发危机的范围之中。作为国民基础设施的哈啰出行,在保障超5.3亿注册用户体验和系统稳定性过程中,是如何通过系统的、有策略的总结复盘来避免故障重复发生的?
作者介绍

哈啰技术风险负责人——孟闯
十年互联网行业研发经验,2015年加入哈啰出行,参与哈啰业务系统从0到1的建设,作为核心owner主导多个重点稳定性保障项目,在高可用架构、技术风险等领域有丰富经验。目前主要牵头哈啰稳定性保障体系化建设,通过人员组织建设、工具/平台建设、关键项目落地等措施保障哈啰所有业务稳定性。
温馨提醒:本文约6000字,预计花费10分钟阅读。
后台回复 “交流” 进入读者交流群;回复“复盘”或“模板”获取资料;
在文章开始之前,先给大家讲一个故事,多年之前我有过这样的一段复盘经历:
一、故障和复盘真的都是坏事吗?
提到复盘,大多数人第一时间想到的是线上出了故障,这下又要有人背锅了;或者是为那个可怜的兄弟暗暗担心;也或者是因为跟自己无关,所以松了一口气。那么故障和复盘真的都是坏事吗?我们该如何理解它呢?我从以下三点讲一下我对故障和复盘的理解。1.1 正视故障发生的必然性 - 有好也有坏
在聊复盘之前,先聊下我对线上故障的看法,首先,在复杂系统中出现故障是必然的,没有任何系统能保证永远不出现故障,重要的是不能出现重复故障,因此,我们要接受故障可能发生的合理性。接着从定性的角度来看,并非所有的故障都是坏事,有些故障是有正面意义的,比如说通过一个小故障发现了一个大隐患,或者是某次故障中相关人员的意识和应急预案都很到位,但是由于故障的原因非常特殊最后仍然造成了较大的影响等等,类似这样的故障都要找出其中的亮点。
所以,我们要用辩证的眼光去看待故障,避免大家“闻故障色变”。想做好这一点,在公司内部的管理制度上要做一些适当倾斜和引导,比如,鼓励快速恢复(对于快速恢复的故障定级比较低)、鼓励通过演练发现更多的线上问题(对于由于演练导致的故障有一定的豁免权)等等。
有奖也有惩,相比那些鼓励的行为,哪些行为是必须要严肃对待的呢?就是人为导致的犯错。大家应该充分意识到我们对故障的理念:偶尔的系统失效是可以容忍的,人为的犯错是要严肃对待的。比如不符合高可用规范的系统设计模式、强弱依赖设计不合理、由于人员意识不到位带来的故障处理时间较长、值班人员未及时接通oncall、由于对线上系统不够重视带来的变更隐患、不遵守变更三板斧规范等等。
1.2 重在改进 - 关于复盘的3个目的
总之,复盘的目的是为了总结和改进,要充分利用好每一次故障的机会,从中汲取教训进行学习,提升我们的经验,完善系统的设计,强化人员意识等等。从整体稳定性建设的角度来看,希望达到3个目的:
-
1)找到根因,从根本上进行优化和改进-消除隐患,查漏补缺。
-
2)找到降低故障发生概率的方法 - 增大MTBF。
-
3)找到让故障快速恢复的方法 -缩短MTTR。
1.3 不要只优化技术 - 组织和制度也要改进
每次出现故障之后,都能深挖出很多东西,有些看起来是技术问题,但是继续深挖下去,可能会变成管理问题。比如人员应急不到位,为什么Oncall值班制度没有落实到位,关键岗位是否缺少backup机制等等。
我们经常说好的系统架构是具有韧性的,那么好的团队组织也应该是反脆弱的。所以复盘的过程中,除了找系统本身的问题,还要找工具的问题、流程机制的问题、管理的问题等等。这样我们才能由点及面的全面解决问题,既治标又治本。
二、故障复盘按照什么流程进行?
线上出现故障之后,优先解决问题。待故障初步恢复之后,先看一下其他有没有待处理的已知隐患事项,确保隐患消除了再进行复盘。或者至少在复盘的时候,有其他人员在跟进隐患的治理进展。不要出现这边在复盘中,那边又出现了同样故障的情况。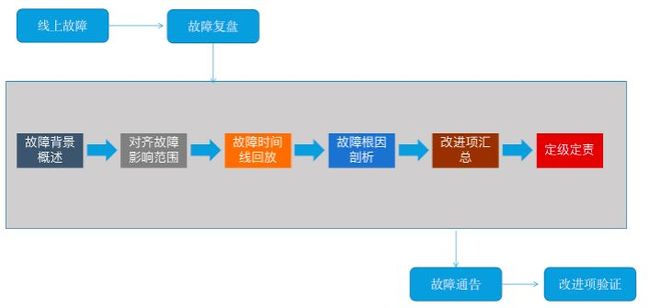
三、开始复盘前需要做哪些准备?
3.1 干系人必须到位
直接原因方、关联(受影响)方等与故障有关的干系人必须全部到场,在复盘文档中记录参会人员名单。同时,视故障的危害程度来确定是否需要更高层级的管理人员到场,比如影响范围超过某种程度的故障必须由TL到场,以此来确保相关定级定责、改进事项落地的有效性和执行力。
3.2 明确复盘owner
每个复盘会议,都必须有唯一的复盘owner,在复盘开始前,由复盘owner来推动各方完成时间线的梳理,搜集故障的影响范围,与各个关联方核实影响的数据,包括业务指标、系统指标、其他指标(客诉、舆情影响等)。同时在会议中,故障的复盘owner要主动引导大家,推动复盘进度,避免出现一些无意义的指责、与故障无关的发散讨论等等。
3.3 理念宣导
复盘的目的是为了总结和改进,但是出了线上故障之后,大家压力都很大,在复盘会议中往往会带着防御的心态来沟通,甚至有时候出现一些互相指责等等。因此,复盘的理念需要提前宣导。
-
理性务实,敢于担当:先从自身找问题,主动提出自己需要改进的地方。
-
心态开放,接受批评:在尊重别人的前提下,所有人都可以提出问题,同时,大家也应该敞开心扉,敢于暴露自己的问题,接受别人的建议或者善意地批评。
四、复盘的关键流程如何落地?
4.1 故障背景概述
故障的背景要解释清楚本次故障复盘的背景,即发生了什么故障,影响了什么业务(产品)等故障的基本情况。在复盘文档中,可以通过结构化的语言进行表达。例如:“x月x日xx时,xxx系统出现异常,导致了xxx,影响了xxx业务,表象为用户无法正常下单,点击下单按钮出现网络开小差,出现了大量客诉等等”。
故障背景的意义在于让别人第一眼了解清楚这个复盘的来龙去脉,根因可以不用写太多,下面会有根因环节。
4.2 对齐故障影响范围
讲清楚本次故障的影响范围,包括影响时间段、影响的业务(产品)线、影响的系统(服务)、订单量、用户量、客诉量,以及有无产生资损等等。从监控的角度看,哪些指标产生了波动,从业务的实际数据看,哪些业务受到了影响。
4.3 故障时间线回放
这个是复盘的重点,很多时候评价复盘的好与坏,就看这个环节能挖出来多少问题。
故障时间线回放,就是指从故障的最源头开始,重新梳理一遍故障的详细过程,包括人员操作、指标变化、监控告警、系统异常、业务实际情况等等。事无巨细,理得越细越好。
因为我们上面提到过,稳定性建设的两个关键要点: 增加MTBF,缩小MTTR。MTTR(故障平均恢复时间)就是指从故障发生开始,到业务恢复的这段时间,我们对MTTR其进行拆解,得到如下几个时间段:MTTR = MTTI + MTTK + MTTF + MTTV。
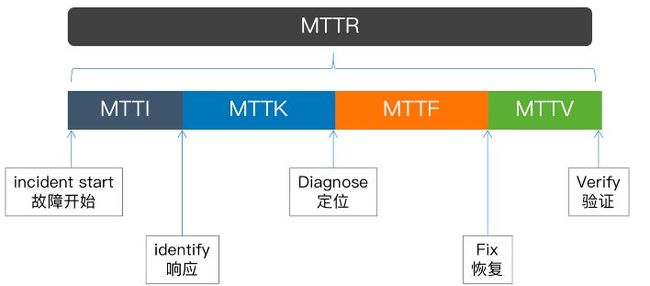
-
1)Mean Time To Identify (MTTI): 从故障开始到应急响应介入的时间,一般是考察监控告警、人员值班oncall的合理性。
-
2)Mean Time To Know (MTTK):从应急响应介入到故障定位的时间,主要考察根因分析、可观测性等工具的能力。
-
3)Mean Time To Fix (MTTF): 从故障定位到故障恢复的时间,主要考察应急预案、快恢体系的能力。
-
4)Mean Time To Verify (MTTV):从故障恢复之后到确认故障已经解决的时间,一般通过用户反馈、自动化测试等确认恢复。
因此,在回放时间线的时候,也要识别出以下几个关键的时间点,然后逐个沟通讨论,如何缩短其中每个环节的耗时。
需要注意提前识别出来的关键事项和时间点:
-
故障引入时间点:即这个故障实际上是从什么时候开始的,可能是某次变更发布/线上操作/其他等。
-
业务指标变化时间点:业务指标何时开始下跌、何时开始恢复等。
-
监控告警发出时间点:即监控是从什么时候发现异常的,告警什么时候发出的。
-
人员介入响应时间点:故障相关的系统值班owner是从什么时候开始响应的。
-
异常定位时间点:即定位到故障的异常点,注意:故障处理过程中的定位是指初因定位,意思是大致定位到了故障点,可以进行下一步的应急止血动作。不是指根因定位,因为有时候找到根因是一件非常难、非常耗时的事情。
-
关键操作时间点:是否做了一些应急预案,包括重启、恢复、止血、高可用配置等。还需要写清楚每个操作的结果,即每个操作之后,报错面有无缩小、系统资源水位有无变化等。
-
确认故障恢复时间点:通过测试验证或者观测业务指标、系统日志等确认系统已经恢复。
重点是对里面的每一步都聊透彻,搞清楚怎么样提升效率、缩短时间。“时间就是金钱”,真正处理过线上故障的同学应该能深刻体会到这句话的分量。故障处理得快1分钟,可能业务上就能少损失很多。
4.4 深挖根因
一般情况下,故障是有两类原因引起的,包括直接(诱发)原因和根本原因,也就是所谓的诱因和根因。
因此在复盘过程中,既要明确诱因,更要深挖根因。比如说,某个业务系统由A/B/C 3个服务组成,依赖关系依次是A依赖B、B依赖C,某次开发同学修改了线上C服务的一个配置,使用了错误的格式,导致了整个业务系统不可用。那么在原因分析过程中,把配置文件修改为错误的格式这个动作肯定是直接原因,但是也要注意,B服务对C服务的依赖关系是强依赖么?如果C服务出现异常的情况下,B服务是否要进行兜底?这里的依赖关系不合理可能就是根因,要分析清楚。
可以基于5why分析法深挖根因,多问几个为什么,层层递进,比如说这样的一个场景: 线上系统运行过程中,某个ES节点突然抖动,RT时间明显变长,95线由200ms升至800ms,然后引发了上游业务异常。那么在分析原因的时候,要问以下几个问题:
1)为什么ES会抖动?
2)ES的可用性标准是什么?
3)ES抖动之后,有出现告警吗?相关人员有第一时间介入处理吗?
4)ES抖动之后,上游直接使用它的服务有兜底措施吗?是否为强依赖?
5)对于这个业务场景来说,ES的直接上游系统是这条链路的核心依赖吗,从整个链路上有无兜底机制?
要层层递进深挖根因,千万不要浅尝辄止,那样可能会错过真正的改进事项。从以往的故障来看,很多问题背后都是系统设计的问题,这样的问题挖得越深,我们的系统可用性才会越强,才能慢慢朝我们理想中的高可用架构前进。
4.5 改进项汇总
把时间线和根因分别确认清楚之后,就能推导出我们对于本次故障复盘的改进事项了。在梳理改进事项的时候,除了与故障相关系统的改进项之外,还需要从整个故障处理过程来看,在故障的各个环节中有无需要优化改进的地方。从 流程制度、团队组织、系统设计、底层工具平台都要综合考虑。
比如某个故障是靠人工(用户投诉)发现的,那么要考虑下这个业务的监控告警是否完善,怎么样能够降低故障触达时间;比如某个故障的告警发出之后,迟迟没有人响应,那么要从管理制度来看,对于应急值班政策的执行是否到位;比如某个故障的排查过程中,定位比较困难,很多地方要靠人工去梳理很多信息,那么要考虑相应的排障工具是否好用;比如定位到问题之后,临时讨论解决方案,那么就要评估相应地应急预案机制是否完善等等。
还有很多其他的问题,大家可以参考上面的MTTR分解环节和故障根因分解环节,自己展开思考下。
在记录改进项的时候,可以考虑结合SMART原则来设计改进项:
1)S - 必须是具体的(Specific),改进项必须是可以落地的,不要泛泛而谈,例如“优化系统设计”这类就属于反例。重新设计A系统对B系统的依赖关系,使其能够对异常进行兜底,这种就属于具体的。
2)M - 必须是可以衡量的(Measurable),即改进项是可以评估的,比如通过故障演练来检验依赖关系的有效性。
3)A - 必须是可以达到的(Attainable),在当前的技术环境下,这个改进项是可行的,不要写未来太远的无法达到的事情。
4)R - 与其他目标具有一定的相关性(Relevant),可以理解与本次故障中其他改进项有关联性。
5)T - 必须具有明确的截止期限(Time-bound),要写清楚改进项的截止时间,在到期之后进行验收。
最后,改进事项重在闭环,即所谓的PDCA循环,Plan(计划)-> Do(执行)-> Check(检查)-> Act(处理),对于我们的故障复盘来说,最后的改进项都要有验证环节,验证通过之后,故障复盘才算是彻底完成。
五、复盘中需要回答哪几个关键问题?
设置问题的目的是引导,通过问题来启发大家思考,并且引导大家往正确的方向去讨论。在复盘过程中,很多参与的同学由于经验或者背景不一样,大家对故障的理解不一定一致,那么复盘的owner要多问一些问题,来引发大家的讨论和思考,从以往的经验中,我们总结了几类问题,大家可以把这个作为讨论的框架:
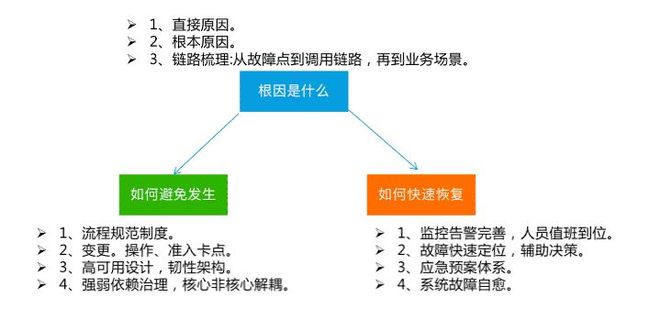
1、故障的根因是什么,它是如何影响到业务可用性的?
当前我们在聊的这个是根因吗?从业务场景对应的链路上看,这个系统(组件)是强依赖吗?依赖是否合理、有无兜底机制。这次的变更流程是否完善、变更三板斧落实的是否到位。对应的观测指标是否能反映系统的真实状态,应急策略是否有效等等。
2、故障为什么会发生,可以避免或者降低发生概率吗?
也就是所谓的提升MTBF,尽可能不出故障,能做到这个自然是最好的结果。
如果是变更引起的,那么要考虑变更流程是否完善,是否按照流程规范操作,有无对应的防御机制。比如变更是否严格按照测试环境、预发环境、生产环境流程执行的,为什么没能在前面发现问题,是否可以在灰度环节发现问题。
如果是某个系统组件失效导致的,那么要评估该组件的可用性是多少,与它所在的链路是否匹配,这条链路是否要设计兜底方案等。比如某个低SLA的系统组件是否在核心链路中。
如果是外部原因引起的,那么就需要认真评估外部依赖的稳定性情况,对方的可用性能够满足我们的诉求。是否把可用性写入到合作条款中,不满足SLA之后是否有相应的补偿或者惩罚等。
3、我们应该做什么,才能更快的恢复业务?
1)监控告警 - 这个故障是如何被发现的,监控告警是否足够完善,我们能否更快一点去发现这个问题。(扩展阅读:)
2)管理制度 - 人员值班响应oncall是否及时,关键人员是否就位,关键岗位有无backup机制,系统owner对负责的组件是否足够熟悉。
3)定位效率 - 现有的排查工具是否好用,有无需要优化的地方,故障定位的时间能否再缩短一点,故障的处理原则是以止血恢复优先,当时的故障处理过程中,有无跑偏方向。
4)应急预案 - 故障处理过程中,是否有应急预案,应急预案是否奏效?日常是否通过故障演练来验证应急预案的有效性。
5)架构设计 - 架构本身的高可用是否完善,是否具有容灾能力。
6)流程规范 - 现有的制度规范是否完善,有无需要优化的。
扩展阅读:
故障复盘究竟怎么做?美图SRE结合10年经验做了三大总结(附模板)
六、故障定级与定责
由于每家公司都有自己的定级与定责制度,这里不做赘述,只说几个关键点。
6.1 故障定级
一般按用户体验、GMV、客诉率等指标来综合计算,每家公司有自己的计算方式。这里不赘述,大家结合实际情况来制定就行。定级的原则可以与业务方一起沟通,一般找几个关键的指标作为参考维度,然后按不同的体量设置不同的级别。
6.2 故障定责
-
定责首先对应的是团队,然后是个人:很多故障只是表象,大部分根因深挖下去,都会有技术管理的因素,虽然引发故障的操作可能是个人,但是更应该从团队的视角去看问题,避免把根因只归结到某个人身上,越是高级别的故障,越要避免简单归因。这里举一个例子:某个新入职的同学,因为操作不得当引发了一个线上问题。这里就要注意,为什么新人可以直接操作线上环境,入职之后是否有相应的培训或者文档让他学习,告诉他如何避免高危操作。(扩展阅读:故障定责定的到底是什么责?)
-
鼓励快速止血和积极参与:对于故障处理过程中,积极参与定位、止血等操作的,给与正面的肯定。对于那些积极主动参与线上救火的同学,用制度为他们兜底。
-
第三方默认无责:如果因为第三方合作方或者服务商出了线上故障,那么在做内部复盘的时候,需要让内部的对应团队来担责,避免把责任归给第三方。即谁引入了第三方的技术组件,谁就要对其可用性负责。这就可以反过来要求我们在使用外部技术组件的时候,要仔细评估对方的可用性情况,以及我们的兜底方案等等。
-
红线和军规:研发规范中,要设定好红线和军规,比如说高峰期严禁变更、变更流程必须符合三板斧(可灰度、可观测、可应急)原则等等。红线和军规是稳定性的底线,坚决不能违反。很多军规都是以往的各个故障血泪史中沉淀出来的,必须遵守且尊重这些红线军规,把它当做铁律。
-
重复犯错必须严肃对待:未知的故障不可怕,可以用来丰富我们的稳定性建设经验,但是重复的踩坑就需要认真对待了,要思考为什么以往的改进事项没有落实到位等等。
写在最后
回过头来再看我们最开始讲的那个故事,如果你是复盘owner,你会怎么做呢,能不能问出以下几个问题?
- BUG为什么会被带到线上环境,线下环境为什么没发现呢,是case覆盖度不够还是其他原因?
- 变更的流程足够规范么,有无进行灰度,在灰度阶段能发现吗?
- 为什么故障先由外部发现,我们自己如何尽早发现故障,监控告警的覆盖度够么,粒度足够细么?
上面说到,复盘不是故障的结束,改进事项经过验收才算彻底结束,因此每一个改进事项的相关方,都应积极主动地push完成。同时,为了最大化的利用好复盘文档的价值,我们未来也考虑通过以下几点来充分利用复盘价值:
1)团队的新人入职后,先组织学习以往的复盘文档,吸收前人经验,避免重复踩坑。
2)把以往故障作为素材,放入到团队日常的稳定性文化建设中,比如通过考试等形式加深大家对故障的理解和记忆。
最后再重复一句:故障不可怕,重复的故障才可怕。
了解更多故障复盘细节,欢迎扫码进入 「读者交流群」,和老师实时互动。
公众号后台回复【复盘模版】获取资料
更多内容欢迎点击“阅读原文”,进入「TakinTalks稳定性社区」,获取更多稳定性相关资料和知识。
声明:本文由公众号「TakinTalks稳定性社区」联合社区专家共同原创撰写,如需转载,请后台回复“转载”获得授权。