Spring源码深度解析笔记(4)——事务
Spring声明式事务让我们从复杂的事务处理中解脱出来,使我们不需要去处理获得连接、关闭连接、事务提交和回滚等操作,再也不需要在与事务相关的方法中处理大量的try…catch…finally代码。Spring事务的使用虽然已经相对简单,但是,还是有很多的使用及配置规则。
创建Spring配置文件
10.2 事务自定义标签
对于Spring中事务功能的代码分析,首先从配置文件开始入手,在配置文件中有这样一个配置:
在自定义标签中解析过程中Spring做了一些辅助操作,关键字annotation-driven,最终锁定类TxNamespaceHandler的init方法,在遇到注入
在解析中存在对于mode属性的判断,如果需要使用AspectJ的方式进行事务切入(Spring中的事务是以AOP为基础的)。
10.2.1 注册InfrastructureAdvisorAutoProxyCreator
以默认配置为例子进行分析,进入AopAutoProxyConfigurer类的configureAutoProxyCreator:
// 注册nfrastructureAdvisorAutoProxyCreator类型的bean
AopNamespaceUtils.registrerAutoProxyCreatorIfNecessary(parserContext,element)
// 创建TransactionAttibuttributeSource的bean
RootBeanDefinition sourceDef = new RootBeanDefinition (Annotation TransactionAttibuttributeSource.class);
// 创建TransactionInterceptor的bean
RootBeanDefinition interceptorDef = new RootBeanDefinition (TransactionInterceptor.class);
// 创建TransactionAttibuttributeSourceAdvisor的bean
RootBeanDefinition advisorDef = new RootBeanDefinition (BeanFactoryTransactionAttibuttributeSourceAdvisor.class);
// 将sourceName的bean注入到advisorDef 中
advisorDef.getPropertyValues().add("transactionAttibuttributeSource",new RunTimeBeanReference(sourceName));
// 将interceptorName的bean注入到advisorDef 的adviceBeanName属性中,如果配置了order属性,则加入到bean中
advisorDef.getPropertyValues().add("adviceBeanName",interceptorName);
代码中注册了代理类和三个bean,这是哪个bean支撑了真个事务功能,首先,其中的两个bean被注册到一个advisorDef的bean中,advisorDef使用BeanFactoryTransactionAttibuttributeSourceAdvisor作为其class属性,也就是说BeanFactoryTransactionAttibuttributeSourceAdvisor代表这当前bean。
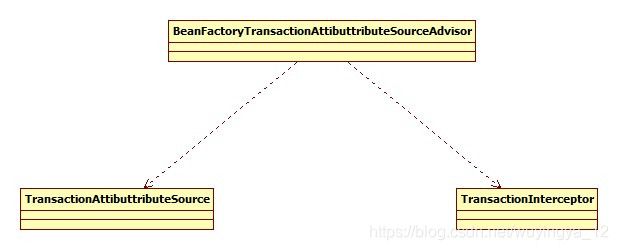
上面函数configureAutoProxyCreator中的第一句貌似很简单但是却是很重要的代码:
AopNamespaceUtils.registrerAutoProxyCreatorIfNecessary(parserContext,element);
// 进入这个函数
AopConfigUtils.registerAutoProxyCreatorIfNecessary(...)
// 进入这个函数
return registerOrEscalatteApcAsRequired(InfrastructureAdvisorAutoProxyCreator.class,registry,source);
上面的两个函数的主要目的是注册了InfrastructureAdvisorAutoProxyCreator类型的bean。
在Spring中,所有bean实例化的时候都会保证调用其postProccessAfterInitialization方法,其实现是在AbstractAutoProxyCreator类中实现的。
// 根据给定的bean的class和name构建出个key,beanClassName_name
Object cacheKey = getCacheKey(bean.getClass() , beanName);
// 是否由于避免循环依赖而创建的bean代理
return wrapIfNecessary(bean,beanName,cacheKey);
这里实现的主要目的是对指定bean进行封装,首先要确定是否需要封装,检测及封装的工作委托给了wrapIfNecessary函数进行
// 如果已经包含则直接返回bean
// 给定的bean类是否代表一个基础类,不应代理,或者配置了指定bean不需要自动代理
// 找出指定bean对应的增强器,并根据找出的增强器创建代理
Object[] specificInterecptors = getAdvicesAndAdvisorsForBean(bean.class(),beanName,null);
10.2.2 获取对应class/method的增强器
获取对应bean对应的增强器,其中包含两个关键字:增强和对应,也就是在getAdvicesAndAdvisorsForBean函数中,不但要找到增强器,而且还需要判断增强器是否满足要求。
// 寻找候选增强器
List candidateAdvisors = findCandidateAdvisors();
// 候选增强器中寻找匹配项
List eligibleAdvisors = findAdvisorsThatCanApply(candidateAdcisors,beanClass,beanName);
- 在函数findCandidateAdvisors中advisorsRetrievaHelper.findAdvisorBean()完成的就是获取增强器的功能
// 通过BeanFactoryUtils类提供的工具方法获取所对应的Advisor的类
advisorName = BeanFactoryUtils.beanNameForTypeIncludingAncestors(this.beanFactory,Advisor.class,true,false);
// 通过BeanFactory根据advisorName获取增强器实例,并将Advisor 实例添加到集合中供候选增强器中寻找匹配项使用
Advisor obj = this.beanFactory.getBean(name,Advisor.class);
- 候选增强器中寻找匹配项
当找出对应的增强器,接下来的任务就是看这些增强器是否与对应的class匹配,当然不只是class,class内部方法如果匹配也可通过验证。
// 首先处理引介质增强
canApply(candidate,clazz)
当前需要对方法分析是否使用于此增强方法,那么当前的adviseor就是之前查出来的BeanFactoryTransactionAttributeSourceAdvisor的bean对象,而BeanFactoryTransactionAttributeSourceAdvisor又简介实现了PointcutAdvisor,因此,在canApply函数的第二个if判断时就会通过判断,会将BeanFactoryTransactionAttributeSourceAdvisor中的getPointcut()方法的返回值作为参数继续调用canApply方法,而getPointcut()方法返回的是TransactionAttributeSourcePointcut类型的实例。而TransactionAttributeSource这个属性就是在解析标签是注入进去的。
// 使用TransactionAttributeSourcePointcut类型的实例作为参数继续跟踪canApply
MothodMatcher mothodMatcher = pc.getMothodMatcher();
mothodMatcher.matches(mothod,targetClass);
通过上面的函数大致可以理清大体脉络,获取对应的类的所有接口并连同类本身一起遍历,遍历过程中的方法再次遍历,一旦匹配成功便认为这个类适用于当前增强器。做匹配的时候mothodMatcher.matches(mothod,targetClass)会使用TransactionAttributeSourcePointcut类的matches方法
tas.getTransactionAttribute(...)
此时的tas表示AnnotationTransactionAttributeSource类型,而AnnotationTransactionAttributeSource类型的getTransactionAttribute方法如下
TransactionAttribute txAtt = compareTransactionAttribute(method,targetClass)
- 提取事务标签
在compareTransactionAttribute函数中我们看到了事务标签的提取过程。
// 查看方法中是否存在事务声明
TransactionAttribute txAtt = findTransactionAttribute(specificMethod);
// 查看方法所在的类是否事务声明
txAtt = findTransactionAttribute(specificMethod.getClass());
// 如果存在接口则在接口中寻找
txAtt = findTransactionAttribute(method);
txAtt = findTransactionAttribute(method.getDeclaringClass());
对于事务属性的获取规则相信大家都已经很清楚了,如果方法中存在事务,则使用方法上的属性,否则使用方法所在的类上的属性,如果方法所在的类的属性上还是没有搜寻到对应的事务属性,那么再次搜寻接口中的方法,最后尝试搜寻接口的类上面的声明。对于函数compareTransactionAttribute中 的逻辑与我们认识的规则并无差别,但是上面的函数并没有真正的区做搜寻的事务属性的逻辑,而是搭建了一个执行框架,将搜索事务的任务委托给了findTransasictionAttribute方法执行。
determineTansactionAttribute(method);
其中this.annotationParsers实在当前类AnnotationTransactionAttributeSource初始化的时候初始化的,其中的值被加入了SpringTransactionAnnotationParser,也就是当进行属性获取的时候其实是使用SpringTransactionAnnotationParser类的parseTransactionAnnotation进行解析。
至此,终于看到了获取注解标记的代码。首先会判断当前类是是否含有Transactional注解。这是事务属性的基础。如果有的话会继续调用parseTransactionAnnotation方法进行详细的属性。
RuleBaseTransactionAttrubue rbta = new RuleBaseTransactionAttrubue();
// 解析propagation
rbta.setPropagationBehavior(ann.propagation().value());
// 解析isolation
rbta.setIsolationLevel(ann.isolation().value());
// 解析timeout
rbta.setTimeOut(ann.timeout());
// 解析readOnly
rbta.setReadOnly(ann.readOnly());
// 解析value
rbta.setQualifier(ann.value());
// 解析rollBackFor
// 解析rollBackForClassName
// 解析noRollBackFor
// 解析noRollBackForClassName
上述方法中实现了对对应类或者方法的事务属性解析,会在这个类中看到任何常用或者不常用的属性提取。
至此,我们完成了事务标签的解析,在回顾一下,我们现在的任务是找出某个增强器是否适合对应的类,而是否匹配的关键则是在于是否从指定的类或者类中的方法中找到对应的事务属性。
至此,事务功能的初始化工作便结束了,当判断某个bean适用于事务增强时,也就是适用于增强器BeanFactoryTransationAttrubuteSourceAdvisor,所以说,在解析自定义标签时,注入的这个类称为了整个事务功能的基础。
BeanFactoryTransationAttrubuteSourceAdvisor作为Advisor的实现类,自然遵从Advisor的处理方式,当代理被调用时会调用这个类的增强方法,也就是此Bean的Advise,又因为在解析事务定义标签时把TransactionInterceptor类型的bean注入到了BeanFactoryTransationAttrubuteSourceAdvisor中,所以在抵用事务增强器增强的代理类时会首先执行TransactionInterceptor进行增强,同时,也就是类中的invoke方法中完成整个事务的逻辑。
10.3 事务增强器
TransactionInterceptor支撑着整个事务功能的框架,逻辑还是相对复杂的,现在开始分析此拦截器是如何实现事务特性的。TransactionInterceptor类继承自MethodeInterceptor,所以调用该类是从其invoke方法开始的。
// 获取对应事务属性
getTransactionAttribute(invocation.getMethod(),targetClass);
// 获取beanFactory的transactionManager
// 构造方法唯一标识
// 如果是声明式事务
// 创建TransactionInfo
createTransactionIfNecessary(tm,txAttr,joinpoint,Identification);
// 执行被增强方法
invocation.proceed()
// 异常回滚
completeTransactionAfterThrowing(txInfo,ex);
// 清除信息
clearupTransactionInfo(txInfo);
// 提交事务
commitTransactionAfterReturn(txInfo);
// 编程式事务处理
从上面的函数中,在Spring中支持两种事务处理的方式。分别是声明式事务处理和编程式事务处理,两种相对于开发人员的差别很大,但对于Spring中的实现来讲,大同小异。在invoke中也可以看到这两种方式的实现,对于声明式的事务处理主要有几种步骤:
- 获取事务的属性,对于事务处理来说,最基础或者最首要的工作就是获取事务属性了,这是支撑整个功能的基石,如果没有事务属性,其他功能也无从谈起,在分析事务准备阶段时已经分析了事务的提取功能
- 加载配置中配置的TransactionManager
- 不同的事务处理方式使用不同的逻辑,对于声明式事务和编程式事务的处理,第一点区别在于事务属性上,因为编程式事务处理是不需要有事务属性的,第二点区别就是TransactionManager上,CallbackPreferringPlatformTransactionManager实现PlatformTransactionManager接口,暴露出一个方法执行事务处理中的回调。所以,这两种方式都可以用作事务处理方式的判断。
- 在目标方法执行前获取事务并收集事务信息。事务信息和事务属性并不相同,也就是TransactionInfo与TransactionAttribute并不相同,TransactionInfo中包含TransactionAttribute信息,但是,粗了TransactionAttribute还有其他事务信息
- 执行目标方法
- 一旦出现异常,尝试异常处理,并不是所有异常,Spring都会回滚,默认只对RuntimeException回滚。
- 提交事务前的事务信息清除。
- 提交事务。
10.3.1 创建事务
首先分析事务创建的过程createTransactionIfNecessary(tm,txAttr,joinpoint,Identification)
// 如果没有名称指定则使用方法唯一标识,并使用DelegatingTransactionAttribute封装txAttr
// 获取TransactionStatus
tm.getTransaction(txAttr);
// 根据指定的属性与Status准备一个TransactionInfo
prepareTransactionInfo(tm,txAttr,joinpointIdentification,status);
对于createTransactionIfNecessary函数主要做了这样几件事
- 使用DelegatingTransactionAttribute封装传入TransactionAttrbute实例。对于传入的TransactionAttrbute实例的参数txAttr,当前的实际类型是RuleBasedTransactionAttrbute,是有获取事务属性时生成的,主要用于数据承载,而这里之所以使用DelegatingTransactionAttribute进行封装,是提供了更多的功能。
- 获取事务,事务处理当然是以事务为核心,那么获取事务就是最重要的事情。
- 构建事务信息,根据之前的几个步骤的信息构建TransactionInfo并返回。
- 获取事务
Spring中使用getTransaction来处理事务的准备工作,包括事务获取以及信息的构建。
doGetTransaction();
// 判断当前线程是否存在事务,判断依据为当前线程记录的连接不为空且连接中(connectionHolder)中的transcationActive属性不为空
// 当前线程已经存在事务
handleExistingTransaction(definition,transaction,debugEnabled);
// 事务超时设置验证
//如果当前线程不存在事务,但是propagationBehavior却被声明为PROPAGATION_MANDATORY抛异常。
// 构造transaction,包括ConnectionHolder,隔离级别,timeout,如果是新连接,绑定到当前线程
doBegin(transaction,definition);
// 新同步事务的设置,针对当前线程的设置
prepareSynchronization(status,definition);
当然,在Spring中的每个复杂的功能实现,并不是一次完成的,而是通过入口函数进行一个框架的搭建,初步构成完整的逻辑,而将实现细节分摊给不同的函数,其中准备工作包括:
- 获取事务,创建对应的事务实例,这里使用的是DataSourceTransactionManager中的doGetTranscation方法,创建基于JDBC的事务实例,如果当前线程中存在关于dataSource的连接,那么直接使用,这里有一个对保存点的设置,是否开启允许保存点取决于是否设置了允许嵌入式事务。
- 如果当前线程存在事务,则转向嵌套事务的处理。
- 事务超时设置验证。
- 事务propagationBehavior属性的设置验证。
- 构建DefaultTransactionStatus。
- 完成transaction,包含ConnectionHolder,隔离级别,timeout,如果是新连接,则绑定到当前线程。
对于一些隔离级别,timeout等功能的设置并不是有Spring来完成的,而是委托给底层的数据库连接去做的,而对于数据库连接的设置就是在doBegin函数中处理的。
// 设置隔离级别
DataSourceUtils.prepareConnectionForTransaction(con,definition);
// 更改自动提交设置,由Spring控制提交
// 设置判断当前线程是否存在事务的依据
// 将当前获取到的连接绑定到当前线程
可以说事务是从这个函数开始的,因为在这个函数中已经开始尝试了对数据库连接的获取,当然,在获取数据库连接的同时一些必要的设置也是需要同步设置的。
- 尝试获取连接,当然并不是每次都会获取新的连接,如果当前线程中connectionHoder已经存在,则没有必要再次设置,或者,对于事务同步标识为true的需要重新获取连接。
- 设置隔离级别以及只读标识,Spring中针对只读操作做了一些处理,但是核心的实现是设置connection上readOnly属性。对于隔离级别的控制也是交由connection去控制的。
- 更改默认提交设置,如果事务属性是自动提交,那么需要更改这种设置,而将提交操作委托给Spring来处理。
- 设置标志位,标识当前连接已经被事务激活
- 设置过期时间。
- connectionHolder绑定当前线程。
设置隔离级别的prepareConnectionForTransaction函数用于负责底层数据库连接的设置,当然,只包含只读标识和隔离级别的设置。由于强大的日志及异常处理,显得代码量比较大,但是单从业务角度去看,关键代码其实并不多。
- 处理已经存在的事务
之前讲述了普通事务建立的过程,但是Spring中支持多种事务的传播行为,对于已经存在的事务,准备操作是如何进行?handleExistingTransaction(definition,transaction,debugEnabled)
// 新事务的建立
// 嵌入式事务的处理
// 有些情况是不能使用保存点操作,比如JTA,那么建立新事务
对于已存在事务的处理过程中,函数对已经存在的事务处理考虑了两种情况
- PROPAGATION_REQUIRES_NEW 表示当前方法必须在它自己的事务里运行,一个新的事务将被启动,而如果有一个事务正在运行的话,则这个方法运行期间被挂起。而Spring中对此种传播方式的处理与新事务建立最大的区别在于使用suspend方法将原事务挂起,将信息挂起的目的当然是为了在当前事务执行完毕后再将原来事务还原。
- PROPAGATION_NEWSTED 表示如果当前有一个事务在运行中,则该方法应该运行在一个嵌套的事务中,被嵌套的事务可以独立于封装事务进行提交或回滚,如果封装事务不存在,行为就像PROPAGATION_REQUIRES_NEW。对于嵌套事务的处理,Spring主要考虑两种方式的处理
2.1 Spring中允许嵌入事务的时候,则首选设置保存点的方式作为异常处理的回滚。
2.2 对于其他方式,比如JTA无法使用保存点的方式,那么处理方式和PROPAGATION_REQUIRES_NEW相同,而一旦出现异常,则由Spring的事务异常处理机制去完成后续操作。
对于挂起的主要目的是记录原有事物的状态,以便后续操作对事务的恢复suspend(Object transaction)。
- 准备事务信息
当已经建立事务连接并完成了事务信息的提取后,需要将所有的事务信息统一记录在TransactionInfo类型的实例中,这个实例包括目标方法开始前的所有状态信息,一旦事务执行失败,Spring会通过TransactionInfo类型的实例中的信息进行回滚等后续操作。
10.3.2 回滚处理
之前完成了目标方法运行前的事务准备工作,而这些准备工作最大的目的无非是对于程序没有按照我们期待的那样进行,也就是出现特定的错误,那么出现错误时,Spring怎么对数据进行恢复的呢?completeTransactionAfterThrowing(txInfo,ex)
// 当抛出异常时首先会判断当前是否存在事务,这是基础依据
// 判断是否回滚默认的依据是抛出异常是否是RuntimeException或者Error的类型
txInfo.transactionAtribute.rollbackOn(ex)
// 根据Transaction信息进行回滚处理
txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
// 如果不满足回滚条件即使抛出异常也同样会提交
在对目标方法执行过程中,一旦出现Throwable就会被引导至此方法处理,但是不代表所有的Throwable都会被回滚处理,比如最常见的Exception,默认是不会被处理的。默认情况下,即使出现异常也会被正常提交,而这个关键就在于txInfo.transactionAtribute.rollbackOn(ex)这个函数。
- 回滚条件,默认情况下Spring中的事务异常处理机制只对RuntimeException和Error两种情况感兴趣,当然也可以通过扩展来改变,最常用的方式是使用事务提供的属性进行设置。
- 回滚处理,当然一旦符合回滚条件,那么Spring就会将程序引导至回滚处理函数中。
// 如果事务已完成,那么再次回滚会抛出异常,否则执行processRollBack(DefaultTransactionStatus status)函数
processRollBack(DefaultTransactionStatus status);
// 激活所有TransactionSynchronization中对应的方法
// 如果有保存点,也就是当前为单独线程则会推到保存点
status.rollbackToHoldSavepoint();
// 如果当前的事务为独立的新事务,则直接退回
doRollback(status);
// 如果当前事务不是独立事务,那么只标记状态,等待事务链执行完毕后统一处理。
doSetRollback(status);
// 清空记录的资源并将挂起的资源恢复
clearupAfterCompletion(status);
同样,对于在Spring中的复杂逻辑处理过程中,在入口函数一般都会给出整个的处理脉络,而把实现细节委托给其他函数去执行。
- 首先是自定义触发器的调用,包括在回滚前,完成回滚后的调用,当然完成回滚包括正常的回滚和回滚过程中出现异常,自定义的触发器会根据这些信息作进一步处理,而对于触发器的注册,常见的回调过程是通过TransactionSynchronizationManager类中的静态方法直接注册的
- 除了触发器的监听函数外,就是真正的回滚逻辑的处理了。
2.1 当之前已经保存的事务信息中有保存点信息的时候,使用保存点信息进行回滚。常用于嵌入式事务,对于嵌入式事务的处理,内嵌式事务的异常不会引起外部事务回滚,根据保存点回滚的实现方式其实是根据底层数据库连接进行的。这里使用的是JDBC的方法进行数据库连接,那么getSavepointManager()函数返回的是JdbcTransactionObjectSurpport,也就是调用JdbcTransactionObjectSurpport中的rollbackToSavepoint方法
2.2 当之前已经保存的事务信息中事务为新事务,那么直接回滚。常用于单独事务的处理。对于没有保存点的回滚,Spring同样是使用底层数据库连接提供的API来操作的。由于使用的是DataSourceTransactionManager,那么doRollback韩式会使用此类中的实现。
2.3当前事务信息中表明是存在事务的,又不属于上述两种情况,多用于JTA,只做回滚标识,等到提交的时候统一不提交。
- 回滚后的信息清除
对于回滚逻辑执行结束后,无论回滚是否成功,都必须要做的事情就是事务结束后的收尾工作。clearupAfterCompletion
doCleanAfterCompletion(status.getTransaction());
// 结束之前事务挂起状态
resume(status.getTransaction(),(SuspendedResourceHolder)status.getSuspendedResources());
从函数中得知,事务处理的收尾处理工作包括如下内容。
- 设置状态是对事务信息作完成标识以避免重复调用。
- 如果当前事务是新的同步状态,需要将绑定到当前线程的事务信息清除。
- 如果实现事务需要做些清除资源的工作。
3.1 将数据库连接从当前线程中接触绑定
3.2 释放连接
3.3 恢复数据库连接的自动提交属性
3.4 重置数据库连接
3.5 如果当前事务是独立的新创建的事务则在事务完成时释放数据库连接。- 如果事务执行前有事务挂起,那么当前事务执行结束后需要将挂起的事务恢复。
10.3.3 事务提交
之前分析了Spring的事务异常处理机制,那么事务的执行没有出现任何异常的,也就意味着事务可以走正常提交事务的流程了。
commitTransactionAfterReturn(txInfo);
在真正的数据提交之前,还需要做个判断。当某个事务既没有保存点又不是新事务,Spring对他的处理方式只是设置一个回滚标记。这个回滚标记就在这里派上用场了,主要的应用场景有。
某个事务是另一个事务的嵌入式事务,但是这些事务又不在Spring管理范围内,或者无法设置保存点,那么Spring会通过设置回滚标识的方式禁止提交。首先当某个嵌入事务发生的回滚的时候会设置回滚标识,而等到外部事务提交时,一旦判断当前事务流被设置了回滚标识,则由外部事务来统一进行整体事务的回滚。所以当事务没有被异常捕获的时候也并不意味着一定会执行提交过程。
当事务执行一切都正常的时候,便可以真正的进入提交流程了processCommit(…)
// 预留
prepareForCommit(status);
// 添加transactionSynchronization中对应方法调用
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
// 如果存在保存点则清除保存点信息
status.releaseHeldSavepoint();
// 如果是独立的事务则直接提交
doCommit(status);
在提交的过程也并不是直接提交的,而是考虑了诸多的方面,符合提交的条件如下。
- 当事务状态中有保存点信息的话便不会去提交事务。
- 当事务非新事务的时候也不会去执行提交事务操作。
此条件主要考虑的是嵌入式事务的情况,对于嵌入事务,在Spring中正常的处理方式是将内嵌事务开始之前设置保存点,一旦内嵌事务出现异常便根据保存点信息进行回滚,但是如果没有出现异常内嵌事务不会单独提交,而是根据事务流由最外层事务进行提交,所以当前存在保存点信息便不是最外层事务,不做保存操作,对于是否是新事物的判断也是基于此考虑。
如果程序流通过事务的层层把关,最会顺利的进入提交流程,那么同样,Spring将事务提交的操作引导至底层数据库连接的API,进行事务提交。