【算法基础】基础算法(三)--(双指针算法、位运算、离散化、区间合并)
一、双指针算法
- 双指针算法是一种通过设置两个指针不断进行单向移动来解决问题的算法。
1、双指针算法模板
记忆!
for (int i = 0, j = 0; i < n; i ++ )
{
while (j < i && check(i, j)) j ++ ;
// 具体问题的逻辑
}常见问题分类:
(1) 对于一个序列,用两个指针维护一段区间, 比如:快速排序的划分过程。
(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作。【数据结构】排序(插入、选择、交换、归并) -- 详解_炫酷的伊莉娜的博客-CSDN博客
2、思路


原本两个指针是有 n² 种组合,因此时间复杂度是 O(n²) 。
而双指针算法就是运用单调性使得指针只能单向移动,因此总的时间复杂度只有 O(2n),也就是 O(n)。双指针算法的核心思想是将两重循环的暴力做法优化到 O(n)。
因为双指针算法是一种优化时间复杂度的方法,所以我们可以首先写出最朴素的两层循环的写法。然后再考虑题目中是否具有单调性。
即当其中一个指针 i 向后移动时,在希望得到答案的情况下,另一个指针 j 是不是只能向着一个方向移动。如果是,说明题目具有单调性,可以通过双指针算法优化。
3、练习
799. 最长连续不重复子序列 - AcWing题库
800. 数组元素的目标和 - AcWing题库
2816. 判断子序列 - AcWing题库
二、位运算
1、位运算模板
记忆!
- 求 n 的第 k 位数字:n >> k & 1
- 返回 n 的最后一位 1:lowbit(n) = n & -n
2、 思路
(1)求 n 的第 k 位数字
- 先把第 k 位移到最后一位:n >> k
- 看个位是几:x & 1
【总结】n >> k & 1
(2)返回 n 的最后一位 1
n = 1010; lowbit(n) = 10;
n = 101000; lowbit(n) = 1000;
n & -n = n & (~n+1)
n = 1010... ...100...0
~n = 0101... ...011...1
~n+1 = 0101... ...100...0
综上所述,n & (~n+1) = 0000... ...100...0
【总结】lowbit(n) = n & -n
int lowbit(int x)
{
return x&(-x);
}
int lowbit(int x)
{
return x&(~x+1);
}原码、反码、补码可了解:【C语言】深度剖析数据在内存中的存储_炫酷的伊莉娜的博客-CSDN博客
3、练习
801. 二进制中1的个数 - AcWing题库
三、离散化
离散化是指,将无限的数据,映射到有限的空间中并保留原来的全 / 偏序关系。
离散化的本质是建立了一段数列到自然数之间的映射关系(value -> index),通过建立新索引,来缩小目标区间,使得可以进行一系列连续数组可以进行的操作比如二分,前缀和等…
1、离散化模板
记忆!
vector alls; // 存储所有待离散化的值
sort(alls.begin(), alls.end()); // 将所有值排序
alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 去掉重复元素
// 二分求出x对应的离散化的值
int find(int x) // 找到第一个大于等于x的位置
{
int l = 0, r = alls.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1; // 映射到1, 2, ...n
} 2、思路
离散化首先需要排序去重:
- 排序:sort(alls.begin(),alls.end())
- 去重:alls.earse(unique(alls.begin(),alls.end()),alls.end());
【实现原理】
以下以一维数组给出示例,将数据离散化到 [0,n-1] 的范围
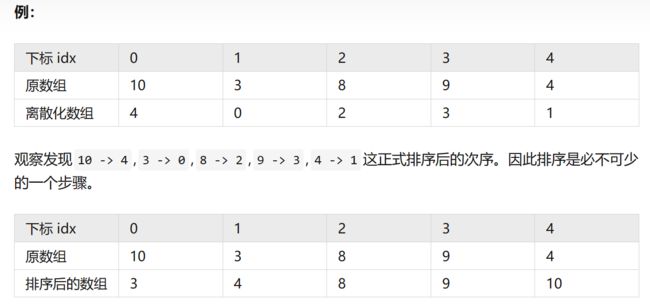
(1)下标映射
如果将下标也一同排序,数据将是怎么的形式呢?
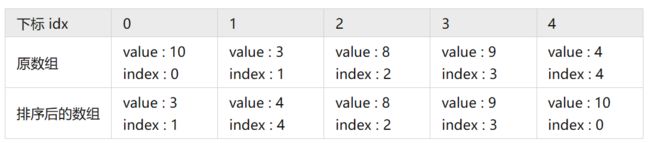
将下标和元素绑定后,有一个好处,对应每个元素能 O(1) 的找出该元素在原始数组中的位置。
因此,我们只需要顺序遍历排序后的元素,顺序的将原数组的值改为 [0,n-1] 的映射即可。
具体的我们可以如下操作:
- 排序后的第 0 号元素 ---> 获取原数组 index1 ---> 将原数组的 1 号元素修改为 0
- 排序后的第 1 号元素 ---> 获取原数组 index4 ---> 将原数组的 4 号元素修改为 1
- 排序后的第 2 号元素 ---> 获取原数组 index2 ---> 将原数组的 2 号元素修改为 2
- 排序后的第 3 号元素 ---> 获取原数组 index3 ---> 将原数组的 3 号元素修改为 3
- 排序后的第 4 号元素 ---> 获取原数组 index0 ---> 将原数组的 0 号元素修改为 4
(2)二分
其实这里的二分法回归本源也是基于下标映射的原理,只是实现是借助二分的形式。
在排序好的数组中对目标数值进行二分搜索,在 O(logn) 的时间复杂度内找到该数值是整体数据中的第几个。
具体的我们可以如下操作:
- 数值 10 ---> 二分搜索 10 ---> 有序序列中第 4 位置
- 数值 3 ---> 二分搜索 3 ---> 有序序列中第 0 位置
- 数值 8 ---> 二分搜索 8 ---> 有序序列中第 9 位置
- 数值 9 ---> 二分搜索 9 ---> 有序序列中第 3 位置
- 数值 4 ---> 二分搜索 4 ---> 有序序列中第 1 位置
3、注意事项
(1)unique函数
unique 是 C++ 自带的一个函数,表示对一个数列去重,然后返回不重复的元素个数,当然在后面要减去首地址。
具体实现过程:(双指针算法:第一个指针用来遍历所有数,第二个指针存储当前的数)
满足下面两个条件:
1、它是第一个。
2、a[i] != a[i-1]
unique() 函数的底层原理:
vector::iterator unique(vector &a) {
int j = 0;
for (int i = 0; i < a.size(); ++i) {
if (!i || a[i] != a[i - 1])//如果是第一个元素或者该元素不等于前一个元素,即不重复元素,我们就把它存到数组前j个元素中
a[j++] = a[i];//每存在一个不同元素,j++
}
return a.begin() + j;//返回的是前j个不重复元素的下标
} (2)复杂度
主要体现在排序中,其余操作 <= O(logn)
- 时间复杂度:O(logn)
主要体现在用于排序的辅助数组中,不考虑 sort 中使用的空间
- 空间复杂度:O(n)
(3)find函数
为什么最后结果返回的是 r+1?
在这个代码中,所有下标都是从 1 开始计数的,而 alls 容器中存储的下标为从小到大排序后的不重复下标,因此在查找时如果找到了对应的下标为 alls[mid] >= x,则 mid 对应的下标为第一个 >= x 的位置。由于 alls 中的下标也是从 1 开始计数的,因此需要返回 r+1 才能得到在数组 a 中对应的下标。
我们需要映射到 1,2,3,...,因为使用前缀和,其下标要 +1 这样后面就可以不考虑边界问题。
(4)为什么要把 l 和 r 插入到离散化的数组当中?
每次读取一个区间的左右下标 l 和 r,并将它们分别插入到 alls 容器中。这是为了在后面处理询问时,能够通过 find 函数找到对应的左右下标在 alls 中的位置。
在处理询问时,需要根据查询的左右下标找到它们在 alls 中的位置,然后计算相应的前缀和。由于 alls 容器中存储的是从小到大排序的不重复下标,将区间的左右下标直接插入到 alls 中,可以保证在处理询问时可以很方便地找到对应的位置。
总结起来,向 alls 尾部插入区间的左右下标是为了方便后面处理询问时快速定位区间的位置。
(5)为什么插入时要调用 find 函数?
在处理插入操作时,需要将给定的数值插入到数组 a 中对应的位置上。但是,在输入数据中给出的下标不一定是连续的,所以不能直接使用 item.first 作为下标直接访问数组 a。
(6)预处理前缀和
数组下标从 0 开始,因此数组 s 中包含了 alls.size()+1 个元素。这里的循环条件是 i <= alls.size() ,表示将所有下标的数值之和存储到数组 s 的第 0 到第 alls.size() 个位置上,其中 s[0] 初始化为 0,表示前缀和的初始值。因此,循环条件是 i <= alls.size() 而不是 i < alls.size(),否则最后一个元素无法被正确处理。
4、练习
802. 区间和 - AcWing题库
typedef pair PII;
const int N = 300010;
int n, m;
int a[N], s[N];
vector alls;//存入下标容器
vector add, query;//add增加容器,存入对应下标和增加的值的大小
//query存入需要计算下标区间和的容器
int find(int x)
{
int l = 0, r = alls.size() - 1;
while (l < r)//查找大于等于x的最小的值的下标
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1;//因为使用前缀和,其下标要+1可以不考虑边界问题
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i ++ )
{
int x, c;
cin >> x >> c;
add.push_back({x, c});//存入下标即对应的数值c
alls.push_back(x);//存入数组下标x=add.first
}
for (int i = 0; i < m; i ++ )
{
int l, r;
cin >> l >> r;
query.push_back({l, r});//存入要求的区间
alls.push_back(l);//存入区间左右下标
alls.push_back(r);
}
// 区间去重
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
// 处理插入
for (auto item : add)
{
int x = find(item.first);//将add容器的add.secend值存入数组a[]当中,
a[x] += item.second;//在去重之后的下标集合alls内寻找对应的下标并添加数值
}
// 预处理前缀和
for (int i = 1; i <= alls.size(); i ++ ) s[i] = s[i - 1] + a[i];
// 处理询问
for (auto item : query)
{
int l = find(item.first), r = find(item.second);//在下标容器中查找对应的左右两端[l~r]下标,然后通过下标得到前缀和相减再得到区间a[l~r]的和
cout << s[r] - s[l - 1] << endl;
}
return 0;
} 【个人理解】
l 和 r 是原数轴上的下标,alls 是所有需要用到的下标,而不是单单那些非 0 的点的下标,在去重排序过后可以就是一个个有序但在数字上并不连续的下标,我们可以把他叫做原下标。二分查找的过程就是将这些有序原下标转化为连续的 1,2,3,4,5.....下标的过程,这个下标是 a 数组的下标,a 数组用来存储每次 +c 的数据。
每次询问 l 和 r 之间的区间和,只需要计算 [l,r] 之间非零的数之和,我们最后计算用的前缀和 s 是 a 数组的前缀和,也就是需要经过原下标(l 与 r)—>离散后下标的转化,我们访问 [l,r] 区间也就是访问 a 数组的一个区间。alls 数组就是用来将原下标进行离散化处理的,要是没有往里面存入 l 和 r,在离散过后我们就无法精确的找到 l 和 r 对应的 a 数组下标,也就是找不到这个区间。
在最后计算区间和的这个操作所用的下标是离散化的下标,alls 数组是用来将原下标转化为离散化下标的,如果 l 和 r 不存入里面转化,我们在最后计算的时候就无法找到区间。
a[N] 表示原数组(数列)离散化后的新数组(数列),alls 表示所有离散化有序后的坐标(下标位置)i;将所有数列坐标(位置)离散有序化的目的是为了方便二分查找,复杂度O(n) 变为 O(logn)。能将所有原数列坐标(位置)离散有序化的条件是,没有进行过插入操作的原数列坐标位置值为 0。这样,求 [l,r] 前缀和时只对操作过的位置求前缀和,并且中间有多少个 0 也不会影响前缀和的结果,这样就可以直接在新的离散化数组 a[N] 中进行前缀和。理解这一点很重要,否则其他情况都无法用离散化的方法优化查询
四、区间合并
1、区间合并模板
记忆!
// 将所有存在交集的区间合并
void merge(vector &segs)
{
vector res;
sort(segs.begin(), segs.end());
int st = -2e9, ed = -2e9;
for (auto seg : segs)
if (ed < seg.first)
{
if (st != -2e9) res.push_back({st, ed});
st = seg.first, ed = seg.second;
}
else ed = max(ed, seg.second);
if (st != -2e9) res.push_back({st, ed});
segs = res;
} 2、思路
(1)按所有区间左端点排序
(2)分为下列三种情况

结果:
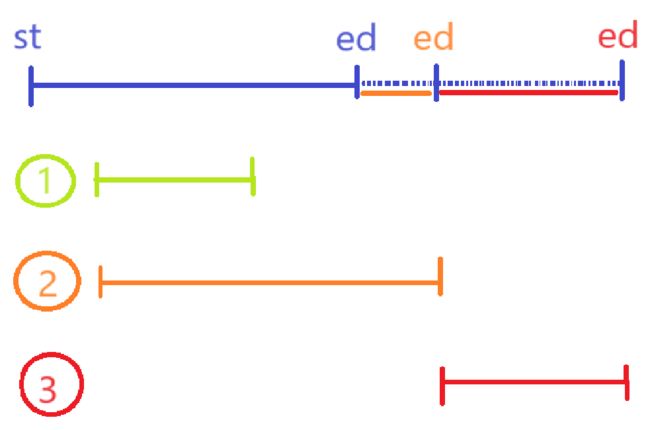
3、注意事项
(1)左右端点的取值
左右端点我们认为是负无穷和正无穷,在这里取:
int st = -2e9, ed = -2e9;(2)区间为0
if (st != -2e9) res.push_back({st, ed});用来处理最后一个合并的区间的情况。防止输入的数组是空的。
- 如果输入的区间数量为 0,那么在遍历结束后,st 的值仍然等于初始值 -2e9,表示没有有效的合并区间。此时,不会执行 res.push_back({st,ed}) 这一句,结果数组 res 将保持为空。
- 而如果输入的区间数量 > 0,在遍历结束后,如果存在有效的合并区间,即 st 不等于初始值 -2e9,那么最后一个合并的区间 {st,ed} 将被正确地添加到结果数组 res 中。
4、练习
803. 区间合并 - AcWing题库