Python库积累之Selenium(一)-Seleniun基础
Selenium是一个用电脑模拟人操作浏览器网页,支持多平台,多浏览器和多种编程语言,广泛应用于自动化,测试,爬虫等场景中.
官方文档:https://www.selenium.dev/selenium/docs/api/py/api.html#
中文文档:https://selenium-python-zh.readthedocs.io/en/latest/index.html
准备工作
安装selenium
直接使用pip安装即可
pip install selenium
下载浏览器驱动
各对应的浏览器驱动下载地址如下:
Firefox浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver , taobao备用地址
IE浏览器驱动:IEDriverServer
Edge浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
在选择浏览器驱动时,我们要选择和我们的浏览器版本号一致的驱动,例如我使用的为Chrome。首先需要查看Chrome版本,在浏览器中输入chrome://version/或者打开设置查看对应的版本号,并根据版本号下载对应的chromedriver
下载解压完成后需要把浏览器驱动放入相对路径中(运行selenium程序所在的路径),或者之后在程序中直接告知selenuim的驱动路径。
可以使用以下代码来测试selenium是否可以正常使用:
from selenium import webdriver
driver = webdriver.Firefox() # Firefox浏览器
# driver = webdriver.Firefox("驱动路径") 用于浏览器驱动不在系统路径下。其他浏览器同理。
driver = webdriver.Chrome() # Chrome浏览器
driver = webdriver.Ie() # Internet Explorer浏览器
driver = webdriver.Edge() # Edge浏览器
driver = webdriver.Opera() # Opera浏览器
driver = webdriver.PhantomJS() # PhantomJS
# 打开网页
driver.get(url) # 打开url网页 比如 driver.get("http://www.baidu.com")
如果可正常使用运行后会出现浏览器页面并进入到对应的url网页中。
元素定位
网页上的文本,内容,按钮,输入框等统称为元素。当我们执行操作,比如需要点击某个按钮,或者在某个输入框中输入时我们需要告诉selenium具体需要操作的位置,这就是元素定位。定位元素的方法非常多,可以按照id,文本内容,xpath等进行定位,具体如下:
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()
例如在百度网站中我们定位到输入框并传入文字selenium:
#coding=utf-8
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.baidu.com")
#########百度输入框的定位方式##########
#通过id方式定位
browser.find_element_by_id("kw").send_keys("selenium")
#通过name方式定位
browser.find_element_by_name("wd").send_keys("selenium")
#通过tag name方式定位
browser.find_element_by_tag_name("input").send_keys("selenium")
#通过class name方式定位
browser.find_element_by_class_name("s_ipt").send_keys("selenium")
#通过CSS方式定位
browser.find_element_by_css_selector("#kw").send_keys("selenium")
#通过xpath方式定位
browser.find_element_by_xpath("//input[@id='kw']").send_keys("selenium")
############################################
browser.find_element_by_id("su").click()
time.sleep(3)
browser.quit()
将element变成elements就是找所有满足的条件,返回数组。
实际中最常用的方式是通过 xpath 定位元素的。具体步骤为在Chrome中按F12进入开发者模式,找到元素对应的代码右键复制xpath即可。
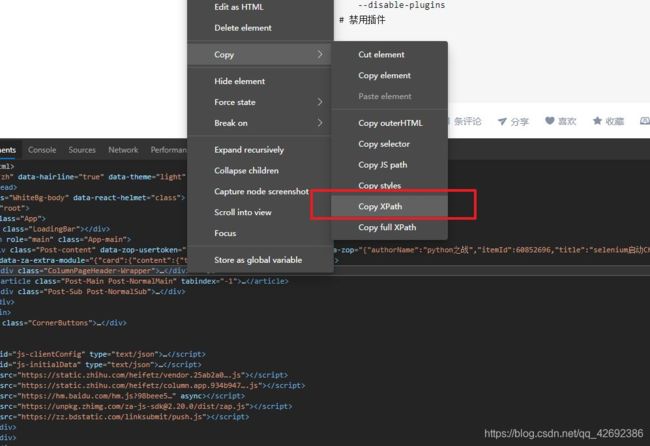
元素定位后我们可以对元素进行各种操作。
元素(Webelement)操作
点击和输入
driver.find_element_by_id("kw").clear() # 清除文本
driver.find_element_by_id("kw").send_keys("selenium") # 模拟按键输入,一般用于输入框,例如输入账号密码等。本句代码向输入框中传入selenium字符串
driver.find_element_by_id("su").click() # 单击元素
提交:可以在搜索框模拟回车操作
search_text = driver.find_element_by_id('kw') search_text.send_keys('selenium') #向输入框内传入selenium
search_text.submit() #提交
其他
size: 返回元素的尺寸。
text: 获取元素的文本。
get_attribute(name): 获得属性值。
is_displayed(): 设置该元素是否用户可见。
控制浏览器操作
控制浏览器窗口大小
driver.set_window_size(480, 800)
浏览器后退,前进
driver.back() #后退
driver.forward() #前进
刷新
driver.refresh() # 刷新
将浏览器最大化/最小化显示
driver.maximize_window() #最大化
driver.minimize_window() #最小化
鼠标操作
在 WebDriver 中, 将这些关于鼠标操作的方法封装在 ActionChains 类提供。ActionChains 类提供了鼠标操作的常用方法:
perform() #执行所有 ActionChains 中存储的行为;
context_click() #右击
double_click() #双击
drag_and_drop() #拖动
move_to_element() #鼠标悬停
举个例子:
from selenium import webdriver
# 引入 ActionChains 类
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
driver.get("https://www.baidu.cn")
# 定位到要悬停的元素
above = driver.find_element_by_link_text("设置")
# 对定位到的元素执行鼠标悬停操作
ActionChains(driver).move_to_element(above).perform()
键盘事件
要想调用键盘按键操作需要引入 keys 包:
from selenium.webdriver.common.keys import Keys #通过 send_keys()调用按键
以下为常用的键盘操作:
send_keys(Keys.BACK_SPACE) 删除键(BackSpace)
send_keys(Keys.SPACE) 空格键(Space)
send_keys(Keys.TAB) 制表键(Tab)
send_keys(Keys.ESCAPE) 回退键(Esc)
send_keys(Keys.ENTER) 回车键(Enter)
send_keys(Keys.F1) 键盘 F1
……
send_keys(Keys.F12) 键盘 F12
#键盘组合键
send_keys(Keys.CONTROL,'a') 全选(Ctrl+A)
send_keys(Keys.CONTROL,'c') 复制(Ctrl+C)
send_keys(Keys.CONTROL,'x') 剪切(Ctrl+X)
send_keys(Keys.CONTROL,'v') 粘贴(Ctrl+V)
具体实例:
# 输入框输入内容
driver.find_element_by_id("kw").send_keys("seleniumm")
# 删除多输入的一个 m
driver.find_element_by_id("kw").send_keys(Keys.BACK_SPACE)
等待页面加载完成
在实际应用中由于网速,硬件条件等原因我们可能无法立即加载页面,这时候就需要等待页面加载完成,否则后续会出现元素无法找到等报错
强制等待
第一种也是最简单粗暴的一种办法就是强制等待sleep(xx),让程序暂停三秒。需要引入“time”模块,这种叫强制等待,不管你浏览器是否加载完了,程序都得等待3秒,3秒一到,继续执行下面的代码,作为调试很有用,有时候也可以在代码里这样等待,不过不建议总用这种等待方式,太死板,严重影响程序执行速度。
# -*- coding: utf-8 -*-
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get('http://baidu.com')
time.sleep(3) # 强制等待3秒再执行下一步
print(driver.current_url)
driver.quit()
隐式等待
隐形等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。在Selenium中使用implicitly_wait()方法实现
from selenium import webdriver
driver = webdriver.Firefox()
driver.implicitly_wait(10) # 隐式等待10秒
driver.get("http://somedomain/url_that_delays_loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
implicitly_wait() 的用法比 time.sleep() 更智能,后者只能选择一个固定的时间的等待,前者可以在一个时间范围内智能的等待。
需要特别说明的是:隐性等待对整个driver的周期都起作用,所以只要设置一次即可,不用像sleep()一样每一步都来一下。
但是隐式等待有一个弊端,那就是程序会一直等待整个页面加载完成,也就是一般情况下你看到浏览器标签栏那个小圈不再转,才会执行下一步,但有时候页面想要的元素早就在加载完成了,但是因为个别js之类的东西特别慢,我仍得等到页面全部完成才能执行下一步,我想等我要的元素出来之后就下一步怎么办?这就要使用selenium提供的另一种等待方式——显性等待了。
显示等待
显性等待就是让程序每隔xx秒测试一下,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
Selenium中实现显示等待的是WebDriverWait类,先看下它有哪些参数与方法:
selenium.webdriver.support.wait.WebDriverWait(类)
参数:
driver: 传入WebDriver实例,即我们上例中的driver
timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间)
poll_frequency: 调用until或until_not中的方法的间隔时间,默认是0.5秒
ignored_exceptions: 忽略的异常,如果在调用until或until_not的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException。
方法:
until:
method: 在等待期间,每隔一段时间(__init__中的poll_frequency)调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not:与until相反,until是当某元素出现或什么条件成立则继续执行,until_not是当某元素消失或什么条件不成立则继续执行,参数也相同,不再赘述。
这里需要特别注意的是until或until_not中的可执行方法method参数,很多人传入了WebElement对象,例如WebDriverWait(driver, 10).until(driver.find_element_by_id('kw')) # 错误,这是错误的用法,这里的参数一定要是可以调用的,即这个对象一定有 call() 方法,否则会抛出异常:TypeError: 'xxx' object is not callable.method参数可以用selenium提供的 expected_conditions 模块中的各种条件,也可以用WebElement的 is_displayed() 、is_enabled()、is_selected() 方法,或者用自己封装的方法都可以。
#coding=utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
base_url = "http://www.baidu.com"
driver = webdriver.Firefox()
driver.implicitly_wait(5)
'''隐式等待和显示等待都存在时,超时时间取二者中较大的'''
locator = (By.ID,'kw')
driver.get(base_url)
WebDriverWait(driver,10).until(EC.title_is(u"百度一下,你就知道"))
'''判断title,返回布尔值'''
WebDriverWait(driver,10).until(EC.title_contains(u"百度一下"))
'''判断title,返回布尔值'''
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,'kw')))
'''判断某个元素是否被加到了dom树里,并不代表该元素一定可见,如果定位到就返回WebElement'''
WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.ID,'su')))
'''判断某个元素是否被添加到了dom里并且可见,可见代表元素可显示且宽和高都大于0'''
WebDriverWait(driver,10).until(EC.visibility_of(driver.find_element(by=By.ID,value='kw')))
'''判断元素是否可见,如果可见就返回这个元素'''
WebDriverWait(driver,10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'.mnav')))
'''判断是否至少有1个元素存在于dom树中,如果定位到就返回列表'''
WebDriverWait(driver,10).until(EC.visibility_of_any_elements_located((By.CSS_SELECTOR,'.mnav')))
'''判断是否至少有一个元素在页面中可见,如果定位到就返回列表'''
WebDriverWait(driver,10).until(EC.text_to_be_present_in_element((By.XPATH,"//*[@id='u1']/a[8]"),u'设置'))
'''判断指定的元素中是否包含了预期的字符串,返回布尔值'''
WebDriverWait(driver,10).until(EC.text_to_be_present_in_element_value((By.CSS_SELECTOR,'#su'),u'百度一下'))
'''判断指定元素的属性值中是否包含了预期的字符串,返回布尔值'''
#WebDriverWait(driver,10).until(EC.frame_to_be_available_and_switch_to_it(locator))
'''判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False'''
#注意这里并没有一个frame可以切换进去
WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.CSS_SELECTOR,'#swfEveryCookieWrap')))
'''判断某个元素在是否存在于dom或不可见,如果可见返回False,不可见返回这个元素'''
#注意#swfEveryCookieWrap在此页面中是一个隐藏的元素
WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='u1']/a[8]"))).click()
'''判断某个元素中是否可见并且是enable的,代表可点击'''
driver.find_element_by_xpath("//*[@id='wrapper']/div[6]/a[1]").click()
#WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@id='wrapper']/div[6]/a[1]"))).click()
#WebDriverWait(driver,10).until(EC.staleness_of(driver.find_element(By.ID,'su')))
'''等待某个元素从dom树中移除'''
#这里没有找到合适的例子
WebDriverWait(driver,10).until(EC.element_to_be_selected(driver.find_element(By.XPATH,"//*[@id='nr']/option[1]")))
'''判断某个元素是否被选中了,一般用在下拉列表'''
WebDriverWait(driver,10).until(EC.element_selection_state_to_be(driver.find_element(By.XPATH,"//*[@id='nr']/option[1]"),True))
'''判断某个元素的选中状态是否符合预期'''
WebDriverWait(driver,10).until(EC.element_located_selection_state_to_be((By.XPATH,"//*[@id='nr']/option[1]"),True))
'''判断某个元素的选中状态是否符合预期'''
driver.find_element_by_xpath(".//*[@id='gxszButton']/a[1]").click()
instance = WebDriverWait(driver,10).until(EC.alert_is_present())
'''判断页面上是否存在alert,如果有就切换到alert并返回alert的内容'''
print instance.text
instance.accept()
driver.close()
在不同的窗口和框架之间移动
定位元素过程中如果页面存在iframe或内嵌窗口就会遇到找不到元素的问题,webdriver 提供了一个 switch_to_frame 方法,可以很轻松的来解决这个问题。
driver.switch_to_window("windowName") #内嵌窗口
driver.switch_to_frame("frameName") #多层框架
以直接取表单的id 或name属性。如果iframe没有可用的id和name属性,则可以通过下面的方式进行定位。
#先通过xpth定位到iframe
xf = driver.find_element_by_xpath('//*[@id="x-URS-iframe"]')
#再将定位对象传给switch_to_frame()方法
driver.switch_to_frame(xf)
一旦我们完成了frame中的工作,我们可以这样返回父frame:
driver.switch_to_default_content()
获取断言信息
讲如何获取断言信息之前,先普及一下断言的概念。断言是编程术语,表示为一些布尔表达,用来检查一个条件,如果它为真,就不做任何事。如果它为假抛出异常。那为什么要使用断言呢?因为使用断言可以创建更稳定、品质更好且 不易于出错的代码。当需要在一个值为FALSE时中断当前操作的话,可以使用断言。比如说我们做selenium自动化,需要打开百度,那么如何去判断打开的这个百度页面是否为真呢?可以获取页面的标题,或者特定的文本等信息去断言是否为真。通常可以通过获取title 、URL和text等信息进行断言
title = driver.title # 打印当前页面title
now_url = driver.current_url # 打印当前页面URL
user = driver.find_element_by_class_name('nums').text #获取结果数目
警告框处理
#切换到alert,默认返回alert对话框对象
alert = driver.switch_to_alert()
#处理对话框
alert.accept()
其中处理对话框的方法有:
text:返回 alert/confirm/prompt 中的文字信息。
accept():接受现有警告框。
dismiss():解散现有警告框。
send_keys(keysToSend):发送文本至警告框。keysToSend:将文本发送至警告框。
下拉框选择
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import sleep
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
sel = driver.find_element_by_xpath("//select[@id='nr']")
Select(sel).select_by_value('50') # 显示50条
文件上传
driver.find_element_by_name("file").send_keys('D:\\upload_file.txt') #定位上传按钮,添加本地文件
无界面模式
无界面模式可以隐藏浏览器界面同时不影响具体操作
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.headless = True #设置无界面模式的第一种方法
#option.add_argument('--headless') #设置无界面模式的第二种方法
driver = webdriver.Chrome(options=option)
driver.get('https://www.baidu.com')
# 获取网页的源码
html = driver.page_source
print(html)
使用代理
from selenium import webdriver
import time
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=http://ip地址') # 代理IP:端口号
driver = webdriver.Chrome(options=options)
driver.get("https://dev.kdlapi.com/testproxy")
# 获取页面内容
print(driver.page_source)
# 延迟3秒后关闭当前窗口,如果是最后一个窗口则退出
time.sleep(3)
driver.close()
cookie操作
WebDriver操作cookie的方法:
get_cookies(): 获得所有cookie信息。
get_cookie(name): 返回字典的key为“name”的cookie信息。
add_cookie(cookie_dict) : 添加cookie。“cookie_dict”指字典对象,必须有name 和value 值。
delete_cookie(name,optionsString):删除cookie信息。“name”是要删除的cookie的名称,“optionsString”是该cookie的选项,目前支持的选项包括“路径”,“域”。
delete_all_cookies(): 删除所有cookie信息
在爬虫中我们就经常需要传入cookie,否则每次自动打开一些有反爬机制的网站就会需要验证,具体可参考文章:https://blog.csdn.net/qq_42692386/article/details/119004055
调用JavaScript代码
js="window.scrollTo(100,450);"
driver.execute_script(js) # 通过javascript设置浏览器窗口的滚动条位置
通过execute_script()方法执行JavaScripts代码来移动滚动条的位置。通过JavaScript和Selenium可以实现非常多的操作
窗口截图
driver.get_screenshot_as_file("D:\\baidu_img.jpg") # 截取当前窗口,并指定截图图片的保存位置
关闭浏览器
close() #关闭单个窗口
quit() #关闭所有窗口
其他Selenium常见问题与解决:
参考文章:
selenium官方文档:
https://www.selenium.dev/selenium/docs/api/py/index.html
https://www.jianshu.com/p/1531e12f8852
https://zhuanlan.zhihu.com/p/111859925
↓↓↓欢迎关注我的公众号,在这里有数据相关技术经验的优质原创文章↓↓↓
