深入理解DPDK-同步互斥机制详解
DPDK根据多核处理器的特点,遵循资源局部化的原则,解耦数据的跨核共享,使得性能可以有很好的水平扩展。但当面对实际应用场景,CPU核间的数据通信、数据同步、临界区保护等都是不得不面对的问题。如何减少由这些基础组件引入的多核依赖的副作用,也是DPDK的一个重要的努力方向。
原子操作
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为“不可被中断的一个或一系列操作”。对原子操作的简单描述就是:多个线程执行一个操作时,其中任何一个线程要么完全执行完此操作,要么没有执行此操作的任何步骤,那么这个操作就是原子的。原子操作是其他内核同步方法的基石。
处理器上的原子操作
在单处理器系统(UniProcessor)中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源互斥的原因。
在多核CPU的时代,体系中运行着多个独立的CPU,即使是可以在单个指令中完成的操作也可能会被干扰。典型的例子就是decl指令(递减指令),它细分为三个过程:“读->改->写”,涉及两次内存操作。如果多个CPU运行的多个进程或线程在同时对同一块内存执行这个指令,那情况是无法预测的。
在x86平台上,总的来说,CPU提供三种独立的原子锁机制:原子保证操作、加LOCK指令前缀和缓存一致性协议。
一些基础内存事务操作,如对一个字节的读或者写,它们总是原子的。处理器保证操作没完成前,其他处理器不能访问相同的内存位置。对于边界对齐的字节、字、双字和四字节都可以自然地进行原子读写操作;对于非对齐的字节、字、双字和四字节,如果它们属于同一个缓存行,那么它们的读写也是自然原子保证的。
在这里特别介绍一下CMPXCHG这条指令,它的语义是比较并交换操作数(CAS,Compare And Set)。而用XCHG类的指令做内存操作,处理器会自动地遵循LOCK的语义,可见该指令是一条原子的CAS单指令操作。它可是实现很多无锁数据结构的基础,DPDK的无锁队列就是一个很好的实现例子。
CAS操作需要输入两个数值,一个旧值(期望操作前的值)和一个新值,在操作期间先比较下旧值有没有发生变化,如果没有发生变化,才交换成新值,发生了变化,则不交换。
如:CMPXCHG r/m,r将累加器AL/AX/EAX/RAX中的值与首操作数(目的操作数)比较,如果相等,第2操作数(源操作数)的值装载 到 首 操 作 数 , zf 置 1 。 如 果 不 等 , 首 操 作 数 的 值 装 载 到AL/AX/EAX/RAX,并将zf清0。
Linux内核原子操作
软件级的原子操作实现依赖于硬件原子操作的支持。对于Linux而言,内核提供了两组原子操作接口:一组是针对整数进行操作;另一组是针对单独的位进行操作。
原子整数操作
针对整数的原子操作只能处理atomic_t类型的数据。这里没有使用C语言的int类型,主要是因为:
- 让原子函数只接受atomic_t类型操作数,可以确保原子操作只与这种特殊类型数据一起使用。
- 使用atomic_t类型确保编译器不对相应的值进行访问优化。
- 使用atomic_t类型可以屏蔽不同体系结构上的数据类型的差异。尽管Linux支持的所有机器上的整型数据都是32位,但是使用atomic_t的代码只能将该类型的数据当作24位来使用。这个限制完全是因为在SPARC体系结构上,原子操作的实现不同于其他体系结构:32位int类型的低8位嵌入了一个锁,因为SPARC体系结构对原子操作缺乏指令级的支持,所以只能利用该锁来避免对原子类型数据的并发访问。
原子整数操作最常见的用途就是实现计数器。原子操作通常是内敛函数,往往通过内嵌汇编指令来实现。如果某个函数本来就是原子的,那么它往往会被定义成一个宏。
原子性与顺序性
原子性确保指令执行期间不被打断,要么全部执行,要么根本不执行。而顺序性确保即使两条或多条指令出现在独立的执行线程中,甚至独立的处理器上,它们本该执行的顺序依然要保持。
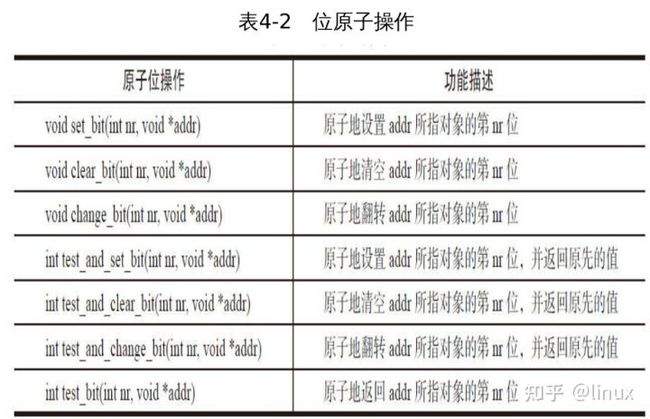
原子位操作
原子位操作函数是对普通的内存地址进行操作的。原子位操作在多数情况下是对一个字长的内存访问,因而位编号在031之间(在64位机器上是063之间),但是对位号的范围没有限制。
在Linux内核中,原子位操作分别定义于include\linux\types.h和arch\x86\include\asm\bitops.h。通常了解一个东西,我们是先了解它怎么用,因此,我们先来看看内核提供给用户的一些接口函数。对于整数原子操作函数,如表4-1所示,下述有关加法的操作在内核中均有相应的减法操作。

表4-2展示的是内核中提供的一些主要位原子操作函数。同时内核
还提供了一组与上述操作对应的非原子位操作函数,名字前多两下划线。由于不保证原子性,因此速度可能执行更快。
DPDK原子操作实现和应用
原子操作在DPDK代码中的定义都在rte_atomic.h文件中,主要包含两部分:内存屏蔽和原16、32和64位的原子操作API。
内存屏障API
- rte_mb():内存屏障读写API
- rte_wmb():内存屏障写API
- rte_rmb():内存屏障读API
这三个API的实现在DPDK代码中没有什么区别,都是直接调用__sync_synchronize(),而__sync_synchronize()函数对应着MFENCE这个序列化加载与存储操作汇编指令。
对MFENCE指令之前发出的所有加载与存储指令执行序列化操作。此序列化操作确保:在全局范围内看到MFENCE指令后面(按程序顺序)的任何加载与存储指令之前,可以在全局范围内看到MFENCE指令前面的每一条加载与存储指令。MFENCE指令的顺序根据 所 有 的 加 载 与 存 储 指 令 、 其 他 MFENCE 指 令 、 任 何 SFENCE 与LFENCE指令以及任何序列化指令(如CPUID指令)确定
通过使用无序发出、推测性读取、写入组合以及写入折叠等技术,弱序类型的内存可获得更高的性能。数据使用者对数据弱序程序的认知或了解因应用程序的不同而异,并且可能不为此数据的产生者所知。对于确保产生弱序结果的例程与使用此数据的例程之间的顺序,MFENCE指令提供了一种高效的方法。
我 们 在 这 里 给 出 一 个 内 存 屏 障 的 应 用 在 DPDK 中 的 实 例 , 在virtio_dev_rx()函数中,在读取avail->flags之前,加入内存屏障API以防止乱序的执行。
*(volatile uint16_t *)&vq->used->idx += count;
vq->last_used_idx = res_end_idx;
/* flush used->idx update before we read avail->flags. */
rte_mb();
/* Kick the guest if necessary. */
if (!(vq->avail->flags & VRING_AVAIL_F_NO_INTERRUPT))
eventfd_write(vq->callfd, (eventfd_t)1);原子操作API
DPDK 代 码 中 提 供 了 16 、 32 和 64 位 原 子 操 作 的 API , 以rte_atomic64_add()API源代码为例,讲解一下DPDK中原子操作的实现,其代码如下:
static inline void
rte_atomic64_add(rte_atomic64_t *v, int64_t inc)
{
int success = 0;3
uint64_t tmp;
while (success == 0) {
tmp = v->cnt;
success = rte_atomic64_cmpset((volatile uint64_t *)&v->cnt,
tmp, tmp + inc);
}
}在VXLAN例子代码中,使用了64位的原子操作API来进行校验码和错误包的统计;这样,在多核系统中,加上原子操作的数据包统计才准确无误。
int
vxlan_rx_pkts(struct virtio_net *dev, struct rte_mbuf **pkts_burst, uint32_t rx_count)
{
uint32_t i = 0;
uint32_t count = 0;
int ret;
struct rte_mbuf *pkts_valid[rx_count];
for (i = 0; i < rx_count; i++) {
if (enable_stats) {
rte_atomic64_add(&dev_statistics[dev->device_fh].rx_bad_ip_csum, (pkts_burst[i]->ol_flags & PKT_RX_IP_CKSUM_BAD) != 0);
rte_atomic64_add(&dev_statistics[dev->device_fh].rx_bad_ip_csum, (pkts_burst[i]->ol_flags & PKT_RX_L4_CKSUM_BAD) != 0);
}
ret = vxlan_rx_process(pkts_burst[i]);
if (unlikely(ret < 0))
continue;
pkts_valid[count] = pkts_burst[i];
count++;
}
ret = rte_vhost_enqueue_burst(dev, VIRTIO_RXQ, pkts_valid, count);
return ret;
}相关视频推荐
后台开发第164讲||为什么dpdk越来越受欢迎,看完以后,让人醍醐灌顶 1. 千万并发的业界标准 2. 网络的瓶颈 3. dpdk脱颖而出
【文章福利】需要C/C++ Linux高级服务器架构师学习资料(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)
可以加入到群里一起探讨技术交流,领取资料


读写锁
读写锁这种资源保护机制也在DPDK代码中得到了充分的应用。
读写锁实际是一种特殊的自旋锁,它把对共享资源的访问操作划分成读操作和写操作,读操作只对共享资源进行读访问,写操作则需要对共享资源进行写操作。这种锁相对于自旋锁而言,能提高并发性,因为在多处理器系统中,它允许同时有多个读操作来访问共享资源,最大可能的读操作数为实际的逻辑CPU数。
写操作是排他性的,一个读写锁同时只能有一个写操作或多个读操作(与CPU数相关),但不能同时既有读操作又有写操作。
读写自旋锁除了和普通自旋锁一样有自旋特性以外,还有以下特点:
- 读锁之间资源是共享的:即一个线程持有了读锁之后,其他线程也可以以读的方式持有这个锁。
- 写锁之间是互斥的:即一个线程持有了写锁之后,其他线程不能以读或者写的方式持有这个锁。
- 读写锁之间是互斥的:即一个线程持有了读锁之后,其他线程不能以写的方式持有这个锁。
上面提及的共享资源可以是简单的单一变量或多个变量,也可以是像文件这样的复杂数据结构。为了防止错误地使用读写自旋锁而引发的bug,我们假定每个共享资源关联一个唯一的读写自旋锁,线程只允许按照类似大象装冰箱的方式访问共享资源:
- 申请锁。
- 获得锁后,读写共享资源。
- 释放锁。
- 我们说某个读写自旋锁算法是正确的,是指该锁满足如下三个属性:
- 互斥。任意时刻读者和写者不能同时访问共享资源(即获得锁);任意时刻只能有至多一个写者访问共享资源。
- 读者并发。在满足“互斥”的前提下,多个读者可以同时访问共享资源。
- 无死锁。如果线程A试图获取锁,那么某个线程必将获得锁,
这个线程可能是A自己;如果线程A试图但是永远没有获得锁,那么某个或某些线程必定无限次地获得锁。
读写自旋锁主要用于比较短小的代码片段,线程等待期间不应该进入睡眠状态,因为睡眠/唤醒操作相当耗时,大大延长了获得锁的等待时间,所以我们要求忙等待。申请锁的线程必须不断地查询是否发生退出等待的事件,不能进入睡眠状态。这个要求只是描述线程执行锁申请操作未成功时的行为,并不涉及锁自身的正确性。
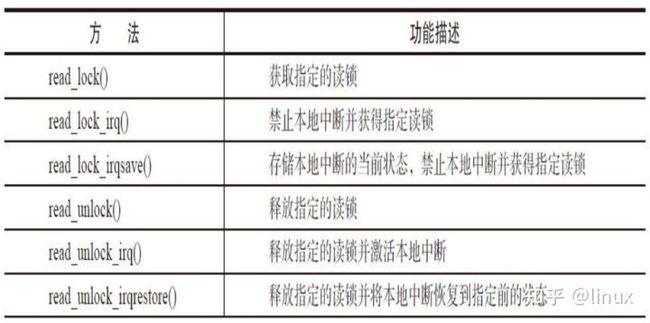
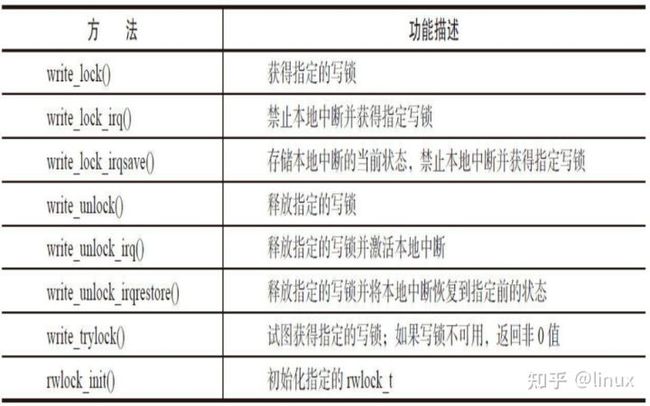
Linux读写锁主要API
下面表4-3中列出了针对读-写自旋锁的所有操作。读写锁相关文件参照各个体系结构中的
读写锁的相关函数如表4-3所示。
DPDK读写锁实现和应用
DPDK读写锁的定义在rte_rwlock.h文件中,
rte_rwlock_init ( rte_rwlock_trwl ) : 初 始 化 读 写 锁 到unlocked状态。
rte_rwlock_read_lock(rte_rwlock_trwl):尝试获取读锁直到锁被占用。
rte_rwlock_read_unlock(rte_rwlock_trwl):释放读锁。
rte_rwlock_write_lock(rte_rwlock_trwl):获取写锁。
rte_rwlock_write_unlock(rte_rwlock_t*rwl):释放写锁。
读写锁在DPDK中主要应用在下面几个地方,对操作的对象进行保护。
- 在查找空闲的memory segment的时候,使用读写锁来保护memseg结构。LPM表创建、查找和释放。
- Memory ring的创建、查找和释放。
- ACL表的创建、查找和释放。
- Memzone的创建、查找和释放等。
下面是查找空闲的memory segment的时候,使用读写锁来保护memseg结构的代码实例。
/*
* Lookup for the memzone identified by the given name
*/
const struct rte_memzone * rte_memzone_lookup(const char *name)
{
struct rte_mem_config *mcfg;
const struct rte_memzone *memzone = NULL;
mcfg = rte_eal_get_configuration()->mem_config;
rte_rwlock_read_lock(&mcfg->mlock);
memzone = memzone_lookup_thread_unsafe(name);rte_rwlock_read_unlock(&mcfg->mlock);
return memzone;
}自旋锁
何谓自旋锁(spin lock)?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,“自旋”一词就是因此而得名。
自旋锁的缺点
自旋锁必须基于CPU的数据总线锁定,它通过读取一个内存单元(spinlock_t)来判断这个自旋锁是否已经被别的CPU锁住。如果否,它写进一个特定值,表示锁定了总线,然后返回。如果是,它会重复以上操作直到成功,或者spin次数超过一个设定值。记住上面提及到的:锁定数据总线的指令只能保证一个指令操作期间CPU独占数据总线。(自旋锁在锁定的时侯,不会睡眠而是会持续地尝试)。其作用是为了解决某项资源的互斥使用。因为自旋锁不会引起调用者睡眠,所以自旋锁的效率远高于互斥锁。虽然自旋锁的效率比互斥锁高,但是它也有些不足之处:
- 自旋锁一直占用CPU,它在未获得锁的情况下,一直运行——自旋,所以占用着CPU,如果不能在很短的时间内获得锁,这无疑会使CPU效率降低。
- 在用自旋锁时有可能造成死锁,当递归调用时有可能造成死锁 , 调 用 有 些 其 他 函 数 ( 如 copy_to_user ( ) 、copy_from_user()、kmalloc()等)也可能造成死锁。
因此我们要慎重使用自旋锁,自旋锁只有在内核可抢占式或SMP的情况下才真正需要,在单CPU且不可抢占式的内核下,自旋锁的操作为空操作。自旋锁适用于锁使用者保持锁时间比较短的情况。
Linux自旋锁API
在Linux kernel实现代码中,自旋锁的实现与体系结构有关,所以相应的头文件
在Linux内核中,自旋锁的基本使用方式如下:
先 声 明 一 个 spinlock_t 类 型 的 自 旋 锁 变 量 , 并 初 始 化 为 “ 未 加锁”状态。在进入临界区之前,调用加锁函数获得锁,在退出临界区之前,调用解锁函数释放锁。例如:
spinlock_t lock = SPIN_LOCK_UNLOCKED;
spin_lock(&lock);
/* 临界区 */
spin_unlock(&lock);获得自旋锁和释放自旋锁的函数有多种变体,如下所示。
spin_lock_irqsave/spin_unlock_irqrestore
spin_lock_irq/spin_unlock_irq
spin_lock_bh/spin_unlock_bh/spin_trylock_bh上面各组函数最终都需要调用自旋锁操作函数。spin_lock函数用于获得自旋锁,如果能够立即获得锁,它就马上返回,否则,它将自旋在那里,直到该自旋锁的保持者释放。spin_unlock函数则用于释放自旋锁。此外,还有一个spin_trylock函数用于尽力获得自旋锁,如果能立即获得锁,它获得锁并返回真;若不能立即获得锁,立即返回假。它不会自旋等待自旋锁被释放。
自旋锁使用时有两点需要注意:
1、旋锁是不可递归的,递归地请求同一个自旋锁会造成死锁。
2、线程获取自旋锁之前,要禁止当前处理器上的中断。(防止获取锁的线程和中断形成竞争条件)
比如:当前线程获取自旋锁后,在临界区中被中断处理程序打断,中断处理程序正好也要获取这个锁,于是中断处理程序会等待当前线程释放锁,而当前线程也在等待中断执行完后再执行临界区和释放锁的代码。
再次总结自旋锁方法如表4-4所示。

DPDK自旋锁实现和应用
DPDK中自旋锁API的定义在rte_spinlock.h文件中,其中下面三个 API 被 广 泛 的 应 用 在 告 警 、 日 志 、 中 断 机 制 、 内 存 共 享 和 linkbonding的代码中,用于临界资源的保护。
rte_spinlock_init(rte_spinlock_t *sl) ;
rte_spinlock_lock(rte_spinlock_t *sl);
rte_spinlock_unlock (rte_spinlock_t *sl);其中rte_spinlock_t定义如下,简洁并且简单。
/**
* The rte_spinlock_t type.
*/
typedef struct {
volatile int locked; /**< lock status 0 = unlocked, 1 = locked */
} rte_spinlock_t;下 面 的 代 码 是 DPDK 中 的 vm_power_manager 应 用 程 序 中 的set_channel_status_all()函数,在自旋锁临界区更新了channel的状态和变化的channel的数量,这种保护在像DPDK这种支持多核的应用中是非常必要的。
Int
set_channel_status_all(const char *vm_name, enum channel_status status)
{
...
rte_spinlock_lock(&(vm_info->config_spinlock));
mask = vm_info->channel_mask;
ITERATIVE_BITMASK_CHECK_64(mask, i) {
vm_info->channels[i]->status = status;
num_channels_changed++;
}
rte_spinlock_unlock(&(vm_info->config_spinlock));
return num_channels_changed;
}无锁机制
当前,高性能的服务器软件(例如,HTTP加速器)在大部分情况下是运行在多核服务器上的,当前的硬件可以提供32、64或者更多的CPU,在这种高并发的环境下,锁竞争机制有时会比数据拷贝、上下文切换等更伤害系统的性能。因此,在多核环境下,需要把重要的数据结构从锁的保护下移到无锁环境,以提高软件性能。
所以,现在无锁机制变得越来越流行,在特定的场合使用不同的无锁队列,可以节省锁开销,提高程序效率。Linux内核中有无锁队列的实现,可谓简洁而不简单。
Linux内核无锁环形缓冲
环形缓冲区通常有一个读指针和一个写指针。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区中可写的数据。通过移动读指针和写指针就可以实现缓冲区的数据读取和写入。在通常情况下,环形缓冲区的读用户仅仅会影响读指针,而写用户仅仅会影响写指针。如果仅仅有一个读用户和一个写用户,那么不需要添加互斥保护机制就可以保证数据的正确性。但是,如果有多个读写用户访问环形缓冲区,那么必须添加互斥保护机制来确保多个用户互斥访问环形缓冲区。具体来讲,如果有多个写用户和一个读用户,那么只是需要给写用户加锁进行保护;反之,如果有一个写用户和多个读用户,那么只是需要对读用户进行加锁保护。
在Linux内核代码中,kfifo就是采用无锁环形缓冲的实现,kfifo是一种“First In First Out”数据结构,它采用了前面提到的环形缓冲区来实现,提供一个无边界的字节流服务。采用环形缓冲区的好处是,当一个数据元素被用掉后,其余数据元素不需要移动其存储位置,从而减少拷贝,提高效率。更重要的是,kfifo采用了并行无锁技术,kfifo实现的单生产/单消费模式的共享队列是不需要加锁同步的。更 多 的 细 节 可 以 阅 读 Linux 内 核 代 码 中 的 kfifo 的 头 文 件(include/linux/kfifo.h)和源文件(kernel/kfifo.c)。
DPDK无锁环形缓冲
基于无锁环形缓冲的的原理,Intel DPDK提供了一套无锁环形缓冲区队列管理代码,支持单生产者产品入列,单消费者产品出列;多名生产者产品入列,多名消费者出列操作。
rte_ring的数据结构定义
下 面 是 DPDK 中 的 rte_ring 的 数 据 结 构 定 义 , 可 以 清 楚 地 理 解rte_ring的设计基础。
/**
* An RTE ring structure.
*
* The producer and the consumer have a head and a tail index. The
particularity
* of these index is that they are not between 0 and size(ring). These
indexes
* are between 0 and 2^32, and we mask their value when we access the
ring[]
* field. Thanks to this assumption, we can do subtractions between 2 index
* values in a modulo-32bit base: that's why the overflow of the indexes is
not
* a problem.
*/
struct rte_ring {
char name[RTE_RING_NAMESIZE]; /**< Name of the ring. */
int flags; /**< Flags supplied at creation. */
/** Ring producer status. */
struct prod {
uint32_t watermark; /**< Maximum items before EDQUOT. */
uint32_t sp_enqueue; /**< True, if single producer. */
uint32_t size; /**< Size of ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
volatile uint32_t head; /**< Producer head. */
volatile uint32_t tail; /**< Producer tail. */
} prod __rte_cache_aligned;
/** Ring consumer status. */
struct cons {
uint32_t sc_dequeue; /**< True, if single consumer. */
uint32_t size; /**< Size of the ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
volatile uint32_t head; /**< Consumer head. */
volatile uint32_t tail; /**< Consumer tail. */
#ifdef RTE_RING_SPLIT_PROD_CONS
} cons __rte_cache_aligned;
#else
} cons;环形缓冲区的剖析
这一节讲解环形缓冲区(ring buffer)如何操作。这个环形结构是由两个头和尾组成,一组被生产者使用,另一组被消费者使用。下面的图分别用prod_head、prod_tail、cons_head和cons_tail来指代它们。每个图代表一个简单的环形ring的状态。
单生产者入队
本小节讲述当一个生产者增加一个对象到环形缓冲区中是如何操作 的 。 在 这 个 例 子 中 只 有 一 个 生 产 者 头 和 尾 ( prod_head 和prod_tail)被修改,并且只有一个生产者。这个初始状态是有一个生产者的头和尾指向了相同的位置。
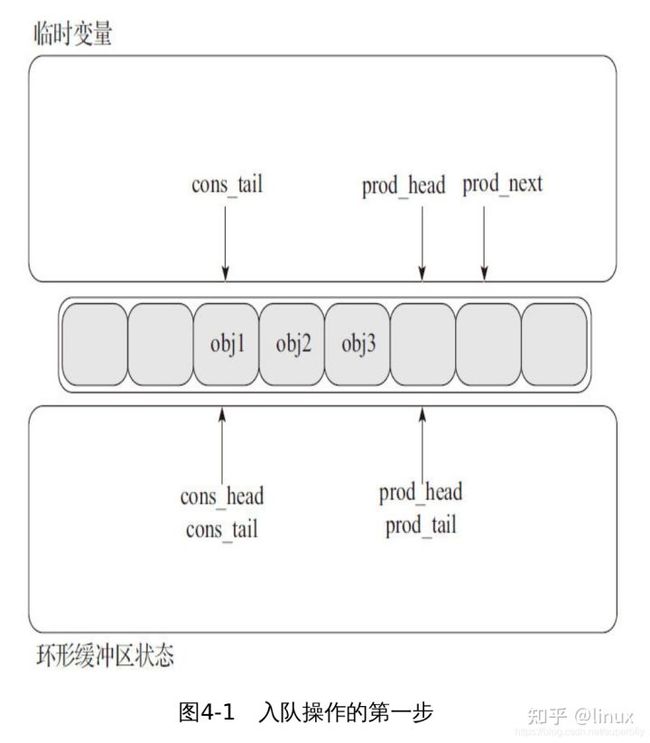
1、入队操作第一步(见图4-1)
首先,暂时将生产者的头索引和消费者的尾部索引交给临时变量;并且将prod_next指向表的下一个对象,如果在这环形缓冲区没有足够的空间,将返回一个错误。
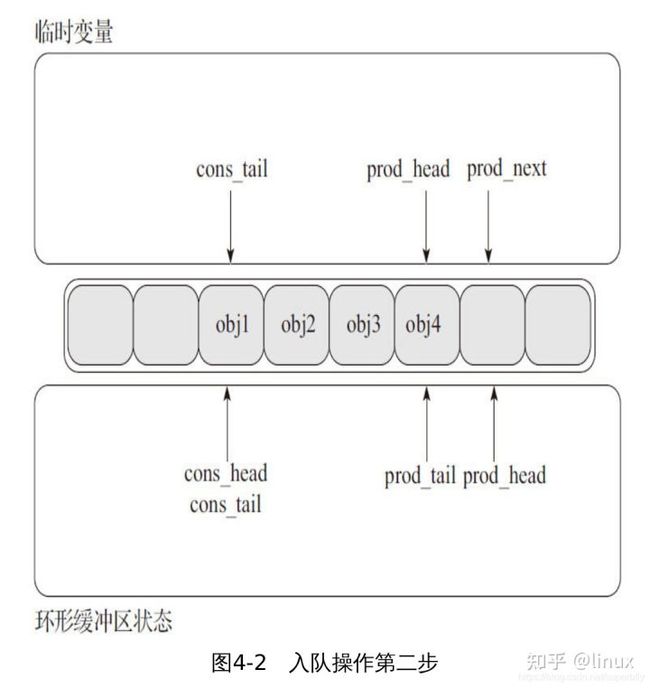
2、入队操作第二步(见图4-2)
第二步是修改prod_head去指向prod_next指向的位置。指向新增加对象的指针被拷贝到ring(obj4)。
入队操作最后一步(见图4-3)
一旦这个对象被增加到环形缓冲区中,prod_tail将要被修改成prod_head指向的位置。至此,这入队操作完成了。

单消费者出队
这一节介绍一个消费者出队操作在环形缓冲区中是如何进行的,在这个例子中,只有一个消费者头和尾(cons_head和cons_tail)被修改并且这只有一个消费者。初始状态是一个消费者的头和尾指向了相同的位置。
1、出队操作第一步(见图4-4)
首先,暂时将消费者的头索引和生产者的尾部索引交给临时变量,并且将cons_next指向表中下一个对象,如果在这环形缓冲区没有足够的对象,将返回一个错误。

2、出队操作第二步(见图4-5)
第二步是修改cons_head去指向cons_next指向的位置,并且指向出队对象(obj1)的指针被拷贝到一个临时用户定义的指针中。

3、出队操作最后一步(见图4-6)
最后,cons_tail被修改成指向cons_head指向的位置。至此,单消费者的出队操作完成了。

多生产者入队
这一节介绍两个生产者同时进行出队操作在环形缓冲区中是如何进 行 的 , 在 这 个 例 子 中 , 只 有 一 个 生 产 者 头 和 尾 ( cons_head 和cons_tail)被修改。初始状态是一个消费者的头和尾指向了相同的位置。
1、多个生产者入队第一步(见图4-7)
首先,在两个核上,暂时将生产者的头索引和消费者的尾部索引交给临时变量,并且将prod_next指向表中下一个对象,如果在这环形缓冲区没有足够的空间,将返回一个错误。

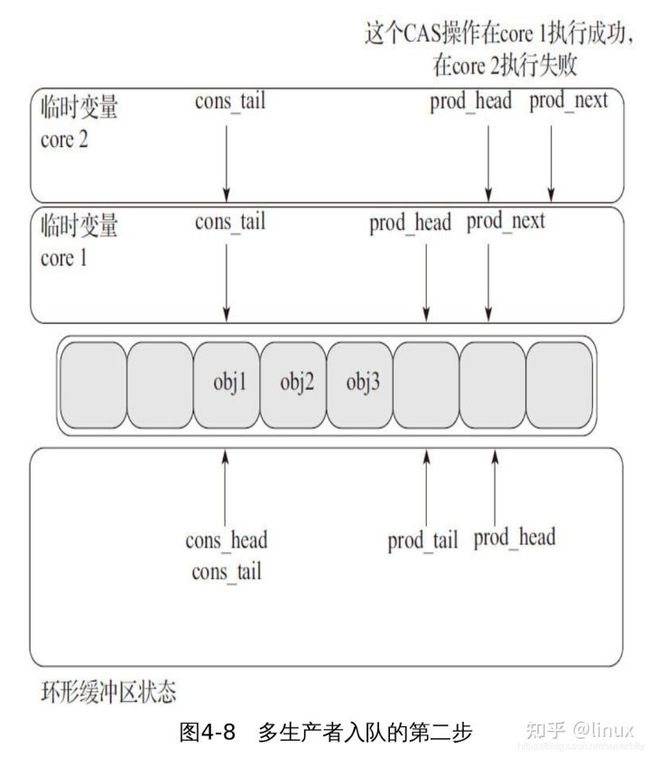
2、多个生产者入队第二步(见图4-8)
第二步是修改prod_head去指向prod_next指向的位置,这个操作使用了前面提到的比较交换指令(CAS)。
3、多生产者入队的第三步(见图4-9)
这个CAS操作在core2执行成功,并且core1更新了环形缓冲区的一个元素(obj4),core 2更新了另一个元素(obj5)。

4、多生产者入队的第四步(见图4-10)
现 在 每 一 个 core 要 更 新 prod_tail 。 如 果 prod_tail 等 于prod_head的临时变量,那么就更新它。这个操作只是在core1上进行。

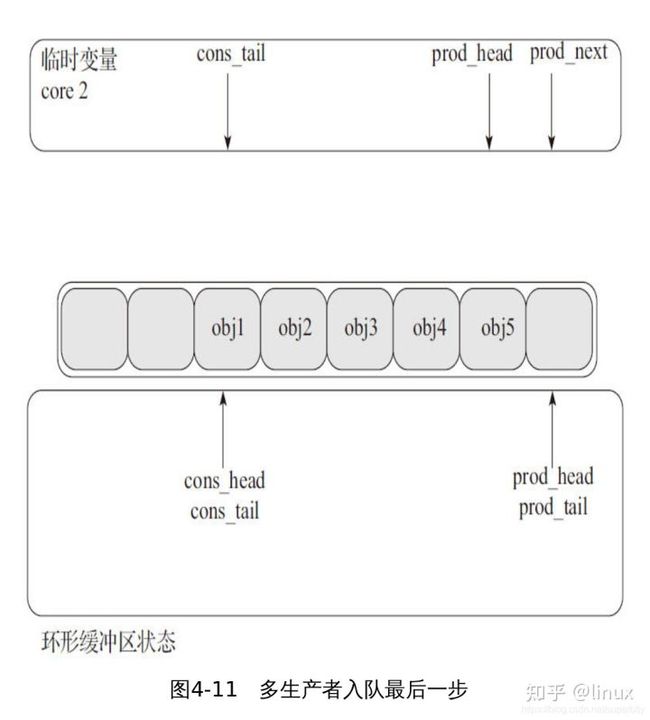
5、多生产者入队的第五步(见图4-11)
一 旦prod_tail在 core1 上 更新 完成 , 那么 也 允许 core2去更 新它,这个操作也在core2上完成了。
小结
原子操作适用于对单个bit位或者单个整型数的操作,不适用于对临界资源进行长时间的保护。
自旋锁主要用来防止多处理器中并发访问临界区,防止内核抢占造成的竞争。另外,自旋锁不允许任务睡眠(持有自旋锁的任务睡眠会造成自死锁——因为睡眠有可能造成持有锁的内核任务被重新调度,而再次申请自己已持有的锁),它能够在中断上下文中使用。
读写锁实际是一种特殊的自旋锁,适用于对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。写者是排他性的,一个读写锁同时只能有一个写者或多个读者(与CPU数相关),但不能同时既有读者又有写者。
无锁队列中单生产者——单消费者模型中不需要加锁,定长的可以通过读指针和写指针进行控制队列操作,变长的通过读指针、写指针、结束指针控制操作。
(一)多对多(一)模型中正常逻辑操作是要对队列操作进行加锁处理。加锁的性能开销较大,一般采用无锁实现,DPDK中就是采用的无锁实现,加锁的性能开销较大,DPDK中采用的无锁数据结构实现,非常高效。
每种同步互斥机制都有其适用场景,我们在使用的时候应该扬长避短,最大限度地发挥它们的优势,这样才能编写高性能的代码。另外,在DPDK代码中,这些机制都在用户空间中实现,便于移植,所以又可以为编写其他用户空间的代码提供参考和便利。