线上问题排查思路总结
前言:
本文总结一些常见的线上问题和对应的排查思路,工具。对于线上问题,我们必须记住一个原则:尽快恢复服务,消除影响。不管出于应急的哪个阶段,我们首先必须想到的是恢复问题,恢复问题并不意味着必须在当下定位到问题。在大多数情况下,我们都是先恢复服务,尽可能多的保留当时的异常信息(内存dump,线程dump,gc log等),等到服务正常,再去复盘问题。下面描述几个经常会遇到的线上紧急问题。
常用的命令工具总结
1. top 命令
-H :Threads-mode operation
Instructs top to display individual threads. Without this command-line option a summation of all threads in each process is shown. Later this can be changed with the `H' interactive command.
-p :Monitor-PIDs mode as: -pN1 -pN2 ... or -pN1,N2,N3 ...
Monitor only processes with specified process IDs. This option can be given up to 20 times, or you can provide a comma delimited list with up to 20 pids. Co-mingling both approaches is permitted. 查看某个进程内部线程占用情况分析:
top -H -p
2. pstack:显示每个进程的栈跟踪
3. ps -elf | grep java -c: 统计java线程数
4. jstat -gcutil 33411 1000 5 打印GC日志,每1000ms打印一次,一共打印5次。 用来判断JVM内存问题,垃圾回收情况。一般top指令基本上满足不了这样的要求,因为它主要是监控总体资源,不一定能定位到java应用程序。jstat是JDK一个轻量级小工具,位于java的bin目录下,主要利用JVM内建指令对java应用程序和性能进行实时的命令行监控。包括对Heap Size和垃圾回收状况的监控。
5. jstack 33411 > /home/dump1 打印线程堆栈信息。 jstack命令主要用来查看某个java进程内线程的堆栈信息。根据堆栈信息我们可以定位到具体代码,所以它在JVM性能调优中使用得非常多。
6. jmap
Jmap是一个可以输出所有内存中对象的工具,甚至可以将VM 中的heap,以二进制输出成文本。打印出某个java进程(使用pid)内存内的,所有‘对象’的情况(如:产生那些对象,及其数量)。
使用方法 jmap -histo pid。如果使用SHELL ,可采用jmap -histo pid>a.log日志将其保存到文件中,在一段时间后,使用文本对比工具,可以对比出GC回收了哪些对象。jmap -dump:format=b,file=outfile 3024 可以将3024进程的内存heap输出出来到outfile文件里,再配合MAT(内存分析工具)。 jmap命令的详细解释
1. CPU利用率过高/飙升
场景:
监控系统突然报警,提示服务器负载过高。引起CPU飙升的问题有很多种,这里只是介入这个现象切入。CPU使用率是衡量系统繁忙程度的重要指标。CPU的使用率的安全阈值是相对的,取决于系统是IO密集型还是计算密集型。一般计算密集型CPU使用率过高load偏低,IO密集型相反。
常见原因:
线上频繁GC,尤其是full gc, 死循环, 线程阻塞,io wait....
定位出问题的线程:
1. top命令定位CPU占用率最高的进程,通过top命令,查看所有cpu进程情况。找到占用cpu最高的进程号PID。

2. 通过top -Hp pid定位使用CPU最高的线程

3. 通过命令printf '0x%x'把线程id转换为16进制
prinf '0x%x' 12817
0x32114. jstack pid | grep 0x3211 -A 30

通过第一步,找到问题代码之后,观察到线程栈的具体情况,可以进行具体分析。下面举几个常见的例子:
情况一: 发现使用CPU最高的都是GC线程。
情况二:发现使用CPU最高的都是业务线程:
- io wait
比如此例中,就是因为磁盘空间不够导致的io阻塞 - 等待内核态锁,如 synchronized
- jstack -l pid | grep BLOCKED 查看阻塞态线程堆栈
- dump 线程栈,分析线程持锁情况。
- arthas提供了thread -b,可以找出当前阻塞其他线程的线程。针对 synchronized 情况
2. 常见现象:频繁GC
简答介绍下GC的流程,具体可以看JVM垃圾收集那几篇文章:
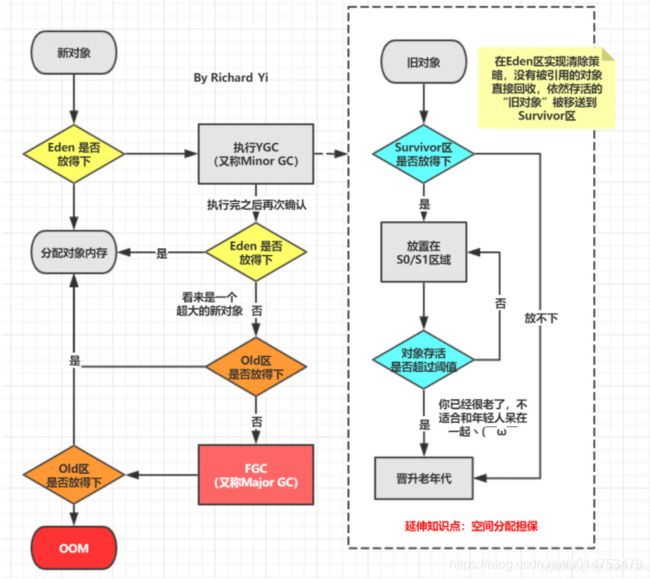
分析方法:
方法a:查看gc日志
方法b: jstat -gcutil 进程号 统计间隔毫秒 统计次数
从S区晋升的对象在老年代也放不下导致Full GC, full gc 回收无效则会抛出OOM
可能的原因:
- survivor区太小,对象过早进入老年代
查看SurvivorRatio参数 ,默认是8
- 对象分配,没有足够的内存 dump堆快照,MAT分析对象占用情况
- old区存在大对象 dump堆,MAT分析对象占用情况
也可以从full gc的效果来推断,正常情况下,一次full GC应该会回收大量的内存,所以正常的堆内存曲线应该是呈现锯齿形。如果发现full gc之后内存几乎没有降下来,可以推断:堆中大量的不能回收的对象在不停膨胀,使得堆的使用占比超过full gc的触发阈值,但是又回收不掉,导致full gc一直执行。也就是说有可能内存泄漏了。
一般来说,GC相关的异常推断都需要涉及到分析工具,使用jmap之类的工具dump出内存快照,然后使用MAT,JVisualVm等可视化工具进行分析。后面会单独写一篇文章介绍怎么通过MAT,JVisualVM分析内存快照。