从C快速入门C++ (命名空间、引用、函数重载)
从C快速入门C++ (命名空间、引用、函数重载)
-
- C++关键字
- const
-
- const 的存储位置
- 结论:
- 命名空间
-
- C++预处理器 和 iostream 文件
-
- 头文件名
- 命名空间使用
- 函数重载
-
- 默认参数
- 函数重载定义
- 函数重载调用原理
- 引用
-
-
- 1. 常引用(const修饰引用)
- 2.引用做函数返回值
- 传值 引用效率比较
- 引用和指针的区别
-
C++是一种计算机高级程序设计语言,由C语言扩展升级而产生 ,最早于1979年由本贾尼·斯特劳斯特卢普在AT&T贝尔工作室研发。 C++既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计。

C++关键字
C++98 中有63个关键字, C90(C89) 32个关键字
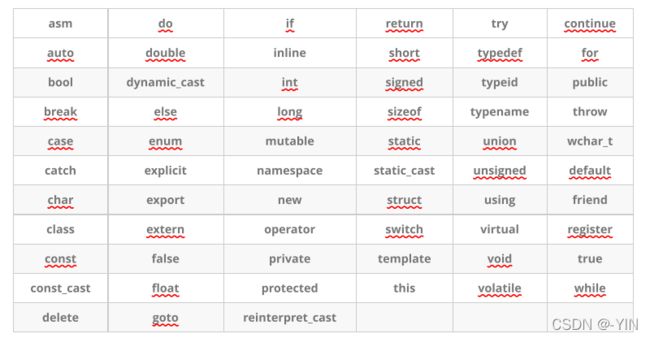
C++63个关键字(有红色波浪线为C语言关键字)
可见 C++ 关键字是在 C语言基础上增加了许多。
const
const 的存储位置
c语言中const 全局变量存储在只读数据段(常量区),编译期最初将其保存在符号表中,第一次使用时为其分配内存,在程序结束时释放。而const 局部变量(局部变量就是在函数中定义的一个const变量)存储在栈中,代码块结束时释放。在c语言中可以通过指针对const局部变量进行修改,而不可以对const全局变量进行修改。因为const全局变量是存储在只读数据段(在常量区)
而c++中,一个const不是必需创建内存空间,而在c中,一个const总是需要一块内存空间。
在c++中是否要为const全局变量分配内存空间,取决于这个const变量的用途,如果是充当着一个值替换(即就是将一个变量名替换为一个值),那么就不分配内存空间,不过当对这个const全局变量取地址或者使用extern时,会分配内存,由于extern意味着使用外部连接,因此必须分配存储空间,这也就是说有几个不同的编译单元应当能够引用它,所以它必须存储空间。存储在只读数据段。也是不能修改的。
c++中对于局部的const变量要区别对待:
对于基础数据类型,也就是const int a = 10这种,编译器会把它放到符号表中,不分配内存,当对其取地址时,会分配内存对于基础数据类型,如果用一个变量初始化const变量,如果const int a = b,那么也是会给a分配内存对于自定数据类型,比如类对象,那么也会分配内存。————参考自CSDN博主「想飞的IT猪」的原创文章,:原文链接
关于const常量的存储位置的讨论(常量折叠)
c 中 const 默认为外部链接,c++中const默认为内部链接。当c语言两个文件中都有const int a的时候,编译器会报重定义的错误。而在c++中,则不会,因为c++中的const默认是内部连接的,const在生成符号时,是local符号。即在本文件中才可见。如要在别的文件中使用它的话(想让const具有外部连接),在文件头部声明:
extern cosnt int data = 10;这样生成的符号就是global符号。
(在static修饰全局变量时也会改变变量的链接属性)
结论:
C 语言中的const是个常变量,被修饰后不能做左值,可以不初始化,但是之后没有机会再初始化。不可以当数组的下标,可以通过指针修改。
C++ 中的const可以看作一个常量。定义的时候必须初始化,可以用作数组的下标。const在C++中编译时进行替换(和宏很像),也可以通过指针修改。
注:通过指针修改在全局区上的const变量,编译可通过,运行就会报异常(C/C++)
C++中通过指针修改:


命名空间
在学习命名空间之前还需要了解一些关于 C++ 的知识
C++预处理器 和 iostream 文件
C++ 和 C一样都使用一个预处理器,在程序进行主编译之前对源文件进行处理
在 C 语言中我们都知道将 C源代码 变成 可执行文件要经过 :
C++ 仍使用#include编译指令 使预处理器将iostream文件的内容添加到程序中以完成 io (输入输出)等,所以使用cin输入 和cout输出都需要包含文件iostream

头文件名
C++ 也使用 编译器自带的头文件(包含文件),相较于 C语言中 如熟悉的 stdio.h (必须使用扩展名 h), C++头文件没有扩展名,有些杯=被重新命名 去掉后缀 h 加上前缀 c 如 cstdlib,不过C++ 仍可以使用老式的 C 的头文件 (详见下图)

命名空间定义
在C/C++中,变量、函数和类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字 污染,
namespace关键字的出现就是针对这种问题的
简而言之,在使用两个代码量较大的项目时 可能存在两个名称都为 fun() 的函数 或者 a 变量, 编译器无法分辨。而命名空间的存在就可以使工程代码封装在 namespace 中, 通过命名空间的名称来明确想使用哪个方法或变量。
举个例子:张三是北大的学生,而李四是清华的学生,他俩的学号都是 001 ,如果你只知道学号无法确定到底是谁,但是如果告诉你是清华的 001 号你就知道指的是 李四。
namespace QingHua
{
struct student{
char name[5];
int num;
};
struct student s = { "LiSi", 001 };
}
注:定义一个命名空间相当于定义一个的
命名空间使用
● 加命名空间名称及作用域限定符( :: )
当用户只想使用命名空间中某个成员时使用这种方式 推荐
std :: cout << "Hello C++";
● 使用 using 将命名空间成员引入
当用户需要频繁使用某个成员时使用,相当于全局变量
#include ● 使用 using namespace 将命名空间成员引入
当需要使用命名空间许多成员而不想每次使用作用于限定符时,直接将命名空间所有成员引入,这是一种省事的方法但是当在大型项目可能会导致命名冲突潜在问题。
#include
函数重载
默认参数
缺省参数是声明或定义函数时为函数的参数制定一个缺省值。在调用该函数时,如果没有实参则使用缺省值,否则使用实参。
可以形象的认为是参数中的 “备胎”。
全缺省参数(参数都有默认值)
void fun(int a = 10, int b = 20, int c = 30)
{
cout<<"a = " << a <<"b = "<< b <<"c = "<< c << endl;
}
半缺省参数(部分参数有默认值)
void fun(int a, int b, int c = 30)
{
cout<<"a = " << a <<"b = "<< b <<"c = "<< c << endl;
}
注:对于带参数列表的函数必须从右往左添加默认值,不能跳着给参数初值 如 void fun(int a = 0,int b, int c = 1) //error
在生命和定义中只能添加一次默认值, 否则会报错:重定义
函数重载定义
默认参数能够让你使用不同数目的参数调用同一个函数,而函数重载能让你使用多个同名函数。(函数的多态)
C++允许在同一作用域中出现同名但是 参数列表不同的几个函数,常用来处理功能类似但数据类型不同的问题。
重载就类似于汉语中一词多义的那种感觉。
为什么C语言不支持重载?
简单来说,因为 C 语言和 C++ 对于函数名修饰规则不一样, C++ 的编译器会对函数名称进行修饰,它会根据函数中的形参类型对每个函数名进行修饰,使编译器和链接器能够区分同名不同参的函数。
linux 下的函数名修饰测试
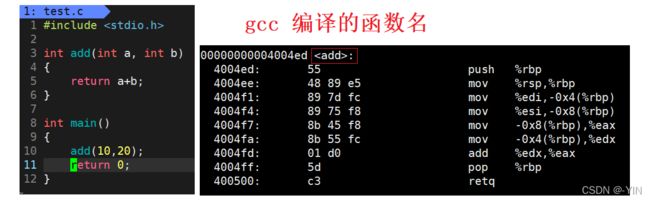
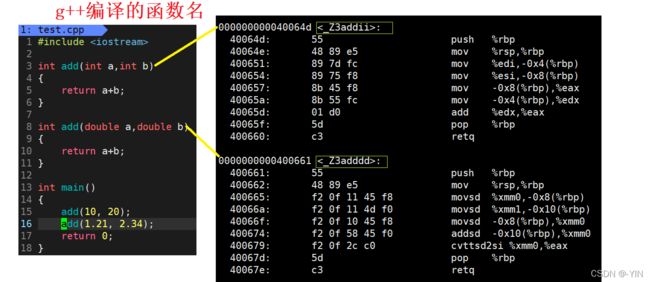
在《程序员的自我修养中》 对 gcc , g++ 与 window vs 的函数名修饰规则做了解释

函数重载调用原理
在函数编译阶段编译器会对函数参数类型进行推演
1> 如果找到参数类型匹配的函数则直接调用
2> 如果没有找到 编译器会尝试进行隐式类型转换如果又可以调用的函数就调用,否则就会报错
引用
引用是已定义变量的别名(另一个名称)。主要用于做函数的形参。
引用的特性:
1. & 不是取地址运算符,而是类型标识符(就像 char*中的 *)。
2. 必须在声明引用变量的时进行初始化。
3. 一个变量可以有多个引用(别名),但一旦引用一个实体就不能引用其他实体。
4. 引用相当于 const 指针,可以理解为 int & b = a; 相当于int* const p = &a (即Tpye & == T * const)
int a = 10;
int& b = a;
//int& b;
//b = a; //error!
.
下面有两个有意思的代码
1. 常引用(const修饰引用)
void test()
{
const int a = 10;
//int& ra = a; //编译出错,类型不匹配 a 为常量
//int& rb = 10; //编译出错,原因同上
double num = 12.34;
// int& rd = num //编译出错
const int& rd = num;
num = 100;
}
当用 int& 引用 double 变量 b 时直接会报错,但将加上 const 后只有如下的 warning
![]()
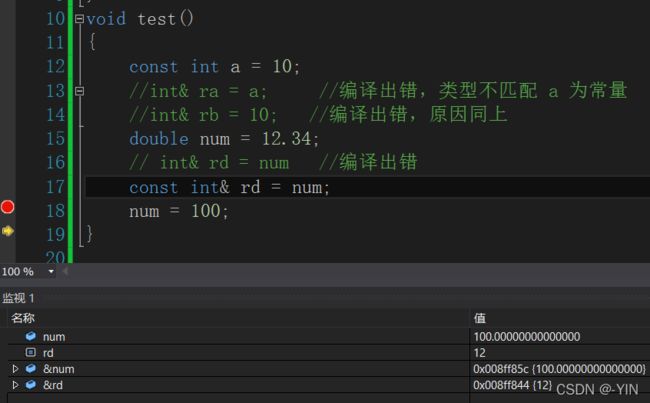
为什么在好像引用成功 num 后,改变num 值后 num 的引用确仍然是 12 ???
结论:num的 “引用” rd的地址与num并不相同,其实rd所引用的并不num而是存储着num的整数部分的临时空间。
临时空间是编译器创建的,用户即不知道该块空间的名字,也不知道该块空间的地址,因此用户是无法修改临时空间中内容的,既然不能修改认为临时空间具有常性。所以加上const编译才通过。
const 修饰引用
1、引用为变量的别名,在定义时必须初始化,不能改变指向,其本身就相当于指针常量(指针类型的常量,其指向不可改变)
2、const在&之前表明引用为常引用,不能通过该引用修改值
3、const在&之后,const 限定作用无效
4、const在&前后都用,效果同2
2.引用做函数返回值
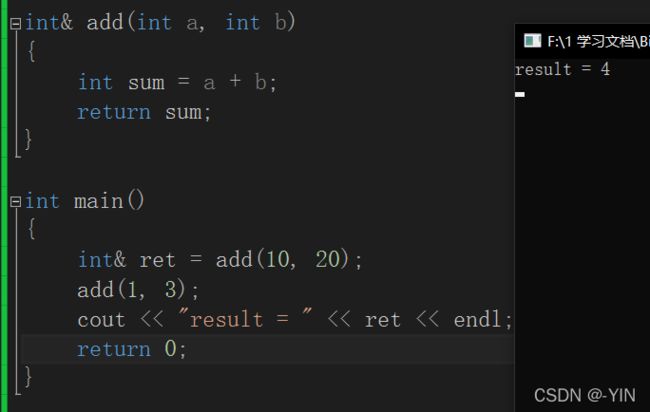
这里 ret 引用的是 add(10,20)的结果 理应是30,为什么ret值为4呢??
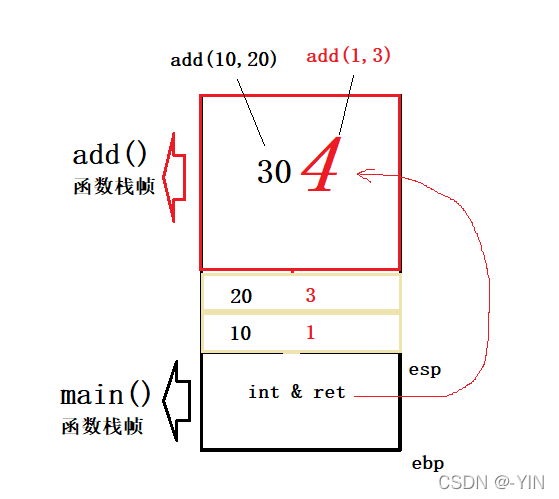
函数调用开辟栈帧,来保存局部变量,函数运行结束开辟的栈空间回收(但是只是接触函数和栈空间的使用关系,但数据不会被清空)。如,酒店退房只是回收房卡无法入住,不会拆掉房间。
注: 所以函数返回时,如果返回对象没被系统回收,就可以用引用返回,否则必须使用传值返回。不能返回函数栈上的空间否则就会出现如上的问题。
传值 引用效率比较
struct A
{
int a[100000];
};
void TestFunc1(A a){}
void TestFunc2(const A& a){}
void TestFunc3(A* a){}
void Test()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 以地址作为函数参数
size_t begin3 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc3(&a);
size_t end3 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl; //传值传参
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl; //传引用传参
cout << "TestFunc2(A*)-time:" << end3 - begin3 << endl; //传地址传参
}

结论:引用做参数和传地址效率差不多,而传值因为要发生拷贝效率很低,这也是传引用做参数的优点。
引用和指针的区别
学过C语言的人都听过指针,或亲身体验过其复杂但又巧妙的设计
在语法层面引用是一个别名,和其引用实体公用同一块空间;而指针(变量)是存放地址的一个变量。 真的这么简单吗?所以C++是如何实现引用的呢??

通过查看汇编指令我们惊奇的发现,不能说指针和引用是毫无关系…这简直一毛一样啊! 原来 C++ 的引用也只不过是指针披上了引用的外衣罢了,底层实现逻辑仍是指针的方式。
结论:
● 引用只是C++语法糖,可以看作编译器自动完成取地址,解引用的常量指针。
● 引用语法层面为了便于理解,而底层引用是按照指针方式实现的
● 引用与指针语法层面不同点(概念,特性)
(1) 引用是一个变量的别名,而指针(变量)存放变量的地址。
(2) 引用在定义时必须要初始化,不能先声明再赋值,而指针可以。
(3) sizeof()含义不同:sizeof 引用结果是引用类型的大小,而 siezof 指针始终是地址大小(32位下 4字节,64位下8字节)
(4) 访问方式不同: 指针需要解引用, 引用不需要。
(5) 引用自增 +1 是所引用的变量加一, 而指针 +1 是加上指针所指向类型的大小。
(6) 有多级指针(二级指针),没有多级引用。
(7) 没有 NULL 引用, 有 NULL 指针。
(8)引用没有int & const因为引用本身就不可变, 而const int &表示常引用; 指针有int * const(指针常量)表示指针本身指向不能改变, const int* 或 int const *(指向常量的指针)只能修改指向,不能修改指针所指对象的值。