Spark Core之RDD编程(内容超详细)
2.1 得到RDD
(1)从数据源
a:外部数据源 :文件、数据库、hive…
b:从scala集合得到:带序列的集合都可以得到RDD

2.2 RDD的转换
在 RDD 上支持 2 种操作:
transformation:从一个已知的 RDD 中创建出来一个新的 RDD 例如: map就是一个transformation.
action:在数据集上计算结束之后, 给驱动程序返回一个值
根据 RDD 中数据类型的不同, 整体分为 2 种 RDD:
- Value类型
- Key-Value类型(其实就是存一个二维的元组)
2.3 Value 类型
2.3.1 map(func)
作用: 返回一个新的 RDD, 该 RDD 是由原 RDD 的每个元素经过函数转换后的值而组成, 就是对 RDD 中的数据做转换。
案例:
//1.得到SparkContext
val conf = new SparkConf().setMaster("local[2]").setAppName("MapDemo1")
val sc = new SparkContext(conf)
//2.创建RDD
var list1 = List(30,50,70,60,10,20)
val rdd1 = sc.parallelize(list1)
//3.转换
val rdd2 = rdd1.map(_ * 2)
//4.行动算子
val res = rdd2.collect()
res.foreach(println)
//5.关闭
sc.stop()
2.3.2 mapPartitions(func)
作用: 类似于map(func), 但是是独立在每个分区上运行.所以:Iterator => Iterator。
假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区。
案例:
//1.得到SparkContext
val conf = new SparkConf().setMaster("local[2]").setAppName("MapDemo1")
val sc = new SparkContext(conf)
//2.创建RDD
var list1 = List(30,50,70,60,10,20)
val rdd1 = sc.parallelize(list1,2)
//3.转换
val rdd2 = rdd1.mapPartitions(it => it.map(_ * 2)) //分区为2 故执行两次
//4.行动算子
val res = rdd2.collect()
res.foreach(println)
//5.关闭
sc.stop()
注:map()与mapPartitions()的区别:
map():传递的函数每个元素执行一次
mapPartitions():传递的函数,每个分区执行一次 注意,当每个分区数据量比较大的时候,尽量避免在分区时toList操作,把分区内的数据全部加在到内存中,有可能会导致分区oom(OOM,全称“Out Of Memory”,意思是“内存用完了”。 它来源于java.lang.OutOfMemoryError。)
当与外部进行连接时应选择mapPartitions(),避免连接数过多。
2.3.3 mapPartitionsWithIndex(func)
作用: 和mapPartitions(func)类似. 但是会给func多提供一个Int值来表示分区的索引. 所以func的类型是:(Int, Iterator) => Iterator
案例:
//1.得到SparkContext
val conf = new SparkConf().setMaster("local[2]").setAppName("MapDemo1")
val sc = new SparkContext(conf)
//2.创建RDD
var list1 = List(30,50,70,60,10,20)
val rdd1 = sc.parallelize(list1,2)
//3.转换
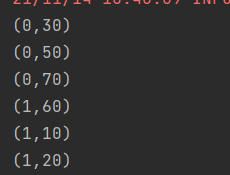
val rdd2 = rdd1.mapPartitionsWithIndex((index, it) => {
it.map(x => (index, x)) //得到分区和对应元素的元组
})
//4.行动算子
val res = rdd2.collect()
res.foreach(println)
//5.关闭
sc.stop()
结果:
2.3.4 flatMap(func) (flat+map)
作用: 类似于map,但是每一个输入元素可以被映射为 0 或多个输出元素(所以func应该返回一个序列,而不是单一元素 T => TraversableOnce[U])

//1.得到SparkContext
val conf = new SparkConf().setMaster("local[2]").setAppName("MapDemo1")
val sc = new SparkContext(conf)
//2.创建RDD
var list1 = List(30,5,70,6,20,1)
val rdd1 = sc.parallelize(list1,2)
//3.转换
// //rdd2中存储这些元素和它们的平方、三次方
// val rdd2 = rdd1.flatMap(x =>List(x,x*x,x*x*x))
//只保留list中偶数的平方,三次方
val rdd2 = rdd1.flatMap(x => { //flatmap必须要返回一个集合
if ( x%2 == 0){
List(x, x * x, x * x * x)
}else{
List()
}
})
//4.行动算子
rdd2.collect().foreach(println)
//5.关闭
sc.stop()
2.3.5 filter(func)算子
作用: 过滤. 返回一个新的 RDD 是由func的返回值为true的那些元素组成
案例:过滤出list集合中大于30的值
//1.得到SparkContext
val conf = new SparkConf().setMaster("local[2]").setAppName("MapDemo1")
val sc = new SparkContext(conf)
//2.创建RDD
var list1 = List(30,50,70,60,20,10)
val rdd1 = sc.parallelize(list1,2)
//3.转换
//过滤出list中大于30的元素值
val rdd2 = rdd1.filter(x => x > 30)
//4.行动算子
rdd2.collect().foreach(println)
//5.关闭
sc.stop()
2.3.6 glom()算子
作用: 将每一个分区的元素合并成一个数组,形成新的 RDD 类型是RDD[Array[T]]
案例:
val conf = new SparkConf().setMaster("local[2]").setAppName("MapDemo1")
val sc = new SparkContext(conf)
var list1 = List(30,50,70,60,20,10)
val rdd1 = sc.parallelize(list1,2)
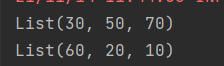
val rdd2 = rdd1.glom().map(x => x.toList) //两个分区,rdd2中对应两个数组
rdd2.collect().foreach(println)
sc.stop()
结果:
2.3.7 groupBy(func)
作用:按照func的返回值进行分组。
func返回值作为 key, 对应的值放入一个迭代器中. 返回的 RDD: RDD[(K, Iterable[T])。
每组内元素的顺序不能保证, 并且甚至每次调用得到的顺序也有可能不同。
案例:
val conf = new SparkConf().setMaster("local[2]").setAppName("GroupBy")
val sc = new SparkContext(conf)
var list1 = List(30,50,7,60,20,1)
val rdd1 = sc.parallelize(list1,2)
val rdd2 = rdd1.groupBy(x => x % 2) //偶数为一组
val rdd3 = rdd2.map({ //使用偏函数,按分组求和
case (k, it) => (k, it.sum)
})
rdd3.collect().foreach(println)
sc.stop()
2.3.8 sample(withReplacement, fraction, seed)
作用:
1.以指定的随机种子随机抽样出比例为fraction的数据,(抽取到的数量是: size * fraction). 需要注意的是得到的结果并不能保证准确的比例。
2.withReplacement表示是抽出的数据是否放回,true为有放回的抽样,false为无放回的抽样. 放回表示数据有可能会被重复抽取到, false 则不可能重复抽取到。如果是false, 则fraction必须是:[0,1], 是 true 则大于等于0就可以了。
3.seed用于指定随机数生成器种子。 一般用默认的, 或者传入当前的时间戳。
案例:
val conf = new SparkConf().setMaster("local[2]").setAppName("GroupBy")
val sc = new SparkContext(conf)
var list1 = 1 to 20
val rdd1 = sc.parallelize(list1,2)
//参数1:表示是否放回抽样,false 比例[0,1] true[0,∞]
val rdd2 = rdd1.sample(true, 3) //抽取的比例在0.2附近,不一定精确
rdd2.collect().foreach(println)
sc.stop()
2.3.9 distinct([numTasks]))
作用:
对 RDD 中元素执行去重操作. 参数表示任务的数量.默认值和分区数保持一致。
案例:
case class User(age:Int,name:String){
override def equals(obj: Any): Boolean = obj match {
case User(age,_) => this.age == age
case _ => false
}
override def hashCode(): Int = this.age
}
object Distinct {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("GroupBy")
val sc = new SparkContext(conf)
// var list1 = List(30,50,70,60,10,20,10,30,50,70)
// val rdd1 = sc.parallelize(list1, 2)
// val rdd2 = rdd1.distinct()
val rdd1 = sc.parallelize(List(User(10, "lisi"), User(20, "zs"), User(10, "ab")))
implicit val ord:Ordering[User] = new Ordering[User]{
override def compare(x: User, y: User): Int = x.age - y.age
}
val rdd2 = rdd1.distinct(2)
rdd2.collect().foreach(println)
sc.stop()
2.3.10 coalesce(numPartitions)
作用: 缩减分区数到指定的数量,用于大数据集过滤后,提高小数据集的执行效率。
案例:
val conf = new SparkConf().setMaster("local[2]").setAppName("coalesce")
val sc = new SparkContext(conf)
val list1 = List(30, 50, 70, 60, 10, 20)
val rdd1 = sc.parallelize(list1,5)
println(rdd1.getNumPartitions)
//减少分区的时候,默认是不会进行shuffle
val rdd2 = rdd1.coalesce(2) //减少分区数到2
println(rdd2.getNumPartitions)
2.3.11 repartition(numPartitions)
作用: 根据新的分区数, 重新 shuffle 所有的数据, 这个操作总会通过网络,新的分区数相比以前可以多, 也可以少。
2.3.12 sortBy(func,[ascending], [numTasks])
作用: 使用func先对数据进行处理,按照处理后结果排序,默认为正序。
val list1 = List("a","c","b","d","b")
val rdd1 = sc.parallelize(list1,2)
//升序
val rdd2 = rdd1.sortBy(x => x)
rdd2.collect().foreach(println)
//降序,将ascending的值设置为false即可
val rdd3 = rdd1.sortBy(x => x, false)
rdd3.collect().foreach(println)
自定义SortBy函数:
//定义样例类
case class Person(age:Int,name:String)
object SortBy2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("SortBy2")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Person(10,"lisi")::Person(20,"zs")::Person(15,"ww")::Nil)
implicit val ord:Ordering[Person] = new Ordering[Person]{ //自定义为按年龄大小排序
override def compare(x: Person, y: Person): Int = x.age - y.age
}
//如果是样例类,或者元组,classTag不需要传
val rdd2 = rdd1.sortBy(user => user)
rdd2.collect().foreach(println)
sc.stop()
}
}
2.3 双 Value 类型交互
这里的“双 Value类型交互”是指的两个 RDD[V]进行交互。
2.3.1 union(otherDataset)
作用:求并集, 对源 RDD 和参数 RDD 求并集后返回一个新的 RDD。
val rdd1 = sc.parallelize(list1,2)
val rdd2 = sc.parallelize(list2,3)
//并集
val rdd3 = rdd1.union(rdd2)
2.3.2 subtract (otherDataset)
作用: 计算差集. 从原 RDD 中减去 原 RDD 和 otherDataset 中的共同的部分。
2.3.3 intersection(otherDataset)
作用: 计算交集. 对源 RDD 和参数 RDD 求交集后返回一个新的 RDD。
2.3.4 zip(otherDataset)
作用: 拉链操作. 需要注意的是, 在 Spark 中, 两个 RDD 的元素的数量和分区数都必须相同, 否则会抛出异常.(在 scala 中, 两个集合的长度可以不同)其实本质就是要求的每个分区的元素的数量相同。
2.3.5 Key-Value 类型
大多数的 Spark 操作可以用在任意类型的 RDD 上, 但是有一些比较特殊的操作只能用在key-value类型的 RDD 上。这些特殊操作大多都涉及shuffle 操作, 比如: 按照 key 分组(group), 聚集(aggregate)等。
在 Spark 中, 这些操作在包含对偶类型(Tuple2)的 RDD 上自动可用(通过隐式转换)。
2.3.6 partitionBy
作用: 对 pairRDD 进行分区操作,如果原有的 partionRDD 的分区器和传入的分区器相同, 则返回原 pairRDD,否则会生成 ShuffleRDD,即会产生 shuffle过程。
2.3.7 reduceByKey(func, [numTasks])
作用: 在一个(K,V)的 RDD 上调用,返回一个(K,V)的 RDD,使用指定的reduce函数,将相同key的value聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
注:
1.是一个聚合算子;
2.和scala(reduce,foldLeft)的不一样,scala最终都聚合成一个值;
3.spark的这个聚合是根据key来聚合的,结果和key的种类有关系;
4.先调整类型为 kv
2.3.8 groupByKey()
作用: 按照key进行分组。
注:
1.分组,按key进行分组;
2.groupBy(x => … )按照返回值来分;
3.groupBykey只能用于kv形式的;
4.groupBy任意RDD都可以使用。
案例:WordCount
val conf = new SparkConf().setMaster("local[2]").setAppName("GroupBykey")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array("hello","hello","world","hello","atguigu","hello","atguigu","atguigu"))
val wordOne = rdd1.map((_, 1))
val wordGrouped = wordOne.groupByKey().mapValues(_.sum) //对每一组的v求和
wordGrouped.collect().foreach(println)
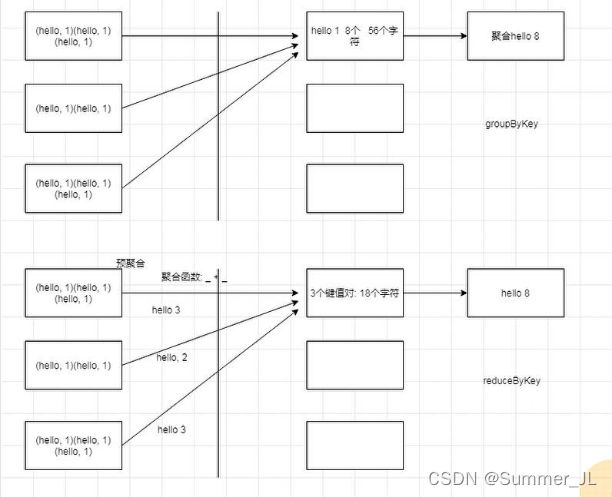
注:reduceByKey 和 groupByKey的区别
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
groupByKey:按照key进行分组,直接进行shuffle。
开发指导:reduceByKey比groupByKey性能更好,建议使用。但是需要注意是否会影响业务逻辑。
2.3.9 foldByKey
参数: (zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
作用:aggregateByKey的简化操作,seqop和combop相同
注:
1.折叠,也是聚合和reduceByKey一样,也有聚合,所有的聚合算子都有预聚合。
2.多了一个0值得功能。
3.0值只在分区内聚合(预聚合)时有效。
2.3.10 aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
函数声明:
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,combOp: (U, U) => U): RDD[(K, U)] = self.withScope {aggregateByKey(zeroValue, defaultPartitioner(self))(seqOp, combOp)}
使用给定的 combine 函数和一个初始化的zero value, 对每个key的value进行聚合.
这个函数返回的类型U不同于源 RDD 中的V类型. U的类型是由初始化的zero value来定的. 所以, 我们需要两个操作: - 一个操作(seqOp)去把 1 个v变成 1 个U - 另外一个操作(combOp)来合并 2 个U。
第一个操作用于在一个分区进行合并, 第二个操作用在两个分区间进行合并,为了避免内存分配, 这两个操作函数都允许返回第一个参数, 而不用创建一个新的U。
参数描述:
zeroValue:给每一个分区中的每一个key一个初始值;
seqOp:函数用于在每一个分区中用初始值逐步迭代value;
combOp:函数用于合并每个分区中的结果。
注:aggregateByKey实现了分区聚合逻辑和分区间的聚合逻辑不一样

2.3.11 combineByKey[C]
作用: 针对每个K, 将V进行合并成C, 得到RDD[(K,C)]
函数声明:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] =
self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue,
mergeCombiners,
partitioner, mapSideCombine, serializer)(null)}
参数描述:
createCombiner: combineByKey会遍历分区中的每个key-value对. 如果第一次碰到这个key, 则调用createCombiner函数,传入value, 得到一个C类型的值.(如果不是第一次碰到这个 key, 则不会调用这个方法)
mergeValue: 如果不是第一个遇到这个key, 则调用这个函数进行合并操作. 分区内合并
mergeCombiners 跨分区合并相同的key的值©. 跨分区合并 。
案例:
//求每个key的和
val result1 = rdd1.combineByKey(
v => v,
(c: Int, v: Int) => c + v,
(c1: Int, c2: Int) => c1 + c2
)
//每个key在每个分区内的最大值,然后再求出这些最大值的和
val result2 = rdd1.combineByKey(
v => v, //遍历分区中的每个key-value对,第一次碰到这个key, 则调用createCombiner函数,传入value
(max:Int,v:Int) =>max.max(v), //如果不是第一个遇到这个key, 则调用这个函数进行合并操作. 分区内合并
(max1:Int,max2:Int) => max1+max2 //跨分区合并相同的key的值(C). 跨分区合并
)
//求每个key的平均值
val result3 = rdd1.combineByKey(
(v:Int) => (v,1),
(sumCount: (Int,Int),v ) => (sumCount._1 +v,sumCount._2),
(sumCount1: (Int,Int),sumCount2:(Int,Int)) => (sumCount1._1 +sumCount2._1,sumCount1._2 +sumCount2._2)
).mapValues {
case (sum,count) => sum.toDouble/count }
2.3.11 sortByKey
作用: 在一个(K,V)的 RDD 上调用, K必须实现 Ordered[K] 接口(或者有一个隐式值: Ordering[K]), 返回一个按照key进行排序的(K,V)的 RDD。
1.用来排序
2.只能用来排序kv形式的RDD
2.3.12 mapValues
作用: 针对(K,V)形式的类型只对V进行操作
2.3.13 join(otherDataset, [numTasks])
内连接:
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素对在一起的(K,(V,W))的RDD。
val rdd1 = sc.parallelize(Array((1, "a"), (1, "b"), (2, "c"),(4,"d")))
val rdd2 = sc.parallelize(Array((1, "aa"), (1, "bb"), (2, "cc")))
val rdd3 = rdd1.join(rdd2) //内连接
//左外连接
val rdd4 = rdd1.leftOuterJoin(rdd2)
注意:
如果某一个 RDD 有重复的 Key, 则会分别与另外一个 RDD 的相同的 Key进行组合.
也支持外连接: leftOuterJoin, rightOuterJoin, and fullOuterJoin.
2.3.14 案例实操
数据结构:时间戳,省份,城市,用户,广告,字段使用空格分割。
1516609143867 6 7 64 16
61516609143869 9 4 75 18
181516609143869 1 7 87 12
需求: 统计出每一个省份广告被点击次数的 TOP3
val conf = new SparkConf().setAppName("Practice1").setMaster("local[2]")
val sc = new SparkContext(conf)
//1.RDD[点击记录] map
val lineRDD = sc.textFile("E:/agent.log")
//2.RDD[(省份,广告),1] reduceByKey
val provinceAdsOne = lineRDD.map(line => {
val split = line.split(" ") //使用空格切割
})
//3.RDD[(省份,广告),10] map
val provinceAdsOneCount = provinceAdsOne.reduceByKey(_ + _)
//4.RDD[(省份,(广告,10))] 做groupBykey
val provinceAndAdsCount = provinceAdsOneCount.map({
case ((pro,ads),count) => (pro,(ads,count)) //调整数据结构
})
//5.RDD[(省份,Iterable(广告1,10),(广告2,7),(广告3,5)...)] 做map操作 只对内部list排序,取前三
val proAndAdsCountGrouped = provinceAndAdsCount.groupByKey()
//不能使用spark的排序,用scala的排序
val result = proAndAdsCountGrouped.map({
case (pro, adsCount) =>
//Iterable是非容器式的集合,只有先转换成能容器式的集合才能用sortBy排序
(pro, adsCount.toList.sortBy(_._2)(Ordering.Int.reverse).take(3))
})
//最后按照省份排序
val res = result.sortByKey()
res.collect().foreach(println)
sc.stop()
2.4 RDD的 Action 操作
2.4.1 reduce(func)
通过func函数聚集 RDD 中的所有元素,先聚合分区内数据,再聚合分区间数据。
2.4.2 collect
以数组的形式返回 RDD 中的所有元素.所有的数据都会被拉到 driver 端, 所以要慎用。
2.4.3 count()
返回 RDD 中元素的个数。
2.4.4 take(n)
返回 RDD 中前 n 个元素组成的数组,take 的数据也会拉到 driver 端, 应该只对小数据集使用。
2.4.5 first
返回 RDD 中的第一个元素. 类似于take(1)。
2.4.6 takeOrdered(n, [ordering])
返回排序后的前 n 个元素, 默认是升序排列,数据也会拉到 driver 端。
2.4.7 aggregate
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U
aggregate函数将每个分区里面的元素通过seqOp和初始值进行聚合,然后用combine函数将每个分区的结果和初始值(zeroValue)进行combine操作。这个函数最终返回的类型不需要和RDD中元素类型一致。
注意:
zeroValue 分区内聚合和分区间聚合的时候各会使用一次。
2.4.8 fold
折叠操作,aggregate的简化操作,seqop和combop一样的时候,可以使用fold
2.4.9 saveAsTextFile(path)
作用:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用toString方法,将它装换为文件中的文本。
2.4.10 saveAsSequenceFile(path)
作用:将数据集中的元素以 Hadoop sequencefile 的格式保存到指定的目录下,可以使 HDFS 或者其他 Hadoop 支持的文件系统。
2.4.11 saveAsObjectFile(path)
作用:用于将 RDD 中的元素序列化成对象,存储到文件中。
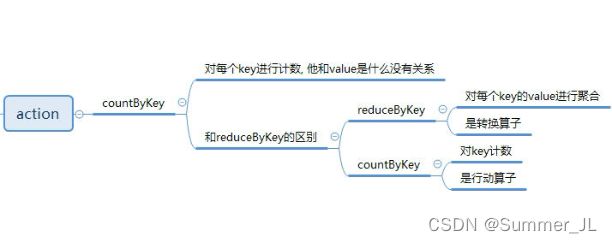
2.4.12 countByKey()
作用:针对(K,V)类型的 RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
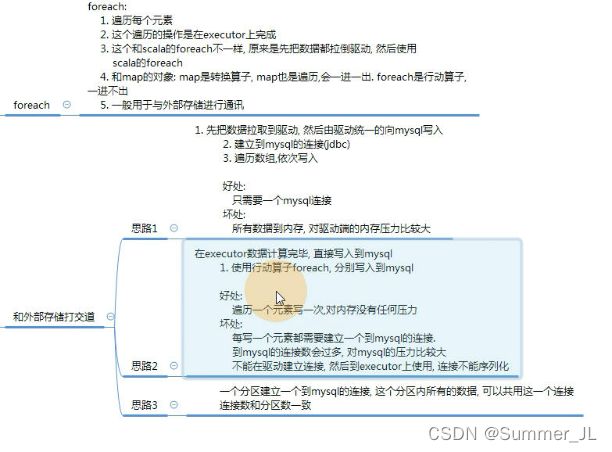
2.4.13 foreach(func)
作用: 针对 RDD 中的每个元素都执行一次func 。每个函数是在 Executor 上执行的, 不是在 driver 端执行的。