SQL聚合函数、group by&having、limit
聚合函数
示例:某user_profile表如下:
| id | device_id | gender | age | university | gpa |
| 1 | 2234 | male | 21 | 北京大学 | 3.2 |
| 2 | 2235 | male | NULL | 复旦大学 | 3.8 |
| 3 | 2236 | female | 20 | 复旦大学 | 3.5 |
查找复旦大学学生gpa最高值
select max(gpa)
from user_profile
where university='复旦大学'类似的用法:
- AVG() 返回某列的均值
- COUNT() 返回某列的行数
- MAX() 返回某列的最大值
- MIN() 返回某列的最小值
- SUM() 返回某列的和
注意聚合函数都会忽略列中的NULL值,但是COUNT(*)也就是统计全部数据的行数时,不会忽略NULL值
在一些聚集运算中,容易出现结果为非整数的情况,这时候如果想要限定结果返回的小数位数就可以使用SQL中内置的round函数,语法格式为round(value,n),其中 value代表想要限制小数位数的字段,n代表想要限制的小数位数。
下列语句就代表求gpa列的均值,并保留一位小数。
select round(avg(gpa),1) as avg_gpaGroup by
SELECT university,avg(gpa) AS avg_gpa
FROM user_profile
Group By university
输出:
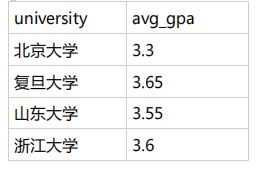
示范的SELECT 语句指定了两个列:university为用户的学校, avg(gpa)为计算字段,代表平均gpa。 GROUP BY 子句指示SQL按university分组分别计算每个学校的平均gpa情况,从输出中可以看到,结果返回了每个大学的平均gpa数值。
在使用Group by时,有一些事项需要注意:
1. GROUP BY 子句可以包含任意数目的列,因而可以对分组进行嵌套, 更细致地进行数据分组。
2. 除聚集计算语句外,SELECT 语句中的每一列都必须在 GROUP BY 子句 中同时给出。
3. 如果分组列中包含具有 NULL 值的行,则 NULL 将作为一个分组返回。 如果列中有多行 NULL 值,它们将分为一组。
4. GROUP BY 子句必须出现在 WHERE 子句之后,ORDER BY 子句之前。
Having
用 GROUP BY 分组数据后,想要过滤数据不能使用where,要使用专门的having语句(过滤出平均gpa大于3.5的学校)
having 条件代码
SELECT university,avg(gpa) AS avg_gpa
FROM user_profile
Group By university
Having avg_gpa>3.5Order by
分组查询结果也支持排序功能,所需要用到的语句是Order By(根据gpa的平均值升序排列)
order by 字段名 asc|desc (升序|降序)
SELECT university,avg(gpa) AS avg_gpa
FROM user_profile
Group By university
Order by avg_gpalimit
分页查询employees表,每5行一页,返回第2页的数据
SELECT *
FROM employees
LIMIT 5,5limit 语句结构: limit x,y
x:从第几条记录开始返回(第一条记录序号为0,默认为0)
Y :返回几条记录