数据结构链表oj讲解
目录
反转单链表
合并两个有序链表
链表的回文结构
链表中倒数第k个节点
相交链表
移除链表元素
链表分割
环形链表Ⅱ
复制带随机指针的链表

反转单链表
1、题目描述
leetcode:206、反转单链表
给你单链表的头节点
head,请你反转链表,并返回反转后的链表。
示例:
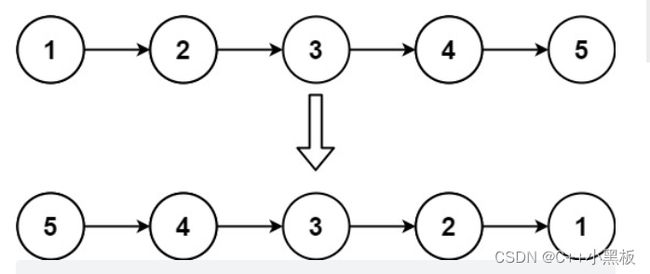
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
这道题目比较暴力的算法是新创建一个链表,把旧链表的数据一个一个挪下来,进行头插。
这样就可以解答出来,不过这种方式的时间复杂度是0(N),空间复杂度O(N),那么我们是否可以简化一下复杂度呢?很显然我们要想反转链表,遍历一遍是必须的,所以我们是否可以节省空间,对原链表下手,而不开辟新的空间呢?答案是肯定的。
2、解:三指针反转单链表
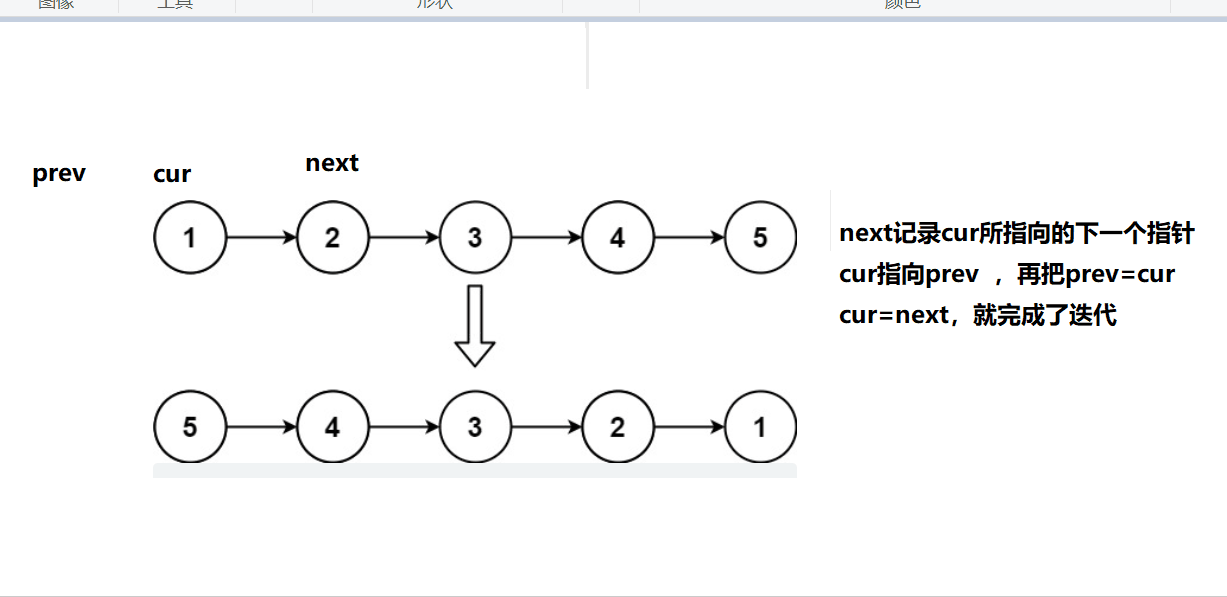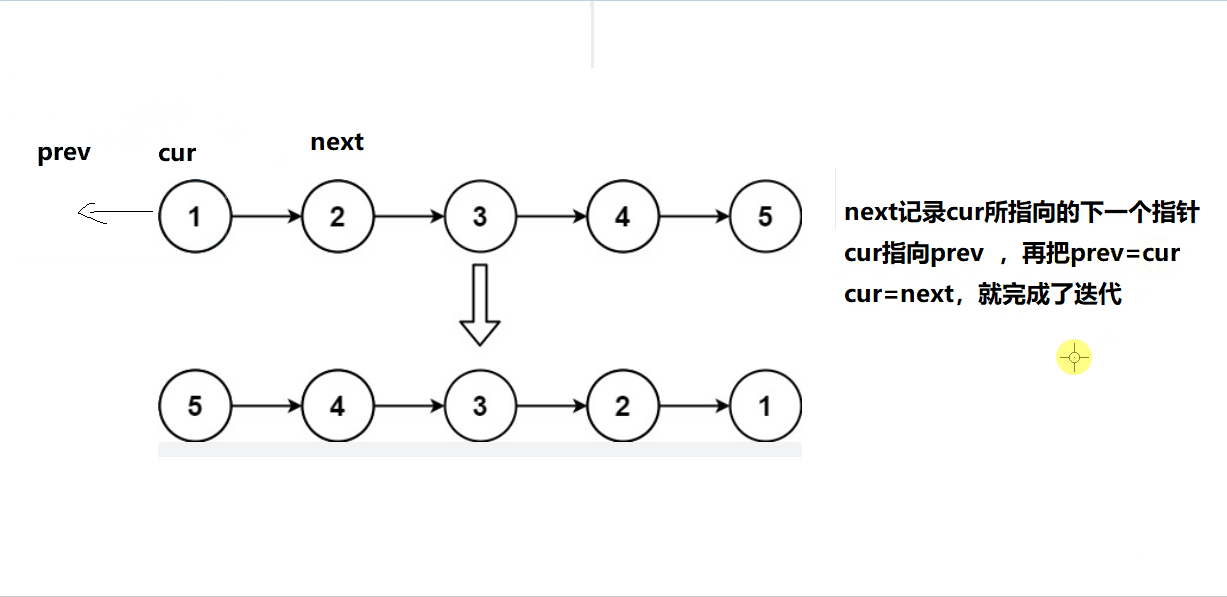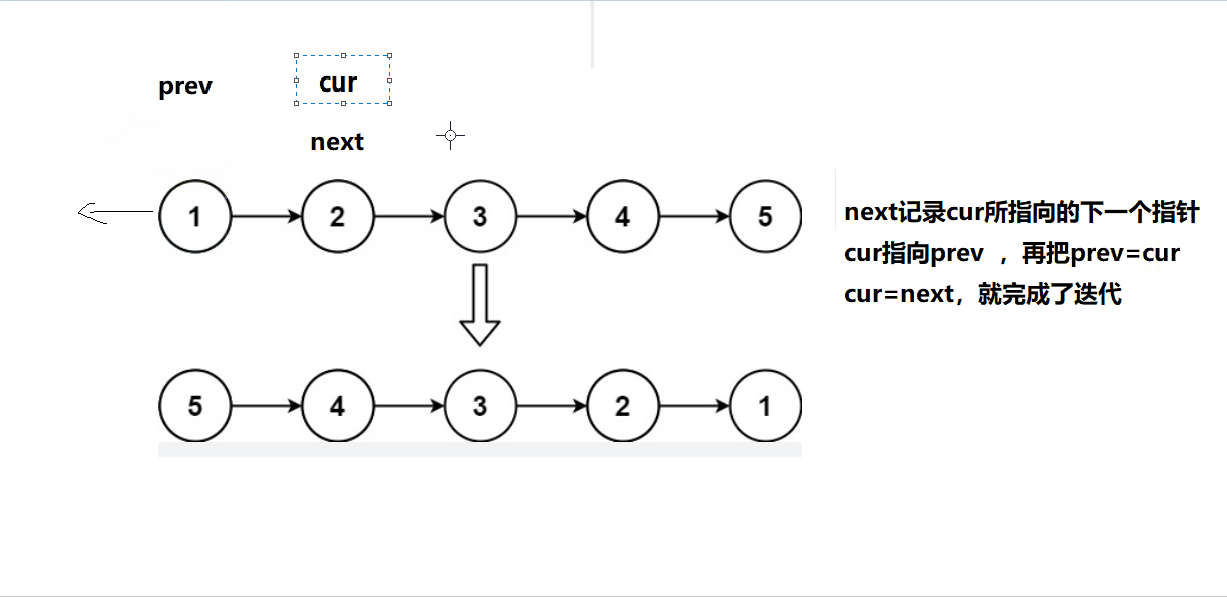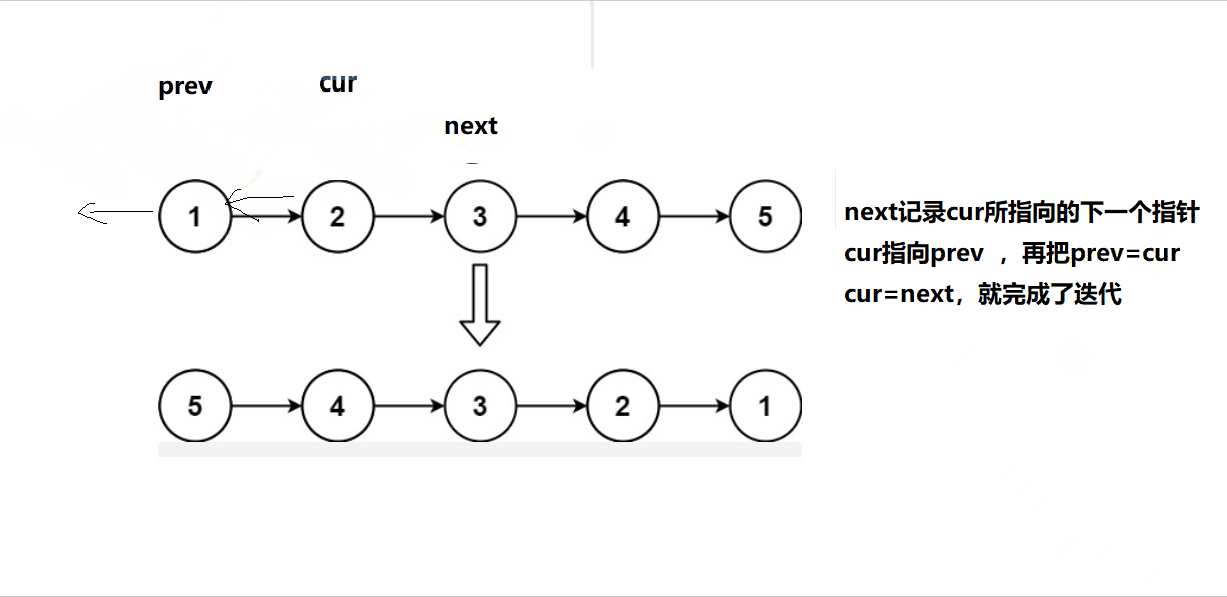
只需要注意一下最后需要返回的头是什么就可以了。
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* prev=NULL;
struct ListNode* cur=head;
struct ListNode* next=NULL;
if(head==NULL)
{
return NULL;
}
while(cur)
{
next=cur->next;
cur->next=prev;
prev=cur;
cur=next;
}
return prev;
}合并两个有序链表
1、题目描述
leetcode:21、合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
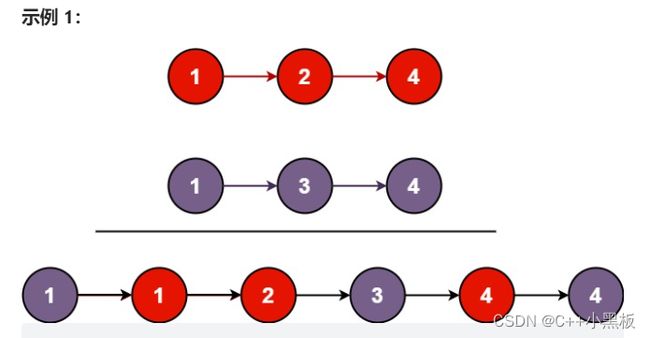
两个指针对两个链表进行遍历,小的尾插,即可。需要注意的是当一个链表结束的时候另一个链表还没结束的处理。
2、解:
带哨兵位的链表进行解答在找头节点的时候比较方便。
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
{
struct ListNode* guard=(struct ListNode*)malloc(sizeof(struct ListNode));
guard->next=NULL;
struct ListNode* cur1=list1;
struct ListNode* cur2=list2;
struct ListNode* cur=guard;
while(cur1&&cur2)
{
if(cur1->valval)
{
cur->next=cur1;
cur1=cur1->next;
}
else
{
cur->next=cur2;
cur2=cur2->next;
}
cur=cur->next;
}
while(cur1)
{
cur->next=cur1;
cur1=cur1->next;
cur=cur->next;
}
while(cur2)
{
cur->next=cur2;
cur2=cur2->next;
cur=cur->next;
}
struct ListNode* newhead=guard->next;
free(guard);
guard=NULL;
return newhead;
} 链表的回文结构
1、题目描述
牛客:(OR36 链表的回文结构)
对于一个链表,请设计一个时间复杂度为O(n),额外空间复杂度为O(1)的算法,判断其是否为回文结构。
给定一个链表的头指针A,请返回一个bool值,代表其是否为回文结构。保证链表长度小于等于900。
测试样例:
1->2->1->2 返回: true
1->2->3->2->1 返回: true
1->2->3->4->2 返回: false
对于回文类的题目,比较快捷的方式就是找到链表的中间节点,对后半段链表进行翻转,然后和前半段链表进行比较,这种方式是比较便捷的。
这里还有一个问题,如何查找链表的中间节点,可能有的方式是遍历计数,然后找中间节点,这种方式是比较低效的,博主想给大家介绍的方式是采用快慢指针的方式查找中间节点。
演示:
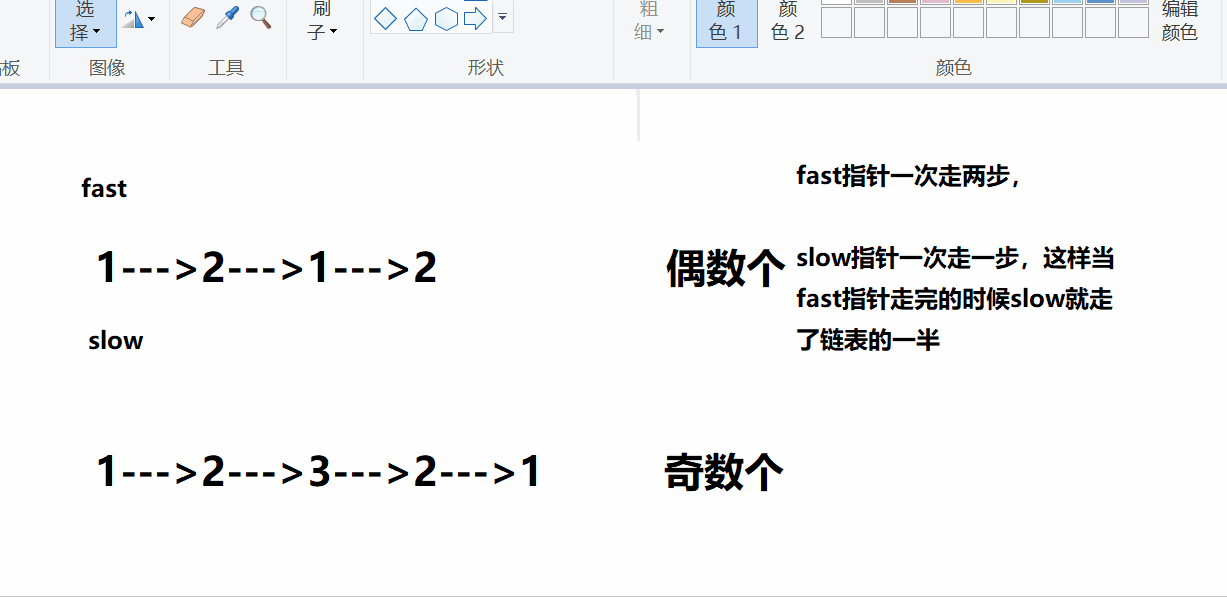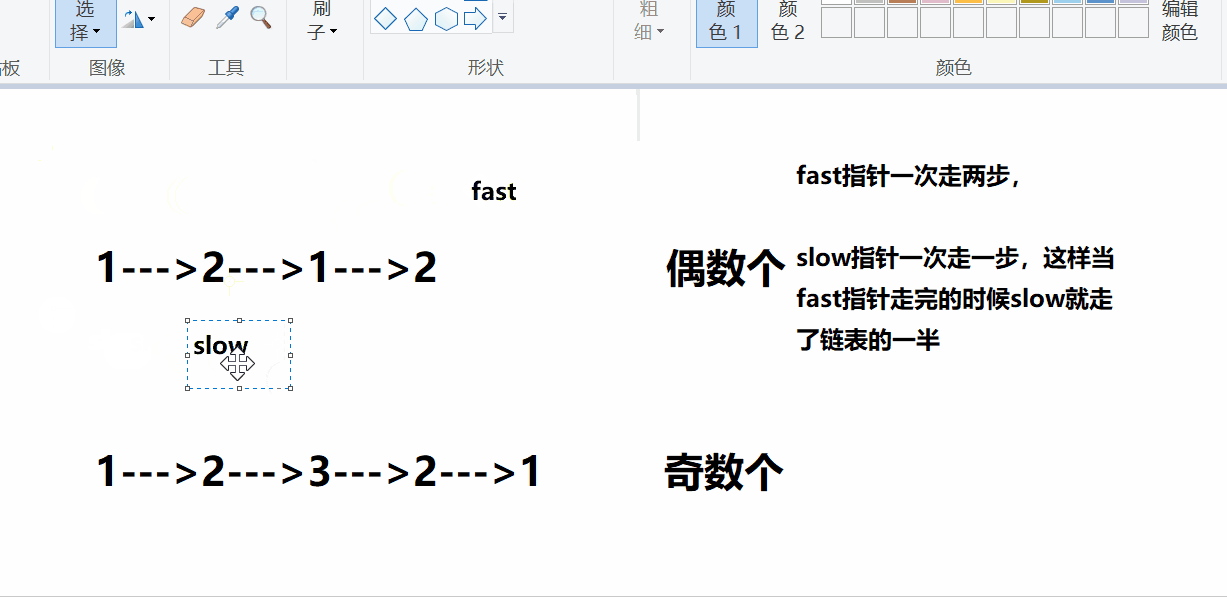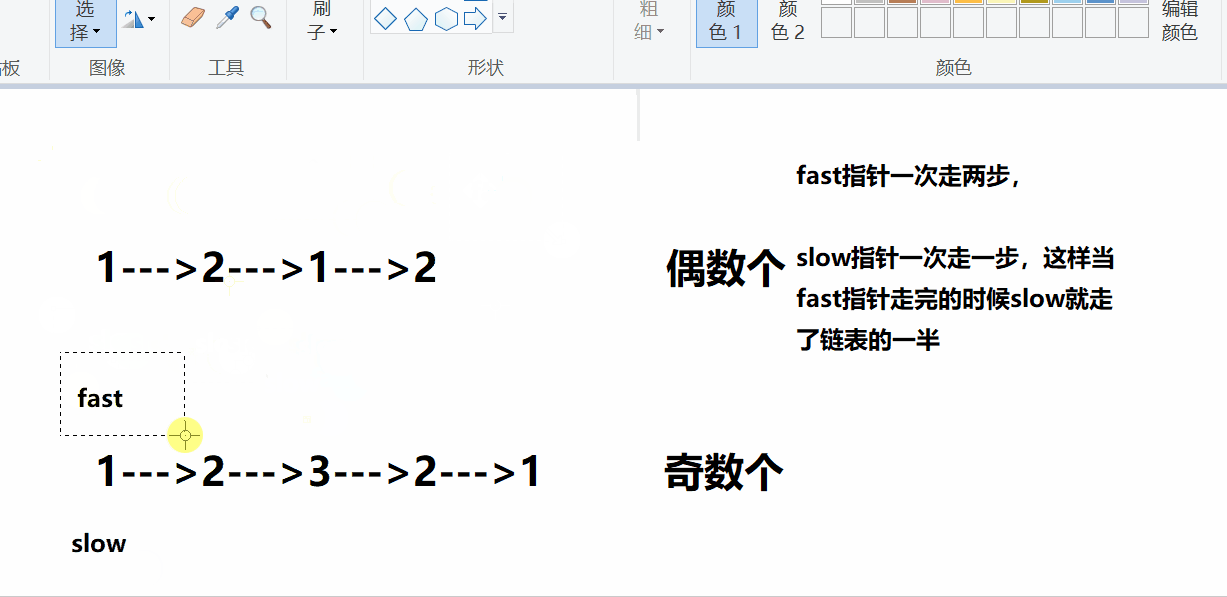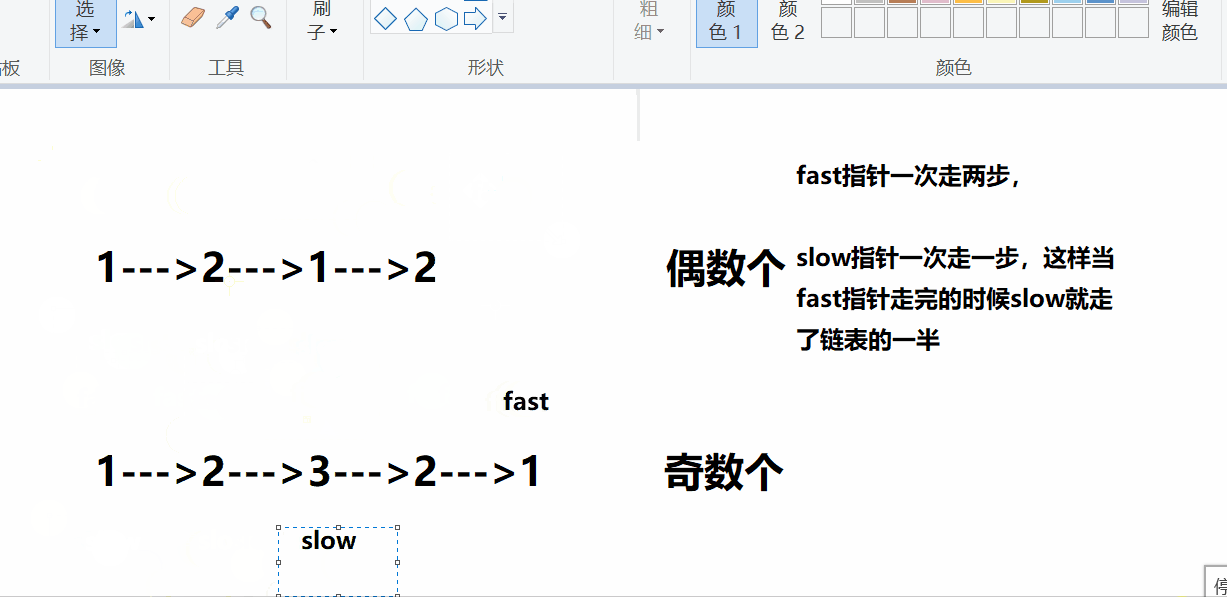
通过观察可以发现,快慢指针对于奇数个和偶数个的处理不一致,只需添加限定条件即可。
找到中间节点后,反转链表我放在上面了,可以直接拿来用,所以,看代码:
class PalindromeList {
public:
struct ListNode* middleNode(struct ListNode* head)
{
struct ListNode* fast,*slow;
fast=slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
}
return slow;
}
struct ListNode* reverseList(struct ListNode* head)
{
struct ListNode* cur=head;
struct ListNode* prev=NULL;
struct ListNode* next=NULL;
while(cur)
{
next=cur->next;
cur->next=prev;
prev=cur;
cur=next;
}
return prev;
}
bool chkPalindrome(ListNode* A) {
// write code here
//快慢指针找到一半,然后前后比较
struct ListNode* mid=middleNode(A);
struct ListNode* rmid=reverseList(mid);
struct ListNode* cur=A;
while(cur&&rmid)//奇数个和偶数个都要考虑到
{
if(cur->val!=rmid->val)
return false;
cur=cur->next;
rmid=rmid->next;
}
return true;
}
};链表中倒数第k个节点
1、题目描述
牛客:(链表中倒数第k个节点)
输入一个链表,输出该链表中倒数第k个结点。
输入:1,{1,2,3,4,5}
返回值:{5}
如果掌握了快慢指针的精髓,那么这道题目对于大家来说是非常轻而易举的,因为这道题目让找到倒数第k个节点,这个节点和最后一个节点相差的不就是k,所以慢指针和快指针相差k,而快指针走到尾不就行了?不过这道题目还有很多细节的地方需要讲述。
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
struct ListNode* fast=pListHead;
struct ListNode* slow=pListHead;
if(fast==NULL)
return NULL;
while(k--)
{
fast=fast->next;
if(k>0&&fast==NULL)
return NULL;
}
while(fast)
{
slow=slow->next;
fast=fast->next;
}
return slow;
}这段代码是可以跑过去的,不过可读性比较差,还可以优化。
主要问题是在这两处:
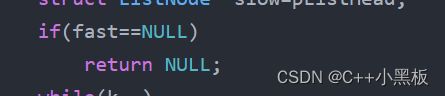
这处代码主要考虑有可能为NULL的问题。
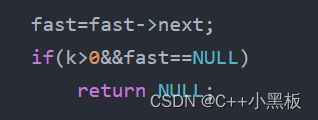
这段代码为什么说它可读性差呢?主要就是k>0这部分让人摸不着头脑。为什么会这样写呢?这也是为了解决一些特殊情况:
如果k是恰好为这个链表的总长度,那么倒数第k个节点势必是第一个节点,但是这时fast已经指向NULL,为了则会返回NULL,这显然是错误的,但是这句代码是为了解决k大于整个链表长度时倒数第k个节点为NULL的情况,显然不能删,只好更改为这样,有没有更好的解决办法?答案肯定是有的:
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k )
{
// write code here
//快慢指针
//找倒数第四个
struct ListNode* fast=pListHead;
struct ListNode* slow=pListHead;
if(pListHead)
{
while(k--)
{
if(fast==NULL)
return NULL;
fast=fast->next;
}
while(fast)
{
fast=fast->next;
slow=slow->next;
}
}
return slow;
}
这样处理对代码进行了进一步的优化。
相交链表
1、题目描述
leetcode:(160.相交链表)
给你两个单链表的头节点
headA和headB,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回null。
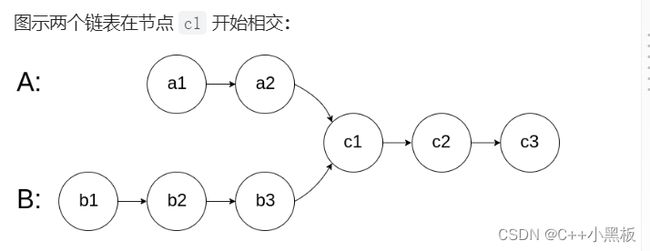
注意由于单链表的next只能指向一个位置,所以链表的相交不可能是像两条直线相交后再无交点,而是相交后之后便一模一样了。
这道题目并不难,遍历两个链表,第一步判断:如果最后地址不相同,那么必然不是相交链表。分别计算两个链表的长度,长链表走他们的差值后再一块走,必然有一个节点地址相同。不过这道题目还是有一点技巧,如果处理一下会简化不少。
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode* curA=headA;
struct ListNode* curB=headB;
int lengthA=1,lengthB=1;
//因为是找尾结点,所以设初始值为1
while(curA->next)
{
curA=curA->next;
lengthA++;
}
while(curB->next)
{
curB=curB->next;
lengthB++;
}
//尾结点不同,必定不是相交链表
if(curA!=curB)
{
return NULL;
}
//假设法可以节省不少
struct ListNode* longlist=headA;
struct ListNode* shortlist=headB;
if(lengthAnext;
}
while(longlist!=shortlist)
{
longlist=longlist->next;
shortlist=shortlist->next;
}
return longlist;
} 移除链表元素
1、题目描述
leetcode:203.移除链表元素
给你一个链表的头节点
head和一个整数val,请你删除链表中所有满足Node.val == val的节点,并返回 新的头节点 。
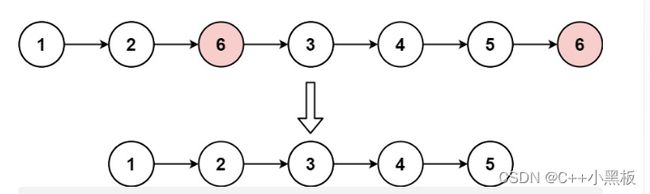
这道题目比较简单,遍历一遍链表,符合条件的拿下来,不符合条件的删除。不过需要处理一些特殊情况,比如说空指针的问题,还有如果头符合条件,那么删除头,重设头的问题。
2、解:
struct ListNode* removeElements(struct ListNode* head, int val)
{
struct ListNode* prev=NULL;
struct ListNode* cur=head;
struct ListNode* del=NULL;
//如果第一个是符合条件的就会出现问题
if(cur==NULL)
{
return NULL;
}
while(cur)
{
if(cur->val!=val)
{
prev=cur;
cur=cur->next;
}
else
{
if(cur==head)
{
del=cur;
head=head->next;
cur=head;
free(del);
del=NULL;
}
else
{
del=cur;
cur=cur->next;
prev->next=cur;
free(del);
del=NULL;
}
}
}
return head;
}链表分割
1、题目描述
牛客:链表分割
现有一链表的头指针 ListNode* pHead,给一定值x,编写一段代码将所有小于x的结点排在其余结点之前,且不能改变原来的数据顺序,返回重新排列后的链表的头指针。
但看这句描述比较抽象,真正的意思是,把一个链表中小于x值的排在x前面,而不改变这些数据的相对顺序,剩下大于等于的按照相对顺序排好。
比如说:

我们的一个简便思路就是:设立两个哨兵位,(设立哨兵位是为了方便找头节点),把小于x的连接在一个哨兵位后面,大于等于x的链接在另一个哨兵位后面,最后再把链接大的数的链表尾插在小的后面就完成了。
2、解:
class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
// write code here
struct ListNode* lessguard=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* greaterguard=(struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* cur=pHead;
lessguard->next=greaterguard->next=NULL;
struct ListNode* cur1=lessguard;
struct ListNode* cur2=greaterguard;
while(cur)
{
if(cur->valnext=cur;
cur1=cur1->next;
}
else
{
cur2->next=cur;
cur2=cur2->next;
}
cur=cur->next;
}
//这点非常重要
cur2->next=NULL;
cur2=greaterguard->next;
while(cur2)
{
cur1->next=cur2;
cur2=cur2->next;
cur1=cur1->next;
}
pHead=lessguard->next;
free(lessguard);
free(greaterguard);
return pHead;
}
}; 如果仅仅写到我所说的地步就可以跑过去它就不是难题了,这里需要十分注意的一个点是:
为什么说这句十分重要,因为第一个链表的尾结点的next是要链接的,所以不需要设为NULL,而第二个链表的尾结点的next可能不是next,这就会导致代码出错,所以这是一个细节。

环形链表Ⅱ
1、题目描述
leetcode:142.环形链表Ⅱ
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
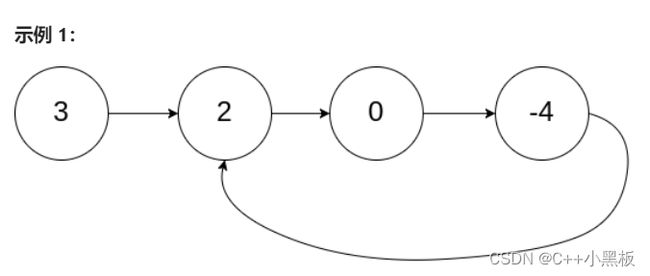
这道题目看着挺长,实际目的就是:判断一个链表是不是环,以及如果是环,那么找到环的入口。
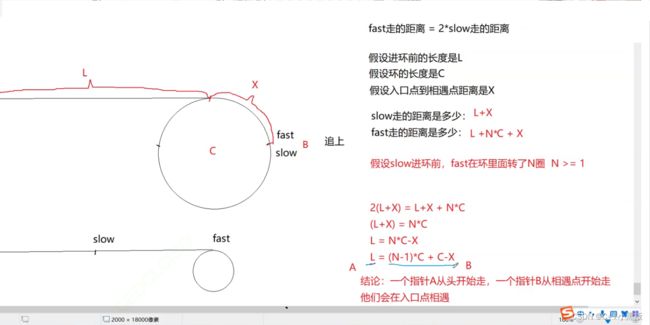
1、解决是否为环:
哈哈,首先我们需要解决这个链表是不是环的问题,这个比较简单,我在本期多次使用了快慢指针的方式来解决,这道题目恰好可以使用快慢指针的方式来确定是否有环。如果有环,那么快指针和慢指针必定在某处会地址相同。为什么呢?在慢指针进入环之前,快指针和慢指针必定不会相交,进环之后,快指针和慢指针相差N个位置,而每次快指针比慢指针多移动一步,所以必定在某个位置快慢指针会地址相同。
2、怎么找到入环点
不妨这样假设,假如我把相遇点做个截断,(当然原题目要求不能破坏链表,所以最后还要复原链表),如果把相遇点的next设为NULL,那么就可以转换成从相遇点和起始点出发找相交点,即相交链表的问题,这个之前我们解答过了,可以直接拿来用。
解一:
struct ListNode* getintersectionnode(struct ListNode* next,struct ListNode* head)
{
struct ListNode* headA=next,*headB=head;
if(headA==NULL||headB==NULL)
return NULL;
int lenA=1,lenB=1;
while(headA->next)
{
headA=headA->next;
++lenA;
}
while(headB->next)
{
headB=headB->next;
++lenB;
}
if(headA!=headB)
return NULL;
struct ListNode* longer=next,*shorter=head;
if(lenAnext;
}
while(longer!=shorter)
{
longer=longer->next;
shorter=shorter->next;
}
return longer;
}
struct ListNode *detectCycle(struct ListNode *head)
{
struct ListNode* slow=head,*fast=head;
while(fast&&fast->next)
{
slow=slow->next;
fast=fast->next->next;
if(slow==fast)
{
struct ListNode* meet=slow;
struct ListNode* next=meet->next;
meet->next=NULL;//断开,如果检测,可以使用后再改回去
struct ListNode* entryNode=getintersectionnode(next,head);
meet->next=next;
return entryNode;
}
}
return NULL;
}
解二:
上面这种方式已经算是比较优秀的解答了,那么这第二种方式更加奇妙,它是一个数学推理出来的关系。
struct ListNode* meetNode(struct ListNode* head)
{
struct ListNode* fast=head;
struct ListNode* slow=head;
while(fast&&fast->next)
{
fast=fast->next->next;
slow=slow->next;
if(fast==slow)
{
return fast;
}
}
return NULL;
}
struct ListNode *detectCycle(struct ListNode *head)
{
struct ListNode* meet=meetNode(head);
if(meet)
{
struct ListNode* cur=head;
while(cur!=meet)
{
cur=cur->next;
meet=meet->next;
}
}
return meet;
}
复制带随机指针的链表
1、题目描述
leetcode:138.复制带随机指针的链表
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码只接受原链表的头节点 head 作为传入参数。
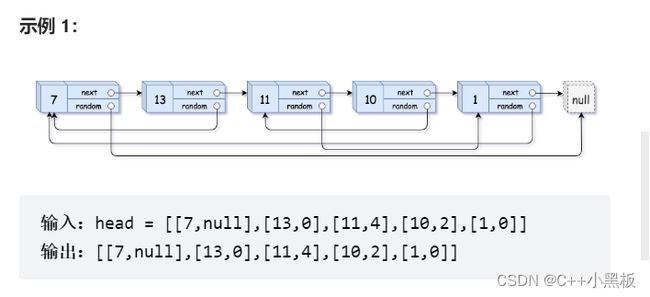
这道题是比较难的题目了,题干就比较吓人,它的意思我给总结一下:
拷贝一个链表,使得它的值和原链表相同,random指针所指向的在链表中的位置和原链表中所指向的在链表中的位置相同。是一个链表的深拷贝。
如果这道题目仅仅是拷贝数值,那么是非常容易的,但是比较麻烦的是random的拷贝,因为他要考虑在链表中的位置,那么可能有人提出通过random所指向的指针,通过它的值来查找,这种方式实际是行不通的,如果一个链表中每个节点所存储的值都不相同还好,如果有两个甚至多个值相同的话,那么很显然会出错,因为值相同的话random不知道去查找哪个。
记住,在解决链表中的问题时我们要充分利用链表的性质!!我们假想,如果通过一个节点的random指针可以找到拷贝的random所指向的位置该多好,事实上,我们利用链表next的性质是可以实现的,我们不妨把它插在random所指向的指针的后面。
图解:
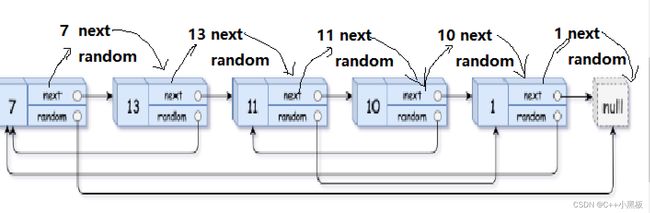
我们可以这样链接,再把拷贝的链接起来,最后再把原链表恢复即可。
struct Node* BuyNewNode(struct Node* cur)
{
struct Node* pioneer=(struct Node*)malloc(sizeof(struct Node));
pioneer->val=cur->val;
pioneer->next=cur->next;
//如果不是空
pioneer->random=NULL;
return pioneer;
}
struct Node* copyRandomList(struct Node* head)
{
struct Node* cur=head;
struct Node* next=NULL;
struct Node* guard=(struct Node*)malloc(sizeof(struct Node));
guard->next=NULL;
guard->random=NULL;
//遍历
while(cur)
{
next=cur->next;
struct Node* pioneer=BuyNewNode(cur);
cur->next=pioneer;
cur=next;
}
cur=head;
struct Node* tail=guard;
struct Node* copy=NULL;
while(cur)
{
copy=cur->next;
next=copy->next;
if(cur->random)
{
copy->random=cur->random->next;
}
else
{
copy->random=NULL;
}
cur=next;
}
cur=head;
while(cur)
{
copy=cur->next;
next=copy->next;
tail->next=copy;
tail=tail->next;
cur->next=next;
cur=next;
}
struct Node* newhead=guard->next;
free(guard);
return newhead;
}