Whisper与ChatGPT联手,轻松实现音频转录文本
目录
前言
一、Whisper简介
二、Whisper可用的模型和语言
三、开源 Whisper 本地转录
3.1、安装pytube库
3.2、下载音频MP4文件
3.3、安装 Whisper 库
四、在线 Whisper API 转录
4.1、Whisper API 接口调用
4.2、使用Prompt参数优化
4.3、其它参数介绍
4.4、转录过程翻译功能
4.5、分割音频处理大文件
4.6、基于ChatGPT对内容进行总结
五、总结
六、资源推荐
前言
前一阵给大家介绍的主题更多的集中在AI编程和LLMs的一些应用实战方面,ChatGPT我们都知道最强大的还是它底层应用的文本语言模型GPT系列,原来我们对于机器学习、深度学习领域想要实现一些相对智能化的小功能,不管是学习成本、人力成本都很大,而且对没有AI方面的经验和数据基础一般门槛都会比较高,现在我们通过GPT来实现这方面的需求相对来说就非常简单了,而且达到的效果也会更好。
今天我们来进入一个新的主题,那就是语音识别,虽然ChatGPT功能很强大,但只能接受文本输入,IOS版本虽然提供了语音输入功能,但因为种种限制,没条件的人很难享受到。 而在现实生活中,我们其实有很多场景下都不方便停下来打字,很多内容比如像YouTube视频、播客音频也没有文字版,所以这个时候,我们就需要一个能够将语音内容转换成文本的能力。
作为目前 AI 界的领导者,OpenAI 自然也不会放过这个需求。他们不仅发表了一个通用的语音识别模型 Whisper,还把对应的代码开源了。在今年的 1 月份,他们也在 API 里提供了对应的语音识别服务。那么今天,我们就一起来看看 Whisper 这个语音识别的模型可以怎么用。
一、Whisper简介
Whisper 是 OpenAI 的一种自动最先进的语音识别系统,它已经接受了 680,000 小时从网络收集的多语言和多任务监督数据的训练。这个庞大而多样化的数据集提高了对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。与 DALLE-2 和 GPT-3 不同,Whisper 是一种免费的开源模型。OpenAI 发布了模型和代码,作为构建利用语音识别的有用应用程序的基础。
Whisper的优势是开源免费、支持多语种(包括中文),根据不同的场景需求有不同模型可供选择,最终的效果比市面上很多音频转文字的效果都要好。
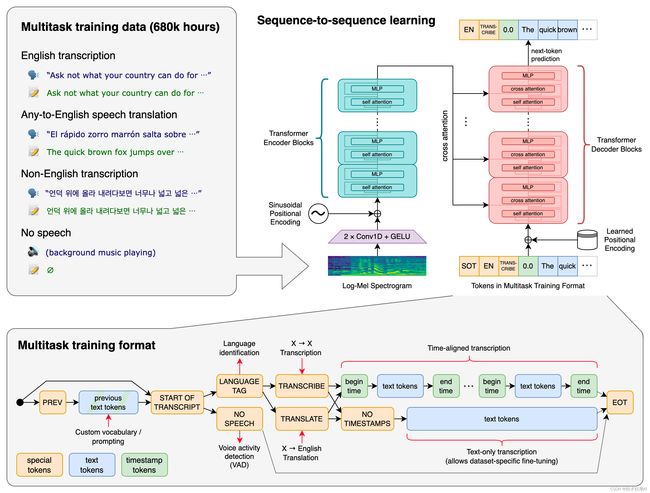
Transformer 序列到序列模型针对各种语音处理任务进行训练,包括多语言语音识别、语音翻译、口语识别和语音活动检测。这些任务共同表示为由解码器预测的一系列标记,允许单个模型取代传统语音处理管道的多个阶段。多任务训练格式使用一组特殊标记作为任务说明符或分类目标。
二、Whisper可用的模型和语言
Whisper提供了五种型号尺寸,其中四种为纯英文版本,提供速度和准确性的权衡。以下是可用型号的名称及其大致的内存要求和相对速度。
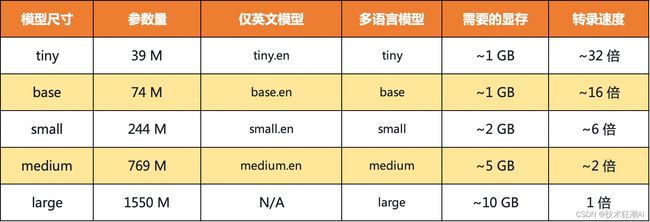 纯英语应用程序的模型往往性能更好,尤其是对于
纯英语应用程序的模型往往性能更好,尤其是对于 tiny.en 和 base.en 模型。我们观察到 small.en 和 medium.en 模型的差异变得不那么明显。
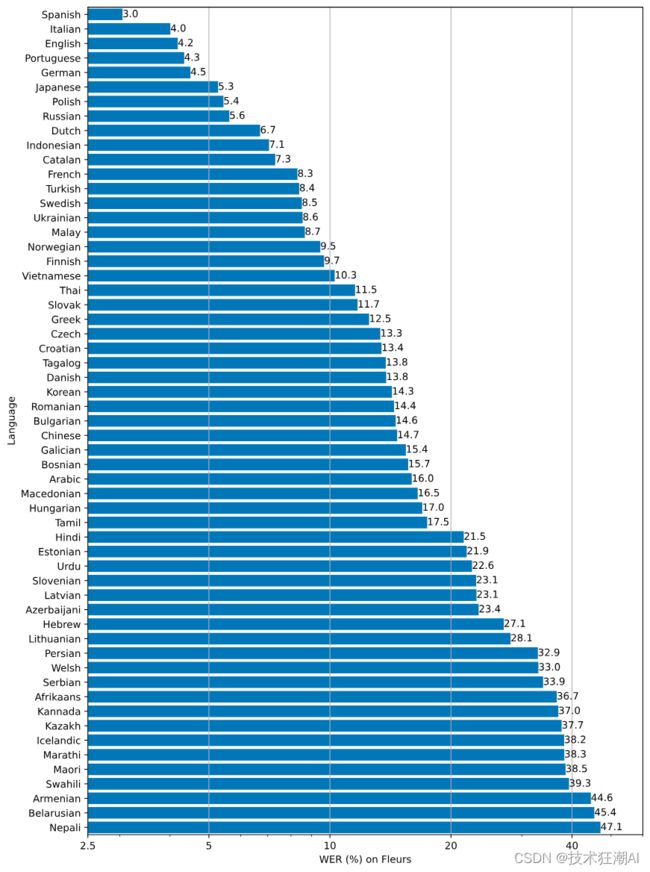
Whisper 的性能因语言而异。下图显示了使用该模型的 Fleurs 数据集按语言的 WER(单词错误率)细分large-v2(数字越小,性能越好)。
 这里需要注意一下,Whisper 的模型和其他开源模型不太一样,它有好几种不同尺寸。你可以通过 load_model 里面的参数来决定加载什么模型。这里我们选用的是最大的 large 模型,它大约需要 10GB 的显存。因为 Colab 提供的 GPU 是英伟达的 T4,有 16G 显存,所以是完全够用的。
这里需要注意一下,Whisper 的模型和其他开源模型不太一样,它有好几种不同尺寸。你可以通过 load_model 里面的参数来决定加载什么模型。这里我们选用的是最大的 large 模型,它大约需要 10GB 的显存。因为 Colab 提供的 GPU 是英伟达的 T4,有 16G 显存,所以是完全够用的。
如果你是使用自己电脑上的显卡,显存没有那么大,你可以选用小一些的模型,比如 small 或者 base。如果你要转录的内容都是英语的,还可以直接使用 small.en 这样仅限于英语的模型。这种小的或者限制语言的模型,速度还更快。不过,如果是像我们这样转录中文为主,混杂了英文的内容,那么尽可能选取大一些的模型,转录的准确率才会比较高。
接下来我们介绍两种方式将音频转录为文件,一种通过OpenAI开源的Whisper模型;一种是直接调用OpenAI开放的Whisper API接口。
三、开源 Whisper 本地转录
这里以YouTube作为一个案例来介绍,思路都是相通的,大家完全可以根据自己的需求去实现自己的应用,比如B站、一些播客或者音频类的资料我们都可以基于这种思路通过Whisper结合ChatGPT来做符合自己的小应用。
3.1、安装pytube库
接下来我们将使用 Whisper 转录 YouTube 视频。我们将使用 Python 的“pytube”库将音频转换为MP4。文件,pytube repo:https://github.com/pytube/pytube。
首先,我们需要安装 Pytube 库。您可以通过在终端中运行以下命令来执行此操作:
!pip install --upgrade pytube
3.2、下载音频MP4文件
对于本教程,将使用“100 秒学习 Python”视频作为案例,视频地址为:https://www.youtube.com/watch?v=x7X9w_GIm1s。
接下来,我们需要导入 pytube,提供 YouTube 视频的链接,并将音频转换为MP4:
# 导入Pytube库
import pytube
#加载YouTube链接
video = "https://www.youtube.com/watch?v=x7X9w_GIm1s"
# 转换和下载为MP4文件
data = pytube.YouTube(video)
audio = data.streams.get_audio_only()
audio.download()
输出是一个名为当前目录中视频标题的文件。在我们的例子中,文件名为Python in 100 Seconds.mp4 ,下一步是将音频转换为文本。我们可以使用 whisper 在三行代码中完成此操作。首先,我们安装并导入 whisper。然后我们加载模型,最后我们转录音频文件。
3.3、安装 Whisper 库
!pip install git+https://github.com/openai/whisper.git -q
import whisper
加载模型。我们将使用“base”模型。
model = whisper.load_model("base")
text = model.transcribe("Python in 100 Seconds.mp4")
现在我们可以打印输出了。
#printing the transcribe
text['text']
输出结果
Python, a high-level, interpreted programming language famous for its zen-like code. It's arguably the most popular language in the world because it's easy to learn, yet practical for serious projects. In fact, you're watching this YouTube video in a Python web application right now. It was created by Kwiidovan Rossum and released in 1991, who named it after Monty Python's blind circus, which is why you'll sometimes find spam and eggs instead of food and bar in code samples. It's commonly used to build server-side applications, like web apps with the Django framework, and is the language of choice for big data analysis and machine learning. Many students choose Python to start learning to code because of its emphasis on readability as outlined by the zen of Python. Beautiful is better than ugly, while explicit is better than implicit. Python is very simple, but avoids the temptation to sprinkle in magic that causes ambiguity. Its code is often organized into notebooks, where individua可以直接访问Google Colab,Jupyter Notebook 的完整代码:https://github.com/Crossme0809/langchain-tutorials/blob/main/Whisper_Transcribe_TouTube_Video.ipynb
四、在线 Whisper API 转录
4.1、Whisper API 接口调用
OpenAI 提供的 Whisper 的 API 非常简单,你只要调用一下 transcribe 函数,就能将音频文件转录成文字。
import openai, os
os.environ['OPENAI_API_KEY'] = "your-openai-api-key"
openai.api_key = os.getenv("OPENAI_API_KEY")
audio_file= open("./data/generative_ai_topics_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file)
print(transcript['text'])
输出结果:
欢迎来到 Onboard 真实的一线经验 走新的投资思考 我是 Monica 我是高宁 我们一起聊聊软件如何改变世界 大家好 欢迎来到 Onboard 我是 Monica 自从OpenAI发布的ChatGBT 掀起了席卷世界的AI热潮 不到三个月就积累了 超过一亿的越货用户 超过1300万的日货用户 真的是展现了AI让人惊讶的 也让很多人直呼 这就是下一个互联网的未来 有不少观众都说 希望我们再做一期AI的讨论 于是这次硬核讨论就来了 这次我们请来了 Google Brain的研究员雪芝 她是Google大语言模型PALM Pathway Language Model的作者之一 要知道这个模型的参数量 是GPT-3的三倍还多 另外还有两位AI产品大牛 一位来自著名的StableDM 背后的商业公司Stability AI 另一位来自某硅谷科技大厂 也曾在吴恩达教授的Landing AI中 担任产品负责人 此外 莫妮凯还邀请到一位 一直关注AI的投资人朋友Bill 当做我的特邀共同主持嘉宾 我们主要讨论几个话题 一方面从研究的视角 最前沿的研究者在关注什么 现在技术的天花板 和未来大的变量可能会在哪里 第二个问题是 未来大的变量可能会在哪里 从产品和商业的角度 什么是一个好的AI产品 整个生态可能随着技术 有怎样的演变 更重要的 我们又能从上一波 AI的创业热潮中学到什么 最后 莫妮凯和Bill还会从投资人的视角 做一个回顾 总结和畅想 这里还有一个小的update 在本集发布的时候 Google也对爆发式增长的 Chad GPT做出了回应 正在测试一个基于Lambda 模型的聊天机器人 ApprenticeBot 正式发布后会有怎样的惊喜 我们都拭目以待 AI无疑是未来几年 最令人兴奋的变量之一 莫妮凯也希望未来能邀请到更多 一线从业者 从不同角度讨论这个话题 不论是想要做创业 研究 产品 还是投资的同学 希望这些对话 对于大家了解这些技术演进 商业的可能 甚至未来对于我们每个人 每个社会意味着什么 都能引发一些思考 提供一些启发 这次的讨论有些技术硬核 需要各位对生成式AI 大模型都有一些基础了解 讨论中涉及到的论文和重要概念 也会总结在本集的简介中 供大家复习参考 几位嘉宾在北美工作生活多年 夹杂英文在所难免 也请大家体谅了 欢迎来到未来 希望大家enjoy
4.2、使用Prompt参数优化
从转录的结果来看,语音识别的转录效果非常好。我们看到尽管音频文件里面混杂着中英文,但是 Whisper 还是很好地识别出来了。不幸的是,转录出来的内容只有空格的分隔符,没有标点符号。
这个问题比较好解决,我们可以在前面的代码里面,增加一个 Prompt 参数就好了。
audio_file= open("./data/generative_ai_topics_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,
prompt="这是一段中文播客内容。")
print(transcript['text'])
输出结果:
欢迎来到 Onboard,真实的一线经验,走新的投资思考。 我是 Monica。 我是高宁。我们一起聊聊软件如何改变世界。 大家好,欢迎来到 Onboard,我是 Monica。 自从 OpenAI 发布的 ChatGBT 掀起了席卷世界的 AI 热潮, 不到三个月就积累了超过一亿的越活用户,超过一千三百万的日活用户。 真的是展现了 AI 让人惊叹的能力, 也让很多人直呼这就是下一个互联网的未来。 有不少观众都说希望我们再做一期 AI 的讨论, 于是这次硬核讨论就来了。 这次我们请来了 Google Brain 的研究员雪芝, 她是 Google 大语言模型 PAMP,Pathway Language Model 的作者之一。 要知道,这个模型的参数量是 GPT-3 的三倍还多。 另外还有两位 AI 产品大牛,一位来自著名的 Stable Diffusion 背后的商业公司 Stability AI, 另一位来自某硅谷科技大厂,也曾在吴恩达教授的 Landing AI 中担任产品负责人。 此外,Monica 还邀请到一位一直关注 AI 的投资人朋友 Bill 当作我的特邀共同主持嘉宾。 我们主要讨论几个话题,一方面从研究的视角,最前沿的研究者在关注什么? 现在技术的天花板和未来大的变量可能会在哪里? 从产品和商业的角度,什么是一个好的 AI 产品? 整个生态可能随着技术有怎样的演变? 更重要的,我们又能从上一波 AI 的创业热潮中学到什么? 最后,Monica 和 Bill 还会从投资人的视角做一个回顾、总结和畅想。 这里还有一个小的 update,在本集发布的时候, Google 也对爆发式增长的ChatGPT 做出了回应, 正在测试一个基于 Lambda 模型的聊天机器人 ApprenticeBot。 正式发布后会有怎样的惊喜?我们都拭目以待。 AI 无疑是未来几年最令人兴奋的变量之一, Monica 也希望未来能邀请到更多一线从业者从不同角度讨论这个话题。 不论是想要做创业、研究、产品还是投资的同学, 希望这些对话对于大家了解这些技术演进、商业的可能, 甚至未来对于我们每个人、每个社会意味着什么, 都能引发一些思考,提供一些启发。 这次的讨论有些技术硬核,需要各位对生成式 AI 大模型都有一些基础了解。 讨论中涉及到的论文和重要概念,也会总结在本集的简介中,供大家复习参考。 几位嘉宾在北美工作生活多年,夹杂英文在所难免,也请大家体谅了。 欢迎来到未来,大家 enjoy!
我们将在 transcribe 函数被调用时传入一个提示语 Prompt,里面包含一句引导 Whisper 模型的中文说明。在这个例子中,我们的 Prompt 使用了中文介绍和标点符号,你会发现 transcribe 函数转录出来的内容也带上了正确的标点符号。
然而,转录出来的内容还有一些小问题。那就是中英文混排的内容里面,英文前后会多出一些空格。为了解决这个问题,我们可以再修改一下 prompt,在提示语里面也使用中英文混排并且不留空格。
audio_file= open("./data/generative_ai_topics_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,
prompt="这是一段Onboard播客的内容。")
print(transcript['text'])
输出结果:
欢迎来到Onboard,真实的一线经验,走新的投资思考。 我是Monica,我是高宁,我们一起聊聊软件如何改变世界。 大家好,欢迎来到Onboard,我是Monica。 自从OpenAI发布的ChatGBT掀起了席卷世界的AI热潮, 不到三个月就积累了超过一亿的越活用户,超过1300万的日活用户。 真的是展现了AI让人惊叹的能力,也让很多人直呼这就是下一个互联网的未来。 有不少观众都说希望我们再做一期AI的讨论,于是这次硬核讨论就来了。 这次我们请来了Google Brain的研究员雪芝, 她是Google大语言模型POM,Pathway Language Model的作者之一。 要知道这个模型的参数量是GPT-3的三倍还多。 另外还有两位AI产品大牛,一位来自著名的Stable Diffusion背后的商业公司Stability AI, 另一位来自某硅谷科技大厂,也曾在吴恩达教授的Landing AI中担任产品负责人。 此外,Monica还邀请到一位一直关注AI的投资人朋友Bill,当做我的特邀共同主持嘉宾。 我们主要讨论几个话题,一方面从研究的视角,最前沿的研究者在关注什么? 现在的技术的天花板和未来大的变量可能会在哪里? 从产品和商业的角度,什么是一个好的AI产品? 整个生态可能随着技术有怎样的演变? 更重要的,我们又能从上一波AI的创业热潮中学到什么? 最后,Monica和Bill还会从投资人的视角做一个回顾、总结和畅想。 这里还有一个小的update,在本集发布的时候, Google也对爆发式增长的ChatGPT做出了回应, 正在测试一个基于Lambda模型的聊天机器人ApprenticeBot。 正式发布后会有怎样的惊喜?我们都拭目以待。 AI无疑是未来几年最令人兴奋的变量之一, Monica也希望未来能邀请到更多一线从业者从不同角度讨论这个话题。 不论是想要做创业、研究、产品还是投资的同学, 希望这些对话对于大家了解这些技术演进、商业的可能, 甚至未来对于我们每个人、每个社会意味着什么, 都能引发一些思考,提供一些启发。 这次的讨论有些技术硬核,需要各位对生成式AI、大模型都有一些基础了解。 讨论中涉及到的论文和重要概念,也会总结在本集的简介中,供大家复习参考。 几位嘉宾在北美工作生活多年,夹杂英文在所难免,也请大家体谅了。 欢迎来到未来,大家enjoy!
可以看到,在音频内容的转录之前提供一段提示,来引导模型更好地进行语音识别,是Whisper模型的一大优点。
如果您认为音频中可能会出现很多专有名词,导致模型容易出错,您可以在提示中加入相应的专有名词。例如,在上面的内容转录中,模型将ChatGPT听错了,变成了ChatGBT。Google的PALM模型也将其听错了,听成了POM。对应的全称Pathways Language Model也少了一个s。针对这些错误,我们只需要再修改一下提示,就能够得到正确的转录结果。
audio_file= open("./data/generative_ai_topics_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,
prompt="这是一段Onboard播客,里面会聊到ChatGPT以及PALM这个大语言模型。这个模型也叫做Pathways Language Model。")
print(transcript['text'])
输出结果:
欢迎来到Onboard,真实的一线经验,走新的投资思考。我是Monica。 我是高宁。我们一起聊聊软件如何改变世界。 大家好,欢迎来到Onboard,我是Monica。 自从OpenAI发布的ChatGPT掀起了席卷世界的AI热潮,不到三个月就积累了超过一亿的越活用户,超过1300万的日活用户。 真的是展现了AI让人惊叹的能力,也让很多人直呼这就是下一个互联网的未来。 有不少观众都说希望我们再做一期AI的讨论,于是这次硬核讨论就来了。 这次我们请来了Google Brain的研究员雪芝,她是Google大语言模型PALM Pathways Language Model的作者之一。 要知道,这个模型的参数量是GPT-3的三倍还多。 另外还有两位AI产品大牛,一位来自著名的Stable Diffusion背后的商业公司Stability AI, 另一位来自某硅谷科技大厂,也曾在吴恩达教授的Landing AI中担任产品负责人。 此外,Monica还邀请到一位一直关注AI的投资人朋友Bill当作我的特邀共同主持嘉宾。 我们主要讨论几个话题,一方面从研究的视角,最前沿的研究者在关注什么? 现在的技术的天花板和未来大的变量可能会在哪里? 从产品和商业的角度,什么是一个好的AI产品? 整个生态可能随着技术有怎样的演变? 更重要的,我们又能从上一波AI的创业热潮中学到什么? 最后,Monica和Bill还会从投资人的视角做一个回顾、总结和畅想。 这里还有一个小的update,在本集发布的时候,Google也对爆发式增长的Chat GPT做出了回应。 正在测试一个基于Lambda模型的聊天机器人ApprenticeBot。 证实发布后会有怎样的惊喜,我们都拭目以待。 AI无疑是未来几年最令人兴奋的变量之一。 Monica也希望未来能邀请到更多一线从业者从不同角度讨论这个话题。 不论是想要做创业、研究、产品还是投资的同学, 希望这些对话对于大家了解这些技术演进、商业的可能,甚至未来对于我们每个人、每个社会意味着什么都能引发一些思考,提供一些启发。 这次的讨论有些技术硬核,需要各位对生成式AI大模型都有一些基础了解。 讨论中涉及到的论文和重要概念也会总结在本集的简介中,供大家复习参考。 几位嘉宾在北美工作生活多年,夹杂英文在所难免,也请大家体谅了。 欢迎来到未来,大家enjoy!
出现这种现象的原因主要与Whisper模型的原理有关。它与GPT类似,会使用之前转录出的文本来预测下一帧音频的内容。通过在最前面加上文本提示,可以影响后面识别出来的内容的概率,从而起到纠正专有名词的作用。
4.3、其它参数介绍
除了模型名称、音频文件和 Prompt 之外,transcribe 接口还支持以下三个参数,可以尝试着自己修改一下,看看效果会有什么变化。
-
response_format,也就是返回的文件格式,我们这里是默认值,也就是 JSON。实际你还可以选择 TEXT 这样的纯文本,或者 SRT 和 VTT 这样的音频字幕格式。这两个格式里面,除了文本内容,还会有对应的时间信息,方便你给视频和音频做字幕。你可以直接试着运行一下看看效果。
-
temperature,这个和我们之前在 ChatGPT 类型模型里的参数含义类似,就是采样下一帧的时候,如何调整概率分布。这里的参数范围是 0-1 之间。
-
language,就是音频的语言。提前给模型指定音频的语言,有助于提升模型识别的准确率和速度。
audio_file= open("./data/generative_ai_topics_clip.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file, response_format="srt",
prompt="这是一段Onboard播客,里面会聊到PALM这个大语言模型。这个模型也叫做Pathways Language Model。")
print(transcript)
输出结果:
1
00:00:01,000 --> 00:00:07,000
欢迎来到Onboard,真实的一线经验,走新的投资思考。我是Monica。
2
00:00:07,000 --> 00:00:11,000
我是高宁。我们一起聊聊软件如何改变世界。
3
00:00:15,000 --> 00:00:17,000
大家好,欢迎来到Onboard,我是Monica。
4
00:00:17,000 --> 00:00:28,000
自从OpenAI发布的ChatGBT掀起了席卷世界的AI热潮,不到三个月就积累了超过一亿的越活用户,超过1300万的日活用户。
5
00:00:28,000 --> 00:00:34,000
真的是展现了AI让人惊叹的能力,也让很多人直呼这就是下一个互联网的未来。
6
00:00:34,000 --> 00:00:41,000
有不少观众都说希望我们再做一期AI的讨论,于是这次硬核讨论就来了。
7
00:00:41,000 --> 00:00:49,000
这次我们请来了Google Brain的研究员雪芝,她是Google大语言模型PALM Pathways Language Model的作者之一。
8
00:00:49,000 --> 00:00:53,000
要知道,这个模型的参数量是GPT-3的三倍还多。
9
00:00:53,000 --> 00:01:01,000
另外还有两位AI产品大牛,一位来自著名的Stable Diffusion背后的商业公司Surbility AI,
10
00:01:01,000 --> 00:01:08,000
另一位来自某硅谷科技大厂,也曾在吴恩达教授的Landing AI中担任产品负责人。
11
00:01:08,000 --> 00:01:15,000
此外,Monica还邀请到一位一直关注AI的投资人朋友Bill当作我的特邀共同主持嘉宾。
12
00:01:15,000 --> 00:01:22,000
我们主要讨论几个话题,一方面从研究的视角,最前沿的研究者在关注什么?
13
00:01:22,000 --> 00:01:26,000
现在的技术的天花板和未来大的变量可能会在哪里?
14
00:01:26,000 --> 00:01:30,000
从产品和商业的角度,什么是一个好的AI产品?
15
00:01:30,000 --> 00:01:33,000
整个生态可能随着技术有怎样的演变?
16
00:01:33,000 --> 00:01:38,000
更重要的,我们又能从上一波AI的创业热潮中学到什么?
17
00:01:38,000 --> 00:01:44,000
最后,Monica和Bill还会从投资人的视角做一个回顾、总结和畅想。
18
00:01:44,000 --> 00:01:51,000
这里还有一个小的update,在本集发布的时候,Google也对爆发式增长的Chat GPT做出了回应。
19
00:01:51,000 --> 00:01:56,000
正在测试一个基于Lambda模型的聊天机器人ApprenticeBot。
20
00:01:56,000 --> 00:02:00,000
证实发布后会有怎样的惊喜,我们都拭目以待。
21
00:02:00,000 --> 00:02:04,000
AI无疑是未来几年最令人兴奋的变量之一。
22
00:02:04,000 --> 00:02:10,000
Monica也希望未来能邀请到更多一线从业者从不同角度讨论这个话题。
23
00:02:10,000 --> 00:02:15,000
不论是想要做创业、研究、产品还是投资的同学,
24
00:02:15,000 --> 00:02:27,000
希望这些对话对于大家了解这些技术演进、商业的可能,甚至未来对于我们每个人、每个社会意味着什么都能引发一些思考,提供一些启发。
25
00:02:27,000 --> 00:02:34,000
这次的讨论有些技术硬核,需要各位对生成式AI大模型都有一些基础了解。
26
00:02:34,000 --> 00:02:41,000
讨论中涉及到的论文和重要概念也会总结在本集的简介中,供大家复习参考。
27
00:02:41,000 --> 00:02:47,000
几位嘉宾在北美工作生活多年,夹杂英文在所难免,也请大家体谅了。
28
00:02:47,000 --> 00:03:12,000
欢迎来到未来,大家enjoy!
4.4、转录过程翻译功能
除了基本的音频转录功能,Whisper的API还提供了一个名为“translation”的接口。该接口可以在转录音频的同时将语音翻译成英文。让我们来试一下。
audio_file= open("./data/generative_ai_topics_clip.mp3", "rb")
translated_prompt="""This is a podcast discussing ChatGPT and PaLM model.
The full name of PaLM is Pathways Language Model."""
transcript = openai.Audio.translate("whisper-1", audio_file,
prompt=translated_prompt)
print(transcript['text'])
输出结果:
Welcome to Onboard. Real first-line experience. New investment thinking. I am Monica. I am Gao Ning. Let's talk about how software can change the world. Hello everyone, welcome to Onboard. I am Monica. Since the release of ChatGPT by OpenAI, the world's AI has been in a frenzy. In less than three months, it has accumulated more than 100 million active users, and more than 13 million active users. It really shows the amazing ability of AI. It also makes many people say that this is the future of the next Internet. Many viewers said that they wanted us to do another AI discussion. So this discussion came. This time we invited a researcher from Google Brain, Xue Zhi. He is one of the authors of Google's large-scale model PaLM, Pathways Language Model. You should know that the number of parameters of this model is three times more than ChatGPT-3. In addition, there are two AI product big cows. One is from the famous company behind Stable Diffusion, Stability AI. The other is from a Silicon Valley technology factory. He was also the product manager in Professor Wu Wenda's Landing AI. In addition, Monica also invited a friend of AI who has been paying attention to AI, Bill, as my special guest host. We mainly discuss several topics. On the one hand, from the perspective of research, what are the most cutting-edge researchers paying attention to? Where are the cutting-edge technologies and the large variables of the future? From the perspective of products and business, what is a good AI product? What kind of evolution may the whole state follow? More importantly, what can we learn from the previous wave of AI entrepreneurship? Finally, Monica and Bill will also make a review, summary and reflection from the perspective of investors. Here is a small update. When this issue was released, Google also responded to the explosive growth of ChatGPT. We are testing an Apprentice Bot based on Lambda model. What kind of surprises will be released? We are looking forward to it. AI is undoubtedly one of the most exciting variables in the coming years. Monica also hopes to invite more first-line entrepreneurs to discuss this topic from different angles. Whether you want to do entrepreneurship, research, product or investment, I hope these conversations will help you understand the possibilities of these technical horizons and business. Even in the future, it can cause some thoughts and inspire us to think about what it means to each person and each society. This discussion is a bit technical, and requires you to have some basic understanding of the biometric AI model. The papers and important concepts involved in the discussion will also be summarized in this episode's summary, which is for your reference. You have worked in North America for many years, and you may have some English mistakes. Please understand. Welcome to the future. Enjoy. Let me give you a brief introduction. Some of your past experiences. A fun fact. Using an AI to represent the world is now palped.
这个接口只能将内容翻译成英文,无法翻译成其他语言。因此,相应的提示也必须使用英文。对我们来说,这可能有些遗憾。如果能够指定翻译的语言,我们就可以直接将许多英文播客转录成中文。现在,为了实现这一点,我们不得不再花费一些费用,让ChatGPT来帮助我们翻译。
4.5、分割音频处理大文件
刚才我们只是尝试转录了一个三分钟的音频片段,接下来我们将尝试转录整个音频。但是,由于OpenAI限制Whisper一次只能转录25MB大小的文件,因此我们需要将大的播客文件分割成小的片段,转录完后再将它们拼接起来。我们可以使用OpenAI在官方文档中提供的PyDub库来分割文件。
在分割之前,我们需要使用FFmpeg将从listennotes下载的MP4文件转换为MP3格式。如果您不了解FFmpeg或没有安装,也没有关系,ChatGPT已经为您编写了相应的命令。
ffmpeg -i ./data/generative_ai_topics_long.mp4 -vn -c:a libmp3lame -q:a 4 ./data/generative_ai_topics_long.mp3
分割MP3文件的代码也很简单,我们可以按照每15分钟一个片段的方式将音频切分。通过PyDub的AudioSegment包,我们可以将整个长的MP3文件加载到内存中,并将其转换为一个数组。数组中的每个元素都是1毫秒的音频数据,我们可以很容易地将数组按照时间切分成每15分钟一个片段的新MP3文件。
首先要确保安装了PyDub库。
%pip install -U pydub
具体实现文件分割的代码:
from pydub import AudioSegment
podcast = AudioSegment.from_mp3("./data/generative_ai_topics_long.mp3")
# PyDub handles time in milliseconds
ten_minutes = 15 * 60 * 1000
total_length = len(podcast)
start = 0
index = 0
while start < total_length:
end = start + ten_minutes
if end < total_length:
chunk = podcast[start:end]
else:
chunk = podcast[start:]
with open(f"./data/generative_ai_topics_{index}.mp3", "wb") as f:
chunk.export(f, format="mp3")
start = end
index += 1
在文件切分完成之后,就需要一个个地来转录对应的音频文件,具体实现代码如下。
prompt = "这是一段Onboard播客,里面会聊到ChatGPT以及PALM这个大语言模型。这个模型也叫做Pathways Language Model。"
for i in range(index):
clip = f"./data/generative_ai_topics_{i}.mp3"
audio_file= open(clip, "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file,
prompt=prompt)
# mkdir ./data/transcripts if not exists
if not os.path.exists("./data/transcripts"):
os.makedirs("./data/transcripts")
# write to file
with open(f"./data/transcripts/generative_ai_topics_{i}.txt", "w") as f:
f.write(transcript['text'])
# get last sentence of the transcript
sentences = transcript['text'].split("。")
prompt = sentences[-1]
在这里,我们对每次进行转录的Prompt做了一个小小的特殊处理。我们将前一个片段转录结果的最后一句话作为下一个转录片段的提示语。这样,我们可以让后面的片段在进行语音识别时知道前面最后说了什么。这样做可以减少错别字的出现。
4.6、基于ChatGPT对内容进行总结
上面我们通过Whisper API将音频文件转录为文本文件后,就可以结合ChatGPT对文本内容进行总结了。
首先确保安装了必要的库
%pip install llama-index==0.5.26
%pip install langchain
%pip install spacy
%run -m spacy download zh_core_web_sm
代码:
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import SpacyTextSplitter
from llama_index import GPTListIndex, LLMPredictor, ServiceContext, SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser
# define LLM
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo", max_tokens=1024))
text_splitter = SpacyTextSplitter(pipeline="zh_core_web_sm", chunk_size = 2048)
parser = SimpleNodeParser(text_splitter=text_splitter)
documents = SimpleDirectoryReader('./data/transcripts').load_data()
nodes = parser.get_nodes_from_documents(documents)
service_context = ServiceContext.from_defaults(llm_predictor=llm_predictor)
list_index = GPTListIndex(nodes=nodes, service_context=service_context)
response = list_index.query("请你用中文总结一下我们的播客内容:", response_mode="tree_summarize")
print(response)
输出结果:
播客讨论了AI的未来发展趋势、技术的天花板、好的AI产品应该具备的特点以及整个生态可能随着技术演变的变化。同时,回顾了上一波AI的创业热潮中的经验教训,并从投资人的视角做了一个回顾、总结和畅想。另外,还讨论了生成式AI大模型、Diffusion app在手机上的成功编译、AI和开源模型的应用、Google POM语言模型的介绍以及其与GPT-3的区别。最后,讨论了数据在微调任务中的重要性以及零样本、少样本和微调方法之间的差异。
可以直接访问Google Colab,Jupyter Notebook 的完整代码https://github.com/Crossme0809/langchain-tutorials/blob/main/WhisperAndChatGPTAPISummaryAudioTutorial.ipynb
其实,不管是用本地GPU跑Whisper的开源模型来转录还是采用OpenAI在线的Whisper API接口进行转录,基本上对于语音或者视频转文本来讲,我们是不是可以结合今天的案例写个爬虫自动抓取YouTube或者其他站点的内容,结合ChatGPT做一些总结分析,然后将结果推送给用户,如果从海量的信息里获取更有价值的内容,AI给我们创造了无限的空间。(一般一个小时左右的音频文件,转录并小结一期的成本也就在5元人民币左右。)
五、总结
OpenAI的Whisper模型非常简单易用,无论是通过API还是使用开源模型,只需要一行代码调用transcribe函数,就能将音频文件转录成对应的文本。
即使是多语言混杂的内容,它也能够转录得很好。通过传入一个Prompt,它不仅能够在整个文本中加上合适的标点符号,还能够根据Prompt中的专有名词,减少转录中这些内容的错误和遗漏。
虽然OpenAI的API接口限制了单个转录文件的大小,但是我们可以很方便地通过Python包如PyDub,将音频文件切分成多个小片段来解决这个问题。
对于转录后的结果,我们可以使用之前学习过的ChatGPT和llama-index来进行相应的文本小结。通过组合Whisper和ChatGPT,我们可以快速地将播客、Youtube访谈等内容转化为文本小结,以便我们快速浏览并判断是否有必要深入了解原始内容。
六、资源推荐
李沐老师的论文精读系列视频非常有价值,也有专门讲解过 OpenAI Whisper 的相关论文,如果你希望深入去研究Whisper的话,可以参考学习一下,另外他基于Whisper 的开源代码做了一个用来剪辑视频的小工具 AutoCut, 工具也非常实用。
OpenAI Whisper论文精读:https://www.bilibili.com/video/BV1VG4y1t74x/
如果你对这篇文章感兴趣,而且你想要学习更多关于AI领域的实战技巧,可以关注「技术狂潮AI」公众号。立即获取:
- 「ChatGPT超全资料汇总|总有一款是你需要的」
- 「最完整的ChatGPT提示工程(含PPT|Xmind|视频|代码)」
- 「最强ChatGPT工具集合|超1200+工具,58个分类」
您将找到丰富的资源和工具,帮助您深入了解和应用ChatGPT。