Python实战:分享4个提升Python编程技能的库
一、介绍
Python在数据科学和人工智能领域应该算是公认最常用的编程语言之一,同时也为程序员、数据科学家和数据分析师提供了非常丰富的库。就算我们使用Python已经有多年的经验,相信仍然会有很多隐藏的工具,会让你感到惊喜。
本文我们将分享四个比较实用的Python库,它们将助于提高你的技能水平。
二、自动提取日期和时间
当我们在处理非结构化文本数据时,希望能提取文本中的日期和时间,按常规的做法精确提取可能有一定的复杂度。然而如果使用 datefinder 库来实现将变得非常容易。顾名思义, datefinder 可用于从文本信息中查找并提取以不同格式编写的时间和日期。 要安装该库,请运行以下命令:
$ pip install datefinder
示例任务:
from datefinder import find_dates
text_data = """
I will meet the business team on August 1st, 2023 at 07 AM. The goal is
to discuss the budget planning for September, 20th 2023 at 10 AM
"""
all_dates = find_dates(text_data)
for match in all_dates:
print(f"Date and time: {match}")
print(f"Only Time: {match.strftime('%H:%M:%S')}")
print(f"Only Day: {match.strftime('%d')}")
print(f"Only Month: {match.strftime('%m')}")
print("--"*5)
以上代码中,find_dates 函数按以下格式返回所有日期和时间的列表: YYYY-MM-DD HH:MM:SS 其中:
-
YYYY是年份 -
MM是月份 -
DD是日期 -
HH是小时 -
MM代表分钟 -
SS对应两位数秒 以下是上述示例的输出:

三、让你的正则表达式具有人类可读性
人们可以轻松记住正则表达式(regex)中的元字符。然而,最困难的部分仍然是构建与给定文本中的复杂模式匹配的表达式。
如果我们能找到一种方法来构建更多人类可读的内容怎么办?
这就是 PRegEx 库派上用场的地方!
它的安装如下:
$ pip install pregex
示例任务: 让我们考虑以下文本数据,我们要在其中提取日期和 URL 信息。
text_data = """
I will meet the business team on the 01-08-2023 at 07 AM.
The meeting will be live on the company website at https://company.info.com/business/live
"""
这可以使用 PRegEx 解决,如下所示: 首先,我们导入相关模块,如下所述:
-
AnyButWhitespace匹配任何字符,但不匹配空格。 -
AnyDigit匹配 0 到 9 之间的任何数字。 -
OneOrMore至少匹配一个字符一次。 -
Either匹配给定模式之一。 -
Exactly匹配重复n次的字符的确切数量。
在 URL 模式中,特意添加了 .net 、 .fr 和 .org 等附加信息,以使模式更加通用。
from pregex.core.classes import AnyButWhitespace, AnyDigit
from pregex.core.quantifiers import OneOrMore, Exactly
from pregex.core.operators import Either
two_digits = Exactly(AnyDigit(), 2)
four_digits = Exactly(AnyDigit(), 4)
date_patter = (
two_digits +
"-" +
two_digits +
"-" +
four_digits
)
url_pattern = (
"https://"
+ OneOrMore(AnyButWhitespace())
+ Either(".com", ".fr", ".net", ".org")
+ OneOrMore(AnyButWhitespace())
)
dates_match = date_patter.get_matches(text_data)
url_match = url_pattern.get_matches(text_data)
print(f"All Dates: {dates_match}")
print(f"URL: {url_match}")
输出:

如果您必须使用 re 包,则整体模式将如下所示:
dates_pattern = r'\b\d{2}-\d{2}-\d{4}\b'
# Regular expression pattern for URL
url_pattern = r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'
我让你自己判断 PRegEx 和 re 之间的易用性!
正如您所看到的,使用 re 模块对于初学者来说根本不友好!
四、使用 IceCream 轻松进行代码调试
如果您使用 print or log 语句来调试 Python 代码,请举手 ✋。 当然可以,但是这并没有什么问题,这里有一个例子。
print(f"x: {x}")
print(f"y: {x}")
print(f"z: {x}")
输出:

这是一个非常好的输出,对吧? 使用 print 或 log 的缺点是,在处理较大的程序时可能会很耗时,特别是当您需要添加文本以获得更好的可读性时。
如果我告诉你有更好的选择怎么办? → 使用 IceCream 代替。它是一个 Python 库,使调试过程更容易、更具可读性。 要安装 IceCream 库,请运行以下命令:
$ pip install icecream
让我们尝试一下显示 x、y 和 z 的值。
from icecream import ic
x = 10
y = 20
z = 30
ic(x)
ic(x)
ic(x)
输出:

使用最少的代码,我们设法获得更具可读性的输出。
这是使用计算矩形面积的函数的另一个示例。
def compute_rectangle_area(length, width):
ic(length, width)
area = length * width
return area
ic(compute_rectangle_area(5, 6))
输出:

IceCream 通过提供函数名称、参数以及结果等详细信息,提供了更具可读性的结果!这不是很棒吗?
五、重新加载正在运行的代码而不丢失当前状态
想象一下,您已经运行了一个任务,并且忘记了打印或记录一些重要的变量。 在这种情况下,最终的解决方案是停止执行,更新代码,然后重新运行。 这有时可能会令人沮丧,尤其是在训练机器学习模型时,您意识到在上一个时期并未记录所有指标。 别再担心了, reloading 随时为您提供帮助! 顾名思义, reloading 是一个 Python 实用程序,可用于重新加载已经运行的代码而不中断其执行。这绝对会改变游戏规则!
通过运行以下命令完成安装:
$ pip install reloading
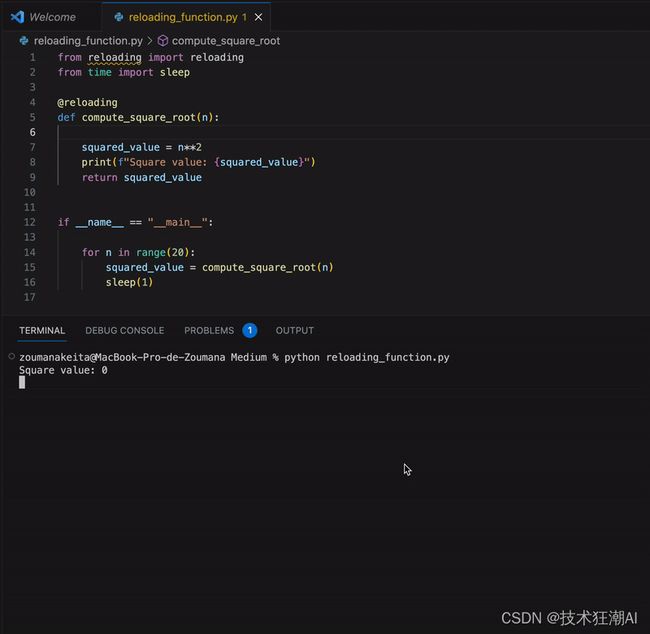
想象一下,您执行了以下 for ,其中您想要打印 i 的值及其平方根。 您可以简单地添加缺少的代码,而不是停止程序,如下面的动画所示: 在这种情况下,唯一需要的就是将迭代器包裹在 reloading 函数中。 进行更改后,从第 6 次迭代开始自动添加平方根的值。然后,在恢复初始状态后,打印语句也从第 16 次迭代开始进行了调整。

使用简单的 for 循环重新加载的插图(作者动画) 通过将函数与 @reloading 装饰器一起使用,可以将相同的逻辑应用于函数。 现在,让我们考虑以下 compute_square_root 函数,它实现了上述 for 循环的逻辑。 该函数首先打印 n 的平方根。运行代码后,将添加信息 for n: {n} 以打印 n 的值。
六、总结
你已经熟悉了一些最不为人知的 Python 库,用于日期和时间提取、模式匹配、代码调试以及在不丢失状态的情况下重新加载代码。