大数据--hive学习笔记
一、Hive简介
建立在Hadoop之上的数据仓库架构
hive的设计目标:可伸缩、可扩展、容错及输入格式松耦合!
- 一套方便的实施数据抽取(ETL)的工具。
- 一种让用户对数据描述其结构的机制。
- 支持用户对存储在Hadoop中的海量数据进行查询和分析的能力。
特性
- 使用HDFS作为数据存储
- 通过Map Reduce完成数据运算
- 提供类似SQL的语言(HQL)
- HQL灵活的可扩展性(UDF、UDAF、UDTF)
- 适合进行离线分析,具有海量数据处理能力
- 响应慢,不适合在线数据处理
二、Hive系统架构

-
元数据
描述Hive数据仓库系统参数,用户在Hive中存储数据的相关参数,类似于关系数据库的系统表。
-
Hive命令行
命令行窗口方式操作hive。类似于oralce的plsql,或者ssh窗口。执行HQL语句。
-
JDBC+Hive Server
通过JDBC方式连接Hive数据库,必须启动Hive Server。
-
Hive引擎(HQL编译、执行)
通过Hive命令行或者JDBC提交的HQL,通过Hive引擎的编译、优化后,转化为MR任务,提交到MR集群运行,然后接收MR的执行结果。
三、Hive数据存储
-
元数据存储(Metastore)
存储Hive数据仓库的各种参数,用户在Hive中存储数据的相关参数,类似于关系数据库的系统表。用关系数据库RDBMS(mysql、JDO、满足实时性)存储元数据。
元数据主要包括:数据库名、表名、表的列名、partitions、Bucket(桶)、及其属性。
-
数据模型
databases、tables、external tables、partitions、buckets(clusters)、view。
(1)、Database:
和关系数据库中的database概念类似。Hive的每个database,对应HDFS中相应的目录。
(2)、Table:
和关系数据库中的table概念类似。每一个Table在HDFS中都有一个相应的目录。向表中加入的数据,存储在HDFS对应的目录下。在删除表的时候,对应的HDFS的目录和数据也被删除。
(3)、External Table:
指向HDFS中已存在的目录。再删除表的时候,仅删除表的声明及相关元数据,表对应的HDFS的目录和数据不会被删除。
(4)、Partition:
对表进行分区,Partition对应于HDFS中表目录下的一个子目录。date和city两个Partition则date = 20090801,ctry=US的HDFS子目录为/wh/pvs/date=20090801/ctry=US,对应于(date=20090801,ctry=CA)的HDFS子目录为/wh/pvs/date=20090801/ctry=CA
(5)、Buckets:
对应不同的数据文件。(hive分区有一个缺点,由于数据存储比较集中,容易形式数据的访问热点,这样在大量并发的访问中,热点数据可能造成整个系统的处理能力下降,所以在分区的基础上进行分通,将访问热点中的数据打散,重新分配到不同的机器上)
-
数据类型
tinyint(3位)、smallint(5位)、int(10位)、bigint(19位)、Boolean、float、double、string。
-
数据存储格式
Hive在创建表的时候提供数据的存储方式,Hive即可解析数据。Hive的数据存储格式:TEXTFILE(文本文件)、SEQUENCEFILE(hadoop分布式文件系统的文件)、REFILE。
-
Hive数据校验
Hive在创建表时声明表的结构,但是不负责表中数据的校验,表中的数据是否符合声明的格式,由用户自己保证。
四、Hive和传统的数据库比较
| 查询语言 |
HQL |
SQL |
| 数据存储 |
HDFS |
块设备或者Local FS |
| 数据格式 |
用户定义 |
系统决定 |
| 数据更新 |
不支持 |
支持 |
| 索引 |
无(高版本有) |
有 |
| 执行延迟 |
高 |
低 |
| 计算方式 |
MapReduce |
Executor |
| 可扩展性 |
高 |
低 |
| 数据规模 |
大 |
小 |
五、Hive安装
前提:
(1)、HDFS和MapReduce已经安装并且运行正常;
(2)、安装用户为hadoop,用户根目录/home/hadoop;
(3)、hive及其元数据库mysql安装在namenode节点上(可以安装在其它节点上);
安装步骤:
1、Hive安装包解压
将Hive安装包解压缩到/home/hadoop,解压后出现目录/home/hadoop/hive。
2、配置Hive的元数据库Mysql
(1)、切换至root用户(命令:su);
(2)、启动mysqld服务(命令:service mysqld restart);
(3)、进入mysql shell(命令:mysql)。
(4)、创建名称为"hadooop",密码也为"hadoop"的mysql用户:
GRANT ALL PRIVILEGES ON *.* TO 'hadoop'@'localhost' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO 'hadoop'@'%' IDENTIFIED BY 'hadoop' WITH GRANT OPTION;
FLUSH PRIVILEGES;
(5)、测试hadoop用户是否创建成功
操作系统用户切换回hadoop用户;
执行命令mysql -uhadoop -phadoop 能够成功进入mysql shell 则说明hadoop用户创建成功。
(6)、设置mysql大小写不敏感
操作系统用户切换到root,修改/etc/my.cnf配置文件,在[mysqld]里面添加下面一行:
lower_case_table_names=1
(7)、用root用户重新启动mysql(service mysqld restart)
3、修改Hive的配置文件hive-site.xml


4、修改环境变量.bash_profile
(1)、修改hadoop用户根目录/home/hadoop/下的环境变量文件 .bash_profile,里面添加下面内容:

(2)、执行 ‘source .bash_profile’ 命令,使上面配置的环境变量生效。
5、验证Hive是否安装成功
(1)、进入hive shell 模式(在字符终端内,执行hive命令);成功后如下图:
![]()
(2)、在hive shell 模式,创建数据库和表的命令如下,每个命令要以分号结束。
创建库:create database test_database;
进入库:use test_database;
创建表:create table test_table(id int,name string);
(3)、进入HDFS,查看test_database及test_table对应的目录是否已经创建,执行命令如下:
hadoop fs -ls -R /user/hive
在hive中创建的数据库test_database及表test_table 分别对应HDFS中的目录:
/user/hive/warehouse/test_database.db
/user/hive/warehouse/test_database.db/test_table
至此,Hive安装并运行成功!
六、Hive操作
1、数据库操作
(1)、查询数据库(show databases;)
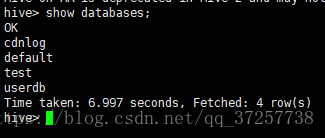
(2)、创建数据库(create database hive_test;)

(3)、删除数据库(drop database hive_test;)

2、表创建删除操作
(1)、创建内部表
# 创建表invites
hive> CREATE TABLE invites(foo INT,bar STRING);
# 查看invites表结构
hive> desc invites;
(2)、创建外部表
Hive的外部表创建时,需要指向HDFS中的一个已经存在的目录(/user/djp/stu)
hive> create external table stu_ext(id int,name string,gender string,birthday string) row format delimited fields terminated by ',' stored as textfile location '/user/djp/stu';
(3)、删除内部表和外部表
删除内部表和删除外部表的HQL语句相同。删除内部表时,表中的数据同时被删除;而外部表指的是HDFS中已经存在的目录,因此删除外部表时,表对应的目录及目录内的内容不会被删除。
hive> drop table stu_ext;
3、向表中导入数据
(1)、向外部表导入数据
在刚才的示例中,创建了一个外部表:stu_ext,指向HDFS的目录是/usr/djp/stu,通过HDFS的 'hadoop fs -put' 命令,向/usr/djp/stu目录拷贝文件,就可以向外部表stu_ext导入数据。
示例:hadoop fs -put student*.txt /user/djp/stu;
注意:在创建表stu_ext时,已经声明的表的格式(包含的字段、字段类型、文件格式、字段分隔符等信息),通过hadoop fs -put 命令导入数据时,要用户自己确保put的数据文件符合stu_ext的格式要求。
其实,不光是外部表中数据,导入hive中的所有数据,hive都不对数据的正确性和有效性进行验证,而是留给用户自己来处理。
(2)、从本地导入数据
数据文件不在hdfs上,直接从本地导入hive表。
hive> create table invites(foo int,bar string);
hive> load data local inpath '/home/hadoop/hive/examples/files/kv2.txt' overwrite into table invites;
注意:这种方式导入的本地数据可以是一个文件,一个文件夹或者通配符,需要注意的是,如果是文件夹,文件夹内不能包含子目录,同样,通配符只能通配文件。
(3)、从HDFS导入数据
数据文件在hdfs上的某个目录下,直接导入hive表;导入到hive表中的文件,被移动到hive表所在的hdfs目录中:
hive> create table invites(foo int,bar string);
hive> load data inpath '/user/djp/kv2.txt' overwrite into table invites;
上述load data 语句执行完成后,/user/djp/kv2.txt这个文件被移动到invites表对应的目录内。
注意:这种方式导入的本地数据可以是一个文件,一个文件夹或者通配符,需要注意的是,如果是文件夹,文件夹内不能包含子目录,同样,通配符只能通配文件。
(4)、从其他表导入数据
数据从一个表导入到另一个表。
hive> from invites insert overwrite table invites_new select * where foo>1 and foo<50;
4、数据查询操作
HQL提供的数据查询操作和SQL相似,主要包括select、from、join、where、group by、order by、limit、top 等子句。这些语句,经过hive的执行引擎的编译优化后,转换为Map Reduce任务在集群上运行,hive把MR的执行结果再返回给客户端。其中特例是 select * from [table name],Hive不会启动MR任务,而是从HDFS中直接读取数据,格式转换后返回给客户端。所以这种查询相较于其他查询速度上要快很多。
(1)、返回一个表中所有数据
hive> select * from invites;
(2)、返回一个表中满足where条件的数据。
hive> select * from invites where foo>1 and foo<100;
(3)、返回一个表中满足where条件的数据,并排序(asc,desc)
hive> select * from invites where foo>1 and foo<100 order by foo desc;
(4)、两个表的join
hive> select * from invites a join invites_new b on a.foo=b.foo;
5、Hive视图操作
低版本的视图不支持视图,高版本的hive支持视图。
Hive View具有以下特点:
# Hive不支持物化视图
# View 只读,不支持LOAD/INSERT/ALTER。用Alter View 改变View定义。
# View 内可能包含ORDER BY/LIMIT 语句,假如一个针对view的查询也包含这些语句,则view中的语句优先级高。
例如:定义view数据为limit 10,针对view 的查询limit 20,则最多返回10条数据。
# Hive支持迭代视图。
(1)、创建视图
hive> create view studentes_view (id,name) as select id,name,from studentes;
(2)、查询视图
对视图的查询QL和对表的查询QL语法相同。
6、Hive的分区(partition)操作
Hive分区的特点
Hive分区和关系型数据库分区的目的相同,主要是为了提供某些查询到的效率。Hive分区主要有一下特点:
(1)、每个分区在hive中以文件夹的形式存在。分区的文件夹属于表对应文件夹的子文件夹;
(2)、hive分区列不是表中的一个实际的字段,而是一个或多个伪列。就是说在表的数据文件中实际上并不保存分区列的信息与数据;
(3)、在hive中,向某个分区中插入什么数据完全是由人来控制的,因为分区键是伪列,不实际存储在文件中;
(4)、Hive支持动态分区,在向表中导入数据时,指定分区规则,hive自动创建分区相应的子文件夹;
Hive分区对数据存储的影响。
(1)、创建一个未分区的表stu1
# 建表HQL
create table stu1 (id int,name string,gender string,birthday string) row format delimited fields terminated by ',' stored as textfile;
# 向表中导入数据
insert overwrite table stu1 select id,name,gender,birthday from studentes;
studentes表是源数据文件导入的原表。

向stu1表导入数据后,在HDFS上stu1表对应的目录内的内容如下图:

stu1表在HDFS中只包含一个名称为000000_0的数据文件,见上图。
(2)、创建一个stu2表,根据gender和birthday进行分区
# 建表HQL(注意:建表时,gender和birthday作为分区字段,不属于stu2表包含的字段)
create table stu2 (id int,name string) partitioned by (gender string,birthday string) row format delimited fields terminated by ',' stored as textfile;
# 设置hive可以全动态分区
--允许使用动态分区可通过set hive.exec.dynamic.partition;查看
hive> set hive.exec.dynamic.partition=true;
--当需要设置所有列为dynamic时需要这样设置
hive> set hive.exec.dynamic.partition.mode=nonstrict;
--如果分区总数超过这个数量会报错
set hive.exec.max.dynamic.partitions=1000;
--单个MR Job允许创建分区的最大数量
set hive.exec.max.dynamic.partitions.pernode=1000;
如果在命令行中设置后没有生效,则可以在配置文件中设置。

# 向表中导入数据
hive> insert overwrite table stu2 partition(gender,birthday) select id,name,gender,birthday from studentes;
studentes表是源数据文件导入的原表。
向stu2表中导入数据后,在HDFS上stu2表对应的目录内的内容如下图:

(3)、在分区后的表上执行查询语句,速度明显提升。

表被分区后,上述的查询语句不但速度提高了,而且还有一个变化:虽然有where子句,但是Hive没有启动MR任务,而是直接从HDFS上读取数据后迅速返回。
7、Hive的开发
Hive提供标准的JDBC API,共java开发者通过编程来访问控制Hive。若需要通过程序连接Hive,需要启动Hive server。启动hive server需要在安装hive的机器上执行如下命令:
hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10001
Hive开发代码示例这里就不展示了,网上有很多例子。