面试1:Java、微服务、架构常见面试题(持续更新中)
Java、微服务、架构常见面试题(持续更新中)
文章目录
- Java、微服务、架构常见面试题(持续更新中)
- ==**Java**==
-
- 1、Java概述
-
- (1)JVM、JRE和JDK
- (2)Java特点
- (3)字节码的好处
- (4)Java VS C++
- (5)Oracle JDK VS Open JDK
- (5)基本数据类型
- (6)Java语言编码方案
- (7)三大特性
- (8)重写与重载
- (9)== 和 equals 的区别
- (10)hashCode 与 equals
- (11)值传递
- (12)反射
- (13)static关键字
- (14)HashMap
- (15)final
- (16)final、finally、finalize
- (17)@Autowired 和 @Resource 有什么区别
- 2、Java集合
-
- Set和List的区别
- 3、Java异常
- 4、并发编程
-
- (1)synchronized
- (2)synchronized 和 Lock 区别?
- (3)volatile 关键字的作用
- (4)Java 中能创建 volatile 数组吗?
- (5)volatile 能使得一个非原子操作变成原子操作吗?
- (6)synchronized 和 volatile 的区别?
- (7)CAS与synchronized**的使用情景**
- (7)如何实现线程的通讯和协作
- (8)线程同步的方法
- (9)如何创建一个线程
- (9)线程池
- ==Spring MVC==
-
- 1、概述
-
- (1)什么是Spring MVC
- (2)Spring IOC
-
- 2.1、IoC(控制反转)
- 2.2、DI(依赖注入)
- ==网络==
-
- 1、三次握手
- 2、长连接和短连接
- 3、TCP如何保证可靠,讲一下拥塞控制的算法
- 4、浏览器输入URL,发生了什么
- 5、DNS解析过程
- 6、http状态吗
- ==**数据库**==
-
- 4、数据库事务的四大特性
- 5、数据库事务如何保证隔离性
- 6、事务并发控制
- 7、事务的隔离级别
- 8、数据库锁的分类
- 9、Myisam和Innodb的区别
- 10、索引为什么用B+树不用平衡二叉树
- 11、 B树和B+树的区别
- ==**计算机组成原理**==
-
- 1、进程和线程区别
- 2、线程有几种状态,运行态能变成就绪态吗
- 3、产生死锁的四个必要条件
- ==**Nginx**==
-
- 1、解释一下什么是Nginx
- 2、Nginx的一些特性
- 3、Nginx VS Apache、Tomcat
- 4、在Nginx中,如何使用未定义的服务器名称阻止处理请求
- 5、Nginx如何处理HTTP请求
- 6、反向代理服务器的优点是什么
- 7、Nginx的最佳用途
- 8、Nginx上的Master和Worker进程
- 9、正向代理与反向代理
- 10、将Nginx错误替换为502,503
- 11、在Nginx中,如何保留url中的双斜线
- 12、ngx_http_upstream_module的作用
- 13、解释C10K的问题
- 14、stub_status和sub_filter指令的作用是什么
- 15、Nginx是否支持将请求压缩到上游
- 16、Nginx中获取当前时间
- 17、gastcgi与cgi的区别
- 18、Nginx常用命令
- 19、Nginx常用配置
- 20、Nginx 如何处理 HTTP 请求
- 21、Nginx为什么不用多线程
- 22、Nginx负载均衡的方式
- 23、Nginx -s 的目的是什么
- 24、ngx_http_upstream_module模块了解吗
- 25、限流了解吗,怎么做
- ==Docker==
-
- 1、什么是Docker
- 2、Docker VS 虚拟机
- 3、Docker容器之间如何实现隔离
- 4、镜像分层
- 5、Docker容器退出时是否会丢失数据
- 6、Docker容器运行的集中状态
- 7、Dockerfile常见的命令是什么
- 8、Dockerfile中的命令COPY和ADD区别
- 9、Docker常用的命令
- 10、容器互相访问方式
- ==**Redis**==
-
- 1、Redis是什么
- 2、Redis的优缺点
- 3、为什么用缓存?为什么用Redis做缓存?
- 4、Redis为什么这么快
- 5、Redis的删除策略有哪些
- 7、watch 命令的作用是什么
- 8、如何使用Redis实现分布式锁
- 9、Redis持久化
- 10、Redis架构模式
- 11、保证Redis中存放的都是热点数据
- 12、Redis事务
-
- 事务支持隔离码?
- Redis事务保证原子性吗,支持回滚吗?
- 13、Reids内存方面
-
- (1)Redis主要消耗什么物理资源?
- (2)Redis的内存用完了会发生什么?
- (3)Redis如何做内存优化?
- 14、Redis分区
-
- (1)提高多核CPU的利用率
- (2)Redis分区
- (3)分区方案
- (4)Redis分区有什么缺点?
- 15、缓存
-
- (1)雪崩
- (2)穿透
- (3)击穿
- 16、Redis与Memcached的区别
- 17、Redis使用
-
- (1)一个字符串最大容量
- (2)Redis如何做大量数据插入
- (3)找固定开头的key
- (4)Redis做异步队列
- (5)Redis如何实现延时队列
- (6)Redis回收进程如何工作的
- (7)Redis回收算法
- ==**智力题**==
-
-
- 1、面粉题
-
- ==**常考算法**==
-
- 1、最长回文数
- 2、接雨水(NC128)
- 4、红包金额分赔算法
- 5、字符串压缩
- 6、括号匹配(NC52)
- 7、最长回文串
- 字符串全排列(JZ27)
- 8、链表排序(NC70)
- 9、合并两个有序链表(NC33)
- 10、两个链表相加(NC40)
- 删除链表的倒数第n个节点(NC53)
- 大数加法(NC1)
- 寻找第K大(NC88)
- 求二叉树的层序遍历(NC15)
- 最长公共前缀(NC55)
- **买卖股票的最好时机**
- **二分查找-II(**NC105**)**
作者:不染心
更新时间:2021/7/4
需要pdf的,在下方留下邮箱即可

Java
1、Java概述
(1)JVM、JRE和JDK
JVM
Java Virtual Machine是Java虚拟机,Java程序需要运行在虚拟机上,不同的平台有自己的虚拟机,因此Java语言可以实现跨平台。
JRE
Java Runtime Environment包括Java虚拟机和Java程序所需的核心类库等。核心类库主要是java.lang包:包含了运行Java程序必不可少的系统类,如基本数据类型、基本数学函数、字符串处理、线程、异常处理类等,系统缺省加载这个包
JDK
Java Development Kit是提供给Java开发人员使用的,其中包含了Java的开发工具,也包括了JRE。所以安装了JDK,就无需再单独安装JRE了。其中的开发工具:编译工具(javac.exe),打包工具(jar.exe)等

(2)Java特点
-
简单易学(Java语言的语法与C语言和C++语言很接近)
-
面向对象(封装,继承,多态)
-
平台无关性(Java虚拟机实现平台无关性)
-
支持网络编程并且很方便(Java语言诞生本身就是为简化网络编程设计的)
-
支持多线程(多线程机制使应用程序在同一时间并行执行多项任)
-
健壮性(Java语言的强类型机制、异常处理、垃圾的自动收集等)
-
安全性
(3)字节码的好处
字节码:Java源代码经过虚拟机编译器编译后产生的文件(即扩展为.class的文件),它不面向任何特定的处理器,只面向虚拟机。
采用字节码的好处:
Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
先看下java中的编译器和解释器:
Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在Java中,这种供虚拟机理解的代码叫做字节码(即扩展为.class的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行,这就是上面提到的Java的特点的编译与解释并存的解释。
Java源代码---->编译器---->jvm可执行的Java字节码(即虚拟指令)---->jvm---->jvm中解释器----->机器可执行的二进制机器码---->程序运行。
(4)Java VS C++
- 都是面向对象的语言,都支持封装、继承和多态
- Java不提供指针来直接访问内存,程序内存更加安全
- Java的类是单继承的,C++支持多重继承;虽然Java的类不可以多继承,但是接口可以多继承。
- Java有自动内存管理机制,不需要程序员手动释放无用内存
(5)Oracle JDK VS Open JDK
-
Oracle JDK版本将每三年发布一次,而OpenJDK版本每三个月发布一次;
-
OpenJDK 是一个参考模型并且是完全开源的,而Oracle JDK是OpenJDK的一个实现,并不是完全开源的;
-
Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎相同,但Oracle JDK有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到Oracle JDK就可以解决问题;
-
在响应性和JVM性能方面,Oracle JDK与OpenJDK相比提供了更好的性能;
-
Oracle JDK不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
-
Oracle JDK根据二进制代码许可协议获得许可,而OpenJDK根据GPL v2许可获得许可。
(5)基本数据类型
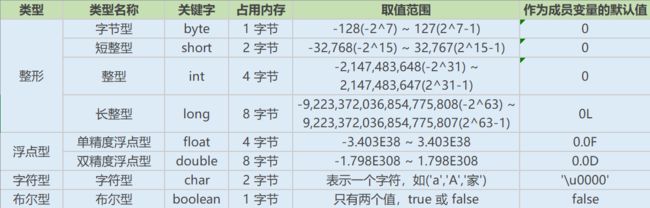
(6)Java语言编码方案
Java语言采用Unicode编码标准,Unicode(标准码),它为每个字符制订了一个唯一的数值,因此在任何的语言,平台,程序都可以放心的使用。
(7)三大特性
Java 面向对象编程三大特性:封装 继承 多态
封装:隐藏对象的属性和实现细节,仅对外提供公共访问方式,将变化隔离,便于使用,提高复用性和安全性。
继承:继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承可以提高代码复用性。继承是多态的前提。
关于继承如下 3 点请记住:
子类拥有父类非 private 的属性和方法。
子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法。
多态性:父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。提高了程序的拓展性。
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重写(override)实现的是运行时的多态性(也称为后绑定)。
(8)重写与重载
-
构造器(constructor)是否可被重写(override)?
构造器不能被继承,因此不能被重写,但可以被重载。
-
重载(Overload)和重写(Override)的区别。重载的方法能否根据返回类型进行区分?
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。
重载:发生在同一个类中,方法名相同参数列表不同(参数类型不同、个数不同、顺序不同),与方法返回值和访问修饰符无关,即重载的方法不能根据返回类型进行区分
重写:发生在父子类中,方法名、参数列表必须相同,返回值小于等于父类,抛出的异常小于等于父类,访问修饰符大于等于父类(里氏代换原则);如果父类方法访问修饰符为private则子类中就不是重写。
(9)== 和 equals 的区别
- 基本数据类型 == 比较的是值,引用数据类型 == 比较的是内存地址
- equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;
(10)hashCode 与 equals
-
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
- 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
-
hashCode()与equals()的相关规定
- 如果两个对象相等,则hashcode一定也是相同的
- 两个对象相等,对两个对象分别调用equals方法都返回true
- 两个对象有相同的hashcode值,它们也不一定是相等的
- 因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
- hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
-
对象的相等与指向他们的引用相等,两者有什么不同?
对象的相等 比的是内存中存放的内容是否相等而 引用相等 比较的是他们指向的内存地址是否相等。
(11)值传递
为什么 Java 中只有值传递
首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。 它用来描述各种程序设计语言(不只是Java)中方法参数传递方式。
Java程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。
(12)反射
-
什么是反射
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
静态编译和动态编译
**静态编译:**在编译时确定类型,绑定对象
**动态编译:**运行时确定类型,绑定对象 -
反射机制的优缺点
- 优点: 运行期类型的判断,动态加载类,提高代码灵活度。
- 缺点: 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
-
反射机制的应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:①我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;②Spring框架也用到很多反射机制,最经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中; 2)Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的Class实例; 4)动态配置实例的属性
-
获取反射的三种方法
- 通过new对象实现反射机制
- 通过路径实现反射机制
- 通过类名实现反射机制
public class Get { //获取反射机制三种方式 public static void main(String[] args) throws ClassNotFoundException { //方式一(通过建立对象) Student stu = new Student(); Class classobj1 = stu.getClass(); System.out.println(classobj1.getName()); //方式二(所在通过路径-相对路径) Class classobj2 = Class.forName("fanshe.Student"); System.out.println(classobj2.getName()); //方式三(通过类名) Class classobj3 = Student.class; System.out.println(classobj3.getName()); }}
(13)static关键字
“static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。”
被static关键字修饰的方法或者变量不需要依赖于对象来进行访问,只要类被加载了,就可以通过类名去进行访问。
static可以用来修饰类的成员方法、类的成员变量,另外可以编写static代码块来优化程序性能。
(14)HashMap
treeifyBin函数里,如果数组长度小于64,会走数组的resize函数,而不是转化成红黑树。所以转化成红黑树的条件有两个:
- 数组中单个链表的长度大于等于8。
- 数组长度大于等于64。两个条件都成立时,转化为红黑树。
(15)final
- 修饰类:当用final修饰一个类时,表明这个类不能被继承。
- 修饰方法:使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。
- 修饰变量:对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
(16)final、finally、finalize
- final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、修饰变量表示该变量是一个常量不能被重新赋值。
- finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法finally代码块中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代码。
- finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,Java 中允许使用 finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。
(17)@Autowired 和 @Resource 有什么区别
@Autowired功能虽说非常强大,但是也有些不足之处。比如:比如它跟spring强耦合了,如果换成了JFinal等其他框架,功能就会失效。而@Resource是JSR-250提供的,它是Java标准,绝大部分框架都支持。
除此之外,有些场景使用@Autowired无法满足的要求,改成@Resource却能解决问题。接下来,我们重点看看@Autowired和@Resource的区别。
- @Autowired默认按byType自动装配,而@Resource默认byName自动装配。
- @Autowired只包含一个参数:required,表示是否开启自动准入,默认是true。而@Resource包含七个参数,其中最重要的两个参数是:name 和 type。
- @Autowired如果要使用byName,需要使用@Qualifier一起配合。而@Resource如果指定了name,则用byName自动装配,如果指定了type,则用byType自动装配。
- @Autowired能够用在:构造器、方法、参数、成员变量和注解上,而@Resource能用在:类、成员变量和方法上。
- @Autowired是spring定义的注解,而@Resource是JSR-250定义的注解。
此外,它们的装配顺序不同。
@Autowired的装配顺序如下:

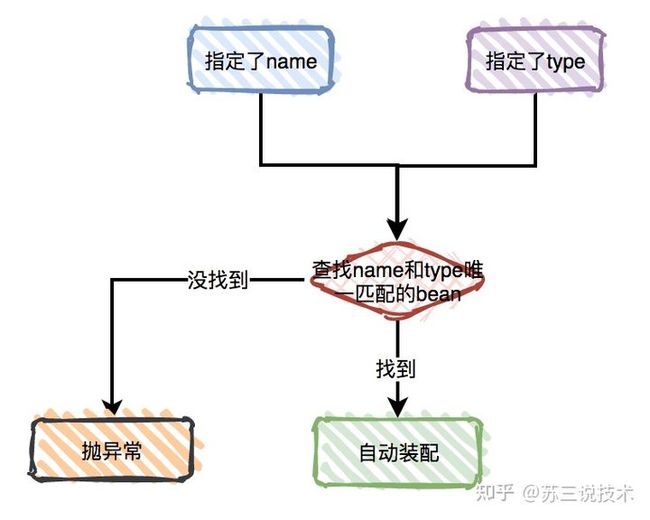
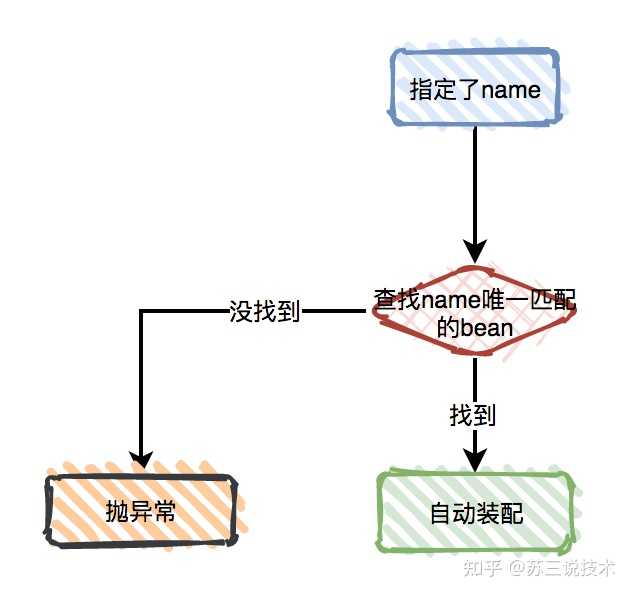
@Resource的装配顺序如下:
- 如果同时指定了name和type:
- 如果指定了name:
- 如果指定了type:

- 如果既没有指定name,也没有指定type:
2、Java集合

Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
Collection 接口又有 3 种子类型,List、Set 和 Queue。
最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
Set和List的区别
-
- Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
-
- Set检索效率低下,删除和插入效率高,插入和删除不会引起元素位置改变 <实现类有HashSet,TreeSet>。
-
- List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高,插入删除效率低,因为会引起其他元素位置改变 <实现类有ArrayList,LinkedList,Vector> 。
3、Java异常
4、并发编程

(1)synchronized
当一个线程进入一个对象的 synchronized 方法 A 之后,其它线程是否可进入此对象的 synchronized 方法 B?
不能。其它线程只能访问该对象的非同步方法,同步方法则不能进入。因为非静态方法上的 synchronized 修饰符要求执行方法时要获得对象的锁,如果已经进入A 方法说明对象锁已经被取走,那么试图进入 B 方法的线程就只能在等锁池(注意不是等待池哦)中等待对象的锁。
synchronized、volatile、CAS 比较
(1)synchronized 是悲观锁,属于抢占式,会引起其他线程阻塞。
(2)volatile 提供多线程共享变量可见性和禁止指令重排序优化。
(3)CAS 是基于冲突检测的乐观锁(非阻塞)
(2)synchronized 和 Lock 区别?
- 首先synchronized是Java内置关键字,在JVM层面,Lock是个Java类;
- synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
- synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
(3)volatile 关键字的作用
volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
从实践角度而言,volatile 的一个重要作用就是和 CAS 结合,保证了原子性
CAS是英文单词Compare And Swap的缩写,翻译过来就是比较并替换,是一种无锁编程,不使用锁,没有阻塞就可以实现线程之间的同步。
CAS机制当中使用了3个基本操作数:内存地址V,旧的预期值A,要修改的新值B。
更新一个变量的时候,只有当变量的预期值A和内存地址V当中的实际值相同时,才会将内存地址V对应的值修改为B。
(4)Java 中能创建 volatile 数组吗?
能,Java 中可以创建 volatile 类型数组,不过只是一个指向数组的引用,而不是整个数组。意思是,如果改变引用指向的数组,将会受到 volatile 的保护,但是如果多个线程同时改变数组的元素,volatile 标示符就不能起到之前的保护作用了。
(5)volatile 能使得一个非原子操作变成原子操作吗?
关键字volatile的主要作用是使变量在多个线程间可见,但无法保证原子性,对于多个线程访问同一个实例变量需要加锁进行同步。
虽然volatile只能保证可见性不能保证原子性,但用volatile修饰long和double可以保证其操作原子性。
(6)synchronized 和 volatile 的区别?
synchronized 表示只有一个线程可以获取作用对象的锁,执行代码,阻塞其他线程。
volatile 表示变量在 CPU 的寄存器中是不确定的,必须从主存中读取。保证多线程环境下变量的可见性;禁止指令重排序。
区别
- volatile 是变量修饰符;synchronized 可以修饰类、方法、变量。
- volatile 仅能实现变量的修改可见性,不能保证原子性;而 synchronized 则可以保证变量的修改可见性和原子性。
- volatile 不会造成线程的阻塞;synchronized 可能会造成线程的阻塞。
- volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
- volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,实际开发中使用 synchronized 关键字的场景还是更多一些。
(7)CAS与synchronized的使用情景
CAS 适用(多读场景,冲突一般较少),
synchronized 适用(多写场景,冲突一般较多)
(7)如何实现线程的通讯和协作
可以通过中断 和 共享变量的方式实现线程间的通讯和协作
比如说最经典的生产者-消费者模型:当队列满时,生产者需要等待队列有空间才能继续往里面放入商品,而在等待的期间内,生产者必须释放对临界资源(即队列)的占用权。因为生产者如果不释放对临界资源的占用权,那么消费者就无法消费队列中的商品,就不会让队列有空间,那么生产者就会一直无限等待下去。因此,一般情况下,当队列满时,会让生产者交出对临界资源的占用权,并进入挂起状态。然后等待消费者消费了商品,然后消费者通知生产者队列有空间了。同样地,当队列空时,消费者也必须等待,等待生产者通知它队列中有商品了。这种互相通信的过程就是线程间的协作。
Java中线程通信协作的最常见的两种方式:
一.syncrhoized加锁的线程的Object类的wait()/notify()/notifyAll()
二.ReentrantLock类加锁的线程的Condition类的await()/signal()/signalAll()
线程间直接的数据交换:
三.通过管道进行线程间通信:1)字节流;2)字符流
同步方法和同步块,哪个是更好的选择?
同步块是更好的选择,因为它不会锁住整个对象(当然你也可以让它锁住整个对象)。同步方法会锁住整个对象,哪怕这个类中有多个不相关联的同步块,这通常会导致他们停止执行并需要等待获得这个对象上的锁。
同步块更要符合开放调用的原则,只在需要锁住的代码块锁住相应的对象,这样从侧面来说也可以避免死锁。
请知道一条原则:同步的范围越小越好。
(8)线程同步的方法
-
同步代码方法:sychronized 关键字修饰的方法
-
同步代码块:sychronized 关键字修饰的代码块
-
使用特殊变量域volatile实现线程同步:volatile关键字为域变量的访问提供了一种免锁机制
-
使用重入锁实现线程同步:reentrantlock类是可冲入、互斥、实现了lock接口的锁他与sychronized方法具有相同的基本行为和语义
(9)如何创建一个线程
1)继承Thread类创建线程
2)实现Runnable接口创建线程
3)使用Callable和Future创建线程
4)使用线程池例如用Executor框架
继承Thread类创建线程
public class MyThread extends Thread{//继承Thread类 public void run(){ //重写run方法 }}public class Main { public static void main(String[] args){ new MyThread().start();//创建并启动线程 }}
实现Runnable接口创建线程
public class MyThread2 implements Runnable {//实现Runnable接口 public void run(){ //重写run方法 }}public class Main { public static void main(String[] args){ //创建并启动线程 MyThread2 myThread=new MyThread2(); Thread thread=new Thread(myThread); thread().start(); //或者 new Thread(new MyThread2()).start(); }}
(9)线程池
什么是线程池:
线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建,使用完毕不需要销毁线程而是放回池中,从而减少创建和销毁线程对象的开销。Java 5+中的 Executor 接口定义一个执行线程的工具。它的子类型即线程池接口是 ExecutorService。要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,因此在工具类 Executors 面提供了一些静态工厂方法,生成一些常用的线程池,
(1)newSingleThreadExecutor:创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
(2)newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。如果希望在服务器上使用线程池,建议使用 newFixedThreadPool方法来创建线程池,这样能获得更好的性能。
(3) newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60 秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。
(4)newScheduledThreadPool:创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
线程池有什么优点?
降低资源消耗:重用存在的线程,减少对象创建销毁的开销。
提高响应速度:可有效的控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
附加功能:提供定时执行、定期执行、单线程、并发数控制等功能。
综上所述使用线程池框架 Executor 能更好的管理线程、提供系统资源使用率。
线程池都有哪些状态?
RUNNING:这是最正常的状态,接受新的任务,处理等待队列中的任务。
SHUTDOWN:不接受新的任务提交,但是会继续处理等待队列中的任务。
STOP:不接受新的任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
TIDYING:所有的任务都销毁了,workCount 为 0,线程池的状态在转换为 TIDYING 状态时,会执行钩子方法 terminated()。
TERMINATED:terminated()方法结束后,线程池的状态就会变成这个。
什么是 Executor 框架?为什么使用 Executor 框架?
Executor 框架是一个根据一组执行策略调用,调度,执行和控制的异步任务的框架。
每次执行任务创建线程 new Thread()比较消耗性能,创建一个线程是比较耗时、耗资源的,而且无限制的创建线程会引起应用程序内存溢出。
所以创建一个线程池是个更好的的解决方案,因为可以限制线程的数量并且可以回收再利用这些线程。利用Executors 框架可以非常方便的创建一个线程池。
在 Java 中 Executor 和 Executors 的区别?
Executors 工具类的不同方法按照我们的需求创建了不同的线程池,来满足业务的需求。
Executor 接口对象能执行我们的线程任务。
ExecutorService 接口继承了 Executor 接口并进行了扩展,提供了更多的方法我们能获得任务执行的状态并且可以获取任务的返回值。
使用 ThreadPoolExecutor 可以创建自定义线程池。
Future 表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完成,并可以使用 get()方法获取计算的结果。
线程池中 submit() 和 execute() 方法有什么区别?
接收参数:execute()只能执行 Runnable 类型的任务。submit()可以执行 Runnable 和 Callable 类型的任务。
返回值:submit()方法可以返回持有计算结果的 Future 对象,而execute()没有
异常处理:submit()方便Exception处理
什么是线程组,为什么在 Java 中不推荐使用?
ThreadGroup 类,可以把线程归属到某一个线程组中,线程组中可以有线程对象,也可以有线程组,组中还可以有线程,这样的组织结构有点类似于树的形式。
线程组和线程池是两个不同的概念,他们的作用完全不同,前者是为了方便线程的管理,后者是为了管理线程的生命周期,复用线程,减少创建销毁线程的开销。
为什么不推荐使用线程组?因为使用有很多的安全隐患吧,没有具体追究,如果需要使用,推荐使用线程池。
Spring MVC
1、概述
(1)什么是Spring MVC
Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合。
(2)Spring IOC
IoC 不是一种技术,只是一种思想,一个重要的面向对象编程的法则,它能指导我们如何设计出松耦合、更优良的程序。传统应用程序都是由我们在类内部主动创建依赖对象,从而导致类与类之间高耦合,难于测试;有了IoC容器后,把创建和查找依赖对象的控制权交给了容器,由容器进行注入组合对象,所以对象与对象之间是 松散耦合,这样也方便测试,利于功能复用,更重要的是使得程序的整个体系结构变得非常灵活。
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
2.1、IoC(控制反转)
首先想说说IoC(Inversion of Control,控制反转)。这是spring的核心,贯穿始终。**所谓IoC,对于spring框架来说,就是由spring来负责控制对象的生命周期和对象间的关系。**这是什么意思呢,举个简单的例子,我们是如何找女朋友的?常见的情况是,我们到处去看哪里有长得漂亮身材又好的mm,然后打听她们的兴趣爱好、qq号、电话号、ip号、iq号………,想办法认识她们,投其所好送其所要,然后嘿嘿……这个过程是复杂深奥的,我们必须自己设计和面对每个环节。传统的程序开发也是如此,在一个对象中,如果要使用另外的对象,就必须得到它(自己new一个,或者从JNDI中查询一个),使用完之后还要将对象销毁(比如Connection等),对象始终会和其他的接口或类藕合起来。
那么IoC是如何做的呢?有点像通过婚介找女朋友,在我和女朋友之间引入了一个第三者:婚姻介绍所。婚介管理了很多男男女女的资料,我可以向婚介提出一个列表,告诉它我想找个什么样的女朋友,比如长得像李嘉欣,身材像林熙雷,唱歌像周杰伦,速度像卡洛斯,技术像齐达内之类的,然后婚介就会按照我们的要求,提供一个mm,我们只需要去和她谈恋爱、结婚就行了。简单明了,如果婚介给我们的人选不符合要求,我们就会抛出异常。整个过程不再由我自己控制,而是有婚介这样一个类似容器的机构来控制。Spring所倡导的开发方式就是如此,所有的类都会在spring容器中登记,告诉spring你是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。
2.2、DI(依赖注入)
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了 spring我们就只需要告诉spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。在系统运行时,spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖 Connection才能正常运行,而这个Connection是由spring注入到A中的,依赖注入的名字就这么来的。那么DI是如何实现的呢? Java 1.3之后一个重要特征是反射(reflection),它允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性,spring就是通过反射来实现注入的。
理解了IoC和DI的概念后,一切都将变得简单明了,剩下的工作只是在spring的框架中堆积木而已。
网络
1、三次握手
三次握手过程理解
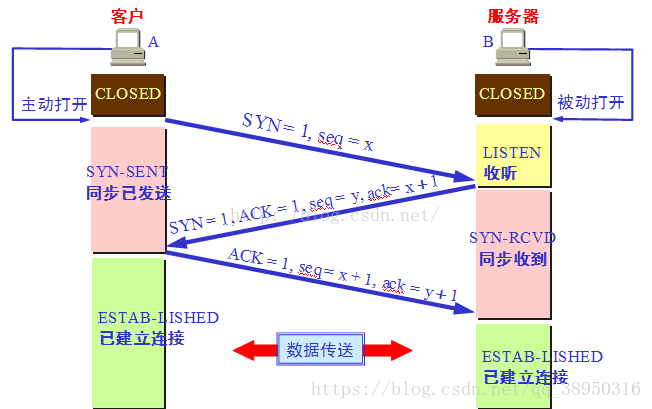
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
四次挥手过程理解

1)客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2)服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3)客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4)服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5)客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6)服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
常见面试题
【问题1】为什么连接的时候是三次握手,关闭的时候却是四次握手?
答:因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,“你发的FIN报文我收到了”。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
【问题2】为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能返回到CLOSE状态?
答:虽然按道理,四个报文都发送完毕,我们可以直接进入CLOSE状态了,但是我们必须假象网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
【问题3】为什么不能用两次握手进行连接?
答:3次握手完成两个重要的功能,既要双方做好发送数据的准备工作(双方都知道彼此已准备好),也要允许双方就初始序列号进行协商,这个序列号在握手过程中被发送和确认。
现在把三次握手改成仅需要两次握手,死锁是可能发生的。作为例子,考虑计算机S和C之间的通信,假定C给S发送一个连接请求分组,S收到了这个分组,并发 送了确认应答分组。按照两次握手的协定,S认为连接已经成功地建立了,可以开始发送数据分组。可是,C在S的应答分组在传输中被丢失的情况下,将不知道S 是否已准备好,不知道S建立什么样的序列号,C甚至怀疑S是否收到自己的连接请求分组。在这种情况下,C认为连接还未建立成功,将忽略S发来的任何数据分 组,只等待连接确认应答分组。而S在发出的分组超时后,重复发送同样的分组。这样就形成了死锁。
【问题4】如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP还设有一个保活计时器,显然,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
2、长连接和短连接
在HTTP/1.0中默认使用短连接。也就是说,客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个HTML或其他类型的Web页中包含有其他的Web资源(如JavaScript文件、图像文件、CSS文件等),每遇到这样一个Web资源,浏览器就会重新建立一个HTTP会话。
而从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头加入这行代码:
Connection:keep-alive
在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中设定这个时间。实现长连接需要客户端和服务端都支持长连接。
什么时候用长连接,短连接?
长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况,。每个TCP连接都需要三步握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,次处理时直接发送数据包就OK了,不用建立TCP连接。例如:数据库的连接用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
而像WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知吧。所以并发量大,但每个用户无需频繁操作情况下需用短连好
优缺点
长连接可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。不过这里存在一个问题,存活功能的探测周期太长,还有就是它只是探测TCP连接的存活,属于比较斯文的做法,遇到恶意的连接时,保活功能就不够使了。在长连接的应用场景下,client端一般不会主动关闭它们之间的连接,Client与server之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接越来越多,server早晚有扛不住的时候,这时候server端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可 以避免一些恶意连接导致server端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在TCP的建立和关闭操作上浪费时间和带宽。
3、TCP如何保证可靠,讲一下拥塞控制的算法
TCP协议保证数据传输可靠性的方式主要有:
(校 序 重 流 拥)
校验和:
发送的数据包的二进制相加然后取反,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP将丢弃这个报文段和不确认收到此报文段。
确认应答+序列号(累计确认+seq):
接收方收到报文就会确认(累积确认:对所有按序接收的数据的确认)
TCP给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
超时重传:
当TCP发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
流量控制:
TCP连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP使用的流量控制协议是可变大小的滑动窗口协议。
接收方有即时窗口(滑动窗口),随ACK报文发送
拥塞控制:
TCP 通过维护一个拥塞窗口来进行拥塞控制,拥塞控制的原则是,只要网络中没有出现拥塞,拥塞窗口的值就可以再增大一些,以便把更多的数据包发送出去,但只要网络出现拥塞,拥塞窗口的值就应该减小一些,以减少注入到网络中的数据包数。
TCP 拥塞控制算法发展的过程中出现了如下几种不同的思路:
- 基于丢包的拥塞控制:将丢包视为出现拥塞,采取缓慢探测的方式,逐渐增大拥塞窗口,当出现丢包时,将拥塞窗口减小,如 Reno、Cubic 等。
- 基于时延的拥塞控制:将时延增加视为出现拥塞,延时增加时增大拥塞窗口,延时减小时减小拥塞窗口,如 Vegas、FastTCP 等。
- 基于链路容量的拥塞控制:实时测量网络带宽和时延,认为网络上报文总量大于带宽时延乘积时出现了拥塞,如 BBR。
- 基于学习的拥塞控制:没有特定的拥塞信号,而是借助评价函数,基于训练数据,使用机器学习的方法形成一个控制策略,如 Remy。
4、浏览器输入URL,发生了什么
1.在浏览器中输入url
用户输入url,例如http://www.baidu.com。其中http为协议,www.baidu.com为网络地址,及指出需要的资源在那台计算机上。一般网络地址可以为域名或IP地址,此处为域名。使用域名是为了方便记忆,但是为了让计算机理解这个地址还需要把它解析为IP地址。
2.应用层DNS解析域名
客户端先检查本地是否有对应的IP地址,若找到则返回响应的IP地址。若没找到则请求上级DNS服务器,直至找到或到根节点。
3.应用层客户端发送HTTP请求
HTTP请求包括请求报头和请求主体两个部分,其中请求报头包含了至关重要的信息,包括请求的方法(GET / POST)、目标url、遵循的协议(http / https / ftp…),返回的信息是否需要缓存,以及客户端是否发送cookie等。
4.传输层TCP传输报文
位于传输层的TCP协议为传输报文提供可靠的字节流服务。它为了方便传输,将大块的数据分割成以报文段为单位的数据包进行管理,并为它们编号,方便服务器接收时能准确地还原报文信息。TCP协议通过“三次握手”等方法保证传输的安全可靠。
“三次握手”的过程是,发送端先发送一个带有SYN(synchronize)标志的数据包给接收端,在一定的延迟时间内等待接收的回复。接收端收到数据包后,传回一个带有SYN/ACK标志的数据包以示传达确认信息。接收方收到后再发送一个带有ACK标志的数据包给接收端以示握手成功。在这个过程中,如果发送端在规定延迟时间内没有收到回复则默认接收方没有收到请求,而再次发送,直到收到回复为止。
5.网络层IP协议查询MAC地址
IP协议的作用是把TCP分割好的各种数据包传送给接收方。而要保证确实能传到接收方还需要接收方的MAC地址,也就是物理地址。IP地址和MAC地址是一一对应的关系,一个网络设备的IP地址可以更换,但是MAC地址一般是固定不变的。ARP协议可以将IP地址解析成对应的MAC地址。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的MAC地址来搜索下一个中转目标。
6.数据到达数据链路层
在找到对方的MAC地址后,就将数据发送到数据链路层传输。这时,客户端发送请求的阶段结束
7.服务器接收数据
接收端的服务器在链路层接收到数据包,再层层向上直到应用层。这过程中包括在运输层通过TCP协议讲分段的数据包重新组成原来的HTTP请求报文。
8.服务器响应请求
服务接收到客户端发送的HTTP请求后,查找客户端请求的资源,并返回响应报文,响应报文中包括一个重要的信息——状态码。状态码由三位数字组成,其中比较常见的是200 OK表示请求成功。301表示永久重定向,即请求的资源已经永久转移到新的位置。在返回301状态码的同时,响应报文也会附带重定向的url,客户端接收到后将http请求的url做相应的改变再重新发送。404 not found 表示客户端请求的资源找不到。
9.服务器返回相应文件**
请求成功后,服务器会返回相应的HTML文件。接下来就到了页面的渲染阶段了。
现代浏览器渲染页面的过程是这样的:jiexiHTML以构建DOM树 –> 构建渲染树 –> 布局渲染树 –> 绘制渲染树。
5、DNS解析过程
- 用户在浏览器中输入网址
www.example.com并点击回车后,查询会进入网络,并且由 DNS 解析器进行接收。 - DNS 解析器会向根域名发起查询请求,要求返回顶级域名的地址。
- 根 DNS 服务器会注意到请求地址的前缀并向 DNS 解析器返回 com 的顶级域名服务器(TLD) 的 IP 地址列表。
- 然后,DNS 解析器会向 TLD 服务器发送查询报文
- TLD 服务器接收请求后,会根据域名的地址把权威 DNS 服务器的 IP 地址返回给 DNS 解析器。
- 最后,DNS 解析器将查询直接发送到权威 DNS 服务器
- 权威 DNS 服务器将 IP 地址返回给 DNS 解析器
- DNS 解析器将会使用 IP 地址响应 Web 浏览器
6、http状态吗

3XX 响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
403 Forbidden
该状态码表明对请求资源的访问被服务器拒绝了。 服务器端没有必要给出拒绝的详细理由, 但如果想作说明的话, 可以在实体的主体部分对原因进行描述, 这样就能让用户看到了。
未获得文件系统的访问授权, 访问权限出现某些问题(从未授权的发送源 IP 地址试图访问) 等列举的情况都可能是发生 403 的原因。
-404 Not Found
该状态码表明服务器上无法找到请求的资源。 除此之外, 也可以在服务器端拒绝请求且不想说明理由时使用。
5XX 服务器错误
5XX 的响应结果表明服务器本身发生错误。
数据库
4、数据库事务的四大特性
原子性、一致性、隔离性、持久性
- 原子性:原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚;
- 一致性:一个事务执行之前和执行之后都必须处于一致性状态;拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
- 隔离性:当多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
- 持久性:持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的;
5、数据库事务如何保证隔离性
锁
6、事务并发控制
MVCC,全称Multi-Version Concurrency Control,即多版本并发控制。MVCC是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
- 脏读(Dirty Read):此种异常时因为一个事务读取了另一个事务修改了但是未提交的数据。
- 不可重复读(Not Repeatable Read):此种异常是一个事务对同一行数据执行了两次或更多次查询,但是却得到了不同的结果,也就是在一个事务里面你不能重复(即多次)读取一行数据,如果你这么做了,不能保证每次读取的结果是一样的,有可能一样有可能不一样。
- 幻读(Phantom Read):幻读和不可重复读有点像,只是针对的不是数据的值而是数据的数量。此种异常是一个事务在两次查询的过程中数据的数量不同,让人以为发生幻觉,幻读大概就是这么得来的吧。
7、事务的隔离级别
如何解决上述的异常情况
- 读未提交(Read Uncommitted):该隔离级别指即使一个事务的更新语句没有提交,但是别的事务可以读到这个改变,几种异常情况都可能出现。极易出错,没有安全性可言,基本不会使用。
- 读已提交(Read Committed):该隔离级别指一个事务只能看到其他事务的已经提交的更新,看不到未提交的更新,消除了脏读和第一类丢失更新,这是大多数数据库的默认隔离级别,如Oracle,Sqlserver。
- 可重复读(Repeatable Read):该隔离级别指一个事务中进行两次或多次同样的对于数据内容的查询,得到的结果是一样的,但不保证对于数据条数的查询是一样的,只要存在读改行数据就禁止写,消除了不可重复读和第二类更新丢失,这是Mysql数据库的默认隔离级别。
- 串行化(Serializable):意思是说这个事务执行的时候不允许别的事务并发执行.完全串行化的读,只要存在读就禁止写,但可以同时读,消除了幻读。这是事务隔离的最高级别,虽然最安全最省心,但是效率太低,一般不会用。
8、数据库锁的分类
- 悲观锁:就是很悲观,它对于数据被外界修改持保守态度,认为数据随时会修改,所以整个数据处理中需要将数据加锁。
- 共享锁(Share locks简记为S锁):读锁,事务A对对象T加s锁,其他事务也只能对T加S,多个事务可以同时读,但不能有写操作,直到A释放S锁。
- 排它锁(Exclusivelocks简记为X锁):也称写锁,事务A对对象T加X锁以后,其他事务不能对T加任何锁,只有事务A可以读写对象T直到A释放X锁。
- 更新锁(简记为U锁)
- 乐观锁:就是很乐观,每次自己操作数据的时候认为没有人回来修改它,所以不去加锁,但是在更新的时候会去判断在此期间数据有没有被修改,需要用户自己去实现。
- 版本号:就是给数据增加一个版本标识,在数据库上就是表中增加一个version字段,每次更新把这个字段加1
- 时间戳
- 待更新字段
- 所有字段
使用范围:
乐观锁:读写比例差距不是非常大或者你的系统没有响应不及时,吞吐量瓶颈问题,那就不要去使用乐观锁,它增加了复杂度,也带来了额外的风险。
悲观锁
9、Myisam和Innodb的区别
区别
-
InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
-
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
-
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
-
innoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快(注意不能加有任何WHERE条件);
-
Innodb不支持全文索引,而MyISAM支持全文索引,在涉及全文索引领域的查询效率上MyISAM速度更快高;PS:5.7以后的InnoDB支持全文索引了
-
MyISAM表格可以被压缩后进行查询操作
-
InnoDB支持表、行(默认)级锁,而MyISAM支持表级锁
-
InnoDB表必须有唯一索引(如主键)(用户没有指定的话会自己找/生产一个隐藏列Row_id来充当默认主键),而Myisam可以没有
-
Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI
Innodb:frm是表定义文件,ibd是数据文件Myisam:frm是表定义文件,myd是数据文件,myi是索引文件如何选择:
1. 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM; 2. 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读也有写,请使用InnoDB。 2. 系统奔溃后,MyISAM恢复起来更困难,能否接受; -
MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。
10、索引为什么用B+树不用平衡二叉树
干嘛的:数据库索引其实就是为了使查询数据效率快。
分类:
- 聚集索引(主键索引):在数据库里面,所有行数都会按照主键索引进行排序。
- 非聚集索引:就是给普通字段加上索引。
- 联合索引:就是好几个字段组成的索引,称为联合索引。
Mysql为什么最终选择了B+树作为索引的数据结构
1.B树能解决的问题,B+树都能解决,且能够更好的解决,降低了树的高度,增加节点的数据存储量。
2.B+树的扫库和扫表能力更强,如果根据索引去根据数据表扫描,对B树扫描,需要整颗树遍历,B+树只需要遍历所有的叶子节点
3.B+树的磁盘读写能力更强,根结点和支节点不保存数据区,所有的根结点和支节点天同样大小的情况下,保存的关键字更多,叶子结点不存子节点的引用,所以,B+树读写一次磁盘加载的关键字更多
4.B+树具有天然的排序功能
5.B+树的查询效率更加稳定,每次查询数据,查询IO次数是稳定的。
11、 B树和B+树的区别
1、B+树的关键字的搜索采用的是左闭合区间,之所以要这样是因为要最好的去支持自增的id,也是Mqsql设计的初衷,保证id=1命中的情况下,也去继续往下查找,直到找到叶子节点中1
2、B+树中的根结点和支节点中没有数据区,关键字对应的数据只保存在叶子节点中,所以只有叶子节点中的关键字数据区才会保存真正的数据内容或者数据对应的地址,但是在B树中,如果根结点命中,是直接返回的,B+树中,叶子节点不会保存子节点的引用
3、B+树的叶子节点是顺序排列的,并且相邻节点之间是顺序引用的关系,叶子节点之间通过指针相连
计算机组成原理
1、进程和线程区别
根本区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位
资源开销:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
包含关系:如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;
内存分配:同一进程的线程共享本进程的地址空间和资源,而进程之间的地址空间和资源是相互独立的
影响关系:一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
执行过程:每个独立的进程有程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,两者均可并发执行
2、线程有几种状态,运行态能变成就绪态吗
新建、就绪、运行、阻塞、死亡
3、产生死锁的四个必要条件
- 互斥条件:线程(进程)对于所分配到的资源具有排它性,即一个资源只能被一个线程(进程)占用,直到被该线程(进程)释放
- 请求与保持条件:一个线程(进程)因请求被占用资源而发生阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程(进程)已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:当发生死锁时,所等待的线程(进程)必定会形成一个环路(类似于死循环),造成永久阻塞
检测死锁的表可以用有向无环图实现
Nginx
异步,非阻塞,使用 epoll ,和大量细节处的优化
1、解释一下什么是Nginx
Nginx—Ngine X,是一款免费的、自由的、开源的、高性能HTTP服务器和反向代理服务器;也是一个IMAP、POP3、SMTP代理服务器;Nginx以其高性能、稳定性、丰富的功能、简单的配置和低资源消耗而闻名。
也就是说Nginx本身就可以托管网站(类似于Tomcat一样),进行Http服务处理,也可以作为反向代理服务器 、负载均衡器和HTTP缓存。
Nginx 解决了服务器的C10K(就是在一秒之内连接客户端的数目为10k即1万)问题。它的设计不像传统的服务器那样使用线程处理请求,而是一个更加高级的机制—事件驱动机制,是一种异步事件驱动结构。
2、Nginx的一些特性
- 跨平台:可以在大多数Unix like 系统编译运行。而且也有Windows的移植版本。
- 配置异常简单。
- 非阻塞、高并发连接:数据复制时,磁盘I/O的第一阶段是非阻塞的。官方测试能支持5万并发连接,实际生产中能跑2~3万并发连接数(得益于Nginx采用了最新的epoll事件处理模型(消息队列)。
- Nginx代理和后端Web服务器间无需长连接;
- Nginx接收用户请求是异步的,即先将用户请求全部接收下来,再一次性发送到后端Web服务器,极大减轻后端Web服务器的压力。
- 发送响应报文时,是边接收来自后端Web服务器的数据,边发送给客户端。
- 网络依赖性低,理论上只要能够ping通就可以实施负载均衡,而且可以有效区分内网、外网流量。
- 支持内置服务器检测。Nginx能够根据应用服务器处理页面返回的状态码、超时信息等检测服务器是否出现故障,并及时返回错误的请求重新提交到其它节点上。
3、Nginx VS Apache、Tomcat
1、Nginx/Apache 是Web Server,而Apache Tomact是一个servlet container
2、tomcat可以对jsp进行解析,nginx和apache只是web服务器,可以简单理解为只能提供html静态文件服务。
Nginx和Apache区别:
1)Nginx轻量级,同样起web 服务,比apache占用更少的内存及资源 。
2)Nginx 抗并发,nginx 处理请求是异步非阻塞的,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能 。
3)Nginx提供负载均衡,可以做做反向代理,前端服务器
4)Nginx多进程单线程,异步非阻塞;Apache多进程同步,阻塞。
4、在Nginx中,如何使用未定义的服务器名称阻止处理请求
只需将请求删除的服务器就可以定义为:
Server{ listen: 80; server_name ""; return 444;}
这里,服务器名被保留为一个空字符串,它将在没有“主机”头字段的情况下匹配请求,而一个特殊的Nginx的非标准代码444被返回,从而终止连接。
5、Nginx如何处理HTTP请求
Nginx 是一个高性能的 Web 服务器,能够同时处理大量的并发请求。它结合多进程机制和异步机制 ,异步机制使用的是异步非阻塞方式
1、多进程机制
服务器每当收到一个客户端时,就有 服务器主进程 ( master process )生成一个 子进程( worker process )出来和客户端建立连接进行交互,直到连接断开,该子进程就结束了。
使用进程的好处是各个进程之间相互独立,不需要加锁,减少了使用锁对性能造成影响,同时降低编程的复杂度,降低开发成本。其次,采用独立的进程,可以让进程互相之间不会影响 ,如果一个进程发生异常退出时,其它进程正常工作, master 进程则很快启动新的 worker 进程,确保服务不会中断,从而将风险降到最低。
缺点是操作系统生成一个子进程需要进行内存复制等操作,在资源和时间上会产生一定的开销。当有大量请求时,会导致系统性能下降 。
2、异步非阻塞机制
每个工作进程 使用 异步非阻塞方式 ,可以处理多个客户端请求 。
当某个 工作进程 接收到客户端的请求以后,调用 IO 进行处理,如果不能立即得到结果,就去处理其他请求 (即为非阻塞 );而客户端在此期间也无需等待响应 ,可以去处理其他事情(即为 异步 )。
当 IO 返回时,就会通知此 工作进程 ;该进程得到通知,暂时 挂起 当前处理的事务去 响应客户端请求 。
6、反向代理服务器的优点是什么
反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时
- 跨平台、配置简单
- 非阻塞、高并发 (处理 2-3 万并发连接数,官方监测能支持 5 万并发)
- 内存消耗小、且开源 (开启 10 个 Nginx 才占 150M 内存)
- 稳定性高,宕机概率小
7、Nginx的最佳用途
Nginx服务器的最佳用法是在网络上部署动态HTTP内容,使用SCGI、WSGI应用程序服务器、用于脚本的FastCGI处理程序。它还可以作为负载均衡器。
8、Nginx上的Master和Worker进程
-
Master进程:读取及评估配置和维持 -
Worker进程:处理请求 -
主程序 Master process 启动后,通过一个 for 循环来 接收和处理外部信号 ;
-
主进程通过 fork() 函数产生 worker 子进程 ,每个子进程执行一个 for循环来实现Nginx服务器对事件的接收和处理 。

一般推荐 worker 进程数与CPU内核数一致,这样一来不存在大量的子进程生成和管理任务,避免了进程之间竞争CPU 资源和进程切换的开销。而且 Nginx 为了更好的利用 多核特性 ,提供了 CPU 亲缘性的绑定选项,我们可以将某一个进程绑定在某一个核上,这样就不会因为进程的切换带来 Cache 的失效。
对于每个请求,有且只有一个工作进程 对其处理。首先,每个 worker 进程都是从 master进程 fork 过来。在 master 进程里面,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程。
所有 worker 进程的 listenfd 会在新连接到来时变得可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件前抢占 accept_mutex ,抢到互斥锁的那个进程注册 listenfd 读事件 ,在读事件里调用 accept 接受该连接。
当一个 worker 进程在 accept 这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端 ,最后才断开连接。这样一个完整的请求就是这样的了。我们可以看到,一个请求,完全由 worker 进程来处理,而且只在一个 worker 进程中处理。
在 Nginx 服务器的运行过程中, 主进程和工作进程 需要进程交互。交互依赖于 Socket 实现的管道来实现。
9、正向代理与反向代理
首先,代理服务器一般指局域网内部的机器通过代理服务器发送请求到互联网上的服务器,代理服务器一般作用在客户端。例如:GoAgent软件。我们的客户端在进行操作的时候,我们使用的正是正向代理,通过正向代理的方式,在我们的客户端运行一个软件,将我们的HTTP请求转发到其他不同的服务器端,实现请求的分发。
反向代理服务器作用在服务器端,它在服务器端接收客户端的请求,然后将请求分发给具体的服务器进行处理,然后再将服务器的相应结果反馈给客户端。Nginx就是一个反向代理服务器软件。
对比:
- 正向代理:前提知道正向代理服务器的IP地址,还有代理程序的端口
- 反向代理:与正向代理相反,对于客户端而言代理服务器就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理的命名空间(中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端。
10、将Nginx错误替换为502,503
502 =错误网关
503 =服务器超载
有可能,但是您可以确保fastcgi_intercept_errors被设置为ON,并使用错误页面指令。
Location / { fastcgi_pass 127.0.01:9001; fastcgi_intercept_errors on; error_page 502 = 503/error_page.html;}
11、在Nginx中,如何保留url中的双斜线
要在URL中保留双斜线,就必须使用merge_slashes_off;
语法:merge_slashes [on/off]
默认值: merge_slashes on
环境: http,server
12、ngx_http_upstream_module的作用
ngx_http_upstream_module用于定义可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组
13、解释C10K的问题
C10K问题是指无法同时处理大量客户端(10,000)的网络套接字
14、stub_status和sub_filter指令的作用是什么
Stub_status指令:该指令用于了解Nginx当前状态的当前状态,如当前的活动连接,接受和处理当前读/写/等待连接的总数;
Sub_filter指令:它用于搜索和替换响应中的内容,并快速修复陈旧的数据;
15、Nginx是否支持将请求压缩到上游
您可以使用Nginx模块gunzip将请求压缩到上游。gunzip模块是一个过滤器,它可以对不支持“gzip”编码方法的客户机或服务器使用“内容编码:gzip”来解压缩响应。
开启nginx gzip压缩后,图片、css、js等静态资源的大小会减小,可节省带宽,提高传输效率,但是会消耗CPU资源。
# 开启gzip gzip off; # 启用gzip压缩的最小文件,小于设置值的文件将不会压缩 gzip_min_length 1k; # gzip 压缩级别,1-9,数字越大压缩的越好,也越占用CPU时间,后面会有详细说明 gzip_comp_level 1; # 进行压缩的文件类型。javascript有多种形式。其中的值可以在 mime.types 文件中找到。 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png application/vnd.ms-fontobject font/ttf font/opentype font/x-woff image/svg+xml;
16、Nginx中获取当前时间
要获得Nginx的当前时间,必须使用SSI模块、$date_gmt和 $date_local的变量。
Proxy_set_header THE-TIME $date_gmt;
17、gastcgi与cgi的区别
1)cgi
web 服务器会根据请求的内容,然后会 fork 一个新进程来运行外部 c 程序(或 perl 脚本…), 这个进程会把处理完的数据返回给 web 服务器,最后 web 服务器把内容发送给用户,刚才 fork 的进程也随之退出。
如果下次用户还请求改动态脚本,那么 web 服务器又再次 fork 一个新进程,周而复始的进行。
2)fastcgi
web 服务器收到一个请求时,他不会重新 fork 一个进程(因为这个进程在 web 服务器启动时就开启了,而且不会退出),web 服务器直接把内容传递给这个进程(进程间通信,但 fastcgi 使用了别的方式,tcp 方式通信),这个进程收到请求后进行处理,把结果返回给 web 服务器,最后自己接着等待下一个请求的到来,而不是退出。
综上,差别在于是否重复 fork 进程,处理请求。
18、Nginx常用命令
- 启动 nginx 。
- 停止
nginx -s stop或nginx -s quit。 - 重载配置
./sbin/nginx -s reload(平滑重启) 或service nginx reload。 - 重载指定配置文件
.nginx -c /usr/local/nginx/conf/nginx.conf。 - 查看 nginx 版本
nginx -v。 - 检查配置文件是否正确
nginx -t。 - 显示帮助信息
nginx -h。
19、Nginx常用配置
worker_processes 8; # 工作进程个数worker_connections 65535; # 每个工作进程能并发处理(发起)的最大连接数(包含所有连接数)error_log /data/logs/nginx/error.log; # 错误日志打印地址access_log /data/logs/nginx/access.log; # 进入日志打印地址log_format main '$remote_addr"$request" ''$status $upstream_addr "$request_time"'; # 进入日志格式## 如果未使用 fastcgi 功能的,可以无视fastcgi_connect_timeout=300; # 连接到后端 fastcgi 超时时间fastcgi_send_timeout=300; # 向 fastcgi 请求超时时间(这个指定值已经完成两次握手后向fastcgi传送请求的超时时间)fastcgi_rend_timeout=300; # 接收 fastcgi 应答超时时间,同理也是2次握手后fastcgi_buffer_size=64k; # 读取 fastcgi 应答第一部分需要多大缓冲区,该值表示使用1个64kb的缓冲区读取应答第一部分(应答头),可以设置为fastcgi_buffers选项缓冲区大小fastcgi_buffers 4 64k; # 指定本地需要多少和多大的缓冲区来缓冲fastcgi应答请求,假设一个php或java脚本所产生页面大小为256kb,那么会为其分配4个64kb的缓冲来缓存fastcgi_cache TEST; # 开启fastcgi缓存并为其指定为TEST名称,降低cpu负载,防止502错误发生listen 80; # 监听端口server_name rrc.test.jiedaibao.com; # 允许域名root /data/release/rrc/web; # 项目根目录index index.php index.html index.htm; # 访问根文件
20、Nginx 如何处理 HTTP 请求
- Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程;
- master 接收来自外界的信号,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程,然后向各worker进程发送信号,每个进程都有可能来处理这个连接;
- 所有 worker 进程的 listenfd 会在新连接到来时变得可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件前抢占 accept_mutex ,抢到互斥锁的那个进程注册 listenfd 读事件 ,在读事件里调用 accept 接受该连接;
- 当一个 worker 进程在 accept 这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端 ,最后才断开连接。
21、Nginx为什么不用多线程
Apache: 创建多个进程或线程,而每个进程或线程都会为其分配 cpu 和内存(线程要比进程小的多,所以 worker 支持比 perfork 高的并发),并发过大会榨干服务器资源。
Nginx: 采用单线程来异步非阻塞处理请求(管理员可以配置 Nginx 主进程的工作进程的数量)(epoll),不会为每个请求分配 cpu 和内存资源,节省了大量资源,同时也减少了大量的 CPU 的上下文切换。所以才使得 Nginx 支持更高的并发。
Netty、Redis 基本采用相同思路
22、Nginx负载均衡的方式
1、轮询(默认) round_robin
每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
upstream backserver { server 192.168.0.14; server 192.168.0.15;}
2、权重weight
指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
upstream backserver { server 192.168.0.14 weight=3; server 192.168.0.15 weight=7;}
3、IP哈希ip_hash
上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。
我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
upstream backserver { ip_hash; server 192.168.0.14:88; server 192.168.0.15:80;}
4、最少连接least_conn
下一个请求将被分派到活动连接数量最少的服务器
23、Nginx -s 的目的是什么
用于运行Nginx -s参数的可执行文件
24、ngx_http_upstream_module模块了解吗
ngx_http_upstream_module模块用于将多个服务器定义成服务器组,可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组。
比如访问www.a.com 缓存+调度:
http{ proxy_cache_path /var/cache/nginx/proxy_cache levels=1:2:2 keys_zone=proxycache:20m inactive=120s max_si #缓存ze=1g; upstream mysqlsrvs{ ip_hash; #源地址hash调度方法 写了backup就不可用 server 172.18.99.1:80 weight=2; #weight权重 server 172.18.99.2:80; #标记down,配合ip_hash使用,实现灰度发布 server 172.18.99.3:80 backup; #backup将服务器标记为“备用”,即所有服务器均不可用时才启用 }}server{ server_name www.a.com; proxy_cache proxycache; proxy_cache_key $request_uri; proxy_cache_valid 200 302 301 1h; proxy_cache_valid any 1m; location / { proxy_pass http://mysqlsrvs; }}
25、限流了解吗,怎么做
Nginx 提供两种限流方式,一是控制速率,二是控制并发连接数。
1、控制速率
ngx_http_limit_req_module 模块提供了漏桶算法(leaky bucket),可以限制单个IP的请求处理频率。
正常限流
http { limit_req_zone 192.168.1.1 zone=myLimit:10m rate=5r/s;}server { location / { limit_req zone=myLimit; rewrite / http://www.hac.cn permanent; }}key: 定义需要限流的对象。zone: 定义共享内存区来存储访问信息。rate: 用于设置最大访问速率。表示基于客户端192.168.1.1进行限流,定义了一个大小为10M,名称为myLimit的内存区,用于存储IP地址访问信息。rate设置IP访问频率,rate=5r/s表示每秒只能处理每个IP地址的5个请求。Nginx限流是按照毫秒级为单位的,也就是说1秒处理5个请求会变成每200ms只处理一个请求。如果200ms内已经处理完1个请求,但是还是有有新的请求到达,这时候Nginx就会拒绝处理该请求。
突发流量限制访问频率
上面rate设置了 5r/s,如果有时候流量突然变大,超出的请求就被拒绝返回503了,突发的流量影响业务就不好了。
这时候可以加上burst 参数,一般再结合 nodelay 一起使用。
server { location / { limit_req zone=myLimit burst=20 nodelay; rewrite / http://www.hac.cn permanent; }}burst=20 nodelay 表示这20个请求立马处理,不能延迟,相当于特事特办。不过,即使这20个突发请求立马处理结束,后续来了请求也不会立马处理。burst=20 相当于缓存队列中占了20个坑,即使请求被处理了,这20个位置这只能按 100ms一个来释放。
2、控制并发连接数
ngx_http_limit_conn_module 提供了限制连接数功能。
limit_conn_zone $binary_remote_addr zone=perip:10m;limit_conn_zone $server_name zone=perserver:10m;server { ... limit_conn perip 10; limit_conn perserver 100;}limit_conn perip 10 作用的key 是 $binary_remote_addr,表示限制单个IP同时最多能持有10个连接。limit_conn perserver 100 作用的key是 $server_name,表示虚拟主机(server) 同时能处理并发连接的总数。
3、对白名单以外的IP限流
如果不想做限流,还可以设置白名单:
利用 Nginx ngx_http_geo_module 和 ngx_http_map_module 两个工具模块提供的功能。
##定义白名单ip列表变量geo $limit { default 1; 10.0.0.0/8 0; 192.168.0.0/10 0; 81.56.0.35 0;}map $limit $limit_key { 0 ""; 1 $binary_remote_addr;}# 正常限流设置limit_req_zone $limit_key zone=myRateLimit:10m rate=10r/s;
除此之外:
ngx_http_core_module 还提供了限制数据传输速度的能力(即常说的下载速度)
location /flv/ { flv; limit_rate_after 500m; limit_rate 50k;}
针对每个请求,表示客户端下载前500m的大小时不限速,下载超过了500m后就限速50k/s。
Docker
1、什么是Docker
Docker是一个容器化平台,它以容器的形式将您的应用程序及其所有依赖项打包在一起,以确保您的应用程序在任何环境中无缝运行。
2、Docker VS 虚拟机
优点
- 容器提供实时配置和可伸缩性,但虚拟机提供缓慢的配置
- 与虚拟机相比,容器轻巧
- 与容器相比,VM的性能有限
- 与VM相比,容器具有更好的资源利用率
Docker不是虚拟化方法。它依赖于实际实现基于容器的虚拟化或操作系统级虚拟化的其他工具。为此,Docker最初使用LXC驱动程序,然后移动到libcontainer现在重命名为runc。Docker主要专注于在应用程序容器内自动部署应用程序。应用程序容器旨在打包和运行单个服务,而系统容器则设计为运行多个进程,如虚拟机。因此,Docker被视为容器化系统上的容器管理或应用程序部署工具。
- 容器不需要引导操作系统内核,因此可以在不到一秒的时间内创建容器。此功能使基于容器的虚拟化比其他虚拟化方法更加独特和可取。
由于基于容器的虚拟化为主机增加了很少或没有开销,因此基于容器的虚拟化具有接近本机的性能。 - 对于基于容器的虚拟化,与其他虚拟化不同,不需要其他软件。
- 主机上的所有容器共享主机的调度程序,从而节省了额外资源的需求。
- 与虚拟机映像相比,容器状态(Docker或LXC映像)的大小很小,因此容器映像很容易分发。
- 容器中的资源管理是通过cgroup实现的。Cgroups不允许容器消耗比分配给它们更多的资源。虽然主机的所有资源都在虚拟机中可见,但无法使用。这可以通过在容器和主机上同时运行top或htop来实现。所有环境的输出看起来都很相似。
3、Docker容器之间如何实现隔离
- 使用Namespaces实现了系统环境的隔离,Namespaces允许一个进程以及它的子进程从共享的宿主机内核资源(网络栈、进程列表、挂载点等)里获得一个仅自己可见的隔离区域,让同一个Namespace下的所有进程感知彼此变化,对外界进程一无所知,仿佛运行在一个独占的操作系统中;
- 使用CGroups限制这个环境的资源使用情况,比如一台16核32GB的机器上只让容器使用2核4GB。使用CGroups还可以为资源设置权重,计算使用量,操控任务(进程或线程)启停等;
- 使用镜像管理功能,利用Docker的镜像分层、写时复制、内容寻址、联合挂载技术实现了一套完整的容器文件系统及运行环境,再结合镜像仓库,镜像可以快速下载和共享,方便在多环境部署。
4、镜像分层
Docker 支持通过扩展现有镜像,创建新的镜像。实际上,Docker Hub 中 99% 的镜像都是通过在 base 镜像中安装和配置需要的软件构建出来的。比如我们现在构建一个新的镜像,Dockerfile 如下:

① 新镜像不再是从 scratch 开始,而是直接在 Debian base 镜像上构建。
② 安装 emacs 编辑器。
③ 安装 apache2。
④ 容器启动时运行 bash。
构建过程如下图所示:

可以看到,新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。为什么 Docker 镜像要采用这种分层结构呢?
最大的一个好处就是 - 共享资源。
比如:有多个镜像都从相同的 base 镜像构建而来,那么 Docker Host 只需在磁盘上保存一份 base 镜像(因为镜像的ID唯一);同时内存中也只需加载一份 base 镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享,我们将在后面更深入地讨论这个特性。
这时可能就有人会问了:如果多个容器共享一份基础镜像,当某个容器修改了基础镜像的内容,比如 /etc 下的文件,这时其他容器的 /etc 是否也会被修改?
答案是不会!修改会被限制在单个容器内。这就是我们接下来要学习的容器 Copy-on-Write 特性。
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
5、Docker容器退出时是否会丢失数据
不会,当Dcoker容器退出时,不会丢失数据。应用程序写入磁盘的所有数据都会保留在其容器中,直到您明确删除该容器为止。即使在容器停止后,该容器的文件系统仍然存在。
6、Docker容器运行的集中状态
运行、已暂停、重新启动、已退出
7、Dockerfile常见的命令是什么
Dockerfile中的一些常用指令如下:FROM:指定基础镜像LABEL:功能是为镜像指定标签RUN:运行指定的命令CMD:容器启动时要运行的命令
8、Dockerfile中的命令COPY和ADD区别
COPY与ADD的区别COPY的只能是本地文件,其他用法一致
9、Docker常用的命令
docker pull 拉取或者更新指定镜像docker push 将镜像推送至远程仓库docker rm 删除容器docker rmi 删除镜像docker images 列出所有镜像docker ps 列出所有容器
10、容器互相访问方式
详细参考:https://blog.csdn.net/qq_38234785/article/details/118459700
1、虚拟IP
安装docker时,docker会默认创建一个内部的桥接网络docker0,每创建一个容器分配一个虚拟网卡,容器之间可以根据ip互相访问。
2、link
运行容器的时候加上参数link
运行第一个容器docker run -it --name centos-1 docker.io/centos:latest运行第二个容器[root@CentOS ~]# docker run -it --name centos-2 --link centos-1:centos-1 docker.io/centos:latest
–link:参数中第一个centos-1是容器名,第二个centos-1是定义的容器别名(使用别名访问容器),为了方便使用,一般别名默认容器名。
3、创建bridge网络
创建bridge网络:docker network create testnet查询新建的网络:docker network ls查看网桥下的容器ip信息: docker network inspect dyl_testnet使用方法:docker run -it --name <容器名> —network --network-alias <网络别名> <镜像名>
推荐使用这种方法,自定义网络,因为使用的是网络别名,可以不用顾虑ip是否变动,只要连接到docker内部bright网络即可互访。bridge也可以建立多个,隔离在不同的网段。
Redis
考察点:概述、数据类型、持久化、过期键删除策略、内存相关、线程模型、集群方案、分区、分布式、缓存异常
1、Redis是什么
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射,支持五种数据类型:符串string、列表list、集合set、散列表hash、有序集合zset。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
2、Redis的优缺点
优点
- 读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
- 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
缺点
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
- Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
3、为什么用缓存?为什么用Redis做缓存?
高性能、高并发
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
4、Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路 I/O 复用模型,非阻塞 IO;
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
5、Redis的删除策略有哪些
定时删除、定期删除、惰性删除
-
定时删除
优点:对内存友好,定时删除策略可以保证过期键会尽可能快地被删除,并释放国期间所占用的内存。
缺点:在内存不紧张但CPU时间紧张的情况下,将CPU时间用在删除和当前任务无关的过期键上,影响服务器的响应时间和吞吐量。
-
定期删除
由于定时删除会占用太多CPU时间,影响服务器的响应时间和吞吐量以及惰性删除浪费太多内存,有内存泄露的危险,所以出现一种整合和折中这两种策略的定期删除策略。定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
-
惰性删除
优点:对CPU时间友好,在每次从键空间获取键时进行过期键检查并是否删除,删除目标也仅限当前处理的键,这个策略不会在其他无关的删除任务上花费任何CPU时间。
缺点:对内存不友好,过期键过期也可能不会被删除,导致所占的内存也不会释放。甚至可能会出现内存泄露的现象,当存在很多过期键,而这些过期键又没有被访问到,这会可能导致它们会一直保存在内存中,造成内存泄露。
7、watch 命令的作用是什么
通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,同时返回Null multi-bulk应答以通知调用者事务执行失败。
在多连接的情况下,防止多个客户端对资源进行争抢,对资源进行修改错误。例如:客户端A和B都在同一时刻读取了mkey的原有值,假设该值为9,此后两个客户端又均将该值加一后set回Redis服务器,这样就会导致mkey的结果为10,而不是我们认为的11。所以我们借助命令watch,解决此问题,伪代码:
WATCH mkey
val = GET mkey
val = val + 1
MULTI
SET mkey $val
EXEC
# 先通过watch监控此键,然后将对mkey的修改放入事务中,这样就可以有效的保证每个连接在执行EXEC之前,如果当前连接获取的mkey的值被其它连接的客户端修改,那么当前连接的EXEC命令将执行失败。这样调用者在判断返回值后就可以获悉val是否被重新设置成功
8、如何使用Redis实现分布式锁
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。但是,如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?这会导致锁就永远得不到释放了。set指令有非常复杂的参数,可以同时把setnx和expire合成一条指令来使用,如下所示:
String set(String key, String value, String nxxx, String expx, long time);
该方法是:存储数据到缓存中,并制定过期时间和当Key存在时是否覆盖。
**nxxx:**只能取NX或者XX,如果取NX,则只有当key不存在是才进行set,如果取XX,则只有当key已经存在时才进行set
**expx:**只能取EX或者PX,代表数据过期时间的单位,EX代表秒,PX代表毫秒。
**time:**过期时间,单位是expx所代表的单位。
9、Redis持久化
Redis实现持久化有两种方法:RDB快照和AOF。
- ROB快照持久化
Redis默认采用RDB快照做数据持久化的,它把内存的数据写入本地的二进制文件dump.rdb中。在生成快照时,Redis将当前进程fork出一个子进程,然后在子进程中循环所有的数据,将数据写进dump.rdb文件,使用redis的save命令可调用这个过程。
- AOF
AOF日志的全称是append only file,从名字上我们就能看出来,它是一个追加写入的日志文件。在使用AOF时,Redis会将每一个收到的写命令都通过write函数追加到文件中,当Redis重启时会通过重新执行文件中保存的写命令来在内存中重建整个数据库的内容。我们可以在配置文件中通过配置告诉Redis我们想要使用fsync函数强制写入到磁盘的时间。
ROB快照持久化的优缺点:
(1)RDB是一个非常紧凑的文件,它保存了某个时间点的数据集,非常适用于数据集的备份。
(2)RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化Redis的性能。
一旦数据库出现问题,那么我们的dump.rdb文件中保存的数据并不是全新的,从上次dump.rdb文件生成到Redis停机这段时间的数据全部丢掉了。
AOF持久化的优缺点:
使用AOF会更加及时地持久化数据。
在写入内存数据的同时将操作命令保存到日志文件,在一个并发更改非常高的系统中,命令日志是一个非常庞大的数据,管理维护成本非常高。
RDB和AOF两者配合
**RDB做镜像全量持久化,AOF做增量持久化。**因为RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要AOF来配合使用。在Redis实例重启时,会使用RDB持久化文件重新构建内存,再使用AOF重放近期的操作指令来实现完整恢复重启之前的状态。
10、Redis架构模式
单机版、主从复制(哨兵模式,集群模式)
-
单机版
简单,但是内存有限、处理能力有限、无法高可用
-
主从复制
-
哨兵模式
- 监控(Monitoring):Sentinel会不断地检查主服务器和从服务器是否运作正常。
- 告警(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作。
特点:1、保证高可用 2、监控各个节点 3、自动故障迁移
缺点:1、主从模式,切换需要时间丢数据 2、没有解决主库的写压力
-
集群模式
- Redis最开始使用主从模式做集群,若master宕机需要手动配置slave转为master;后来为了高可用提出来哨兵模式,该模式下有一个哨兵监视master和slave,若master宕机可自动将slave转为master,但它也有一个问题,就是不能动态扩充;所以在Redis 3.x提出cluster集群模式。
-
11、保证Redis中存放的都是热点数据
redis内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
当内存不足时候,内存淘汰策略如下
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
全局的键空间选择性移除
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。(这个是最常用的)
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
设置过期时间的键空间选择性移除
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
12、Redis事务
Redis作为NoSQL数据库也同样提供了事务机制。一个事务从开始到执行会经历以下三个阶段:开始事务->命令入队->执行事务。具体执行过程如下所示:
(1)批量操作在发送 EXEC 命令前被放入队列缓存。
(2)收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行。
(3)在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
在Redis中,MULTI/EXEC/DISCARD/WATCH这四个命令是我们实现事务的基石。
注意:单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务支持隔离码?
Redis 是单进程程序,并且它保证在执行事务时,不会对事务进行中断,事务可以运行直到执行完所有事务队列中的命令为止。因此,Redis 的事务是总是带有隔离性的。
Redis事务保证原子性吗,支持回滚吗?
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
13、Reids内存方面
(1)Redis主要消耗什么物理资源?
内存。
(2)Redis的内存用完了会发生什么?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
(3)Redis如何做内存优化?
可以好好利用Hash,list,sorted set,set等集合类型数据,因为通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面
14、Redis分区
(1)提高多核CPU的利用率
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
(2)Redis分区
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
(3)分区方案
-
客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
-
代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
-
查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
(4)Redis分区有什么缺点?
- 涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
- 同时操作多个key,则不能使用Redis事务.
- 分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集
- 当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。
- 分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
15、缓存
(1)雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
- 给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
(2)穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
(3)击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案
- 设置热点数据永远不过期。
- 加互斥锁,互斥锁
16、Redis与Memcached的区别
两者都是非关系型内存键值数据库,现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!Redis 与 Memcached 主要有以下不同:
| 对比参数 | Redis | Memcached |
|---|---|---|
| 类型 | 1.支持内存 2.非关系型数据库 |
1.支持内存 2.非关系型数据库 3.缓存形式 |
| 数据类型 | String、List、Set、Sort Set、Hash | 文本、二进制类型 |
| 查询操作 | 批量操作、支持事务、类型对应CRUD | 常用CRUD、少量其他命令 |
| 附加功能 | 1.发布订阅模式 2.主从分区 3.支持序列化 4.Lua脚本 |
支持多线程服务 |
| 网络IO模型 | 单线程的多路 , IO复用模型 | 多线程,非阻塞IO模型 |
| 持久化 | ROB、BOF | 不支持 |
| 适用场景 | 复杂数据结构、有持久化、高可用、valu内容大 | 纯key-value,数据量非常大,并发量非常大 |
17、Redis使用
(1)一个字符串最大容量
512M
(2)Redis如何做大量数据插入
Redis2.6开始redis-cli支持一种新的被称之为pipe mode的新模式用于执行大量数据插入工作。
(3)找固定开头的key
假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
(4)Redis做异步队列
使用list类型保存数据信息,rpush生产消息,lpop消费消息,当lpop没有消息时,可以sleep一段时间,然后再检查有没有信息,如果不想sleep的话,可以使用blpop, 在没有信息的时候,会一直阻塞,直到信息的到来。redis可以通过pub/sub主题订阅模式实现一个生产者,多个消费者,当然也存在一定的缺点,当消费者下线时,生产的消息会丢失。
(5)Redis如何实现延时队列
使用sortedset,使用时间戳做score, 消息内容作为key,调用zadd来生产消息,消费者使用zrangbyscore获取n秒之前的数据做轮询处理。
(6)Redis回收进程如何工作的
-
一个客户端运行了新的命令,添加了新的数据。
-
Redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
-
一个新的命令被执行,等等。
-
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
(7)Redis回收算法
LRU算法
智力题
1、面粉题
9000g面粉,有50g和200g面粉,一个天平,怎么样三次内获得2000g面粉
常考算法
1、最长回文数
import java.util.*;public class Solution { public int getLongestPalindrome(String A, int n) { // write code here int maxL = 0; for(int i = 0; i < (n - 1) * 2; i++){ int left = (int)Math.floor(i * 0.5); int right = (int)Math.ceil(0.5 * i); while(left >= 0 && right <= n-1 && A.charAt(left) == A.charAt(right)){ left--; right++; } maxL = right - left - 1 > maxL ? right - left - 1 : maxL; } return maxL; } }
2、接雨水(NC128)
class Solution { public int trap(int[] height) { int left = 0; int right = height.length - 1; int maxLeftHeight = 0; int maxrightHeight = 0; int result = 0; while(left < right){ if(height[left] <= height[right]){ maxLeftHeight = Math.max(maxLeftHeight, height[left]); result += maxLeftHeight - height[left]; left++; }else{ maxrightHeight = Math.max(maxrightHeight, height[right]); result += maxrightHeight - height[right]; right--; } } return result; }}
4、红包金额分赔算法
5、字符串压缩
aaabbac - > 3a2bac
6、括号匹配(NC52)
import java.util.*;public class Solution { /** * @param s string字符串 * @return bool布尔型 */ public boolean isValid (String s) { // write code here Stack st = new Stack(); for(char item : s.toCharArray()){ if(item == '(') st.push(')'); else if(item == '[') st.push(']'); else if(item == '{') st.push('}'); else if(st.empty() || st.pop() != item) return false; } return st.empty(); }}
7、最长回文串
字符串全排列(JZ27)
import java.util.ArrayList;public class Solution { public ArrayList<String> resultList = new ArrayList<>(); public void func(StringBuilder resultStr, StringBuilder targetStr){ if(targetStr.length() == 0 && !resultList.contains(resultStr.toString())){ resultList.add(resultStr.toString()); return ; } for(int i = 0; i < targetStr.length(); i++){ StringBuilder tempa = new StringBuilder(resultStr); StringBuilder tempb = new StringBuilder(targetStr); tempa.append(targetStr.charAt(i)); tempb.deleteCharAt(i); func(tempa, tempb); } return ; } public ArrayList<String> Permutation(String str) { func(new StringBuilder(str.length()), new StringBuilder(str)); return resultList; }}
8、链表排序(NC70)
import java.util.*;/* * public class ListNode { * int val; * ListNode next = null; * } */public class Solution { /** * * @param head ListNode类 the head node * @return ListNode类 */ public ListNode sortInList (ListNode head) { // write code here ListNode firstPoint = null; ListNode secondePoint; // 使用冒泡排序,只对其中的数据部分进行交换 while(firstPoint != head.next){ secondePoint = head; while(secondePoint.next != firstPoint){ if(secondePoint.val > secondePoint.next.val){ int temp = secondePoint.val; secondePoint.val = secondePoint.next.val; secondePoint.next.val = temp; } secondePoint = secondePoint.next; } firstPoint = secondePoint; } return head; }}
9、合并两个有序链表(NC33)
import java.util.*;/* * public class ListNode { * int val; * ListNode next = null; * } */public class Solution { /** * @param l1 ListNode类 * @param l2 ListNode类 * @return ListNode类 */ public ListNode mergeTwoLists (ListNode l1, ListNode l2) { // write code here if(l1 == null) return l2; if(l2 == null) return l1; ListNode l0 = new ListNode(0); // 额外增加一个新节点 ListNode p = l0; while(l1 != null && l2 != null){ if(l1.val > l2.val){ p.next = l2; l2 = l2.next; }else{ p.next = l1; l1 = l1.next; } p = p.next; } if(l1 != null) p.next = l1; if(l2 != null) p.next = l2; return l0.next; }}
10、两个链表相加(NC40)
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* }
*/
public class Solution {
/**
*
* @param head1 ListNode类
* @param head2 ListNode类
* @return ListNode类
*/
public ListNode addInList (ListNode head1, ListNode head2) {
// write code here
if(head1 == null) return head2;
if(head2 == null) return head1;
head1 = reverseList(head1);
head2 = reverseList(head2);
int jinWei = 0; // 进位标识符
int sum;
ListNode resultList = new ListNode(0); // 增加一个空白节点,方便插入
ListNode p = resultList; // 空白链表的指针方便往后移动
while(head1 != null || head2 != null){
sum = jinWei;
ListNode tempNode = head1; // 将两个数的余数,存放在之前的节点中(不额外生成节点,默认是链表1中的节点)
if(head1 != null){
sum += head1.val;
head1 = head1.next;
}
if(head2 != null){
sum += head2.val;
tempNode = head2;
head2 = head2.next;
}
tempNode.val = sum % 10;
jinWei = sum / 10;
p.next = tempNode;
p = p.next;
}
// 如果两个链表遍历完了,还有进位,就为其新生成一个节点,插入进去
if(jinWei == 1) p.next = new ListNode(1);
return reverseList(resultList.next);
}
/**
* 链表反转
*/
public ListNode reverseList(ListNode l){
ListNode p = l.next;
l.next = null;
while(p != null){
ListNode temp = p;
p = p.next;
temp.next = l;
l = temp;
}
return l;
}
}
删除链表的倒数第n个节点(NC53)
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* }
*/
public class Solution {
/**
*
* @param head ListNode类
* @param n int整型
* @return ListNode类
*/
public ListNode removeNthFromEnd (ListNode head, int n) {
// write code here
ListNode resultNode = new ListNode(0);
resultNode.next = head;
ListNode firstPoint = resultNode;
ListNode seconedPoint = resultNode;
for(int i = 0; i <= n; i++)
firstPoint = firstPoint.next;
while(firstPoint != null){
firstPoint = firstPoint.next;
seconedPoint = seconedPoint.next;
}
seconedPoint.next = seconedPoint.next.next;
return resultNode.next;
}
}
大数加法(NC1)
原理都是遍历两个字符串或者链表,和上题类似
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
* 计算两个数之和
* @param s string字符串 表示第一个整数
* @param t string字符串 表示第二个整数
* @return string字符串
*/
public String solve (String s, String t) {
// write code here
int sL = s.length() - 1;
int tL = t.length() - 1;
StringBuilder resultStr = new StringBuilder(Math.max(sL, tL) + 1);
int jinWei = 0;
int sum;
while(sL >= 0 || tL >= 0){
sum = jinWei;
if(sL >= 0){
sum += s.charAt(sL) - '0';
sL--;
}
if(tL >= 0){
sum += t.charAt(tL) - '0';
tL--;
}
resultStr.append((sum % 10) + "");
jinWei = sum / 10;
}
if(jinWei == 1) resultStr.append("1");
return resultStr.reverse().toString();
}
}
寻找第K大(NC88)
import java.util.*;
public class Solution {
// 传统的 partition 算法
public int patition(int[] a, int left, int right, int K){
if(left > right)
return -1;
int leftPoint = left;
int rightPoint = right;
int shaoBing = a[leftPoint];
while(leftPoint < rightPoint){
while(leftPoint < rightPoint && a[rightPoint] >= shaoBing)
rightPoint--;
a[leftPoint] = a[rightPoint];
while(leftPoint < rightPoint && a[leftPoint] <= shaoBing)
leftPoint++;
a[rightPoint] = a[leftPoint];
}
a[leftPoint] = shaoBing;
if(leftPoint == K) return a[leftPoint];
else if (leftPoint > K) return patition(a, left, leftPoint - 1, K);
else return patition(a, leftPoint + 1, right, K);
}
public int findKth(int[] a, int n, int K) {
// 转化为求解升序数组中,排在第n-k的数
return patition(a, 0, n-1,n-K);
}
}
求二叉树的层序遍历(NC15)
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* }
*/
public class Solution {
/**
*
* @param root TreeNode类
* @return int整型ArrayList>
*/
public ArrayList<ArrayList<Integer>> levelOrder (TreeNode root) {
// write code here
if(root == null)
return new ArrayList<>();
Queue<TreeNode> q = new LinkedList<TreeNode>();
ArrayList<ArrayList<Integer>> resultList = new ArrayList<>();
ArrayList<Integer> tempList = new ArrayList<>();
TreeNode flage = null;
q.offer(root);
q.offer(flage);
while(!q.isEmpty()){
TreeNode t = q.poll();
if(t != null){
if (t.left != null ) q.offer(t.left);
if (t.right != null ) q.offer(t.right);
tempList.add(t.val);
}else{
resultList.add(new ArrayList<>(tempList));
if(q.isEmpty()) break;
q.offer(t);
tempList.clear();
}
}
return resultList;
}
}
最长公共前缀(NC55)
import java.util.*;
public class Solution {
/**
*
* @param strs string字符串一维数组
* @return string字符串
*/
public String longestCommonPrefix (String[] strs) {
// write code here
if(strs.length == 0)
return "";
int L = 0;
for(int i = 0; i < strs[0].length(); i++){
Character c = strs[0].charAt(i);
for(int j = 0; j < strs.length; j ++){
if(strs[j].length() <= i || strs[j].charAt(i) != c)
return strs[0].substring(0, L);
}
L++;
}
return strs[0].substring(0, L);
}
}
买卖股票的最好时机
import java.util.*;
public class Solution {
/**
* @param prices int整型一维数组
* @return int整型
*/
public int maxProfit (int[] prices) {
// write code here
int max = 0;
int currentmax = 0;
for(int i = 1; i < prices.length; i++){
currentmax += prices[i] - prices[i - 1];
if(currentmax < 0)
currentmax = 0;
else
max = max > currentmax ? max : currentmax;
}
return max;
}
}
二分查找-II(NC105)
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 如果目标值存在返回下标,否则返回 -1
* @param nums int整型一维数组
* @param target int整型
* @return int整型
*/
public int search (int[] nums, int target) {
// write code here
return serch2(0, nums.length - 1, nums, target );
}
public int serch2(int left, int right, int[] nums, int target){
if(left > right)
return -1;
int mind = (int)((left + right) / 2);
if(nums[mind] > target)
return serch2(left, mind - 1, nums, target );
else if(nums[mind] < target)
return serch2(mind + 1, right, nums, target );
else{
int firstIndex = mind;
// 往前找第一个位置
while(firstIndex >= 0 && nums[mind] == nums[firstIndex]){
firstIndex--;
}
return firstIndex + 1;
}
}
}