Java常识
文章目录
- -33
- -32 tomcat
-
- -32.1 tomcat spring项目启动入口
- -32.2 tomcat catalina 是什么
- -32.3 tomcat的类加载
- -31 `MANIFEST.MF `
- -30 FileChannel.transfer
- -29 Class.getResource() V.S. Classloader.getResource()
- -28 SQL_CALC_FOUND_ROWS
- -27 如何在代码中获取一个sdk的版本
- -26 如何从包装的异常中抽取内部异常
- -25 慎重命名为xxxHelper
- -24 java 进程的关闭
- -23 版本不兼容的一个解决思路
- -22 位运算
- -21 如何让list按指定顺序排
- -20 C1 C2编译
- -19
- -18
- -17 线程池异术
-
- -17.1 线程池coreSize=0会发生啥
- -17.2 线程池公用的暗坑
- -17.3 线程的异常
- -17.4 线程池中线程的异常
- -17.5 submit()任务的异常要主动抓取或者try catch 打印
- -16
- -15
- -14
- -13 如何动态修改线上日志打印级别
- -12 如何起一个内嵌的web容器
- -11 如何从文件末尾开始读一行
- -10 获取test/resources/下面的文件
- -9 logback中如何延时关闭`appender`
- -8 DNS缓存在哪里?
- -7 父子类有相同的字段, 那么getter 会取到谁的字段?
- -6 数据字典(常量)的维护 / java8 JAXB
- -5. 为何不推荐JDK的序列化
- -4. 胖客户端/ 瘦客户端
- -3.String.getBytes()
- -2. Java中数组是对象吗?
- -1. volatile tips
- 0. 原子性和线程安全
- 1.如何监听一个文件的CRUD
- 2. 如何显示默认的Java程序JVM参数
- 3. Side effect
- 4. btrace greys arthas
- 5. 锁定义的小技巧
- 6. 约定俗成的命名习惯
-33
-32 tomcat
-32.1 tomcat spring项目启动入口
突然想到,一个spring-web(非springboot-web) 打包成war,如何被tomcat拉起来?
原因在 web.xml:
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListenerlistener-class>
listener>
-32.2 tomcat catalina 是什么
catalina是tomcat 的一部分,也是其核心组件.
p.s. 如果需要系统了解下tomcat,可以看其官网,十分详尽;
如果需要深入Classloader,tomcat的实现方式(破坏双亲委派)也很独特。

-32.3 tomcat的类加载
tomcat的类加载比较特殊,因其支持一个进程起多个应用 【实际上极少会有人这样部署,这纯粹是项目人为加风险】,
每个应用的包版本可能不同,如果使用一般应用的类加载机制,极易遇到类冲突,所以tomcat8 默认情况下是打破了双亲委派机制,但也提供了配置来关闭该特性。
默认情况下,tomcat的class加载顺序是
1 使用bootstrap引导类加载器加载 (JVM 的东西 )
2 使用system系统类加载器加载 (tomcat的启动类Bootstrap包)
3 使用WebAppClassLoader 加载 WEB-INF/classes (应用自定义的class) 【key point】
4 使用WebAppClassLoader 加载在WEB-INF/lib (应用的依赖包) 【key point】
5 使用common类加载器在CATALINA_HOME/lib中加载 (tomcat的依赖包,公共的,被各个应用共享的)
为啥要记录下这点,这提供了一个hack的方法:假如有个年久失修、没有源码的三方包在WEB-INF/lib,某个类有bug,除了 继承等常规手段外,还能手搓个同包名、类名的类。打包后,这个类会出现在 WEB-INF/classes里,由于其加载优先级更高,会被先加载到,这样会事实上覆盖了WEB-INF/lib中的类。
这个方法在tomcat下能成,但建议慎用。
see also
-31 MANIFEST.MF
MANIFEST 文件是 JAR 归档中所包含的特殊文件,MANIFEST 文件被用来定义扩展或文件打包相关数据
- Main-Class 指定程序的入口
- Class-Path 指定jar包的依赖关系,class loader会依据这个路径来搜索class
- spring boot包里这个文件可能还有
Implementation-Version等信息
jdk提供了JarFile可读到其中内容。利用这点可以在代码中获取到当前SDK的版本,版本号可作为日志或者上报实例信息的关键字,方便排查问题
-30 FileChannel.transfer
try (FileChannel fromChannel = new FileInputStream("from.txt").getChannel();
FileChannel toChannel = new FileOutputStream("to.txt").getChannel()) {
long size = fromChannel.size();
for (long left = size; left > 0; ) {
System.out.println("position " + (size -left) + " left " + left);
//注意: FileChannel.transfer() 并不保证一次性就能操作这个文件的copy,所以这里循环调用了
left = left - fromChannel.transferTo(size - left, left, toChannel);
}
}
-29 Class.getResource() V.S. Classloader.getResource()
Class.getResource()本质也是Classloader.getResource()Class.getResource()的传参若以 “/” 开头,表示传的是绝对路径;若不是以“/”开头,表示传参相对路径Classloader.getResource()只支持绝对路径- 假如
resources目录下有个1.txt,则:
URL resource = ResourceTest.class.getResource("1.txt"); //null
// 能获取到 【注意这是个相对路径,相对路径以 / 开头】
URL resourceA = ResourceTest.class.getResource("/1.txt");
//能获取到 【注意这是个绝对路径,表示类路径下没有子目录,直接就是 1.txt】
URL resourceB = ResourceTest.class.getClassLoader().getResource("1.txt");
URL resourceC = ResourceTest.class.getClassLoader().getResource("/1.txt"); //null
getResource()的典型用法是获取jar中的配置文件内容,看springboot源码
org.springframework.core.io.support.SpringFactoriesLoader#loadSpringFactories;
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
Enumeration<URL> urls = classLoader.getResources(FACTORIES_RESOURCE_LOCATION);
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
//....
}
-28 SQL_CALC_FOUND_ROWS
有项目使用下面语句实现分页,看起来少了select count(*) 这样的语句,但SQL_CALC_FOUND_ROWS 在未命中索引时会导致比较差的性能,Mysql 8.0 已经将其废弃了 mysql_deprecate_SQL_CALC_FOUND_ROWS
select SQL_CALC_FOUND_ROWS id,flow_id from flow_mapping;
select found_rows();
-27 如何在代码中获取一个sdk的版本
典型的用途:Sdk希望能在日志中打印 或 向ZK上报自己的版本号,版本号是POM的一个配置值,不同版本sdk的配置值不一样。
如果不能自动获取,那么每次发版还得手改版本号。
方案:
-
- 在
resources/META-INF下创建xxx.module,比如
- 在
module.type=my-sdk
module.name=my-sdk-module
module.version=${project.version}
-
- 代码中读取(就是读取文件)
try (InputStream mySDKVersionFileStream = mySDKVersion.class.getClassLoader()
.getResourceAsStream("META-INF/mySDKclient.module");) {
Properties props = new Properties();
props.load(mySDKVersionFileStream);
// 略
} catch (Throwable e) {
System.err.println("Failed to load mySDK version from META-INF/mySDKclient.module");
e.printStackTrace();
return UNKNOWN_VERSION;
}
-26 如何从包装的异常中抽取内部异常
ThrowableAnalyzer throwableAnalyzer = new ThrowableAnalyzer();
Throwable[] causeChain = throwableAnalyzer.determineCauseChain(e);
RuntimeException re = (OffsetOutOfRangeException)
throwableAnalyzer.getFirstThrowableOfType(OffsetOutOfRangeException.class, causeChain);
-25 慎重命名为xxxHelper
xxxHelper的命名容易将一个类的职责泛化掉,违背单一职责的原则。比如处理csv,
CSVHelper.parse(String)
CSVHelper.create(int[])
不如命名为:
CSVParser.parse(String)
CSVBuilder.create(int[])
也不是一个好的设计(?),可能manage的职责可以是A的。当然也不绝对。
-24 java 进程的关闭
- Runtime.halt() - 相当于kill -9
- Runtime.exit() - 相当于kill -15 (SIGTERM 信号)
-23 版本不兼容的一个解决思路
如果版本不兼容,我们就把 不兼容的地方定义成接口,然后通过SPI的方式注入我们想要想要的版本。
通过这种方式来决定使用接口的实现。
-22 位运算
int a1 = 1 << 2; //4
int a2 = 1 << 8; //256
int a3 = a2 | a1; //在a2基础上增加a1 ,得到a3
System.out.println(a3);
System.out.println((a3 & a1) == a1); //a3 拥有 a1
System.out.println((~a1 & a3)); //就是a2
-21 如何让list按指定顺序排
List<String> standard = Lists.newArrayList("a", "c", "d");
List<String> chaos = Lists.newArrayList("a", "d", "c", "d", "c", "e"); //期望排序 a,c,c,d,d,e
List<Pair<String, Integer>> chaoPairs = new ArrayList<>(chaos.size());
for (String chao : chaos) {
int index = Integer.MAX_VALUE;
for (int i = 0; i < standard.size(); i++) {
if (chao.equals(standard.get(i))) {
index = i;
break;
}
}
chaoPairs.add(new ImmutablePair<>(chao, index));
}
chaoPairs.sort(Comparator.comparing(pair -> pair.getRight()));
-20 C1 C2编译
C1编译器(-client)启动速度快,但是性能相比较Server Compiler(-server) 相对来说会差一些.
Server Compiler关注的是编译耗时较长的全局优化,甚至还会根据程序运行时收集到的信息进行不可靠的激进优化。Server Compiler通常比Client Compiler启动时间长,适合用于长时间在后台运行的程序(Web服务)。
HotSpot虚拟机目前有两种:C2和Graal。
C2可能在应用启动初期导致CPU毛刺甚至飙高,可见 JVM c1、c2编译线程CPU消耗高怎么办
-19
-18
-17 线程池异术
-17.1 线程池coreSize=0会发生啥
java8之后:
如果corePoolSize=0,提交任务时如果线程池为空,则会立即创建一个线程来执行任务(先排队再获取);如果提交任务的时候,线程池不为空,则先在等待队列中排队,只有队列满了才会创建新线程. 简单理解,就是退化成了单线程了
参考链接
-17.2 线程池公用的暗坑
父子任务用同一个线程池,尤其是单线程,可能会造成死锁 (主要是父子等在队列等对方)
-17.3 线程的异常
class FailedTask implements Runnable {
static final AtomicInteger counter = new AtomicInteger();
@Override
public void run() {
System.out.println("I am " + Thread.currentThread().getName() + " @ " + counter.incrementAndGet());
int i = 1 / 0;
}
}
@Test
public void test4() throws Exception {
new Thread(new FailedTask()).start();
//子线程中的异常将会打印出来,但不会中断父线程 (注意: 父线程捕捉不到子线程异常,但是可以打印!!)
System.out.println(" Main thread runs good");
Thread.sleep(1000);
}
-17.4 线程池中线程的异常
@Test
public void test5() throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor();
// 三个提交的任务都会执行,而且都会失败.
// 说明: 线程池中的线程遇到异常,并不会导致整个线程池崩掉
// 1、execute方法,可以看异常输出在控制台,而submit在控制台没有直接输出,必须调用Future.get()方法时,可以捕获到异常。
// 2、一个线程出现异常不会影响线程池里面其他线程的正常执行。
// 3、线程不是被回收而是线程池把这个线程移除掉,同时创建一个新的线程放到线程池中。
executor.execute(new FailedTask());
executor.execute(new FailedTask());
Future<?> future = executor.submit(new FailedTask());// console不会打印异常!!!
future.get(); // 如果是submit 一定要父线程,主动去get() 才能获取到异常
System.in.read();
}
那最佳实践是什么?
个人觉得:
- 如果父线程并不需要子线程的执行状态, 那么推荐将子线程的run() 做好try catch , 并打印好日志
- 线程池做好异常兜底打印
-17.5 submit()任务的异常要主动抓取或者try catch 打印
@Test
public void test3() throws Exception {
ExecutorService executor = Executors.newSingleThreadExecutor(r -> {
Thread thread = new Thread(r);
thread.setUncaughtExceptionHandler((t, e) -> {
System.out.println("run into exception:" + t.getName());
e.printStackTrace();
});
return thread;
});
Future<?> future = executor.submit(new FailedTask());
// future.get();
// 1) 通过submit 提交的任务即使有异常,也 不会被 setUncaughtExceptionHandler 去捕捉到.
// (这点还是有点意外) 而需要另一个线程(父线程) 主动去get()
// 2) execute/submit 我们在使用的时候还是要注意下区别的
executor.execute(new FailedTask());
System.in.read();
}
-16
-15
-14
-13 如何动态修改线上日志打印级别
使用ali arthas 就可做到.
实际上参考下logback的源码,结合一些配置管理工具, 我们还可以做到动态下发logger的打印级别.
Springboot admin似乎也能做到这点,有需要可以参考下实现
-12 如何起一个内嵌的web容器
不少中间件,会自带一个web容器, 其中以jetty 比较多,用来开放http 接口, 方便外部查询服务状态.
kafka mirror maker2也是一个使用案例, 若有需要,可以参考 org.apache.kafka.connect.runtime.rest.RestServer的写法.
-11 如何从文件末尾开始读一行
有很多写法, 但大多数是需要从文件开头开始遍历到最后, 实际调研发现commons-io已经有工具类了.
ReversedLinesFileReader reader = new ReversedLinesFileReader(file);
System.out.println(reader.readLine());
reader.close();
-10 获取test/resources/下面的文件
String path = this.getClass().getClassLoader().getResource("file-test.txt").getFile();
File file = new File(path);
System.out.println(file.getAbsolutePath());
// D:\my_own_projects\fast-test\common\target\classes\file-test.txt
注意: 打印出来的路径是在 target 目录,说明实际上是读的编译之后的路径
-9 logback中如何延时关闭appender
背景:大多数应用并不在乎应用在关闭的时候是不是正确处理了 Logback 的 appender ,反正不影响业务,最多是有些日志没来得及打印进程就退出了而已.
可如果我们希望"正经点"呢?
-8 DNS缓存在哪里?
假如现在有个中间件有故障, 运维把DNS切到新中间件了,我们的Java应用没有重启,那啥时能感知到DNS连到新地址呢?
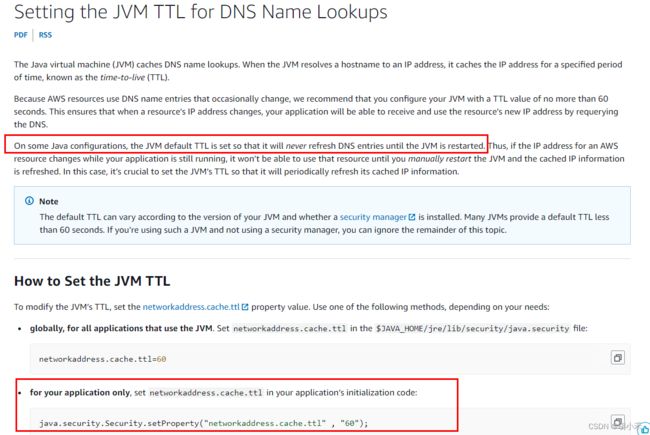
参考AWS的文档
-7 父子类有相同的字段, 那么getter 会取到谁的字段?
public class CTest {
public static void main(String[] args) {
// 返回 1 ,因为实际上 子类是覆盖了 父类的方法,返回的是 父类的 param 值
System.out.println(new Son().getParam());
}
static class Son extends Father{
private int param = 2;
public int getParam() {
return super.param;
}
}
static class Father {
private int param = 1;
public int getParam() {
return this.param;
}
}
}
再看另一种场景:
public class CTest {
public static void main(String[] args) {
// 返回 1 ,因为父类拿不到子类的 属性, 父类的 this 指代的是 Father 对象自己
System.out.println(new Son().getParam());
}
static class Son extends Father{
private int param = 2;
}
static class Father {
private int param = 1;
public int getParam() {
return this.param;
}
}
}
那再来这样呢?
public class CTest {
public static void main(String[] args) {
// 返回 2 ,因为子类的属性 /方法都覆盖了父类
System.out.println(new Son().getParam());
}
static class Son extends Father{
private int param = 2;
public int getParam() {
return this.param;
}
}
static class Father {
private int param = 1;
public int getParam() {
return this.param;
}
}
}
给了我们一种启发,假如有个三方包,包中有个写死字段, 我们不满意,想要覆盖它,咋搞?覆盖啊.
-6 数据字典(常量)的维护 / java8 JAXB
项目中肯定有很多这样的常量, 比如定义后端返回的字段 foo 页面上显示label =“已完成”.
- 后端直接返回页面 label;前端无逻辑,直接无脑展示
- 后端有一个字典接口 ,返回所有的 字段状态 --> label映射.
如果label要改, 改DB即可
上面都是一般操作,还有个神做法是 定制一个xml文件,
利用 java8 的JAXBContext Unmarshaller 接口去解析.
虽然可维护性不如在DB维护,但是逼格确实高, 而且我也是才发现java8 原来有这样的操作 xml 的API !!!
-5. 为何不推荐JDK的序列化

原因3: 序列化效率的差异( 这个暂时没有动手实践过,但据网络各路资料描述, JDK序列化效率相比json 有差异)
-4. 胖客户端/ 瘦客户端
我理解就是活儿(业务)让谁干的问题.客户端干的活儿,没有服务端多,但是比例还是越来越大的.这就是越来越胖.
Thick client
Thin client
-3.String.getBytes()
String.getBytes() 和 String.getBytes(Charset) 对于中文等非ASCII的字符可能处理并不相同.所以,我们代码中尽量指定字符集
@Test
public void test() {
// 对中文的长度处理不同
String s1 = "abc";
Assert.assertEquals(s1.getBytes(StandardCharsets.UTF_8).length, s1.getBytes().length);
String s2 = "abc我";
Assert.assertNotEquals(s2.getBytes(StandardCharsets.UTF_8).length, s2.getBytes());
}
-2. Java中数组是对象吗?
答案:是.
In the Java programming language, arrays are objects , are dynamically created, and may be assigned to variables of type Object. All methods of class Object may be invoked on an array.
数组对象并不是从某个类实例化来的,而是由JVM直接创建的,因此查看类名的时候会发现是很奇怪的类似于"[I"这样的样子,这个直接创建的对象的父类就是Object,所以可以调用Object中的所有方法,包括你用到的toString().
-1. volatile tips
- volatile 保证线程可见性 ,修饰对象的时候可能有坑,所以一般用来修饰原始类型
- 若用来修饰对象,只能保证引用可见,但是引用的对象里可能有别的引用,这些引用却没法保证可见性.
不过, 在一些JVM实现里, 这种说法可能并不成立 .
0. 原子性和线程安全
原子性和线程安全, 总听有人混在一起,傻傻分不清楚, 实际上二者压根儿不是一回事.
线程安全是说多线程同时操作同一个对象, 不会引发问题;
原子性是说 一组操作在完成之前, 内部状态对外不可见.也有人这样理解:
一个或多个操作,要么全部执行且在执行过程中不被任何因素打断,要么全部不执行。在Java中当我们讨论一个操作具有原子性问题是一般就是指这个操作会被线程的随机调度打断.
比如能保证原子性,那么也能保证线程安全; 此外注意
不要把数据库的原子性和Java并发的原子性生搬硬套在一起去理解
那怎么保持原子性?
- 单条线程
- 借助原子类 ,比如atomicLong里面的 accumulateAndGet方法
- 加入synchronized的关键字
1.如何监听一个文件的CRUD
使用JDK 自带的 WatchService
2. 如何显示默认的Java程序JVM参数
直接运行一个Java程序,所有的JVM参数都使用默认的,那问题来了,默认的是多少呢?我咋知道呢?
答:
使用参数即可打印看到默认的参数
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:gc.log
3. Side effect
什么叫函数(方法)的副作用?
先来一段释义:
In computer science, an operation, function or expression is said to have a side effect if it modifies some state variable value(s) outside its local environment, that is to say has an observable effect besides returning a value (the intended effect) to the invoker of the operation. State data updated “outside” of the operation may be maintained “inside” a stateful object or a wider stateful system within which the operation is performed. Example side effects include modifying a non-local variable, modifying a static local variable, modifying a mutable argument passed by reference, performing I/O or calling other side-effect functions. In the presence of side effects, a program’s behaviour may depend on history; that is, the order of evaluation matters. Understanding and debugging a function with side effects requires knowledge about the context and its possible histories.
The degree to which side effects are used depends on the programming paradigm. Imperative programming is commonly used to produce side effects, to update a system’s state. By contrast, declarative programming is commonly used to report on the state of system, without side effects.
In functional programming, side effects are rarely used. The lack of side effects makes it easier to do formal verifications of a program. Functional languages such as Standard ML, Scheme and Scala do not restrict side effects, but it is customary for programmers to avoid them.The functional language Haskell expresses side effects such as I/O and other stateful computations using monadic actions
上面的讲解比较学术, 我们拿Java来简单粗暴地理解: 一个方法的执行, 不会修改外部状态, 比如实例属性, 静态变量,传参对象的状态, IO操作等,就是 Side-Effect 的.
维基百科参考链接
4. btrace greys arthas
都是JVM诊断工具,但是arthas 是集大成者. 只要使用arthas 即可.没必要纠结用哪个
5. 锁定义的小技巧
在Logback源码中看到一个有意思的类: 没有具体方法,属性等,就这么一句.
// This class just makes it easier to identify locks associated with logback
// when analysing thread dumps.
public class LogbackLock extends Object {
}
看作者加的注释, 这也是保命的一个小技巧.
6. 约定俗成的命名习惯
写代码时, 命名真是一门大学问.好的命名一目了然,甚至省去了注释. 命名的过程就是建模的过程.假如在命名时发现无所适从, 大概率是模型本身有地方没有想清楚.
看多几个开源框架就会发现有不少很贴切的命名套路.窃以为, 自己写代码时完全可以模仿这种"套路",提高代码的可读性. 下面以logback为例:
Logger(“记录者”)LoggerFactory(命名就可以知道这是个工厂)LoggerContext(记录者上下文)Appender(append在英文中是"追加写"的含义,附注就叫appendix. 这个翻译成中文还真别扭)JoranConfigurator(“配置器”: 用来获取/计算 配置的这么个类/对象)LevelFilter(“过滤器”)LevelChangePropagator(Level变化的"传播者": Logback使用这个类将Logback 的 logger 转化为 jul 的logger. 作者将这种行为称为"propagator"确实贴切 )ContextSelector(“上下文选择器”: 这是个接口,提供了不同上下文的入口,主要被LoggerFactory访问获取不同上下文下的Logger)ILoggingEvent(Logback 将每一次日志记录都抽象成了 "event, 也就是ILoggingEvent`接口 (核心接口))DeferredProcessingAware(“延迟处理感知”: 翻译成中文,让人摸不着头脑… Logback有延时处理LoggingEvent的设计, 为了把这种"延时"行为抽象出来, 搞了一个DeferredProcessingAware.XxxAware的命名风格很常见,翻看下Spring代码即可知)ContextInitializer(“上下文初始化器”: 把初始化上下文的"行为"抽象了出来)EventEvaluator(“事件评估者” — 这么翻译??? 原设计意图:Evaluates whether a given an event matches user-specified criteria.)LifeCycle(“对象的生命循环”: 在Spring 中也有类似的设计, 用来表示对象从生到死的过程)Discriminator(这个接口用来compute a discriminating value for a given event)discriminate在英文中有"歧视"的含义.
SiftingAppender(“筛分appender”: 根据上面的Discriminator计算得到一个值,然后根据这个值动态获取appender,e.g. 根据user session 将日志打到不同的日志文件里)AppenderTracker("Appender"跟踪器: 把 动态获取appender的行为抽象出来,称之为tracker, 没毛病)StaticLoggerBinder(静态Logger 绑定器: 把获取LoggerFactory的行为抽象了出来)DelayingShutdownHook(延时关闭进程的钩子)AppenderAttachable(把 向logger 绑定 appender的行为给 抽象了出来)OptionHelper(用来处理 -D参数, 环境变量,反射获取对象的工具类; 这个命名倒是贴切)
… 等等…