GreenPlum初窥
介绍
greenplum 4.3.8.0,基于PostgreSQL 8.2.15。
Greenplum is regarded as the most scalable mission-critical analytical
database。
GP是Pivotal公司,将PostgreSQL增强后,把多实例组合,一起提供服务的MPP架构数据库。
PB级的装载能力(支持50PB)
遵从SQL-92, SQL-99, SQL-2003,包括SQL 2003 OLAP扩展项
原生MapReduce功能

web GUI的greenplum数据仓库系统运行状态监控工具
有人提到,gp最大精华,就是分布式执行计划
架构
shared nothing
至少如下几部分,相对PGSQL,GP做了优化:
模块:
- system catalog
- query planner
- optimizer
- query executor
- transaction manager
BI相关:
- parallel data loading (external tables)
- resource management
- query optimizations
存储相关:
- column-oriented tables
- append-optimized tables
- data partitioning
optimizer
因为greenplum是基于PostgreSQL做的,它自带PQSQL光环
优化器,有两种:
- legacy optimizer
- Pivotal Query Optimizer
segment
每个主机,叫一个segment host,而一个实体服务,叫一个segment
一个主机上,可以有多个服务实例。官方文档上也推荐,如果是现在的多核服务器,建议一个segmeng host(服务器)上,配置多个segment
但是每个segment要占用segment host下的一个端口。
一个CPU Core一个segment instance???
数据装载
High-performance loading uses MPP Scatter/Gather Streaming technology.
Scatter/Gather 流引擎是专为并行数据加载和导出而设计,Scatter指数据通过并行加载服务器并行分散到各个数据节点,Gather指数据在 GPDB内部可以根据分布策略按需并行分发。
数据加载方式有三种:
- sql insert
- copy,加载csv文件,可自定义间隔等
- gpfdist & gpload, 外部数据,需要看下是如何操作的
copy模式只能通过master节点导,所以相对比较慢。
存储
支持行存和列存,数据存储压缩,最大可以有30倍,这对客户最好的体验就是数据导入速度。
When different tables are joined on the same columns that comprise the distribution key, the join can be accomplished at the segments, which is much faster than joining rows across segments. 阿里某数据库,对join有要求,就是分区列必须都在join里。如果GP也这么做,速度会提升。
filespace & tablespace
基于greenplum system,创建一个filespace
tablespace是可以关联到固定磁盘空间的,譬如一些表IO要求小,可以放到sata上,一些IO要求高的,可以放到SSD上。
tablespace是创建在filespace上的:
CREATE TABLESPACE fastspace FILESPACE fastdisk;创建表的时候,可以指定此表存储的位置:
CREATE TABLE tablename(options) TABLESPACE spacename查看:
SELECT spcname as tblspc, fsname as filespc,
fsedbid as seg_dbid, fselocation as datadir
FROM pg_tablespace pgts, pg_filespace pgfs,
pg_filespace_entry pgfse
WHERE pgts.spcfsoid=pgfse.fsefsoid
AND pgfse.fsefsoid=pgfs.oid
ORDER BY tblspc, seg_dbid;
tblspc | filespc | seg_dbid | datadir
------------+-----------+----------+-----------------------------------
pg_default | pg_system | 1 | /home/gpadmin/data/master/gpseg-1
pg_default | pg_system | 2 | /gpadmin/data/primary/gpseg0
pg_default | pg_system | 3 | /gpadmin/data/primary/gpseg1
pg_global | pg_system | 1 | /home/gpadmin/data/master/gpseg-1
pg_global | pg_system | 2 | /gpadmin/data/primary/gpseg0
pg_global | pg_system | 3 | /gpadmin/data/primary/gpseg1
(6 rows)
存储模型
storage model
默认存储模型是和PostgreSQL一样的heap storage。
- heap storage
heap模型,更适合OLTP类型,它的存储方式,适合频繁数据修改的场景。
因为update和delete都需要整行信息。 - append-optimized storage
这种模式,官网上的介绍,建议针对批量表使用。bulk data load, read-only queries
行存,列存及混合
- row
- column
- combination of both
行存:
- 事物操作频繁的OLTP作业,一次取列较多
- selects against the table are wide, where many columns of a single row is needed in a query
- Row oriented storage is more efficient when many columns are selected at the same time, or when the row size of a table is relatively small
列存:
- 典型的数据仓库作业(基于较少列进行聚合计算),简单几列数据的修改
- 在适合的场景,能够在I/O和存储空间上,占得优势。
- 更适合做压缩,对应压缩率也会更高
- Column-oriented table storage is only available on append-optimized tables.
- many columns where only a small subset of columns is accessed by the queries
- selects are narrow and with aggregations of data computed over a small number of columns
- for single columns that require regular updates without modifying other column data
- best suited to queries that aggregate many values of a single column where the WHERE or HAVING predicate is also on the aggregate column
创建列存,column-oriented必须是append-optimized:
=> CREATE TABLE bar (a int, b text)
WITH (appendonly=true, orientation=column)
DISTRIBUTED BY (a);
数据压缩
Append-Optimized Tables Only
有两种压缩方式:1. 表级别压缩 2. 列级别压缩
显而易见,表级别压缩算法,会应用到整个表,列级别压缩算法,可以针对不同列,应用不同的压缩算法。
Distribution Policy
选择分布策略的时候,考虑三方面:
- 平均分布
- 尽量本地操作,譬如join,sort,aggregation等,尽量在本地操作
- 平衡查询工作,将查询任务拆解后,均衡地分布在所有节点上
默认是hash分布,如果有主键,则按主键,如果没有,则用第一列。
如果两个表join,建议使用join的列作为distributed key,这样可以使join本地化。
geometric和user-defined不能用做分布列
如果整张表都没有合适的列做分布列,gp就会按randomly或in round-robin fashion来处理
创建分布列:
=> CREATE TABLE products
(name varchar(40),
prod_id integer,
supplier_id integer)
DISTRIBUTED BY (prod_id);随机创建分布列:
=> CREATE TABLE random_stuff
(things text,
doodads text,
etc text)
DISTRIBUTED RANDOMLY;分布键(Distribution Key)选择
1. 能够将数据均衡地分散到各个segment上,达到并行处理,这是目的
2. distributed key和partition key不要用同一个
3. 数值列,可以,也建议使用这种类型。譬如smallint,integer,bigint等
4. varchar类型,可以
5. 时间类型,可以,也是比较建议使用的。譬如time,timestamp,date
6. 不适合做distributed key的类型,浮点型,TEXT类型,0/1这种等。
Partitioning
在创建表的时候,可以选择分区策略PARTITION BY和SUBPARTITION BY
在建表的时候,每个分区都会建立一个CHECK约束。这个CHECK会限定这个分区内数据的存储要求。查询器在做查询的时候,会检查分区的CHECK来决定扫描哪些分区。
表分区只能在创建的时候指定,不支持先导数据再建分区。后续会介绍多级分区,无论多少级,每一级分区最多可以有32767个。
建立分区的时候,一定要配DEFAULT partition,否则,一旦数据匹配不到CHECK,那么数据就会加载失败。
system catalog中会存储分区信息。
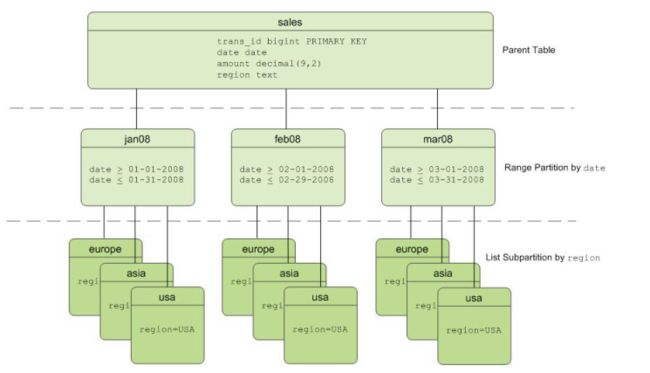
官方把用户的表称为root partitioned table,把经过分区后生成的有各自CHECK的存储单元称为leaf child table。可以通过INSERT把数据直接插入到根表,这时数据会被按规则分配到对应的叶表上;也可以直接把数据插入到叶表上。
如果有主键,主键必须包含分区列。
创建表分区,会带来额外的分区管理开销,不是所有的表都适合做分区。
表符合如下几个特征,才比较适合做分区:
- 足够大
- 当前查询效率不符合预期
- 业务查询条件一致
譬如大量查询where条件都是基于时间范围查询 - 历史数据
譬如要求缓存最近7天的数据,按天做分区。当做新旧数据更新的时候,可以按分区更新,更方便。 - 分区列,能否均衡地分割数据
只有在语句执行的时候,能够基于分区列信息去预判,减少查询分区数时,分区列才起到作用。
如果语句执行结果,要遍历所有分区,那么查询结果会差于无分区的数据存储方式。
可以做多级分区,但是操作风险略高,要小心:
譬如用col1和col2做多级分区列,col1里面有2种类型,col2里面有3中类型,那么最终GP将会划出来2*3=6个分区。
如果是列式存储,共10列。每列会存在同一个小表内,基于上面的分区,最终会生成2*3*10=60个分区
PS:要拿实际环境验证下
多级分区,会减少查询计划分解时间,单较单一的分区,查询更快。
分区有两种方式:
- range partitioning
按范围分区 - list partitioning
按值分区
使用Pivotal Query Optimizer的话,分区列只能使用1个。使用legacy optimizer,可以多列做composite partition keys。
range partitioning
分区可以按start, end, every来划分。默认start是包含在内的,但是end是不包含的:
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( START (date '2008-01-01') INCLUSIVE
END (date '2009-01-01') EXCLUSIVE
EVERY (INTERVAL '1 day') );可以手工指定分区,不用为每个分区指定end,它会以下一个分区的开始作为结束:
CREATE TABLE sales (id int, date date, amt decimal(10,2))
DISTRIBUTED BY (id)
PARTITION BY RANGE (date)
( PARTITION Jan08 START (date '2008-01-01') INCLUSIVE ,
PARTITION Feb08 START (date '2008-02-01') INCLUSIVE ,
PARTITION Mar08 START (date '2008-03-01') INCLUSIVE ,
PARTITION Apr08 START (date '2008-04-01') INCLUSIVE ,
PARTITION May08 START (date '2008-05-01') INCLUSIVE ,
PARTITION Jun08 START (date '2008-06-01') INCLUSIVE ,
END (date '2009-01-01') EXCLUSIVE );CREATE TABLE rank (id int, rank int, year int, gender
char(1), count int)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
( START (2001) END (2008) EVERY (1),
DEFAULT PARTITION extra ); list partitioning
CREATE TABLE rank (id int, rank int, year int, gender
char(1), count int )
DISTRIBUTED BY (id)
PARTITION BY LIST (gender)
( PARTITION girls VALUES ('F'),
PARTITION boys VALUES ('M'),
DEFAULT PARTITION other );multi-level partitions
每个分区下,都会按照subpartition做分区。
两层分区:
CREATE TABLE sales (trans_id int, date date, amount
decimal(9,2), region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE (date)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe'),
DEFAULT SUBPARTITION other_regions)
(START (date '2011-01-01') INCLUSIVE
END (date '2012-01-01') EXCLUSIVE
EVERY (INTERVAL '1 month'),
DEFAULT PARTITION outlying_dates );三层分区:
CREATE TABLE p3_sales (id int, year int, month int, day int,
region text)
DISTRIBUTED BY (id)
PARTITION BY RANGE (year)
SUBPARTITION BY RANGE (month)
SUBPARTITION TEMPLATE (
START (1) END (13) EVERY (1),
DEFAULT SUBPARTITION other_months )
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE (
SUBPARTITION usa VALUES ('usa'),
SUBPARTITION europe VALUES ('europe'),
SUBPARTITION asia VALUES ('asia'),
DEFAULT SUBPARTITION other_regions )
( START (2002) END (2012) EVERY (1),
DEFAULT PARTITION outlying_years );索引(要看看)
GP不建议使用索引
GP主要做快速有序地扫描(基于分区)
如果建立全局索引,数据分布机制和分区机制,会完全打乱索引。如果基于单个分区去建立索引,这个有点像阿里的xxx,应该有一定效果吧。
GP中索引的起作用的场景:
返回1条或者很小的集合时
当可以使用index来替代全表扫描的查询(append-optimized tables)
GP只支持在用户创建的表上建立索引,不支持GP依据分区创建的叶表上创建索引。创建的索引会被复制到各个叶表上。
目前测试看到:
打开pivotal query optimizer,会触发index scan或table scan
打开legacy optimizer,会触发seq scan
类型
支持:
B-tree(默认)
GiST
不支持:
Hash
GIN
unique indexes
当索引列和分区列一致,append-optimized tables不支持
还有一些其他限制,再看看bitmap indexes
创建索引:
CREATE INDEX gender_idx ON employee (gender);cluster
cluster an index可以改变数据在物理磁盘上存储的序列,起到优化的作用。
直接用CLUSTER命令,对大表来说会比较慢。推荐一个比较快的办法,先把数据加载到一个临时表,然后通过修改的办法触发数据重排序:
CREATE TABLE new_table (LIKE old_table)
AS SELECT * FROM old_table ORDER BY myixcolumn;
DROP old_table;
ALTER TABLE new_table RENAME TO old_table;
CREATE INDEX myixcolumn_ix ON old_table;
VACUUM ANALYZE old_table;PQO
Pivotal Query Optimizer
GP 4.3.5.0版本开始有,和legacy optimizer共存,默认使用legacy optimizer。
针对planning和optimization做了优化,在多核环境优势最大。
在如下几种类型的查询和操作有明显提升:
- Queries against partitioned tables
- Queries that contain a common table expression (CTE)
- Queries that contain subqueries
- DML Operation Enhancements with Pivotal Query Optimizer
在如下几个操作下,也有增强:
- Improved join ordering
- Join-Aggregate reordering
- Sort order optimization
- Data skew estimates included in query optimization
PQO的开关,可以在如下三个层面打开:
- A Greenplum Database system
gpconfig -c optimizer -v on --masteronly
gpstop -u - A specific Greenplum database
ALTER DATABASE test_db SET OPTIMIZER = ON ; - A session or query
set optimizer = on ;
要使用PQO要满足几个条件:
- The table does not contain multi-column partition keys.
- The multi-level partitioned table is a uniform multi-level partitioned table.
- The server configuration parameter optimizer_enable_master_only_queries is set to on when running against master only tables such as the system table pg_attribute.
- Statistics have been collected on the root partition of a partitioned table.
在有分区的表上,应用PQO,要在根分区执行ANALYZE ,先收集一些根表的信息(不收集叶表的)。
ROOTPARTITION
要看下analyze命令。
GP还做了一个工具,analyzedb,用来做整体收集。
PQO和旧的legacy optimizer并存,是因为PQO不能独立支持所有GP宣传的特性,包括:
- indexed expressions
- PERCENTILE window function
- External parameters
- 个别分区表不支持
- Non-uniform partitioned tables.
- Partitioned tables that have been altered to use an external table as a leaf child partition.
- SortMergeJoin
- Ordered aggregations
- These analytics extensions:
- CUBE
- Multiple grouping sets
- These scalar operators:
- ROW
- ROWCOMPARE
- FIELDSELECT
- Multiple DISTINCT qualified aggregate functions
- Inverse distribution functions
PQO使用时,如下功能,性能会下降:
xxx
如果使用join等操作,会触发shuffle,GP有两种类型:
1. 表比较小的时候,会广播,broadcast motion
2. 数据比较大的时候,redistribution motion,这个重分布,也只是把数据装载到内存中,同步到对应segment上而已,物理存储位置不变化
ANALYZE
针对分区和存储,做了数据收集。
可以配置参数,数值越大,信息收集时间越长,而未来查询效率更高(但只提到了legacy optimizer)
内存
GP对每个分区partition都有一个buffer
针对列存表,每列都有一个buffer
所以,一个拥有很多分区数,且列数特别多的表,消耗内存会很多
模式 schema
Query
两种查询模式:
- parallel query plan
- targeted query plan
motion
相比常见的查询计划,GP多了一个叫motion,并不是所有的查询都需要motion。
在查询执行的时候,segment之间会交换元组(tuple)。
查询计划,会切成很多个,能够由segment独立执行的单元,叫slice。
tuning
操作系统级别:
1. 提升系统内存cache,也不要太大,以免剩余内存不足,出现SWAP
2. 提高磁盘文件访问句柄数,提升磁盘IO
用最小的数据类型去存储数据,尤其是参与join的列。
Indexing is a bad word in Greenplum. Although supported, this is the last resort to a inefficiently written queries which usually have to do to an unbalanced distribution selection and/or some other related predicate that should have been coded (like the distributions are not being used in the JOIN)
- Be constant with the execution of ANALYZE for tables that only get INSERT executed against them
- Help your DBA find the Distribution Mismatch to help you make your processing work faster
Greenplum Database devises a query plan for each query it is given. - Choosing the right query plan to match the query and data structure is absolutely critical for good performance.
- A query plan defines how the query will be executed in Greenplum Database’s parallel execution environment.
- By examining the query plans of poorly performing queries, you can identify possible performance tuning opportunities.
Based on Greenplum’s Architecture:
- Distribute by JOIN (For LOCAL JOIN Practice)
- Partition by Predicate when truly necessary
- Index only when truly necessary (not encourage)
- As a DBA you must analyze and make sure that all of the tables associated with one another do posses the same DISTRIBUTION KEY set of components (or columns)
- A LOCAL JOIN is that join between two or more tables that share the same Distribution column values, just as a Clustering Index does in a conventional RDBMS.
- A LOCAL JOIN executes faster than a conventional Clustering INDEX.
select name, setting, unit, min_val, max_val, short_desc, extra_desc from pg_settings;
目前认为比较关键的
"block_size";"Shows size of a disk block"
"cpu_index_tuple_cost";"Sets the planner's estimate of the cost of processing each index entry during an index scan."
"cpu_operator_cost";"Sets the planner's estimate of the cost of processing each operator or function call."
"cpu_tuple_cost";"Sets the planner's estimate of the cost of processing each tuple (row)."
"debug_print_parse";"Prints the parse tree to the server log."
"debug_print_plan";"Prints the execution plan to server log."
"effective_cache_size";"Sets the planner's assumption about size of the disk cache."
"enable_bitmapscan";"Enables the planner's use of bitmap-scan plans."
"enable_groupagg";"Enables the planner's use of grouping aggregation plans."
"enable_hashagg";"Enables the planner's use of hashed aggregation plans."
"enable_hashjoin";"Enables the planner's use of hash join plans."
"enable_indexscan";"Enables the planner's use of index-scan plans."
"enable_mergejoin";"Enables the planner's use of merge join plans."
"enable_nestloop";"Enables the planner's use of nested-loop join plans."
"enable_seqscan";"Enables the planner's use of sequential-scan plans."
"enable_sort";"Enables the planner's use of explicit sort steps."
"random_page_cost";"Sets the planner's estimate of the cost of a nonsequentially fetched disk page."
"seq_page_cost";"Sets the planner's estimate of the cost of a sequentially fetched disk page."
"gp_autostats_mode";"Sets the autostats mode."如果使用index scan效果比较好,我们可以通过如下方式,使优化器解析成index scan:
1. set enable_indexscan on
2. 降低random_page_cost的值到20或者10,甚至更低
3. 提升seq_page_cost的值到10或者15,甚至更高
scan包括
- Seq Scan on heap tables
- Append-Only Scan on row oriented AO tables
- Append-Only Columnar Scan on column oriented AO tables
- Index scan
- Bitmap Append-Only Row-Oriented Scan
Join包括:
- hash join(一般是最快的)
- nested loop join
- merge join
join
http://blog.csdn.net/lichangzai/article/details/8332957
聚合
HashAggregate & GroupAggregate
http://blog.csdn.net/scutshuxue/article/details/6791157
讨论
dist
ribution & partitioning
distribution是物理层面的,partitioning是逻辑层面的
distribution策略保证数据分布在不同segment上,进而使得任务并发处理
partitioning是逻辑层面的,将同一各segment上的数据进行分区,进而达到segment上查询动作的优化
安装配置
用户
不能用root安装和启动gp
新建帐户要对安装目录有完整权限,默认安装位置/usr/local/greenplum-db-4.3.x.x,也可在安装的时候输入一个完整路径
data directory
存储数据的位置
如果1个物理机上安装了多个实例,譬如装了1个master,3个segment,那么就得配4个路径
配置
国外有个安装文档,很详细,参考:
https://blog.pivotal.io/big-data-pivotal/features/how-to-build-a-hardware-cluster-for-pivotal-greenplum-database
建议每个segment host上,配置最多4到6个segments,而物理服务器的内存,也建议在256G或者更高,每个segment建议分配32G内存。
使用
连接
yum -y install postgresql
psql -d gp -h 1.2.3.4 -p 5432 -U gpadmin操作
pqsql命令
help可以打印出总的帮助信息
\?有点类似man,可以看到pqsql的命令帮助
数据库
创建:
createdb -h 192.168.123.92 -p 5432 -U gpadmin db_t查看数据库列表
psql -l -h 192.168.123.92 -p 5432 -U gpadmin
[root@slb1 ~]# psql -l -h 192.168.123.92 -p 5432 -U gpadmin
List of databases
Name | Owner | Encoding | Access privileges
-----------+---------+----------+---------------------
db_t | gpadmin | UTF8 | 列出所有数据库
db_t=# \l
List of databases
Name | Owner | Encoding | Access privileges
-----------+---------+----------+---------------------
db_t | gpadmin | UTF8 |
...
template0 | gpadmin | UTF8 | =c/gpadmin
: gpadmin=CTc/gpadmin
template1 | gpadmin | UTF8 | =c/gpadmin
: gpadmin=CTc/gpadmin
(6 rows)
db_t=# SELECT datname from pg_database;
datname
-----------
...
db_t
template1
template0
(6 rows)
表
创建表
db_t=# CREATE TABLE t1 (
i1 int PRIMARY KEY,
i2 int,
s1 varchar(40)
);如果给出了模式名(比如,CREATE TABLE myschema.mytable …), 那么表是在指定模式中创建的。否则它在当前模式中创建。
create TABLE t_schema.t3 (
i1 int PRIMARY KEY,
i2 int,
s1 varchar(40)
);列出表的详细信息
db_t=# \d+ t3
Table "t_schema.t3"
Column | Type | Modifiers | Storage | Description
--------+-----------------------+-----------+----------+-------------
i1 | integer | not null | plain |
i2 | integer | | plain |
s1 | character varying(40) | | extended |
Indexes:
"t3_pkey" PRIMARY KEY, btree (i1)
Has OIDs: no列出当前模式schema下所有表
db_t=# \dt
List of relations
Schema | Name | Type | Owner
--------+------+-------+---------
public | t1 | table | gpadmin
(1 row)查看所有表,抛开模式schema
db_t=# select schemaname,tablename,tableowner from pg_tables;
schemaname | tablename | tableowner
--------------------+-------------------------------+------------
information_schema | sql_languages | gpadmin
information_schema | sql_packages | gpadmin
... | ... | ...
public | t1 | gpadmin
public | t2 | gpadmin
t_schema | t3 | gpadmin
(90 rows)查看某张表数据量:
select pg_size_pretty(pg_relation_size('table_name_xxxxx')); 模式
列出模式
db_t=# \dn
List of schemas
Name | Owner
--------------------+---------
gp_toolkit | gpadmin
information_schema | gpadmin
pg_aoseg | gpadmin
pg_bitmapindex | gpadmin
pg_catalog | gpadmin
pg_toast | gpadmin
public | gpadmin
(7 rows)创建新模式schema
CREATE SCHEMA t_schema;删除模式schema
DROP SCHEMA t_schema;查看当前模式
db_t=# SHOW search_path;
search_path
----------------
"$user",public
(1 row)修改默认模式
db_t=# SET search_path=t_schema;
SET
Time: 14.754 ms
db_t=# SHOW search_path;
search_path
-------------
t_schema
(1 row)配置
select name, setting, unit from pg_settings ;Grand Unified Configuration (GUC)
GUCs for Index Selection
1. random_page_cost (master/session/reload) Default value: 100
Sets the planner’s estimate of the cost of a non sequentially fetched disk page
Lower value increases the chances for index scan to be picked
2. enable_indexscan (master/session/reload) Default value: on
Enables or disables the query planner’s use of index-scan plan types
3. enable_nestloop (master/session/reload) Default value: off
Enables or disables the query planner’s use of nested-loop join plans
This should be enabled for use of index in nested loop joins
4. enable_bitmapscan (master/session/reload) Default value: on
Enables or disables the query planner’s use of bitmap-scan plan types.
Generally bitmap scan provides faster access, however you can try disabling it in specifically if you are getting very few rows out of index
5. enable_seqscan (master/session/reload) Default value: on
Disabling enable_seqscan results in use of index
Use this parameter very carefully only as last resort
其他
#显示命令执行的时间
\timing运维
监控
磁盘 iostat
网络 ifstat
CPU mpstat
内存 tee/vmstat
gpperfmon,GP performance monitor
gpcheckperf,文件系统读写性能测试
pgbench和TCP-H
基础
深入
append optimized storage
todo
资源隔离&高并发
todo
评测
参考
pgsql的命令
Greenplum Database Performance Tuning