2021CVPR 弱/暗光《Seeing in Extra Darkness Using a Deep-Red Flash》
文章开头,不得不吐槽一下,此篇文章如朦胧的秋雨,让懵懂的少年,深夜里伴行,永远走不出这寂静的夜。
先点题点题:

文章一开始放了一个大大的Fig 1 ,告诉我们:
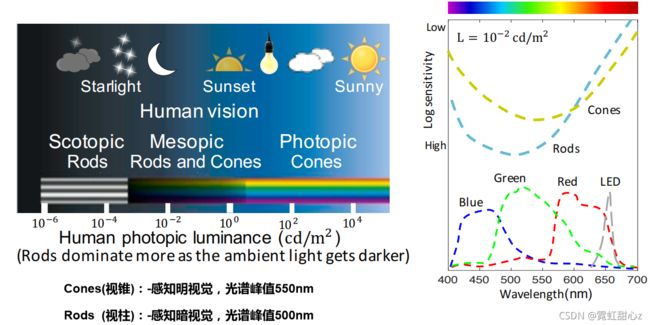
人眼有两种细胞:
1)Cones(视锥细胞,感知明亮视觉,在白天主导工作,对色彩明暗,对光不敏感);
2)Rods(视杆细胞,感知暗视觉,在晚上主导工作,对色彩不敏感,但对光敏感)。
在L = 10^-2cd/m^2 (cd(坎德拉):被照射物体光表面辐射量单位)的暗光环境下,人眼中的Rods占主导地位(Cones也工作,只是不占主导),Rods可以看见黑白视觉,当是红色光时并不能有效捕获(这个波段,Cones占主导地位,且是黑夜环境下,所以眼睛很难捕捉到),但是LED相机传感器,却能感知到。
所以如果把这种红光作为暗光环境下的闪光灯,拍照的时候对人眼的影响会很小,但是相机却能很好的捕获内容。

就是上面这个样子了,嘿嘿。为什么是660nm,后面作者解释了,照射660nm的深红光时时,可以获得最大信息。
接下来作者展示了结果:

看图可以理解,作者在获取视频时,一帧弱光,一帧红光(这里和几位老师发生了歧义,小孩子的我认为(frame88和frame89是同一时刻的,只是开着红光拍摄,但是捕获2种图像;而老师们认为,frame88 和frame89不是同一帧,以红光阶段性闪烁的方式拍摄的))。仔细看88 89像一幅图和90有区别。同时这里也说明了,利用深红光拍摄,不会产生白光拍摄时对眼睛的闪烁影响。
接下来作者为了解释深红光拍摄为什么不会对人眼产生影响:
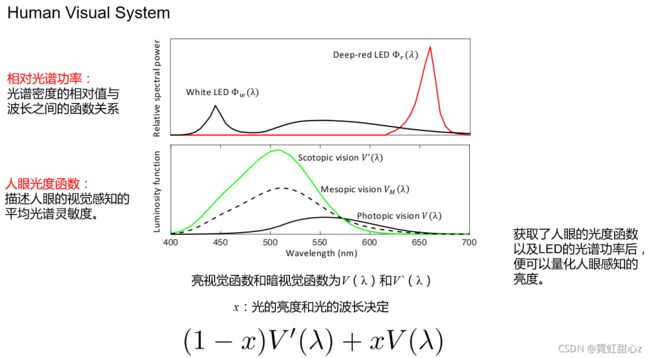
两幅图的大环境是 L = 10^-2cd/m^2 的弱光环境。
看第一幅图,White LED 和Deep-red LED的相对光谱功率不一样
看第二幅图,根据第一幅图的光谱功率不同,人眼感知也不同,Deep-red LED人眼几乎感知不到,而White LED却能很好地感知,间接说明了,利用Deep-red LED夜晚拍照的好处。
Mesopic vision 相当于真实的人眼的视觉曲线,由视锥和视杆同时控制。
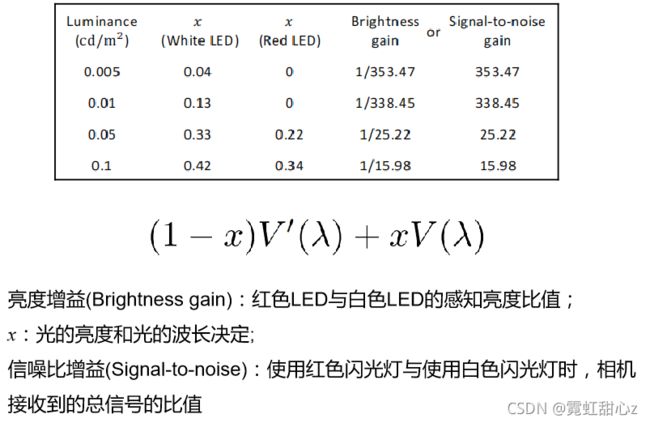
上图,作者进一步说明了,同样条件下,Deep-red LED可以获得更多的信噪比,从表从可以看出,作者有一些测量设备,可以获知Deep-red LED的一些参数。

上式是人眼的视觉函数,由控制系数x控制暗视觉和亮视觉(这里猜测,作者就是利用这个对相机LED driver 进行一个建模,得到合适控制系数x的为的是获取适应人眼的Deep-red LED) Fig 3就是描述了一个人眼的浦肯野转换。随着Dark teim 的增加,Cones感受阈值下降,逐步转换到Rods。
Fig 3就是描述了一个人眼的浦肯野转换。随着Dark teim 的增加,Cones感受阈值下降,逐步转换到Rods。
接下来作者介绍相机系统:

这此时指出怎么探索来自深红灯图像的引导信号?
因为作者后面需要利用MFF-Net对引导信号和弱光图像进行融合,提取引导信号的边缘信息,弱光图像的颜色信息。
作者说所使用的相机的红色通道的灵敏度大约是绿色通道的4倍,灵敏度是蓝色通道的10倍。一个简单的选择是选择深红光图像中的红色通道信号作为引导信号进行重建。然而,单一的红色通道可测量的动态范围是有限的,因为了解到红色物体很容易达到饱和,并且红色通道中缠着着蓝色物体的低级信号。所以!他选择利用R+G+B作为引导信号!(但是图像显示起来还是深红色的)
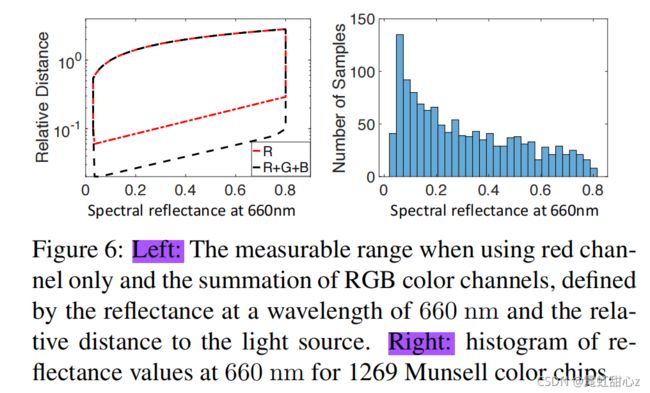
Fig 6 就是解释R+G+B会有更大的动态范围---即围成的面积更大。后面的直方图则是作者测试了对660nm的反射率,发现百分之80的都可以反射红光。
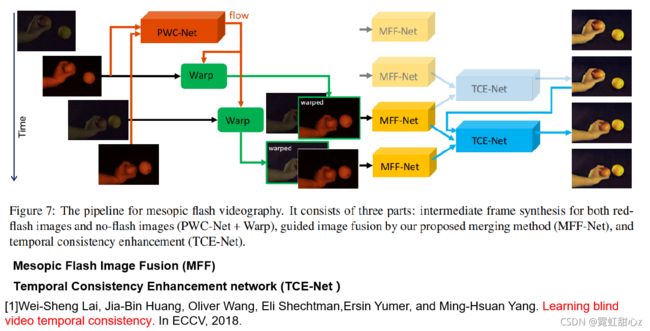
Fig 7 是作者的网络架构。
首先利用两个Deep-red LED拍摄的图像进行一个Pwc-Net 光流计算,得到t-1帧和t帧间的光流(flow),利用flow来Warping t-1帧的Deep-red LED图像得到t帧的Deep-red LED 图像。
然后,再用flow Warping t帧的弱光图像得到t帧的弱光图像。分别进行弱光如图像和Deep-red LED进行融合,得到增强后的弱光图像!(这里已经是一个增强效果很不错的图像了)
最后,把2个t帧的图像和一个t-1帧的图形放入TCE-Net网络进行一个时序性的计算。保证视频输入输出。
(上面说的情况是frame88 frame89为同一情况下的结果,如果frame88 和frame89不同)
那么图像的视频序列就是t-2 t-1 t t+1帧,4帧各不相同,首先计算flow,然后将t-1 warp到 t(Deep-red LED) ,t warp 到 t+1 (弱光),那么就得到了 t 、t+1 和 t-2 、t-1 两组图,然后进行MFF-Net融合(但是既然帧不同,内容肯定也有些不同,不同的话为什么要融合,融合要学习什么呢?融合之后的差距再用插值补全?)
MFF-Net 是一个ResUnet。

Occlusion Esitimation 就是一个光流的遮挡估计,计算两帧之间,物体移动前,移动后,都有哪些画面被遮挡,把遮挡的部分进行计算,为的是恢复边缘信息。
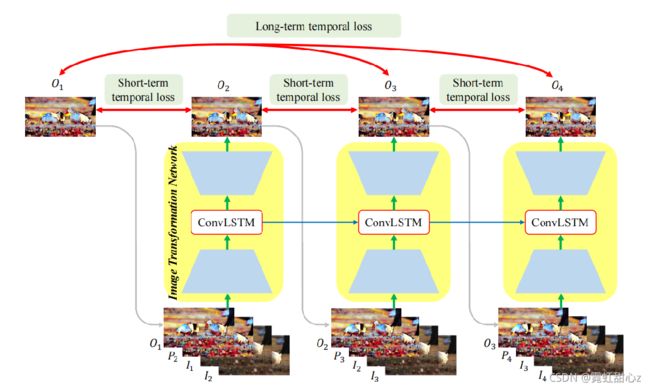
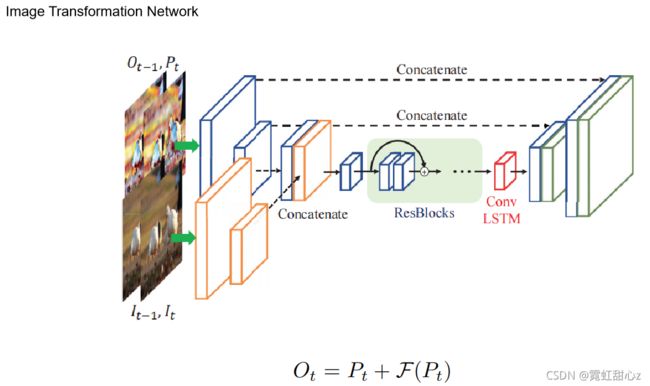
上面三张图是TCE-Net 内容略。
训练的过程!!使用了下面文章中的NYU数据集
[1]Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor segmentation and support inference from rgbd images. In ECCV, 2012.《从 rgbd 图像中支持推断室内分割》 NYU v2 dataset
But ! 你用别人的数据集训练,那你怎么得到的深红外光图像做single guide ???,作者在这里说把R+G+B相加,三个相加就能得到暗光图像吗?
有下面2个猜想:
1)三通道相加再加到R图像上去,得到了R通道值较高的灰度图,近似等于深红外图像
2)根据之前的模拟人眼控制参数x, 对图像进行一个深红外灯的模拟,改变NYU数据集,得到深红外灯的图像。
然后引入噪声(模拟暗光图像),然后呢作者只希望从引导图像中学习边缘信息,所以做了一下Modulation操作:


以及Loss :
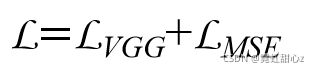

到了实验展示部分:Ambient-Light Lmage 是环境光,作者这意思就是是正常环境光呗,给图像加极深的噪声来模拟暗光图像噪声,当做暗光图像,那不然你这环境光是咋拍的这么清晰的,那叫暗光吗?





总结,文章有几个点没有说清楚,
1)frame88 frame 89 是同一时刻吗?如果不是同一时刻,那么用这两张图经过flow warp 后进行融合相当于t-1 t帧的融合,能从中学到什么信息呢,学边缘,学颜色?
2) 既然最后训练的数据集没有深红外光,那指导信号就单单是R+G+B吗?那加起来的前提也不是深红光拍摄的呀,NYU数据集是2012年的,合成一个训练集,那你前面提那么多深红光的好处,为什么?
3) ambient-light 是什么环境下的环境光,弱光吗?
有看懂的大哥可以联系小弟,小弟着实几个点没懂,人笨。