General Algorithms - Graph
- BFS
-
-
- Red Knights Shortest Path - World CodeSprint 12 -
-
-
- DFS
-
-
- Even Tree
- Roads and Libraries
-
-
- MST
-
-
- Kruskal MST Really Special Subtree
-
-
- A
BFS
Red Knight’s Shortest Path - World CodeSprint 12 -

While loop 和 Recusive function可以互相用来替换; 0 为任意随机起始点, 4 为任意终点, 1,2,3为过程中步骤


DFS
Even Tree
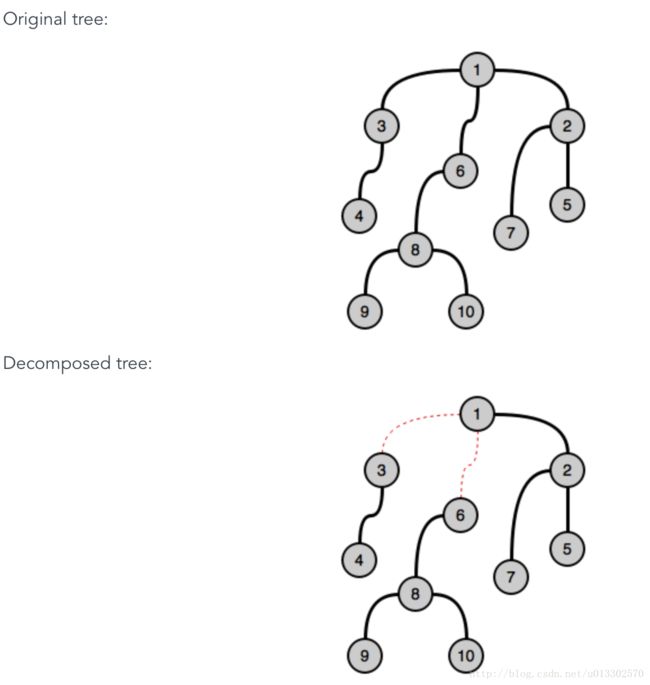
由于已知node范围在2-100,把adjacency list(vector)的范围直接写成 ”>100” 大一点的可以帮助更快确定位置。Sparse 的这种不确定分布的图,使用matrix会增加storage的负担,最大情况会需要一个100x100的matrix, 然而不是每个matrix 的cell都会用到。
整个DFS里,不用一个一个node来回测试相连为不为even的tree,只用计算出DFS 遍历的nodes的和能不能被%2。使用公共的Variable来 counts 可以砍掉的edges的数量。
最要小心是return的时候,nodes的总和计算要加上当前的这一个node (1), 即:dfs(当前node)+1。dfs(当前node) recursion (back tracking)的作用是累计当前node的 子nodes 的个数。
用
num_vertex+=num_nodes累计到当前node,需要经过的子nodes.Visit[] 的boolean判断在DFS非要不可,是为了track node.

Roads and Libraries

此题已知edge 和 node统一Weights,则BFS没有优势但也可以用
除了BFS, DFS这些能够确保每个点和边都会经过的,还有Minimum Spanning Tree 可以用. MST运用了Union-Find的Data structure,比如根据Weight来Swap
MST解法 1
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.*;
class MinSpanningTree {
public static final class Edge implements Comparable<Edge> {
final int srcId;
final int trgId;
final long value;
Edge(int srcId, int trgId, long value) {
this.srcId = srcId;
this.trgId = trgId;
this.value = value;
}
public int compareTo(Edge o) {
return (value < o.value) ? -1 : (value > o.value) ? 1 : 0;
}
}
private static final class NodeEntry {
NodesSet owner;
NodeEntry next;
}
private static final class NodesSet {
int size;
NodeEntry first;
NodeEntry last;
NodesSet(NodeEntry node) {
size = 1;
first = node;
last = node;
}
static void merge(NodesSet set1, NodesSet set2) {
if (set1.size < set2.size) {
merge(set2, set1);
return;
}
set1.size += set2.size;
set1.last.next = set2.first;
set1.last = set2.last;
NodeEntry node = set2.first;
while (node != null) {
node.owner = set1;
node = node.next;
}
}
}
private int nodesCount;
private int edgesCount;
private Edge[] edges;
public MinSpanningTree(int nodes) {
this.nodesCount = nodes;
this.edgesCount = 0;
this.edges = new Edge[nodesCount];
}
public void addEdge(int srcId, int trgId, long value) {
if (edgesCount == edges.length) {
edges = Arrays.copyOf(edges, 2 * edges.length);
}
edges[edgesCount++] = new Edge(srcId, trgId, value);
}
public Edge[] getMinSpanningTree() {
NodeEntry[] nodes = new NodeEntry[nodesCount];
for (int i = 0; i < nodesCount; i++) {
nodes[i] = new NodeEntry();
nodes[i].owner = new NodesSet(nodes[i]);
}
edges = Arrays.copyOf(edges, edgesCount);
Arrays.sort(edges, 0, edgesCount);
Edge[] spanningTree = new Edge[nodesCount-1];
int k = 0;
for (int i = 0; i < edgesCount & k+1 < nodesCount; i++) {
NodesSet set1 = nodes[edges[i].srcId].owner;
NodesSet set2 = nodes[edges[i].trgId].owner;
if (set1 != set2) {
NodesSet.merge(set1, set2);
spanningTree[k++] = edges[i];
}
}
return (k+1 < nodesCount) ? null : spanningTree;
}
public long getMinSpanningTreeSize() {
Edge[] spanningTree = getMinSpanningTree();
if (spanningTree == null) return -1;
long treeSize = 0;
for (Edge edge : spanningTree) treeSize += edge.value;
return treeSize;
}
}
public class Solution {
public static void main(String[] args) {
Scanner in = new Scanner(new BufferedReader(new InputStreamReader(System.in), 256 << 10));
int testsNumber = in.nextInt();
for (int test = 0; test < testsNumber; test++) {
int n = in.nextInt();
int m = in.nextInt();
int costOfLib = in.nextInt();
int costOfRoad = in.nextInt();
MinSpanningTree tree = new MinSpanningTree(n+1);
for (int i = 0; i < n; i++) {
tree.addEdge(0, i+1, costOfLib);
}
for (int i = 0; i < m; i++) {
int v1 = in.nextInt();
int v2 = in.nextInt();
tree.addEdge(v1, v2, costOfRoad);
}
System.out.println(tree.getMinSpanningTreeSize());
}
in.close();
}
}MST解法2
import java.io.*;
import java.util.*;
import java.text.*;
import java.math.*;
import java.util.regex.*;
public class Solution {
public static class Edge {
public int u, v;
public long w;
public Edge(int u, int v, long w) {
this.u = u;
this.v = v;
this.w = w;
}
}
public static class UnionFind {
private int parent[];
private int rank[];
public UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
public int findSet(int x) {
while (parent[x] != x) {
parent[x] = parent[parent[x]];
x = parent[x];
}
return x;
}
public void union(int a, int b) {
int setA = findSet(a);
int setB = findSet(b);
if (rank[setA] > rank[setB]) {
parent[setB] = setA;
} else {
parent[setA] = setB;
if (rank[setA] == rank[setB]) {
rank[setB] += 1;
}
}
}
public boolean connected(int a, int b) {
return (findSet(a) == findSet(b));
}
}
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int q = in.nextInt();
for(int a0 = 0; a0 < q; a0++){
long n = in.nextLong();
long m = in.nextLong();
long lib = in.nextLong();
long road = in.nextLong();
List edges = new ArrayList<>();
for(int a1 = 0; a1 < m; a1++){
int city_1 = in.nextInt();
int city_2 = in.nextInt();
edges.add(new Edge(city_1, city_2, road));
}
UnionFind uf = new UnionFind((int)(n + 1));
long minCost = n * lib;
long roadCosts = 0;
long libCosts = n * lib;
for (Edge edge : edges) {
if (!uf.connected(edge.u, edge.v)) {
uf.union(edge.u, edge.v);
roadCosts += road;
libCosts -= lib;
minCost = Math.min(minCost, roadCosts + libCosts);
}
}
System.out.println(minCost);
}
}
} MST
Kruskal (MST): Really Special Subtree



按照算法,右图的大括号里的已经是所有edges从小到大的排序。已知从最小的那个开始直到所有nodes都包含在一个Minimum Spanning Tree里:先是Edge(1,3), 到Edge(2,3),当到Edge(1,2)时,由于前面的两个Edges已经包含了1 与 2 这两个node,所以忽略Edge(1,2);到Edge(3,4), 然后到Edge(1,4),由于前面也已经包含了Node 1 和 4,所以忽略Edge(1,4), 到Edge(2,4)同理,也被忽略。则最后只留有:
Edge(1,3) +Edge(2,3)+Edge(3,4) = 3+4+5 = 12
- 这个算法的time complexity 由Sort来决定。因为在找MST时的For loop只为Edge的数量级,很少很简单。
