用python读取股票价格_我用Python分析股票价格走势,学以致用获取第一桶金!

【AI科技大本营导读】比来,A股市场尤其是上证指数走势凌厉,让营长有种身在牛市中的错觉。然而大盘天天涨,营长账户中仍是那几百万,甚至还有所缩水。夜深人静的时辰,营长经常会点着一支烟,考虑到底有没有一个完满的算法,可以预测股价的涨跌,如许就可以早日实现财务自由,走向人生顶峰。这时,一篇外国友人的文章成功引起了营长的注意,看完后备受启发,所以我们将其编译后,分享给大师,尤其是天天编码的轨范员。
交情提示:股市有风险,投资需谨严。营长忘了说,几十亿津巴布韦比。
对数据科学家来说,预测证券市场走势是一项很是有勾引力的工作,固然,他们如许做的目的很洪流平上并不是为了获取物质报答,而是为了挑战本身。证券市场起升沉伏、变幻莫测,试想一下,若是在这个市场里存在一些我们或者我们的模子可以进修到的既定形式,让我们可以打败那些商科毕业的操盘手,将是何等美好。固然,当我一起头使用加性模子(additive model)来做时辰序列预测时,我不得不先用模仿盘来验证我的模子在股票市场上的默示。
一众挑战者们都希望在每日收益率上可以跑赢市场,可是大多数都失败了,我也未能幸免。不外,在这个过程中也学到了大量Python相干知识,网罗面向工具编程、数据措置、建模、以及可视化等等。同时,我也认清了一个事理,不要在每日收益率上锱铢必较,学会容忍恰当的短期亏损,放长线才能钓大鱼。

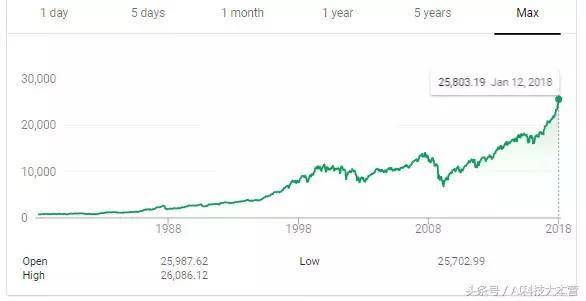
一天与三十年比力成效:你甘愿把钱投在哪里?
在任何使命中(不仅是数据科学),当我们没有获得立竿见影的成效时,我们都有三个选择:
1. 调解成效,让我们看起来像是成功了
2. 潜匿成效,所以没有人会注意到
3. 公开我们所有的成效和编制,以便其别人(以及我们本身)可以从中吸收经历和教训
显然,不管站在小我仍是社会层面,方案三都是最佳选择,但它同时也是最必要勇气去理论的。我可以选择性地公布成效,比如当我的模子可以带来丰厚的利润报答时,我也可以包庇失败的现实,假装本身从来没有在这项工作上花过时辰。这似乎是很无邪的设法!我们之所以可以前进是由于不竭频频失败——进修这个过程,而不仅仅是之前的成功。并且,为有难度的使命编写Python代码而付出的全力也并不该该空费!

这篇文章记实了我使用Python开发的“stock explorer”工具——Stocker的预测功能。此前,我曾展现了若何使用Stocker停止分析,并且将完好的代码贴在GitHub上,以便当大师。
Github代码地点:
https://github.com/WillKoehrsen/Data-Analysis/tree/master/stocker
▌实现预测的Stocker工具
Stocker是一款用于试探股票情形的Python工具。一旦我们安装了所需的库(检察文档),我们可以在剧本的统一文件夹中启动一个Jupyter Notebook,并导入Stocker类:

如今可以访谒这个类了。我们经由过程通报任一有效的股票代码(粗体是输出)来建树一个Stocker类的工具:

按照上面的输出成效,我们有20年的亚马逊每日股票数据可以用来试探! Stocker工具是建立在Quandl金融库上,并且拥有3000多只股票可以使用。我们可以使用plot_stock函数来绘制一个简单的历史股价图:


Stocker的分析功能可以用来创造数据中的团体趋向和形式,但我们将重点关注预测股票将来的价钱上。Stocker中的预测功能是使用一个加性模子来实现的,该模子将时辰序列视为季节性(如每日、每周和每月)的团体趋向组合。Stocker使用Facebook开发的智能软件包停止加性建模,用一行代码就可以建示范子并停止预测:


注意,表示预测成效的绿线包含了相对应的置信区间,这代表在模子预测的不确定性。在这种情形下,若是将置信区间宽度设置为80%,这意味着我们估量这个规模将包含实际值的可能性为80%。置信区间将跟着时辰进一步扩大,这是由于跟着预测时辰间隔现稀有据的时辰越来越远,预测值将面临更多的不确定性。任何时辰我们做如许的预测,都必需包含一个置信区间。虽然大多数人倾向于一个确定的值,但我们的预测成效必需反响出我们糊口在一个布满不确定性的世界!

任何人都可以做股票预测:简单地选择一个数字,而这就是你的估测(我可能是错的,但我敢必定,这是华尔街所有人都市做的)。为了让我们的模子具有可托度,我们必要评估它的切确性。Stocker工具中有良多用于评估模子切确度的编制。
▌评估预测成效
为了计较切确率,我们必要一个测试集和一个练习集。我们必要晓得测试集的谜底,也就是实际的股价,所以我们将使用曩昔一年的历史数据(本例中为2017年)。练习时,我们不选用2014-2016的数据来作为练习集。把守进修的根基思惟是模子从练习集中进修到数据中的形式和关系,然后可以在测试数据上精确地重现成效。
我们必要量化我们的切确率,所以我们使用了测试集的预测成效和实际值,我们计较的目标网罗测试集和练习集的美元均匀误差、精确预测价钱变化趋向的时辰百分比、以及实际价钱落在预测成效80%置信区间内的时辰百分比。所有这些计较都由Stocker主动完成,并且可视化了局很好:


可以看到,预测成效真是蹩脚透了,还不如直接抛硬币。若是我们按照这个预测成效来投资,那么我们最好是买买彩票,如许斗劲明智。可是,不要抛却这个模子,第一个模子通常斗劲蹩脚,由于我们使用的是默认参数(称为超参数)。若是我们最后的考试考试不成功,那么我们可以调解这些参数来获得一个更好的模子。在Prophet模子中有良多不合的参数设置必要调解,最重要的是变点先验标准(changepoint prior scale),它节制着模子在数据趋向上的偏移量。

▌变点先验(Changepoint Prior)的选择
变点代表时辰序列从添加到减少,或者从缓慢添加到越来越快(反之亦然)。它们呈如今时辰序列变化率最大的地方。变点先验标准体如今模子中给以变点的偏移量。这是用来节制过度拟合与欠拟合的(也被称为误差与方差间的权衡)。
一个更高的先验能创造一个更多变点权重和更具弹性的模子,但这可能会导致过拟合,由于该模子将严格服从练习数据的纪律,而不能将它泛化到新的测试数据中。降低先验会减少模子的矫捷性,而这又可能会导致相反的问题:欠拟合,当我们的模子没有完全服从练习数据,而没有进修到底层形式时,这种情形就会产生。若何找出恰当的参数以到达精确的平衡,这更多的是一个工程问题而不是理论问题,在这里,我们只能依靠经历成效。Stocker类有两种不合的编制来选择恰当的先验:可视化和量化。 我们可以从可视化编制起头:


在这里,我们使用三年的数据停止练习,然后表示了六个月的预测成效。我们没有量化这里的预测成效,由于我们只是试图去理解变点先验值的浸染。这个图表很好地说了然过拟合与欠拟合!代表最小先验的蓝线与代表练习数据的黑线值并不是非常接近,就仿佛它有本身的一套形式,并在数据的四周随意选了一条道路。比力之下,代表最大先验的黄线,则与练习察算作果很是切近。变点先验的默认值是0.5,它落在两个极值之间的某处。
我们还要注意先验值不合带来的不确定性(暗影区间)方面的差异。最小的先验值在练习数据上默示有最大的不确定性,但在测试数据上的不确定性却是最小。比力之下,最大的先验值在练习数据上具有最小的不确定性,但在测试数据上却有最大的不确定性。先验值越高,对练习数据的拟合就越好,由于它紧跟每次的不雅观不雅观察值。可是,当使用测试数据时,过拟合模子就会由于没有任何数据点来定位而迷失掉。由于股票具有相称多的变化性,我们可能必要比默认模子更矫捷的模子,如许才能够捕捉尽可能多的形式信息。
如今我们对先验值带来的影响有了一个概念,我们可以使用练习集和验证集对数值停止评估:

在这里,我们必需注意到,我们的验证集和测试集是不一样的数据。若是它们是一样的,那么我们会获得在测试数据上了局最好的模子,可是它只是在测试数据上过拟合了,而我们的模子也不能用于实际世界的数据。总的来说,就像在数据科学中通常所做的那样,我们正在使用三组不合的数据:练习集(2013-2015)、验证集(2016)和测试集(2017)。
我们用四个目标来评估四个先验值:练习误差、练习规模(置信区间)、测试误差和测试规模(置信区间),所有的值都以美元为单位。正如我们在图中看到的那样,先验值越高,练习误差越低,练习数据的不确定性越低。我们也可以看到,更高的先验能降低我们的测试错误。为了在测试集上获得更高的切确率,作为交流,跟着先验的添加,我们在测试数据上获得了更大规模的不确定性。
Stocker先验验证还可以经由过程两条线来阐述这些点:

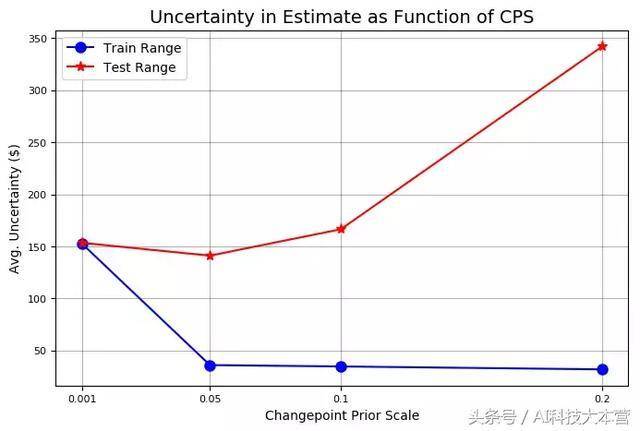
基于不合变点先验标准下,练习和测试切确性曲线和不确定性曲线
既然最高的先验值产生了最低的测试误差率,我们应该考试考试再添加先验值来看看是否能获得更好的成效。我们可以经由过程在验证中参加其它值的编制来优化我们的搜索:


改进后的练习和测试曲线
领先验值为0.5时,测试集的错误率将最小化。是以我们将重新设置Stocker工具的变点先验值。
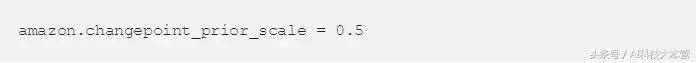
我们可以调解模子的其他参数,比如我们期望看到的形式,或者模子使用的练习数据。找到最佳组合只必要频频上述过程,并使用一些不合的值。请随意考试考试肆意的参数!
▌评估改进的模子
如今我们的模子已经优化好了,我们可以再次评估它:


如今看起来良多若干好多了! 这表示了模子优化的重要性。使用默认值可以供给第一次合理揣测,可是我们必要确定,我们正在使用精确的模子“设置”,就像我们试图经由过程调解平衡和淡入淡出来优化立体声的声音那样(很抱愧引用了一个过时的例子)。
▌玩转股票市场
股票预测是一个幽默的理论,但真正的乐趣在于不雅观不雅观察这些预测成效在实际市场中会阐扬多好的浸染。使用evaluate_prediction函数,我们可以在评估时代使用我们的模子“玩一玩”股票市场。我们将使用模子预测给出的计策,与我们在整个时代简单地采办和持有股票的计策停止一个比力。
我们的计策轨则很简单,如下:
1、当模子预测股价会上涨的那一天,我们起头买入,并在一天竣事时卖出。当模子预测股价下跌时,我们就不买入任何股票;
2、若是我们采办股票的价钱在当天上涨,那么我们就把股票上涨的幅度乘以我们采办的股票的数目;
3、若是我们采办的股票价钱下跌,我们就把下跌的幅度乘以股票的数目,计作我们的损失。
在整个评估时代,也就是2017年,我们天天以如许的编制停止股票把持。将股票的数目添加进模子回馈里面,Stocker就会以数字和图表表示的编制告诉我们这个计策是若何停止的:


上图告诉了我们一个很是贵重的计策:买入并持有!虽然我们可以在计策上再作出相称大的调解,但更好的选择是长期投资。
我们可以考试考试其他的测试时辰段,看看有没有什么时辰我们的模子给出的计策能胜过买入和持有的编制。我们的计策是斗劲保守的,由于当我们预测市场下跌的时辰我们不息止把持,所以当股票下跌的时辰,我们等待有比持有计策更好的编制。

不息用假造货泉考试考试
我就晓得我们的模子可以做到这一点!不外,我们的模子只需在已经有了当天的数据时才能按捺市场,也就是说还只是事后诸葛亮。
▌对股票将来价钱的预测
如今我们有了一个像样的模子,然后就可以使用predict_future()函数来对股票将来价钱的停止预测。

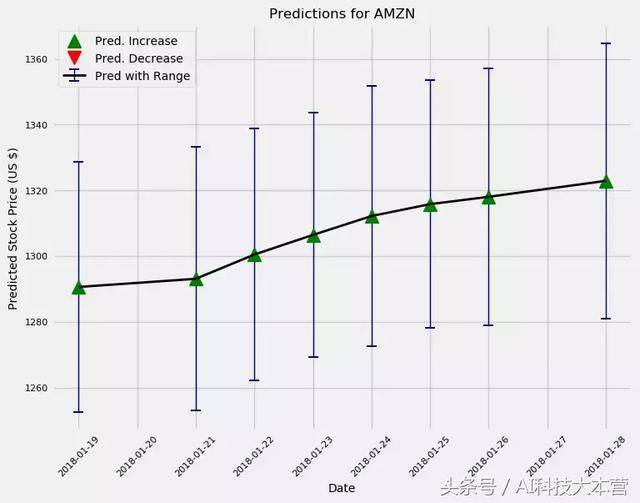

预测接下来10天和100天的股票价钱趋向
这个模子和大多数“专业人士”一样,总体上看好Amazon这支股票。别的,我们按照预期做出的估量,不确定性会进一步添加。实际上,若是我们使用这个模子计策停止生意,那我们天天都可以练习一个新的模子,并且提早预测最多一天的价钱。
虽然我们可能没有从Stocker工具中获得丰厚的收益,可是重点在于开发过程而不是终极成效! 在我们考试考试之前,我们实际上不晓得本身是否能处理如许一个问题,就算终极失败,也好过从不考试考试!任何有乐趣搜检代码或使用Stocker工具的人,都可以在GitHub上找到代码。(https://github.com/WillKoehrsen/Data-Analysis/tree/master/stocker)
好了,今天的知识就分享到这里,欢迎关注爱编程的南风,私信关键词:学习资料,获取更多学习资源,如果文章对你有有帮助,请收藏关注,在今后与你分享更多学习python的文章。同时欢迎在下面评论区留言如何学习python。