git 原理简介
文章目录
-
- 关于版本控制
- 分为三种版本控制方案
-
- 本地版本控制
- 集中化的版本控制
- 分布式版本控制
- git基本底层原理
- git提交流程原理
- Git的引用(分支)
- git log原理
- 总结
- 参考链接
关于版本控制
- 什么是“版本控制”?我为什么要关心它呢? 版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。
在本书所展示的例子中,我们对保存着软件源代码的文件作版本控制,但实际上,你可以对任何类型的文件进行版本控制。- 作用:
如果你是位图形或网页设计师,可能会需要保存某一幅图片或页面布局文件的所有修订版本(这或许是你非常渴望拥有的功能),采用版本控制系统(VCS)是个明智的选择。 有了它你就可以将选定的文件回溯到之前的状态,甚至将整个项目都回退到过去某个时间点的状态,你可以比较文件的变化细节,查出最后是谁修改了哪个地方,从而找出导致怪异问题出现的原因,又是谁在何时报告了某个功能缺陷等等。 使用版本控制系统通常还意味着,就算你乱来一气把整个项目中的文件改的改删的删,你也照样可以轻松恢复到原先的样子。 但额外增加的工作量却微乎其微。
分为三种版本控制方案
本地版本控制
例如:
许多人习惯用复制整个项目目录的方式来保存不同的版本,或许还会改名加上备份时间以示区别。
这么做唯一的好处就是简单,但是特别容易犯错。 有时候会混淆所在的工作目录,一不小心会写错文件或者覆盖意想外的文件。
为了解决这个问题,人们很久以前就开发了许多种本地版本控制系统,大多都是采用某种简单的数据库来记录文件的历次更新差异。

其中最流行的一种叫做 RCS,现今许多计算机系统上都还看得到它的踪影。 RCS 的工作原理是在硬盘上保存补丁集(补丁是指文件修订前后的变化);通过应用所有的补丁,可以重新计算出各个版本的文件内容。
问题:显而易见的漏洞 ,如何让在不同系统上的开发者协同工作
集中化的版本控制
于是,集中化的版本控制系统(Centralized Version Control Systems,简称 CVCS)应运而生。
这类系统,诸如 CVS、Subversion 以及 Perforce
等,都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
多年以来,这已成为版本控制系统的标准做法。
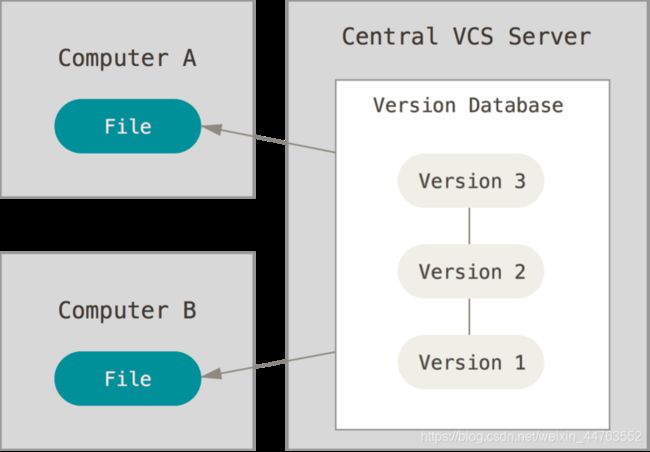
这种做法带来了许多好处,特别是相较于老式的本地 VCS 来说。 现在,每个人都可以在一定程度上看到项目中的其他人正在做些什么。 而管理员也可以轻松掌控每个开发者的权限,并且管理一个 CVCS 要远比在各个客户端上维护本地数据库来得轻松容易。
事分两面,有好有坏。 这么做最显而易见的缺点是中央服务器的单点故障。 如果宕机一小时,那么在这一小时内,谁都无法提交更新,也就无法协同工作。 如果中心数据库所在的磁盘发生损坏,又没有做恰当备份,毫无疑问你将丢失所有数据——包括项目的整个变更历史,只剩下人们在各自机器上保留的单独快照。 本地版本控制系统也存在类似问题,只要整个项目的历史记录被保存在单一位置,就有丢失所有历史更新记录的风险。
分布式版本控制
于是分布式版本控制系统(Distributed Version Control System,简称 DVCS)面世了。
在这类系统中,像
Git、Mercurial、Bazaar 以及 Darcs 等,客户端并不只提取最新版本的文件快照,
而是把代码仓库完整地镜像下来,包括完整的历史记录。
这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。
因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。

更进一步,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
这就是git 分布式版本系统的优势。
git基本底层原理
Git的核心是它的对象数据库,其中保存着git的对象,其中最重要的是blob、tree和commit对象,blob对象实现了对文件内容的记录,tree对象实现了对文件名、文件目录结构的记录,commit对象实现了对版本提交时间、版本作者、版本序列、版本说明等附加信息的记录。这三类对象,完美实现了git的基础功能:对版本状态的记录。
blob数据对象记录内容,tree对象记录文件名和文件目录结构,commit对象记录版本的信息
git提交流程原理
git add 添加文件到暂存区,并且创建数据对象添加到tree对象中且记录到git数据库 (作用)
Git根据某一时刻暂存区所表示的状态创建并记录一个对应的树对象(一个暂存区对应一个tree对象)
git commit (作用)
然后把以上的tree对象添加到commit 对象中记录到git 数据库中。
bolob(文件)>tree(目录)>commit(汇总提交和提交信息)>Git数据库
每次我们运行 git add 和 git commit 命令时, Git 所做的实质工作是将被改写的文件保存为数据对象,更新暂存区,记录树对象,最后创建一个指明了顶层树对象和父提交的提交对象。 这三种主要的 Git 对象——数据对象、树对象、提交对象——最初均以单独文件的形式保存在 .git/objects 目录下(对象数据库)。
Git的引用(分支)
Git的引用(references)保存在.git/refs目录下。git的引用类似于一个指针,它指向的是某一个hash键值。
创建一个引用实在再简单不过。我们只需把一个git对象的hash键值保存在以引用的名字命名的文件中即可。
分支
创建一个新分支:它只是为你创建了一个可以移动的新的指针
分支指针指向commit对象集中的某一个对象而已。
这里我要说一个容易被误导的地方:
我们创建一个新分支会感觉此分支是一个独立的单元,其实分支指针和commit集是一对一的关系,只是commit集根据时间序列排列,分支的指针会自动指向最新的commit对象。
区别在于不同分支指向的commit对象前后顺序不同而已。有新有旧的commit
这基本就是 Git 分支的本质:一个指向某一系列提交之首的指针或引用。 (分支也就是一个指针或引用)
合并分支分为三种情况:
- 快进步合并:
基于master创建的hosfix分支合并 (master指针向右移动至hotfix最新commit对象)
注意:快进步合并方式会把hotfix的所有commit记录合并至master,其原理是在master源commit节点C2 处追加了hotfix分支的所有commit记录并且将master指针向右移动至最新的commit记录

2. hotfix合并到master后,现需要iss53分支合并到master,但是iss53分支并没有hotfix分支commit记录
出现这种情况的时候,Git 会使用两个分支的末端所指的快照(C4 和 C5)以及这两个分支的公共祖先(C2),做一个简单的三方合并。
三方合并:
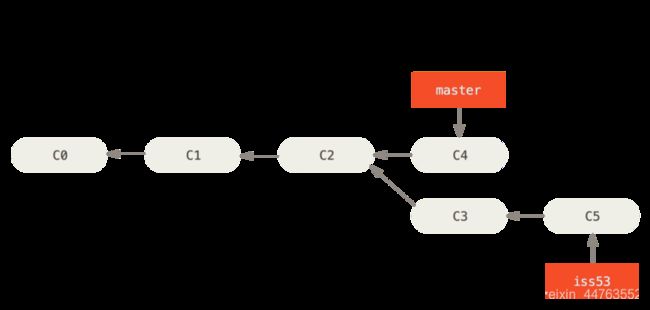
一次典型合并中所用到的三个快照
和之前将分支指针向前推进所不同的是,Git 将此次三方合并的结果做了一个新的快照并且自动创建一个新的提交指向它。 这个被称作一次合并提交,它的特别之处在于他有不止一个父提交。
这种三方合并,类似于合并三个分支各自最新的commit代码,最后一次性做一次提交。 特殊之处在于,master分支有多个父commit节点 例如:C2、C4、C5
- 合并冲突
冲突的产生是因为在合并的时候,不同分支修改了相同的位置。所以在合并的时候git不知道那个到底是你想保留的,所以就提出疑问(冲突提醒)让你自己手动选择想要保留的内容,从而解决冲突,最后 重新创建 commit 合并提交。
git log原理
列出所有分支log及所有父节点commit
查找HEAD指针对应的分支,本例是master
找到master指针指向的快照,本例是785f188674ef3c6ddc5b516307884e1d551f53ca
找到父节点(前一个快照)c9053865e9dff393fd2f7a92a18f9bd7f2caa7fa
以此类推,显示当前分支的所有快照
总结
Git的核心是它的对象数据库,其中保存着git的对象,其中最重要的是blob、tree和commit对象,blob对象实现了对文件内容的记录,tree对象实现了对文件名、文件目录结构的记录,commit对象实现了对版本提交时间、版本作者、版本序列、版本说明等附加信息的记录。这三类对象,完美实现了git的基础功能:对版本状态的记录。
Git引用是指向git对象hash键值的类似指针的文件。通过Git引用,我们可以更加方便的定位到某一版本的提交。Git分支、tags等功能都是基于Git引用实现的。
参考链接
底层原理
底层原理2
git官网
git pull原理