TA入门笔记(十七)
参考
may佬《技术美术百人计划》
IMR, TBR, TBDR 还有GPU架构方面的一些理解
移动设备GPU架构知识汇总
图形3.4 延迟渲染管线介绍
渲染路径(Rendering Path)
决定光照的实现方式。简言之,就是当前渲染目标使用的光照流程
渲染方式
前向渲染(Forward Rendering)
在渲染每一帧时,每一个顶点/片元都要执行一次片元着色器中的代码,这时需要将所有的光照信息都传递到片元着色器中进行计算,包括了距离很远影响微乎其微的小型光源,会造成很大的浪费
待渲染几何体 → \rightarrow →顶点着色器 → \rightarrow →片元着色器 → \rightarrow →渲染目标


- 最亮的几个光源会被实现为像素光照
- 然后最多4个光源会被实现为顶点光照
- 剩下的光源会被实现为效率较高的球面调谐光照(Spherical Hamanic),这是一种模拟光照
延迟渲染(Deferred Rendering)
主要解决大量光照渲染的方案。实质上是先不迭代三角形做光照计算,而是先找出能看到的所有像素再去迭代光照,避免在看不到的三角形上造成浪费
延迟渲染将拆分为两个pass
- 第一个pass称为几何处理通路。首先将场景渲染一次,获取到待渲染对象的各种几何信息存储到名为G-buffer的缓冲区中,这些缓冲区将会在之后用作更复杂的光照计算。由于有深度测试,所以最终写入G-buffer中的各个数据都是离摄像机最近的片元的几何属性,这意味着最后在G-buffer中的片元必定要进行光照计算的
- 第二个pass称为光照处理通路。该pass会遍历所有G-buffer中的位置、颜色、法线等参数,执行一次光照计算
- 透明物体没有深度信息,所以还是以前向渲染的方式在最后渲染
待渲染几何体 → \rightarrow →顶点着色器 → \rightarrow →MRT → \rightarrow →光照计算 → \rightarrow →渲染目标


几何缓冲区G-buffer:主要用于存储每个像素对应的位置(Position),法线(Normal),漫反射颜色(Diffuse Color)以及其他有用材质参数
不同渲染路径的特性
- 后处理方式不同
- 需要深度信息进行后处理时,前向渲染需要单独渲染出一张深度图,而延迟渲染可以直接取G-buffer中的深度来进行计算
- 着色计算不同
- 延迟渲染的光照计算统一是在LightingPass计算的,所以只能算一个光照pass
- 抗锯齿方式不同
不同渲染路径的优劣
前向渲染:
- 缺点:
- 光源数量对计算 复杂度影响巨大
- 访问深度等数据需要额外计算
- 优点:
- 支持半透明渲染
- 支持使用多个光照pass
- 支持自定义光照计算方式
延迟渲染:
- 缺点:
- 对MSAA支持不友好
- 透明物体渲染存在问题
- 占用大量显存带宽
- 优点:
- 大量光照场景优势明显
- 只渲染可见像素,节省计算量
- 对后处理支持良好
- 用更少的shader
其他
渲染路径设置


移动端优化
两个TBDR:
-
一个是SIGGRAPH 2010上提出的基于延迟渲染的优化方式,通过分块来降低带宽和内存用量

-
一个是PowerVR基于手机GPU的TBR架构提出的,通过HSR(可见性测试)减少overdraw
GPU架构
常见的架构有三种:IMR,TBR和TBDR。其中IMR用于PC端的GPU渲染,TBR用于移动端,TBDR是基于TBR的改进
IMR(Immediate Mode Rending)

图中蓝色部分为渲染管线,灰色部分为GPU的显存,包括几何信息、纹理信息、深度buffer及Frame Buffer等。
渲染管线里的读写操作都是直接在显存和GPU中传输数据的,每一次渲染完的Color和Depth数据写回到Frame Buffer和 Depth Buffer都会产生很大的带宽消耗,所以IMR架构中也会有L1和L2之类的Cache来优化这部分大量的带宽消耗。
TBR

首先需要明确的是,移动端的GPU是没有显存的。上边的灰色部分为On_Chip Memory,可以理解为L1和L2缓存(GPU中的缓存结构);下边的灰色为系统内存
对于TBR来讲,整个光栅化和像素处理会被分为一个个Tile进行处理,通常为16×16大小的Tile。TBR的结构通过On-Chip Buffers来储存Tiling后的Depth Buffer和Color buffer。也就是原先IMR架构中对主存中Color/Depth Buffer进行的读写操作变成直接在GPU中的高速内存操作,减少了最影响性能的系统内存传输的开销。

TBR的实现策略是对于Cpu过来的绘制,只对他们做顶点处理,也就是上图中的Geometry Processor部分,产生的结果(Frame Data)暂时写回到物理内存,等到需要刷新整个Frame Buffer时,才会将这批绘制光栅化,做tile-based-rendering。从这点上看,其实TBR本质上也是一种延迟渲染,因此有的文章会把移动端GPU渲染架构统称为TBDR。
TBR和IMR的优劣
由于带宽消耗最大的DepthBuffer 和 ColorBuffer的读写都发生在On_Chip Memory上,所以TBR相比于IMR降低了带宽消耗,降低了功耗,提高了渲染效率,但是性能会有所下降;而IMR相当于舍弃了效率换取了更高的峰值性能。因此不用电池的,独显的会选IMR。但是要用电池,或追求性价比不舍得上独立显存(如游戏机),大概率会选择TBR。
TBDR
TBDR是PowerVR提出来的对TBR的一次改进,在TBR的基础上再加了一个Deferred
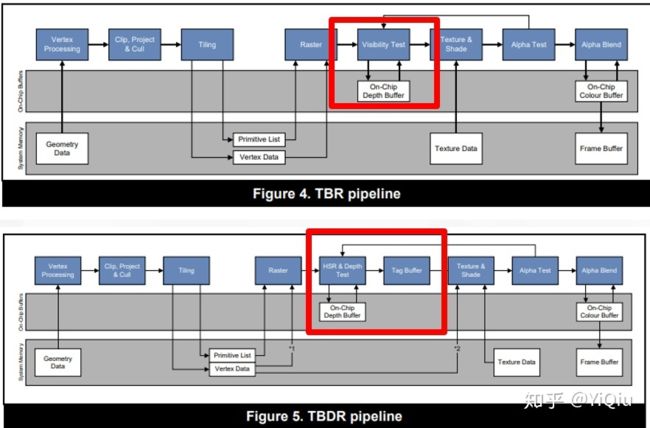
由于TBR的设计主要是用于减少IMR的带宽开销,overdraw的问题依旧没有解决。
通常用来解决overdraw的是early-Z技术,在绘制前先做深度检测,减少不必要的绘制。
但是early-Z无法完全避免overdraw。因为我们在真正对一个复杂场景去渲染的时候是不可能进行严格的由近到远的绘制的。如下图无法根据每个物体与摄像机的距离来对他们的绘制进行排序。

PowerVR提出了HSR,不需要在软件层面对物体进行排序,直接提供硬件级别的支持来解决OverDraw。当一个像素通过early-Z之后,先不进行绘制,而是只只记录标记这个像素归哪个图元来画。等到这个Tile上所有的图元都处理完了,最后再真正的开始绘制每个图元中被标记上能绘制的像素点。这样可以保证零overdraw。
 这一操作利用了TBR的特点,几何阶段处理后的结果存在FrameData中,必须到需要整个FrameBuffer的绘制时才会去着色,而HSR发生于着色前,拥有这批绘制需要的所有几何信息,并通过硬件提供了像素级别的深度测试,因此不需要关心eraly-Z当中的绘制顺序问题。
这一操作利用了TBR的特点,几何阶段处理后的结果存在FrameData中,必须到需要整个FrameBuffer的绘制时才会去着色,而HSR发生于着色前,拥有这批绘制需要的所有几何信息,并通过硬件提供了像素级别的深度测试,因此不需要关心eraly-Z当中的绘制顺序问题。
(作业)移动设备渲染通用优化建议
针对带宽的优化:
- 贴图格式能压缩就压缩 贴图内存越小,片上命中率就越高,总的传输量也少
- 能开mipmap就开mipmap(前提是能用到,UI贴图就不用开了)与减小实际使用的贴图内存是一个道理,但是会增加总贴图的内存占用大小,需要在内存开销和带宽开销上做一个平衡。
- 随机纹理寻址相对于相邻纹理寻址有显著开销 提高片上命中率。
- 3DTexture Sampling有显著的开销 3DTexture整体内存占用大,垂直方向相邻像素内存不相邻很容易cache miss,这是我个人推测。
- Trilinear/Anisotropic相对于Bilinear有显著的开销 Trilinear其实就相当于tex3D了(此结论不负责任),Bilinear相对于Point几乎没有额外开销(此结论负责任,texture fetch都是一次拿相邻的四个出来),所以Bilinear能忍就尽量凑合用着吧。
- 使用LUT(look up texture)很可能是负优化 需要对比权衡带宽占用+texture fetch操作增加与ALU占用增加降低并行效率,另外还很可能涉及到美术工作流和最终效果,所以是个不是很好进行操作的优化。之前看过腾讯的技术分享将引擎中Tonemapping那步的3DLUT(UE4和Unity都是这样的)替换为函数拟合的优化,理论上应该是会提升不少性能,但是要想真正应用到生产环境,保证效果,还要做好拟合工具链,是得费不少力气的
- 通道图能合并就合并,减少Shader中贴图采样次数
- 控制Framebuffer大小
- 总顶点数量也是带宽开销的影响因素 虽然以现在GPU的计算能力来说,顶点数增多产生的VS计算开销增加通常是忽略不计的。但是仍不能忽略总顶点数量对于VertexBuffer所消耗带宽的影响,对于总顶点数的限制应该更多的从带宽消耗上去进行测试和分析。
对于AlphaTest的优化:
- 只要Shader中包含discard指令的都会被GPU认为是AlphaTest图元(GPU对于AlphaTest绘制流程的判定是基于图元而不是像素)
- 无论是PowerVR还是Mali/Adreno芯片,AlphaTest图元的绘制都会影响整体渲染性能。
- 随着芯片的发展AlphaTest图元对于渲染性能的影响主要在于Overdraw增加而非降低硬件设计流程效率,其优化思路与AlphaBlend一样,就是少画
- 严格按照Opaque - AlphaTest - AlphaBlend的顺序进行渲染可以最大化减小AlphaTest对于渲染性能的影响。
- 将Opaque, AlphaTest与AlphaBlend打乱顺序渲染会极大的降低渲染性能,任何情况下都不应该这么做。
- 不要尝试使用AlphaTest替代AlphaBlend,这并不会产生太多优化。
- 不要尝试使用AlphaTest替代Opaque,这会产生负优化
- 不要尝试使用AlphaBlend替代AlphaTest,这会造成错误的渲染结果。
- 在保证正确渲染顺序情况下,AlphaTest与AlphaBlend开销相似,不存在任何替代优化关系
- 增加少量顶点以减少AlphaTest图元的绘制面积是可以提升一些渲染性能的。
- 首先统一绘制AlphaTest图元的DepthPrepass,再以ZTest Equal和不含discard指令的Shader统一绘制AlphaTest图元,大多数情况下是可以显著提升总体渲染性能的(需要实际测试)
其他渲染路径
延迟光照(Light Pre-Pass/Deferred Lighting)
- 使用更少的buffer信息,着色计算时使用的是forward
- 减少G-buffer占用的过多开销,支持多种光照模型

Forward+(即Tiled Forward Rending,分块正向渲染)
- 通过分块索引的方式以及深度和法线信息,对需要进行光照计算的片元进行光照计算
- 减少带宽,支持多光源,强制需要一个preZ进行深度预计算


群组渲染 (Clustered Rending) - 带宽相对减少,多光源下效率提升
MSAA
- DX9不支持
- 在延迟渲染中的问题在于像素已经被光栅化,无法再使用更大的像素来渲染
- https://catlikecoding.com/unity/tutorials/rendering/part-13/

不同path下光源shader编写

PreZ/Zprepass
是当eraly-Z失效时或需要深度图的时候一种手动替代的方案