UDP与TCP协议
很抱歉,我之前写好的UDP与TCP文章不小心被删了,所以,这篇文章只有一半,后面我会尽快补全。
在完成HTTPS的学习后,我们就完成了应用层的所有讲解,下面我们开始讲解传输层,这一层常用的协议为TCP和UDP。
一、再谈端口号
1.端口号
端口号(port)标识了一个主机上进行通信的不同的应用程序。
如图所示,在一个机器上运行着许多进程,每个进程使用的协议都不一样,比如FTP,SSH,SMTP,HTTP,FTP等。

正是因为每一个进程都有自己的端口号(如图中TCP21,TCP22这些,后面的数字就是端口号)当发来的数据从网络中传输到应用层后,操作系统就能根据端口号将数据交给对应的进程。
2.五元组
TCP/IP协议是传输数据常用的协议,它会用 “源IP”、“源端口号”、“目的IP”、“目的端口号”、“协议号” 这样一个五元组来标识一个通信。
如下图所示,客户端A打开了两个浏览器页面(可认为是两个进程)向服务器分别发送数据1和数据2。所以在这两份数据的五元组中,源IP地址都是客户端A的IP地址,目标IP地址都是服务器的IP地址,源端口号分别是2001和2002,它们能标识这两个进程,目标端口号都是服务端的HTTP进程,HTTP使用的端口号是80。
客户端B也打开一个浏览器页面(可认为是一个进程)向服务器发送的数据3。所以在这份数据的五元组中,源IP地址就是客户端B的IP地址,目标IP是服务端的IP地址,源端口号是这个页面进程的端口号,目标端口号是服务器HTTP进程的端口号80。
协议号是通信协议的编号,指定的协议号可以标识一种协议,比如6号就标识TCP协议。
IP地址属于IP协议的内容,IP协议属于网络层,在传输层处不做讨论。
3.端口号划分
在前面编写套接字代码的时候,端口号的类型是uint16_t,本质是一个16位的无符号整数。由于这个整数的最大值是65535,所以端口号的范围是0~65535。
这些端口号可以分为知名端口号和操作系统动态分配的端口号。
(1)知名端口号
0~1023范围内的端口号叫做知名端口号,这些端口号常被固定的服务绑定,如HTTP、FTP、SSH等这些广为使用的应用层协议,他们的端口号都是固定的。由于应用层协议本质上是进程在使用,所以在这里应用层协议、进程可以看作是等价的。
可以这样理解,110对应的是报警电话,120对应的是急救电话,119是火警电话,这些号码已经跟这些公共服务强绑定了。这些放在端口号上也一样,0~1023这些端口号都有对应的协议,不能随便更改,就像报警电话不会随便更改一样。所以,我们自己写程序时,要避开0~1023这些知名端口号。
下面是一些服务的端口号:
| 服务 |
端口号 |
| SSH |
22 |
| FTP |
21 |
| TELNET |
23 |
| HTTP |
80 |
| HTTPS |
443 |
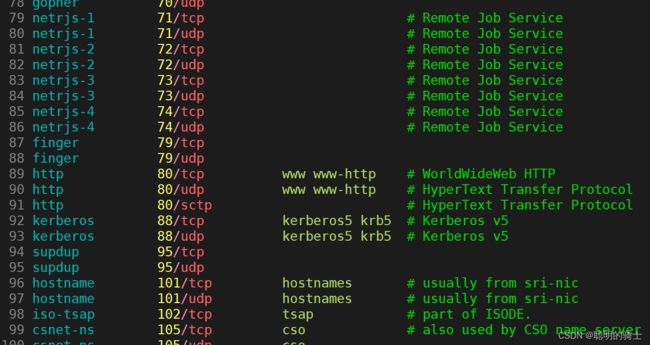
在Linux机器中,有一个文件/etc/services,它存储了所有具体端口号对应的服务协议。我截取了该文件的一部分,可以清楚地看到http的端口号是80。
(2)操作系统动态分配的端口号
剩下的1024~65535这些端口号就可以由我们指定去绑定某个进程,比如我们之前使用的8080、8081、8082这些。
除了自己用bind函数显式绑定,操作系统还可以自动从这些端口号中选择一个分配给某个进程。比如说,我们之前写的客户端的套接字就并没有使用bind绑定端口号,在调用sendto函数时,操作系统就会自己从1024~65535中随机指定一个端口号绑定。
(3)端口号与进程之间的关系
由于端口号是标识一个进程的标识符,所以根据一个端口号必须找到一个唯一的进程。
换句话说,一个端口号不能被多个进程绑定。
因为一个进程绑定多个端口号并不破坏一个端口号必须找到一个唯一的进程的特性。
所以,一个进程可以绑定多个端口号。
4.一些Linux指令
(1)netstat
netstat指令前面已经用过好多次。
语法:netstat+[选项](例:netstat -lntp)
功能:可用于查看当前机器的网络状态。
常用选项:
- n 拒绝显示别名,能显示数字的全部转化成数字
- l 仅列出有在 Listen (监听) 的服務状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项,默认不显示LISTEN相关
(2)pidof
还有一个指令pidof使用起来也非常的方便。
语法:pidof+[进程名](例:pidof server)
功能:得到进程名对应的pid值。
我们之前查看进程的pid时总需要用使用ps ajx查看所有进程,还要自己找对应的进程。现在直接使用pidof就能返回进程的pid。

还有我们如果想对进程进行处理,往往都需要它的pid,pidof与其他指令异同使用会很方便。我以终止进程为例。
我们的httpserver还在运行,想中止它,我们可以输入pidof httpserver | xargs kill -9,其中xargs表示把管道传送过来的数据追加到后面的语句中。这样整个语句就变为kill -9 pid,从而终止进程。
![]()
二、UDP
1.协议格式
下图就是UDP协议的格式,前八个字节属于协议报头,之后的是有效载荷。

UDP协议的前八个字节作为报头,64个比特位。其中这八个字节的前16位0-15存放的是源端口号,第16~31位存放目的端口号,32~47位存放的是UDP的长度,48~64位存放的是UDP校验和。
- 16位源端口号:表示发送端(客户端)的端口号。
- 16位目的端口号:表示接收端(服务端)的端口号。
- 16位UDP长度:整个UDP数据段(报文)的长度,包括报头和有效载荷,UDP数据段最大64KB。
- 16位校验和:由操作系统进行校验,如果发送方和接收方的校验和不一致,说明出错,就会丢弃整个UDP数据段。
UDP数据段最长不能超过64KB,所以如果传输的数据超过了64KB,就需要用户在应用层手动将数据分成多个大小小于等于64KB的数据包,并进行多次发送,在接收端用户也需要手动将各分包重新拼装。
2.解包和分用
解包的最关键问题在于如何把报头和有效载荷进行分离,而分用最关键的在于计算机收到的信息怎么传递给需要的进程。
(1)解包
UDP协议是传输层协议,由操作系统维护,而Linux操作系统又是由C语言写的,所以UDP的报头一定会在操作系统中有自己的结构化数据,我们如果自己写一个结构体描述差不多就是这样:
struct udp_hdr
{
uint16_t src_port;//16位源端口号
uint16_t dest_port;//16位目的端口号
uint16_t length;//16位UDP长度
uint16_t check;//16位UDP校验和
};
当然将各变量改为unsigned int src_port:16;这样的结构也可以。
以C语言的知识理解报头与有效数据的分离,我们可以认为当计算机接收UDP数据时,该数据会先放在操作系统的已创建的内核缓冲区内(最大为64KB)。然后创建一个hdr指针指向UDP报头起始位置,再再偏移报头字节数(sizeof(udp_hdr))构建一个start指针指向内核中有效载荷的起始位置。最后根据报头的结构化数据将数据将各个数据(包括正文内容)拷贝到内存,这样就能实现了分离。
上面过程的伪代码:
char* hdr = malloc(XXX);//操作系统创建内核缓冲区
char* start = hdr + sizeof(struct udr_hdr);//指向有效载荷
strcpy(start,buffer,len);//将用户缓冲区中数据复制到内核缓冲区有效载荷处。
(struct udp_hdr*)hdr->src_port = xxx;//赋值源端口
(struct udp_hdr*)hdr->dest_port = xxx;//赋值源端口
(struct udp_hdr*)hdr->length = xxx;//赋值源端口
(struct udp_hdr*)hdr->check = xxx;//赋值源端口(2)分用
分用时,操作系统中已经维护了一个哈希表,使用绑定的端口号作为key值,就能直接找到这个进程,将有效载荷交给进程即可。所以,进程只要使用网络就一定要绑定端口号,不管是否使用bind显式绑定,这个绑定的过程本质上就是将数据插入哈希表。
3.特点
UDP协议有以下特点:
(1)无连接:只需要指定目的IP和目的端口就可以直接进行传输,不需要建立连接。
(2)不可靠:没有确认机制,没有重传机制,如果因为网络故障该数据段无法发到对方,UDP协议层也不会给应用层返回任何错误信息。
UDP发送数据的方式就像发邮件,发送者只管发出去,至于对方能不能收到完全不关心。
(3)面向数据报:不能够灵活控制读写数据的次数和数量。
- 应用层交给UDP多长的报文,UDP原样发送,既不拆分,也不合并。
- UDP发送数据段时,一次性将内核缓冲区中的数据全部发送出去。
- 接收端会一次性接收发送端发送的所有数据,不能分多次接收。
比如快递,你发快递只能一个一个发,不能先发半个,然后再发半个。收快递也是,不能先收半个,然后再收半个,只能一个个完整的快递进行收发。
4.TCP缓冲区
我需要先解释TCP的缓冲区,然后UDP的缓冲区我们就更好理解了。
还记得之前用过的send/sendto、recv/recvfrom这样的的接口吗?这些系统调用直接就能把数据发出去了?
结论当然是否定的。系统调用的工作在操作系统和用户应用的界限之间,而在网络的分层模型中,数据会一层一层向下传递并在物理层发出,所以这些系统调用的任务一定是从应用层将数据向操作系统传递。
在TCP协议中,操作系统会为通信双方各自维护一个发送缓冲区,一个接收缓冲区。用户层在调用send/sendto函数之后,操作系统会自动对需要发送的内容拼接TCP报头(TCP报头的具体内容后面会讲)形成数据段,然后拷贝到到发送缓冲区中。
同样,本主机从对端主机收到数据段后,也会先将其放入接收缓冲区中。当用户层读使用recv/recvfrom这样的系统调用时,系统调用就会将接收缓冲区内的数据拷贝到应用层中,具体点说就是拷贝到接收数据的字符串中。

所以,send/sendto、recv/recvfrom本质上是一个拷贝接口,它们前者负责将应用层的数据拷贝到发送缓冲区,后者负责将数据从接收缓冲区拷贝到应用层。
在两个缓冲区中的数据由TCP的内部代码进行发送和接收,用户只负责将数据放入或拿出这两个缓冲区。正是因为数据的传输无需用户参与,所以TCP的全名叫做传输控制协议。
而且这两个缓冲区使得通信双方进程在同一时刻,既可以发送数据,也可以接收数据,且互不影响,我们称之为全双工。
5.UDP缓冲区
UDP协议与TCP相似,只是少了一个发送缓冲区。当客户端使用UDP协议将用户层的数据使用sendto发送的时候,数据会被直接拷贝到内核中,经过一定处理后立即发出。
在使用UDP协议接收数据时,操作系统将发送来的数据存放在接收缓冲区中,在适当的时候,操作系统会将数据交给用户层。
UDP的信息传输方式也实现了发送和接收数据同时进行和互不干扰,也叫做全双工。

6.常见的基于UDP的应用层协议
| 缩写 |
全名 |
| NFS |
网络文件系统 |
| TFTP |
简单文件传输协议 |
| DHCP |
动态主机配置协议 |
| BOOT |
启动协议(用于无盘设备启动) |
| DNS |
域名解析协议 |
上面这些协议在传输层都是使用的UDP协议,其中很多我们天天都在用。
比如说DNS域名解析协议,我们之前说url中像baidu.com这样的域名本质上是该网站服务器的IP地址。

当我们在浏览器地址栏中输入某个Web服务器的域名时。用户主机首先用户主机会首先在自己的DNS高速缓存中查找该域名所应的IP地址。
如果没有找到,则会使用UDP协议向网络中的某台DNS服务器发送该域名IP地址的查询请求,DNS服务器中有域名和IP地映射关系的数据库。当DNS服务器收到DNS查询报文后,在其数据库中查询,之后将查询的IP地址发送给用户主机。
此时,用户主机中的浏览器可以通过Web服务器的IP地址对其进行访问了。
三、TCP
TCP全称为 “传输控制协议(Transmission Control Protocol”).,它可以对数据的传输进行细致的控制。
1.协议格式
如图所示,TCP协议格式包括20位固定长度数据、选项和数据,其中前20字节加上选项组成报头。我们在这里不讲解选项的内容,你只需要知道这部分不是定长的就可以了。

- 16位源端口号:发送方进程的端口号。
- 16位目的端口号:接收方进程的端口号。
- 32位序号和32位确认号: 后面讲。
- 4位首部长度: 表示该TCP报头的长度,是一个无符号整数。TCP报头所占字节数=首部长度 * 4,又因为4比特位的无符号整数最大值为15,所以TCP的最大头部长度是15 * 4 = 60字节。
- 6位标志位:标识TCP数据段的类型,包括URG、ACK、PSH、RST、SYN和FIN,每个都是一个标志位且各自有各自的功能。
- 16位窗口大小:表示滑动窗口的大小,后面再讲解。
- 16位校验和:发送端填充CRC校验。接收端校验不通过, 则认为数据有问题,此处的检验和不仅包含TCP首部,也包含TCP数据部分。
- 16位紧急指针:标识哪部分数据是紧急数据(带外数据)。
TCP协议同样内置于操作系统中,它的报头也是一个C语言编写的结构化数据,只是结构体中的成员变量大小和类型与UDP不同而已。
struct tcp_hdr
{
uint32_t src_port:16;
uint32_t dest_port:16;
uint32_t seq;
uint32_t ack_seq;
uint32_t header_length:4;
......
};2.解包和分用
TCP的解包与UDP很相似,TCP的报头已经有20字节被固定占用,报头的剩余部分是长度不固定的选项。
所以我们先建立一个指针p1指向这20各字节,可以通过指针访问这些数据。
在TCP报头中存有首部长度,通过首部长度乘以4就得到了报头的字节数,头部长度*4 - 20 = 选项长度,此时我们就可以根据选项的长度构建另一个指向选项头部的指针p2,即p1后移20字节,可以获取选项的内容。
最后根据报头字节数将p1后移构建指针p3,获取正文的内容。
最后分用和之前一样,根据端口号在哈希表中对应进程即可。
3.缓冲区
TCP缓冲区前面已经说过了,操作系统维护了一个发送缓冲区,一个接收缓冲区,实现了全双工。
什么时候将数据段从发送缓冲区发出去,什么时候将数据从接收缓冲区交给应用层?
一次从缓冲区发送多少个字节的数据,一次接受多少数据?
这些全部由内置在操作系统中的TCP协议自行决定。所以说,TCP作为传输控制协议对数据的收发完全自主。
4.面向字节流
我们常说TCP面向字节流的,这又是什么意思呢?
TCP不像UDP那样,一次必须发送或者接收一个完整的数据段。TCP发送与接收数据以字节为单位,不考虑接收到的数据是不是一个完整的数据段。这些流动的字节像河流一样,所以说TCP是面向字节流的。
5.网络协议和协议栈
如下图所示,应用层协议本质上就是进程,而每个进程都有pid,需要使用网络的进程还有一个或多个端口号port,操作系统会维护一个哈希表。操作系统会根据所有使用网络的进程构造(port:pid)的键值对存放在哈希表中,port是key值,pid是value。
在操作系统完成数据段的解包以后,会根据TCP协议中的目的port在哈希表中查找对应进程的pid,有了pid操作系统就能找到PCB,而PCB的文件描述符表中必定有一个fd指向的文件是一个网络套接字。
而套接字本质上也是个文件,所以也会存在一个struct file结构体来管理它,该结构体中的读写缓冲区其实就是TCP协议的接收和发送缓冲区。
最后,将TCP层解包后的有效载荷放入找到的struct file的接收缓冲区中。此时分用中最重要的将数据交给对应进程的任务就完成了,应用层就可以根据文件描述符fd用read读取有效载荷(报文)了,这就完成了数据的接收。
发送的过程也是一样,不过是走了相反的方向。
