Python 函数用法和底层分析
目录
- 1 函数简介
-
- 1.1 函数的基本概念
- 1.2 Python函数的分类
- 2 函数的定义和调用
-
- 2.1 核心要点
- 2.2 形参和实参
- 2.3 文档字符串(函数的注释)
- 2.4 返回值
- 3 函数也是对象,内存底层分析
- 4 变量的作用域(全局变量和局部变量)
- 5 局部变量和全局变量效率测试
- 6 参数的传递
-
- 6.1 传递可变对象的引用
- 6.2 传递不可变对象的引用
- 6.3 浅拷贝和深拷贝
- 6.4 传递不可变对象包含的子对象是可变的情况
- 7 参数的几种类型
-
- 7.1 位置参数
- 7.2 默认值参数
- 7.3 命名参数
- 7.4 可变参数
- 7.5 强制命名参数
- 8 lambda表达式和匿名函数
- 9 eval()函数
- 10 递归函数
- 11 嵌套函数(内部函数)
-
- 11.1 nonlocal关键字
- 12 LEGB规则
函数是可重用的程序代码块。函数的作用,不仅可以实现代码的复用,更能实现代码的一致性。一致性指的是,只要修改函数的代码,则所有调用该函数的地方都能得到体现。
在编写函数时,函数体中的代码写法和我们前面讲述的基本一致,只是对代码实现了封装,并增加了函数调用、传递参数、返回计算结果等内容。
为了让大家更容易理解,掌握的更深刻。我们也要深入内存底层进行分析。绝大多数语言内存底层都是高度相似的,这样大家掌握了这些内容也便于以后学习其他语言。
1 函数简介
1.1 函数的基本概念
- 一个程序由一个个任务组成;函数就是代表一个任务或者一个功能。
- 函数是代码复用的通用机制。
- 函数也是对象,底层机制和变量类似
1.2 Python函数的分类
Python中函数分为如下几类:
- 内置函数
我们前面使用的str()、list()、len()等这些都是内置函数,我们可以拿来直接使用。 - 标准库函数
我们可以通过import语句导入库,然后使用其中定义的函数 - 第三方库函数
Python社区也提供了很多高质量的库。下载安装这些库后,也是通过import语句导入,然后可以使用这些第三方库的函数 - 用户自定义函数
用户自己定义的函数,显然也是开发中适应用户自身需求定义的函数。今天我们学习的就是如何自定义函数。
2 函数的定义和调用
2.1 核心要点
Python中,定义函数的语法如下:
def 函数名 ([参数列表]) :
'''文档字符串'''
函数体/若干语句
要点:
- 我们使用def来定义函数,然后就是一个空格和函数名称;
(1) Python执行def时,会创建一个函数对象,并绑定到函数名变量上。 - 参数列表
(1) 圆括号内是形式参数列表,有多个参数则使用逗号隔开
(2) 形式参数不需要声明类型,也不需要指定函数返回值类型
(3) 无参数,也必须保留空的圆括号
(4) 实参列表必须与形参列表一一对应 - return返回值
(1) 如果函数体中包含return语句,则结束函数执行并返回值;
(2) 如果函数体中不包含return语句,则返回None值。 - 调用函数之前,必须要先定义函数,即先调用def创建函数对象
(1) 内置函数对象会自动创建
(2) 标准库和第三方库函数,通过import导入模块时,会执行模块中的def语句
我们通过实际定义函数来学习函数的定义方式。
2.2 形参和实参
形参和实参的要点,请参考上一节中的总结。在此不再赘述。
【操作】定义一个函数,实现两个数的比较,并返回较大的值。
def printMax(a,b):
'''实现两个数的比较,并返回较大的值'''
if a>b:
print(a,'较大值')
else:
print(b,'较大值')
printMax(10,20)
printMax(30,5)
执行结果:
20 较大值
30 较大值
上面的printMax函数中,在定义时写的printMax(a,b)。a和b称为“形式参数”,简称“形参”。也就是说,形式参数是在定义函数时使用的。 形式参数的命名只要符合“标识符”命名规则即可。
在调用函数时,传递的参数称为“实际参数”,简称“实参”。上面代码中,printMax(10,20),10和20就是实际参数。
2.3 文档字符串(函数的注释)
程序的可读性最重要,一般建议在函数体开始的部分附上函数定义说明,这就是“文档字符串”,也有人成为“函数的注释”。我们通过三个单引号或者三个双引号来实现,中间可以加入多行文字进行说明。
【操作】测试文档字符串的使用
def print_star(n):
'''根据传入的n,打印多个星号'''
print("*"*n)
help(print_star)
help(print_star.__doc__)
我们调用help(函数名.doc)可以打印输出函数的文档字符串。执行结果如下:
Help on function print_star in module __main__:
print_star(n)
根据传入的n,打印多个星号
No Python documentation found for '根据传入的n,打印多个星号'.
2.4 返回值
return返回值要点:
- 如果函数体中包含return语句,则结束函数执行并返回值;
- 如果函数体中不包含return语句,则返回None值。
- 要返回多个返回值,使用列表、元组、字典、集合将多个值“存起来”即可。
【操作】定义一个打印n个星号的无返回值的函数
def print_star(n):
print("*"*n)
print_star(5)
【操作】定义一个返回两个数平均值的函数
def my_avg(a,b):
return (a+b)/2
#如下是函数的调用
c = my_avg(20,30)
print(c)
3 函数也是对象,内存底层分析
Python中,“一切都是对象”。实际上,执行def定义函数后,系统就创建了相应的函数对象。我们执行如下程序,然后进行解释:
def test01():
print("sxtsxt")
test01() # 函数后面加括号,代表调用这个函数
c=test01
c()
print(id(test01))
print(id(c))
print(type(c))
执行结果:
sxtsxt
sxtsxt
2296084655984
2296084655984
<class 'function'>
上面代码执行def时,系统中会创建函数对象,并通过test01这个变量进行引用:

我们执行“c=test01”后,显然将test01变量的值赋给了变量c,内存图变成了:

显然,我们可以看出变量c和test01都是指向了同一个函数对象。因此,执行c()和执行test01()的效果是完全一致的。 Python中,圆括号意味着调用函数。在没有圆括号的情况下,Python会把函数当做普通对象。
与此核心原理类似,我们也可以做如下操作:
zhengshu = int
zhengshu("234")
显然,我们将内置函数对象int()赋值给了变量zhengshu,这样zhengshu和int都是指向了同一个内置函数对象。当然,此处仅限于原理性讲解,实际开发中没必要这么做。
4 变量的作用域(全局变量和局部变量)
变量起作用的范围称为变量的作用域,不同作用域内同名变量之间互不影响。变量分为:全局变量、局部变量。
全局变量:
- 在函数和类定义之外声明的变量。作用域为定义的模块,从定义位置开始直到模块结束。
- 全局变量降低了函数的通用性和可读性。应尽量避免全局变量的使用。
- 全局变量一般做常量使用。
- 函数内要改变全局变量的值,使用global声明一下
- 储存在栈中
局部变量:
- 在函数体中(包含形式参数)声明的变量。
- 局部变量的引用比全局变量快,优先考虑使用。
- 如果局部变量和全局变量同名,则在函数内隐藏全局变量,只使用同名的局部变量
- 储存在栈帧(stark frame)中,函数运行结束,栈帧销毁
【操作】全局变量的作用域测试
a = 100 #全局变量
def f1():
global a #如果要在函数内改变全局变量的值,增加global关键字声明
print(a) #打印全局变量a的值
a = 300
f1()
print(a)
执行结果:
100
300
【操作】全局变量和局部变量同名测试
a=100
def f1():
a = 3 #同名的局部变量
print(a)
f1()
print(a) #a仍然是100,没有变化
执行结果:
3
100
【操作】 输出局部变量和全局变量
a = 100
def f1(a,b,c):
print(a,b,c)
print(locals()) #打印输出的局部变量
print("#"*20)
print(globals()) #打印输出的全局变量
f1(2,3,4)
执行结果:
2 3 4
{'a': 2, 'b': 3, 'c': 4}
####################
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000021EAA7B0910>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/dell/PycharmProjects/mystudypy400/func_04.py', '__cached__': None, 'a': 100, 'f1': <function f1 at 0x0000021EAA8F6F70>}
5 局部变量和全局变量效率测试
局部变量的查询和访问速度比全局变量快,优先考虑使用,尤其是在循环的时候。
在特别强调效率的地方或者循环次数较多的地方,可以通过将全局变量转为局部变量提高运行速度。
【操作】测试局部变量和全局变量效率
#测试局部变量、全局变量的效率
import math
import time
def test01():
start = time.time()
for i in range(10000000):
math.sqrt(30)
end = time.time()
print("耗时{0}".format((end-start)))
def test02():
b = math.sqrt
start = time.time()
for i in range(10000000):
b(30)
end = time.time()
print("耗时{0}".format((end-start)))
test01()
test02()
运行结果:
耗时2.3589999675750732
耗时1.6410000324249268
6 参数的传递
函数的参数传递本质上就是:从实参到形参的赋值操作。 Python中“一切皆对象”,所有的赋值操作都是“引用的赋值”。所以,Python中参数的传递都是“引用传递”,不是“值传递”。具体操作时分为两类:
- 对“可变对象”进行“写操作”,直接作用于原对象本身。
- 对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间。(起到其他语言的“值传递”效果,但不是“值传递”)
可变对象有:
字典、列表、集合、自定义的对象等
不可变对象有:
数字、字符串、元组、function等
6.1 传递可变对象的引用
传递参数是可变对象(例如:列表、字典、自定义的其他可变对象等),实际传递的还是对象的引用。在函数体中不创建新的对象拷贝,而是可以直接修改所传递的对象。
【操作】参数传递:传递可变对象的引用
b = [10,20]
def f2(m):
print("m:",id(m)) #b和m是同一个对象
m.append(30) #由于m是可变对象,不创建对象拷贝,直接修改这个对象
f2(b)
print("b:",id(b))
print(b) # b被改变
执行结果:
m: 1618097404800
b: 1618097404800
[10, 20, 30]
6.2 传递不可变对象的引用
传递参数是不可变对象(例如:int、float、字符串、元组、布尔值),实际传递的还是对象的引用。在”赋值操作”时,由于不可变对象无法修改,系统会新创建一个对象。
【操作】参数传递:传递不可变对象的引用
a = 100
def f1(n):
print("n:",id(n)) #传递进来的是a对象的地址
n = n+200 #由于a是不可变对象,因此创建新的对象n,这里对n进行修改
print("n:",id(n)) #n已经变成了新的对象
print(n)
f1(a)
print("a:",id(a))
print(a) # a不能被改变
执行结果:
n: 140714268680960
n: 1853089016240
300
a: 140714268680960
100
显然,通过id值我们可以看到n和a一开始是同一个对象。给n赋值后,n是新的对象。
6.3 浅拷贝和深拷贝
为了更深入的了解参数传递的底层原理,我们需要讲解一下“浅拷贝和深拷贝”。我们可以使用内置函数:copy(浅拷贝)、deepcopy(深拷贝)。
浅拷贝:不拷贝子对象的内容,只是拷贝子对象的引用。(克隆个体)
深拷贝:会连子对象的内存也全部拷贝一份,对子对象的修改不会影响源对象。(克隆家体)
源码:
#测试浅拷贝和深拷贝
import copy
def testCopy():
'''测试浅拷贝'''
a = [10, 20, [5, 6]]
b = copy.copy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("浅拷贝......")
print("a", a)
print("b", b)
def testDeepCopy():
'''测试深拷贝'''
a = [10, 20, [5, 6]]
b = copy.deepcopy(a)
print("a", a)
print("b", b)
b.append(30)
b[2].append(7)
print("深拷贝......")
print("a", a)
print("b", b)
testCopy()
print("*************")
testDeepCopy()
运行结果:
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
浅拷贝......
a [10, 20, [5, 6, 7]]
b [10, 20, [5, 6, 7], 30]
*************
a [10, 20, [5, 6]]
b [10, 20, [5, 6]]
深拷贝......
a [10, 20, [5, 6]]
b [10, 20, [5, 6, 7], 30]
内存图:
浅拷贝:

深拷贝:

6.4 传递不可变对象包含的子对象是可变的情况
# 传递不可变对象时,不可变对象里面包含的子对象是可变的,则方法内修改了这个可变对象,源对象也发生了变化
a = (10, 20, [5,6]) # 元组对象(指向地址)不可变,但是列表(指向地址)可变,可以改变其中的列表
print("a:",id(a))
def test01(m):
print("m:", id(m))
m[2][0]=888
print(m)
print("m", id(m))
test01(a)
print(a)
运行结果:
a: 2394584171584
m: 2394584171584
(10, 20, [888, 6])
m 2394584171584
(10, 20, [888, 6])
7 参数的几种类型
7.1 位置参数
函数调用时,实参默认按位置顺序传递,需要个数和形参匹配。按位置传递的参数,称为:“位置参数”。
【操作】测试位置参数
def f1(a,b,c):
print(a,b,c)
f1(2,3,4)
f1(2,3) #报错,位置参数不匹配
执行结果:
Traceback (most recent call last):
File "C:/Users/dell/PycharmProjects/mystudypy400/func_09.py", line 5, in <module>
f1(2,3) #报错,位置参数不匹配
TypeError: f1() missing 1 required positional argument: 'c'
2 3 4
7.2 默认值参数
我们可以为某些参数设置默认值,这样这些参数在传递时就是可选的。称为“默认值参数”。默认值参数放到位置参数后面。
【操作】测试默认值参数
def f1(a,b,c=10,d=20): #默认值参数必须位于普通位置参数后面,放前面无法识别
print(a,b,c,d)
f1(8,9)
f1(8,9,19)
f1(8,9,19,29)
执行结果:
8 9 10 20
8 9 19 20
8 9 19 29
7.3 命名参数
我们也可以按照形参的名称传递参数,称为“命名参数”,也称“关键字参数”。
【操作】测试命名参数
def f1(a,b,c):
print(a,b,c)
f1(8,9,19) #位置参数
f1(c=10,a=20,b=30) #命名参数
执行结果:
8 9 19
20 30 10
7.4 可变参数
可变参数指的是“可变数量的参数”。分两种情况:
- *param(一个星号),将多个参数收集到一个“元组”对象中。
- **param(两个星号),将多个参数收集到一个“字典”对象中。
【操作】测试可变参数处理(元组、字典两种方式)
def f1(a,b,*c):
print(a,b,c)
f1(8,9,19,20)
def f2(a,b,**c):
print(a,b,c)
f2(8,9,name='gaoqi',age=18)
def f3(a,b,*c,**d):
print(a,b,c,d)
f3(8,9,20,30,name='gaoqi',age=18)
执行结果:
8 9 (19, 20)
8 9 {'name': 'gaoqi', 'age': 18}
8 9 (20, 30) {'name': 'gaoqi', 'age': 18}
7.5 强制命名参数
在带星号的“可变参数”后面增加新的参数,必须在调用的时候“强制命名参数”。
【操作】强制命名参数的使用
def f1(*a,b,c):
print(a,b,c)
#f1(2,3,4) #会报错。由于a是可变参数,将2,3,4全部收集。造成b和c没有赋值。
f1(2,b=3,c=4)
执行结果:(元组只有一个元素时,后面有逗号才是元组)
(2,) 3 4
8 lambda表达式和匿名函数
lambda表达式可以用来声明匿名函数。lambda函数是一种简单的、在同一行中定义函数的方法。lambda函数实际生成了一个函数对象。
lambda表达式只允许包含一个表达式,不能包含复杂语句,该表达式的计算结果就是函数的返回值。
lambda表达式的基本语法如下:
lambda arg1,arg2,arg3... : <表达式>
arg1/arg2/arg3为函数的参数。<表达式>相当于函数体。运算结果是:表达式的运算结果。
【操作】lambda表达式使用
f = lambda a,b,c:a+b+c
print(f)
print(f(2,3,4))
g = [lambda a:a*2,lambda b:b*3,lambda c:c*4]
print(g[0](6),g[1](7),g[2](8))
执行结果:
<function <lambda> at 0x000001ECA97D6EE0>
9
12 21 32
9 eval()函数
功能:将字符串str当成有效的表达式来求值并返回计算结果。
语法:
eval(source[, globals[, locals]]) -> value
参数:
source:一个Python表达式或函数compile()返回的代码对象
globals:可选。必须是dictionary
locals:可选。任意映射对象
#测试eval()函数
s = "print('abcde')"
eval(s)
a = 10
b = 20
c = eval("a+b")
print(c)
dict1 = dict(a=100,b=200)
d=eval("a+b")
print(d)
e=eval("a+b",dict1)
print(e)
运行结果
abcde
30
30
300
eval函数会将字符串当做语句来执行,因此会被注入安全隐患。比如:字符串中含有删除文件的语句。那就麻烦大了。因此,使用时候,要慎重!!!
10 递归函数
递归函数指的是:自己调用自己的函数,在函数体内部直接或间接的自己调用自己。递归类似于大家中学数学学习过的“数学归纳法”。 每个递归函数必须包含两个部分:
- 终止条件
表示递归什么时候结束。一般用于返回值,不再调用自己。 - 递归步骤
把第n步的值和第n-1步相关联。
【操作】 测试递归函数基本原理
def test01(n):
print("test01:",n)
if n == 0:
print("over")
else:
test01(n-1)
print("test01***", n)
def test02():
print("test02")
test01(4)
运行结果(先进后出,后进先出):
test01: 4
test01: 3
test01: 2
test01: 1
test01: 0
over
test01*** 0
test01*** 1
test01*** 2
test01*** 3
test01*** 4
内存图
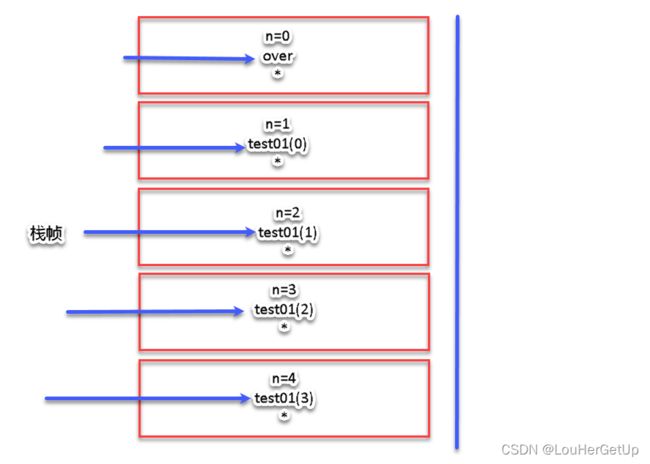
递归函数由于会创建大量的函数对象、过量的消耗内存和运算能力。在处理大量数据时,谨慎使用。
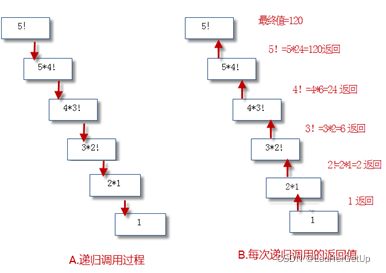
【操作】 使用递归函数计算阶乘(factorial)
def factorial(n):
if n==1:return 1
return n*factorial(n-1)
for i in range(1,6):
print(i,'!=',factorial(i))
执行结果:
1 != 1
2 != 2
3 != 6
4 != 24
5!=120
11 嵌套函数(内部函数)
嵌套函数:
在函数内部定义的函数!
【操作】嵌套函数定义
def outer():
print("outer running")
def inner01():
print("inner01 running")
inner01()
outer()
执行结果:
outer running
inner01 running
上面程序中,inner01()就是定义在outer 函数内部的函数。inner01()的定义和调用都在outer ()函数内部。
一般在什么情况下使用嵌套函数?
- 封装 - 数据隐藏
外部无法访问“嵌套函数”。 - 贯彻 DRY(Don’t Repeat Yourself) 原则
嵌套函数,可以让我们在函数内部避免重复代码。 - 闭包
后面会详细讲解。
【操作】使用嵌套函数避免重复代码
def printChineseName(name,familyName):
print("{0} {1}".format(familyName,name))
def printEnglishName(name,familyName):
print("{0} {1}".format(name, familyName))
#使用1个函数代替上面的两个函数
def printName(isChinese,name,familyName):
def inner_print(a, b):
print("{0} {1}".format(a,b))
if isChinese:
inner_print(familyName, name)
else:
inner_print(name, familyName)
printName(True,"小七","高")
printName(False,"George","Bush")
运行结果
高 小七
George Bush
11.1 nonlocal关键字
```python
nonlocal 用来声明外层的局部变量。
global 用来声明全局变量。
【操作】使用nonlocal声明外层局部变量
```python
#测试nonlocal、global关键字的用法
a = 100
def outer():
b = 10
def inner():
nonlocal b #声明外部函数的局部变量
print("inner b:",b)
b = 20
global a #声明全局变量
a = 1000
inner()
print("outer b:",b)
outer()
print("a:",a)
12 LEGB规则
Python在查找“名称”时,是按照LEGB规则查找的:
Local-->Enclosed-->Global-->Built in
Local 指的就是函数或者类的方法内部
Enclosed 指的是嵌套函数(一个函数包裹另一个函数,闭包)
Global 指的是模块中的全局变量
Built in 指的是Python为自己保留的特殊名称。
如果某个name映射在局部(local)命名空间中没有找到,接下来就会在闭包作用域(enclosed)进行搜索,如果闭包作用域也没有找到,Python就会到全局(global)命名空间中进行查找,最后会在内建(built-in)命名空间搜索 (如果一个名称在所有命名空间中都没有找到,就会产生一个NameError)。
#测试LEGB
print(type(str))
# str = "global str"
def outer():
# str = "outer"
def inner():
# str = "inner"
print(str)
inner()
outer()
我们依次将几个str注释掉,观察控制台打印的内容,体会LEBG的搜索顺序。