MySQL运维进阶必备
一、安装和启动MySQL
1.1 Linux 版
#yum install mysql-server(Linux版)
1.2 Windows 版
#省略
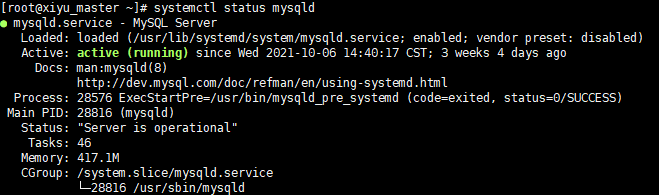
1.3 启动mysql
/etc/init.d/mysqld restart
systemctl status mysqld
三、登录mysql
#ps -ef | grep mysql
3.1 登录数据库
1)密码可以安装日志中查找
mysql -h{数据库连接地址} -u{用户名} -p{密码} -P{端口} {数据库名字}
3.2 创建账号和密码
create user 'xiyu'@'%' identified by 'Admin123!';
select user,host from mysql.user; //查看是否创建成功

注意:
Host:%代表所有
User:root 用户名
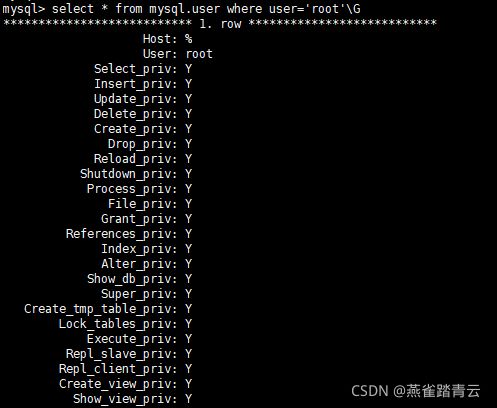
3.3 查看单个用户权限
1)查看用户权限详情
select * from mysql.user where user='root'\G
select * from mysql.user where user='xiyu'\G

3.4 给用户赋权限
1)给予用户全部的权限
GRANT
ALL PRIVILEGES
ON *.*
TO xiyu@'%';
或者
GRANT
ALL PRIVILEGES
ON *.*
TO xiyu@'%' WITH GRANT OPTION;
2)单个数据库授权
只给175.155.59.133这个 IP 赋给 mysql数据库查询的权限,用户:qingchen,密码:Admin123!
GRANT
select
ON mysql.*
TO xiyu@'192.168.1.1';
flush privileges;
3)单个表授权
单个数据库单个表授权,只给qingchen账号mysql库中的user表权限
GRANT
select
ON mysql.user
TO xiyu@'%';
IDENTIFIED BY 'Admin123!';
flush privileges;
4)撤销权限
撤销某个用户的权限,格式 : revoke 权限 on 数据库名 from 用户名@“客户端地址”;
revoke all on *.* from xiyu@'%';
grant system_user on *.* to 'root';
四、常见命令
4.1 常用命令
1)查看版本和用户名
select version(); //查看数据库版本
select user(); //查看当前用户
select database(); //查看当前所在数据库
select user,host from mysql.user; //查看所有用户
select * from mysql.user where user='root'\G //查看单个用户的情况
show databases; //查看数据库列表
use database名字; //进入(切换)到某个数据库
2)查看数据库和表
show tables from database名字; 不进入(切换)查看某个数据库中表
desc table名字; 查看表结构
3)创建、更新和删除表信息
create table 表名(
列名 列类型,
列名 列类型,
...
) //创建表
select * from table名字; //查看表
update 表名 set 字段='新结果' where 条件1 {and} {条件2}; //更新表字段
delete from 表名 where 条件1 {and} {条件2}; //删除表字段
4)时区查询和配置
检查mysql系统时区
show variables like '%time_zone%';
修改时区
set time_zone='+8:00'; //将时区设置为东八区
验证时间
select now();

时区特别说明:
格林威治标准时间GMT
世界协调时间UTC
夏日节约时间DST
中央标准时间CST
CST可以同时表示美国,澳大利亚,中国,古巴四个国家的标准时间
Central Standard Time (USA) UT-6:00(美国cst时间:零区时减6个小时)
Central Standard Time (Australia) UT+9:30(澳大利亚cst:加9个半小时)
China Standard Time UT+8:00(中国cst:加8个小时)
Cuba Standard Time UT-4:00 (古巴cst:减4个小时)
如:当UTC时间为0点时,中国CST时间为8点,因为零时区和中国北京时区相差8个时区。
4.2 DQL语言学习(data query languge)
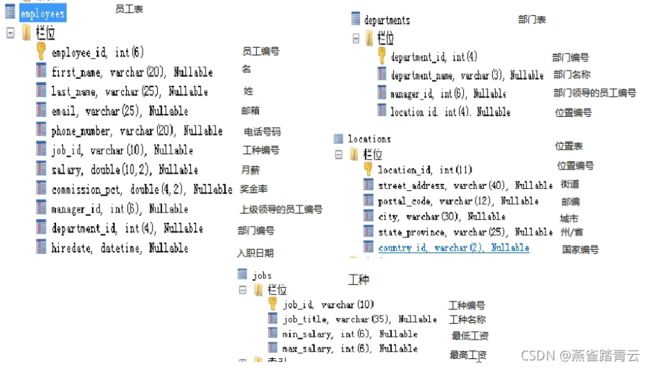
环境搭建:
- 创建数据库 myemployees(员工部门信息库)
- 创建数据表 departments(部门表)、employees(员工表)、jobs(岗位表)、locations(位置表)
- 以上表均以插入数据,后续所以实验均在以上库和表中完成
4.2.1 基础查询
1)查询字段
select 查询条件 from 表名;
select last_name from employees; //查询姓名一个字段
SELECT last_name,salary FROM employees; //查询多个字段
SELECT * FROM employees; //查询全部字段
2)常量查询
SELECT 100; //查询常量值
SELECT 100%98; //查询表达式
SELECT 1+2; //两个均为数值型,作加法运算
SELECT '123'+2; //一方为字符,试图将字符转算数值型
SELECT 'tom'+2; //一方为字符,试图将字符转算数值型,转换失败,作为0运行
SELECT VERSION(); //查询函数
3)设置别名查询
SELECT last_name AS 姓,first_name AS 名 FROM employees; //用AS起别名,用于有重名的适合区分
SELECT last_name 姓,first_name 名 FROM employees; //可以省略AS
4)使用DISTINCT去重查询
SELECT DISTINCT department_id FROM employees ; //查看员工表中所有部门编号

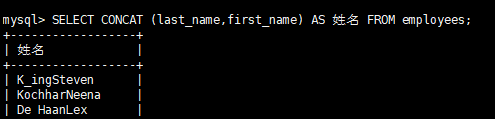
5)使用CONCAT字段拼接
SELECT CONCAT (last_name,first_name) AS 姓名 FROM employees;
6)使用IFNULL,为NULL时返回0
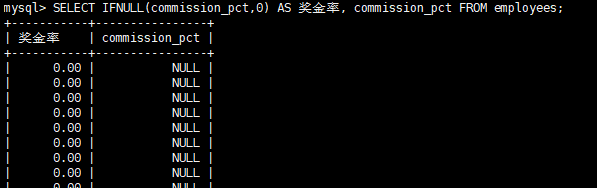
SELECT IFNULL(commission_pct,0) AS 奖金率, commission_pct FROM employees; //奖金有空时返回0
4.2.2 条件查询
1)条件查询定义
使用 MySQL SELECT语句时,在指定查询条件,从 FROM 子句的中间结果中选取适当的数据行,达到数据过滤的效果,被称为条件查询语句
2)条件查询语法
SELECT 查询列表 FROM 表名 WHERE 筛选条件; 先表名,再筛选,最后查询
案例一、查询工资大于12000的员工信息
SELECT * FROM employees WHERE salary>12000; 工资大于12000

3)条件查询分类
条件运算符:
><
=
!=
<>
>=
<=
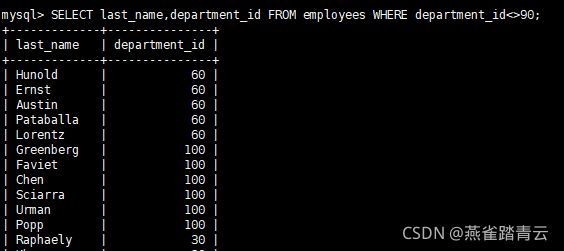
案例一、查询部门编号不等于90的员工信息
SELECT last_name,department_id FROM employees WHERE department_id<>90; 部门编号不等于90的,<>和!=一样的效果
4)逻辑运算符
&& 与 :两个条件均true 结果true,反之false
|| 或:一个条件为true 结果为ture,反之false
! 非:连接条件本身为false,结果为true,反之false
案例一、查询工资大于等于10000小于等于20000的员工姓名
SELECT last_name,salary,commission_pct FROM employees WHERE salary>=10000 AND salary <=20000;

案例二、 查询部门ID大于等于90 小于等于110 并且工资大于15000的员工信息
SELECT * FROM employees WHERE department_id>=90 AND department_id<=110 OR salary>15000;

5)模糊查询
like:一般和通配符搭配使用,%代表多个字符,包括0个,_代表一个字符
between and: xx和xx之间
in:
is null:
案例一、查询员工表中包含字符a的员工信息
SELECT * FROM employees WHERE last_name LIKE '%a%';

案例二、查询员工表中第三个字符为n,第五个字符为l的员工信息
SELECT
*
FROM
employees
WHERE
last_name LIKE '___n_l%';

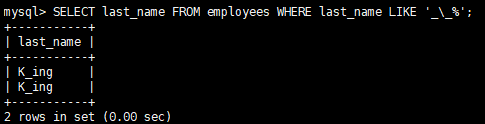
案例三、查询员工表中第二个字符为_ 的员工名(用 \ 对 _转义)
SELECT
last_name
FROM
employees
WHERE
last_name LIKE '_\_%';
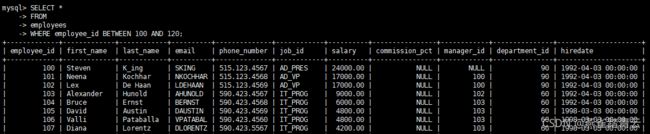
案例四、查询员工编号再100到120之间的员工信息
SELECT
*
FROM
employees
WHERE
employee_id BETWEEN 100 AND 120;
等同于employee_id>=100 AND employee_id<=120,不能调换顺序
案例五、查询员工工种编号是IT_PROG、AD_VP
SELECT
last_name,
job_id
FROM
employees
WHERE
job_id IN ( 'IT_PROT' OR job_id = 'AD_VP');
等同于job_id = ‘IT_PROT’ OR job_id = ‘AD_VP’;
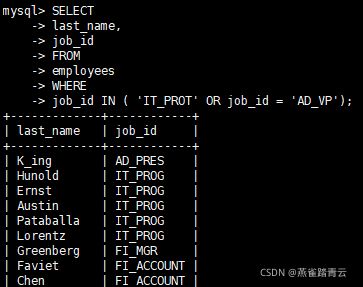
案例六、查询没有奖金的员工名和奖金率
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct IS NULL;

相反值 IS NOT NULL
案例六、查询没有奖金的员工名和奖金率,使用安全等于 <=>
SELECT
last_name,
commission_pct
FROM
employees
WHERE
commission_pct <=> NULL;
结果等价于 IS NULL,是安全等于可读性比较差,用的不多
说明:
IS NULL:仅仅可以判断NULL值,可读性较高,建议使用
<=>:既可以判断NULL值,又可以判断普通的数值,可读性较差
4.2.3 排序查询
1)排序查询定义
在MySQL SELECT 语句中,将结果中的数据按照一定的顺序进行排序
2)排序查询语法
SELECT 查询列表
FROM 表
【WHERE 筛选条件】
ORDER BY 排序列表 ASC|DESC //升序或降序
3)排序查询案例
案例一、工资升序排名
SELECT * FROM employees ORDER BY salary DESC;降序
SELECT * FROM employees ORDER BY salary ACS; 升序(默认就是升序)
案例二、查询部门编号>=90的员工信息,按入职时间的先后进行排序
SELECT * FROM employees WHERE department_id >=90 ORDER BY hiredate ASC;
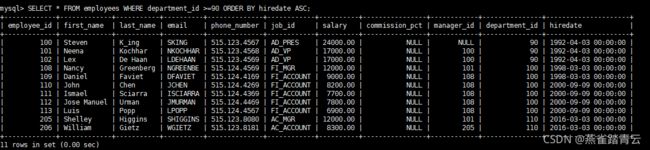
案例三、按年薪的高低显示员工的信息和年薪【按表达式排序】
SELECT * ,salary*12*(1+IFNULL(commission_pct,0)) FROM employees ORDER BY salary*12*(1+IFNULL(commission_pct,0)) DESC;
或者
SELECT * ,salary*12*(1+IFNULL(commission_pct,0)) 年薪 FROM employees ORDER BY 年薪 DESC;


案例四、按姓名的长度显示员工姓名和工资【按函数排序】
SELECT LENGTH(last_name) 字节长度, last_name,salary FROM employees ORDER BY 字节长度 DESC;
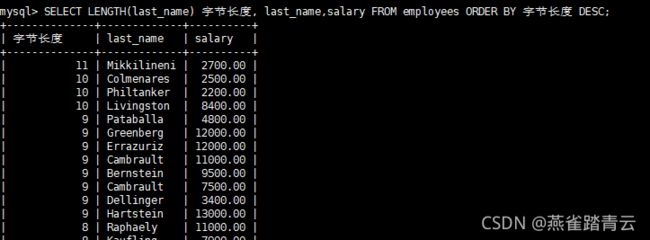
案例五、查询员工信息,先按照工资升序,再按照员工编号降序【多字段排序】
SELECT * FROM employees ORDER BY salary ASC,employee_id DESC;

注意:
1、ACS代表升序,DESC代表降序,默认升序
2、order by子句中支持单个字段、多个字段、表达式、函数、别名
3、order by子句放在查询语句的最后面,limit子句除外
4.2.4 常见函数
1) 常见函数定义
将一组逻辑语句封装在方法体中,对外暴漏方法名,隐藏实现细节,提高代码的重用性
2) 常见函数语法
select 函数名(实参列表)【from 表】;
3) 常见函数分类
- 单行函数,如concat、length、ifnull等
- 分组函数,做统计使用,又称为统计函数、聚合函数、组函数
4.2.5 单行函数
4.2.5.1、字符函数 - length
1) length
获取参数值的字节个数
SELECT LENGTH(‘xiyu’);
SELECT LENGTH(‘张无忌’); //一个数字三个字节
SHOW VARIABLES LIKE ‘%char%’;
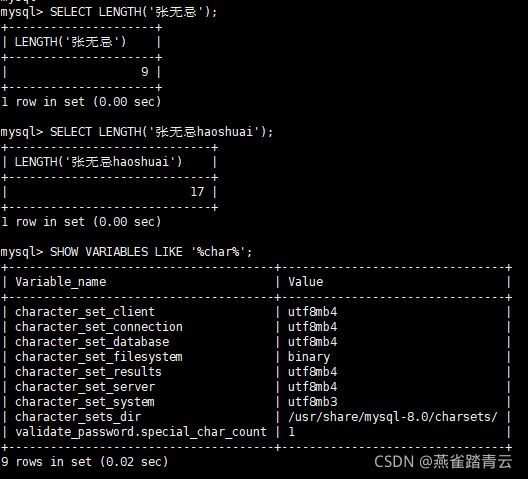
4.2.5.2、字符函数 - concat
concat 拼接函数 ,用来拼接字符串
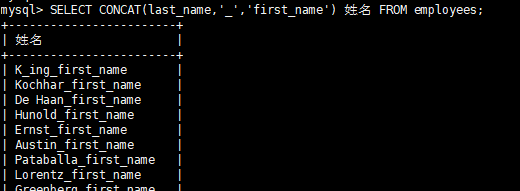
SELECT CONCAT(last_name,’_’,‘first_name’) 姓名 FROM employees;
4.2.5.3、字符函数 - upper lower
upper lower 大小写转化
SELECT UPPER(‘xiyu’); //转为大写
SELECT LOWER(‘xiYU’);//转为小写
案例:姓名大小写并进行拼接
SELECT CONCAT(UPPER(last_name), LOWER(first_name)) 姓名 FROM employees;

4.2.5.4、字符函数 - substr
substr 截取字符
索引从1开始,第二位代表长度,只有一个参数的话,从第N个开始到最后
SELECT SUBSTR(‘赵敏爱上了张无忌’,6) ;
SELECT SUBSTR(‘赵敏爱上了张无忌’,1,2) ;
SELECT SUBSTR(‘赵敏爱上了张无忌’,1,2) ;

4.2.5.5、字符函数 - instr
instr 返回字串第一次出现的索引位置,如果找不到返回0
SELECT INSTR(‘赵敏爱上了张无忌’,‘没结果’) AS out_put;

4.2.5.6、字符函数 - trim
trim 去前后空字符
SELECT LENGTH(TRIM(‘赵敏爱上了张无忌’) ) AS out_put;

4.2.5.7、字符函数 - lpad
lpad 左填充
SELECT LPAD(‘白眉鹰王’,5,‘abcd’) AS out_put; 大于目前长度填充后边指定的字符

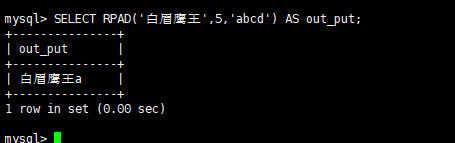
4.2.5.8、字符函数 - rpad
rpad 右填充
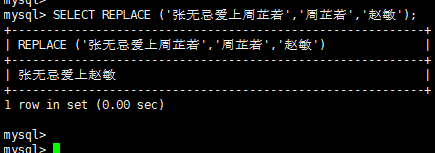
4.2.5.9、字符函数 - replace
replace 替换
SELECT REPLACE (‘张无忌爱上周芷若’,‘周芷若’,‘赵敏’);
4.2.5.10、数学函数 - round
round四舍五入
select round(1.1);
select round(9.5);
select round(-1.6);

4.2.5.11、数学函数 - ceil
ceil 向上取整,返回参数的最小整数
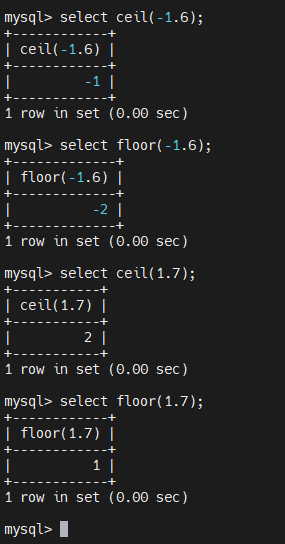
4.2.5.12、数学函数 - floor
floor向下取整,返回参数的最大整数
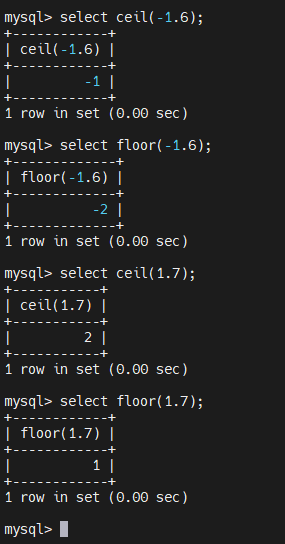
4.2.5.13、数学函数 - truncate
truncate 截断
select truncate(1.234,1);

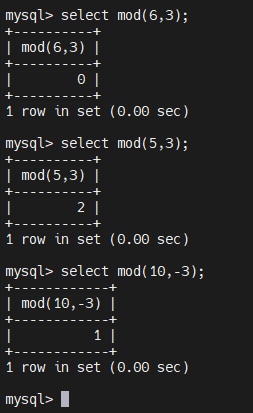
4.2.5.14、数学函数 - mod
mod 取余数
select mod(6,3);
select mod(5,3);
select mod(10,-3);
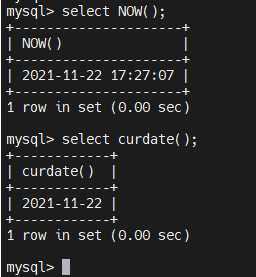
4.2.5.15、日期函数 - now
select NOW(); //返回当前日期和时间
select curdata(); //返回当前日期
select curtime(); //返回当前时间
select MONTH(NOW()) 月; //显示月份
select MONTHNAME(NOW()) 月; //英文显示月份
select YEAR(hiredate) 年 from employees; //显示员工入职年份
4.2.5.16、日期函数 - 格式转换
select str_to_date(‘10-11-2021’,’%m-%d-%Y’);
select date_format(‘2021-11-22’,’%Y年%m月%d日’);

| 格式符号 | 功能 |
|---|---|
| %Y | 代表四位年份 |
| %y | 代表2位的年份 |
| %m | 代表月份(01,02,11,12) |
| %c | 代表月份(1,2…11,12) |
| %d | 代表日(01,02) |
| %H | 代表小时(24小时) |
| %h | 代表小时(12小时) |
| %i | 代表分钟(00,01) |
| %s | 代表秒(00,01.59) |
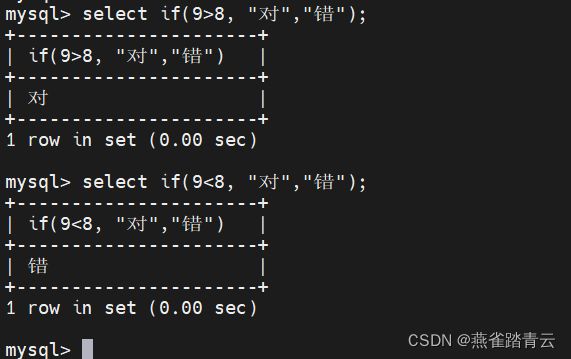
4.2.5.17、流程控制函数 - if
select if(9>8 “对”,“错”);
select if(9<8 “对”,“错”);
mysql >select first_name,last_name ,commission_pct,if(commission_pct is null, “哎,没奖金”,“哈哈,有奖金”) as 备注 from employees ;

4.2.5.18、流程控制函数 - case
case 判断的字段或者表达式
when 常量1 then 要显示的值1或者语句1;
when 常量2 then 要显示的值2或者语句2;
…
else 要显示的值n或者语句n;
end
*/
案例:
部门号=30,显示的工资为1.1倍
部门号=40,显示的工资为1.2倍
部门号=50,显示的工资为1.3倍
其他部门,显示原工资
*/
方法一:
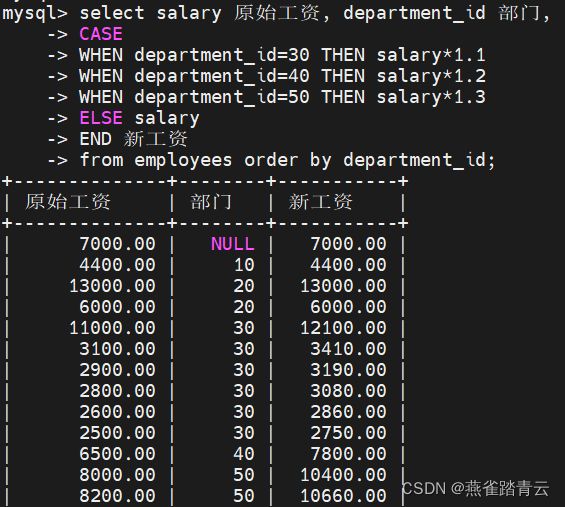
mysql>select salary 原始工资, department_id 部门,
CASE department_id
WHEN 30 THEN salary1.1
WHEN 40 THEN salary1.2
WHEN 50 THEN salary*1.3
ELSE salary
END 新工资
from employees order by department_id;

方法二:
mysql>select salary 原始工资, department_id 部门,
CASE
WHEN department_id=30 THEN salary1.1
WHEN department_id=40 THEN salary1.2
WHEN department_id=50 THEN salary*1.3
ELSE salary
END 新工资
from employees order by department_id;
4.2.6、分组函数
4.2.6.1 分组函数 - 作用
用于统计,又称聚合函数、统计函数或者组函数
4.2.6.2 分组函数 - 分类(SUM AVG MAX MIN COUNT)
1)sum 求和(支持数值型)
2)avg 平均(支持数值型)
3)max 最大值(支持数值型)
4)min 最小值(支持数值型)
5)count 计算个数(支持任何类型)
select SUM(salary) FROM employees;
select AVG(salary) FROM employees
select MAX(salary) FROM employees
select MIN(salary) FROM employees
select COUNT(salary) FROM employees
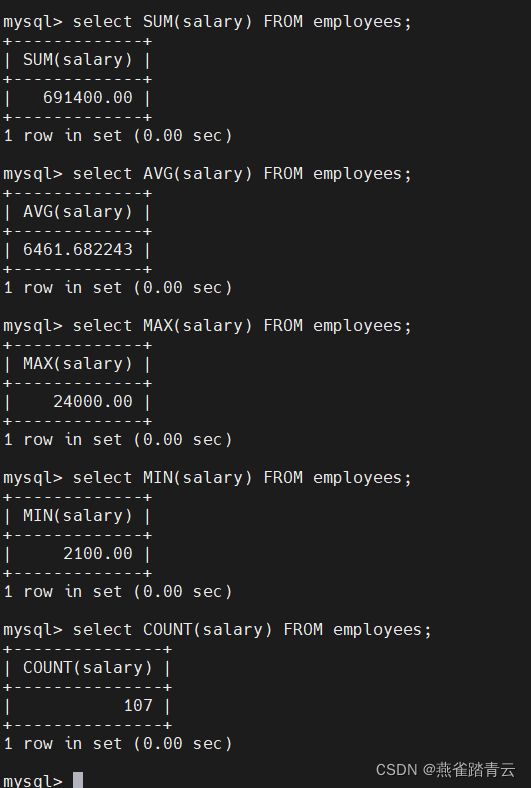
mysql> select SUM(salary) 和,AVG(salary) 平均,MAX(salary) 最大值,MIN(salary) 最小值,COUNT(salary) 个数 FROM employees;

4.2.6.3 分组函数 - 支持的类型
1)sum 求和(支持数值型)
2)avg 平均(支持数值型)
3)max 最大值(支持任何类型)
4)min 最小值(支持任何类型)
5)count 计算个数(支持任何类型)
注意:以上null值都忽略,只计算非空数值
4.2.6.4 分组函数 - distinct搭配
distinct :去重功能
mysql>select sum(distinct salary) ,sum(salary) from employees;

mysql>select count(distinct salary) ,count(salary) from employees;
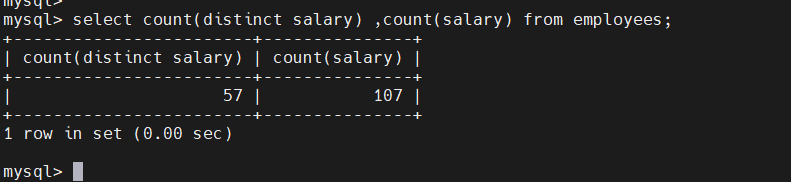
去重之后只有57个,未去重有107个
4.2.6.5 分组函数 - count函数
mysql>select count(department_id) from employees;
mysql>select count(*) from employees;
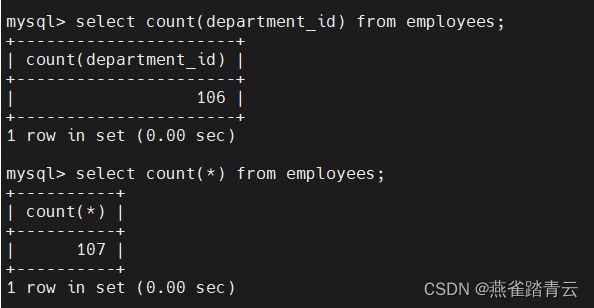
注意:
count统计某一个字段(若是非空,忽略)一般用count()或者count(1)来统计行数
count() 代表所有行数,准确统计
count(1)代表在表的前面加一列名为“1”的字段,然后统计“1”的个数,当然,“1”可以换成任何数值或者常量,都可以统计
- 5.5之前默认引擎 MYISAM COUNT(*) 效率高
- 5.5之后默认引擎INNODB COUNT(*)与1的效率产不多
4.2.6.6 分组函数 - 注意事项
1)与分组函数一同查询的字段有限制
比如统计平均值与部门的对应关系
2)与分组函数一同查询的字段要求是group by后的字段
4.2.7、分组查询
4.2.8、连接查询
4.2.9、子查询
4.2.10、分页查询
4.2.11、union联合查询
4.3 DML
4.4 DDL
4.5 TCL
4.6 视图
4.7 存储过程和函数
4.4 流程控制结构
部分内容摘自《blibli博主-黎曼的猜想》